- Table of Contents
-
- H3C S3610[5510] Series Ethernet Switches Operation Manual-Release 0001-(V1.02)
- 00-1Cover
- 00-2Product Overview
- 01-Login Operation
- 02-VLAN Operation
- 03-IP Address and Performance Operation
- 04-QinQ-BPDU Tunnel Operation
- 05-Port Correlation Configuration Operation
- 06-MAC Address Table Management Operation
- 07-MAC-IP-Port Binding Operation
- 08-MSTP Operation
- 09-Routing Overview Operation
- 10-IPv4 Routing Operation
- 11-IPv6 Routing Operation
- 12-IPv6 Configuration Operation
- 13-Multicast Protocol Operation
- 14-802.1x-HABP-MAC Authentication Operation
- 15-AAA-RADIUS-HWTACACS Operation
- 16-ARP Operation
- 17-DHCP Operation
- 18-ACL Operation
- 19-QoS Operation
- 20-Port Mirroring Operation
- 21-Cluster Management Operation
- 22-UDP Helper Operation
- 23-SNMP-RMON Operation
- 24-NTP Operation
- 25-DNS Operation
- 26-File System Management Operation
- 27-Information Center Operation
- 28-System Maintenance and Debugging Operation
- 29-NQA Operation
- 30-VRRP Operation
- 31-SSH Operation
- 32-Appendix
- Related Documents
-
| Title | Size | Download |
|---|---|---|
| 10-IPv4 Routing Operation | 3 MB |
Table of Contents
Chapter 1 Static Routing Configuration
1.1.3 Application of Static Routing
1.2.1 Configuration Prerequisites
1.2.2 Configuring Static Routes
1.3 Displaying and Maintaining Static Routes
1.4 Example of Static Routes Configuration
2.2 Configuring RIP Basic Functions
2.2.1 Configuration Prerequisites
2.3 Configuring RIP Advanced Functions
2.3.1 Configuring an Additional Routing Metric
2.3.2 Configuring RIP-2 Route Summarization
2.3.3 Disabling Host Route Reception
2.3.4 Advertising a Default Route
2.3.5 Configuring Inbound/Outbound Route Filtering Policies
2.3.6 Configuring a Priority for RIP
2.3.7 Configuring RIP Route Redistribution
2.4 Optimizing the RIP Network
2.4.2 Configuring the Split Horizon and Poison Reverse
2.4.3 Configuring the Maximum Number of Load Balanced Routes
2.4.4 Configuring RIP Message Check
2.4.5 Configuring RIP-2 Message Authentication
2.4.6 Configuring a RIP Neighbor
2.4.7 Configuring RIP-to-MIB Binding
2.5 Displaying and Maintaining RIP
2.6.2 Configuring RIP Route Redistribution
2.7 Troubleshooting RIP Configuration
2.7.2 Route Oscillation Occurred
3.1.2 OSPF Area and Route Summarization
3.1.3 Classification of OSPF Networks
3.2 OSPF Configuration Task List
3.3 Configuring OSPF Basic Functions
3.4 Configuring OSPF Area Parameters
3.5 Configuring OSPF Network Types
3.5.2 Configuring the OSPF Network Type for an Interface
3.5.3 Configuring an NBMA Neighbor
3.5.4 Configuring the DR Priority for an OSPF Interface
3.6 Configuring OSPF Routing Information Management
3.6.2 Configuring OSPF Route Summarization
3.6.3 Configuring OSPF Inbound Route Filtering
3.6.4 Configuring ABR Type3 LSA Filtering
3.6.5 Configuring OSPF Link Cost
3.6.6 Configuring the Maximum Number of OSPF Routes
3.6.7 Configuring the Maximum Number of Load-balanced Routes
3.6.8 Configuring OSPF Priority
3.6.9 Configuring OSPF Route Redistribution
3.7 Configuring OSPF Network Optimization
3.7.2 Configuring OSPF Packet Timers
3.7.3 Configuring LSA Transmission Delay Time
3.7.4 Configuring SPF Calculation Interval
3.7.5 Configuring LSA Minimum Repeat Arrival Interval
3.7.6 Configuring LSA Generation Interval
3.7.7 Disabling Interfaces from Sending OSPF Packets
3.7.8 Configuring Stub Routers
3.7.9 Configuring OSPF Authentication
3.7.10 Adding Interface MTU into DD Packets
3.7.11 Configuring the Maximum Number of External LSAs in LSDB
3.7.12 Making External Route Selection Rules Defined in RFC1583 Compatible
3.7.13 Configuring OSPF Network Management
3.8 Displaying and Maintaining OSPF
3.9 OSPF Typical Configuration Examples
3.9.1 Configuring OSPF Basic Functions
3.9.2 Configuring an OSPF Stub Area
3.9.3 Configuring an OSPF NSSA Area
3.9.4 Configuring OSPF DR Election
3.9.5 Configuring OSPF Virtual Links
3.10 Troubleshooting OSPF Configuration
3.10.1 No OSPF Neighbor Relationship Established
3.10.2 Incorrect Routing Information
4.1.5 IS-IS Features Supported
4.2 IS-IS Configuration Task List
4.3 Configuring IS-IS Basic Functions
4.3.1 Configuration Prerequisites
4.4 Configuring IS-IS Routing Information Control
4.4.1 Configuration Prerequisites
4.4.2 Configuring IS-IS Protocol Priority
4.4.3 Configuring IS-IS Link Cost
4.4.4 Configuring the Maximum Number of Load Balanced Routes
4.4.5 Configuring IS-IS Route Summarization
4.4.6 Advertising a Default Route
4.4.7 Configuring Inbound Route Filtering
4.4.8 Configuring Route Redistribution
4.4.9 Configuring Route Leaking
4.5 Tuning and Optimizing IS-IS Network
4.5.1 Configuration Prerequisites
4.5.2 Configuring a DIS Priority for an Interface
4.5.3 Configuring IS-IS Timers
4.5.4 Configuring LSP Parameters
4.5.5 Configuring SPF Parameters
4.5.6 Configuring Dynamic Host Name Mapping
4.5.7 Configuring IS-IS Authentication
4.5.8 Configuring LSDB Overload Tag
4.5.9 Logging the Adjacency Changes
4.5.10 Enabling an Interface to Send Small Hello Packets
4.6 Displaying and Maintaining IS-IS Configuration
4.7 IS-IS Configuration Example
4.7.1 IS-IS Basic Configuration
4.7.2 DIS Selection Configuration
5.1.4 IBGP and IGP Information Synchronization
5.1.5 Settlements for Problems Caused by Large Scale BGP Networks
5.2 BGP Configuration Task List
5.3 Configuring BGP Basic Functions
5.4 Controlling Route Distribution and Reception
5.4.2 Configuring BGP Route Redistribution
5.4.3 Configuring BGP Route Summarization
5.4.4 Advertising a Default Route
5.4.5 Configuring BGP Routing Distribution Policy
5.4.6 Configuring BGP Routing Reception Policy
5.4.7 Configuring BGP and IGP Route Synchronization
5.4.8 Configuring BGP Route Dampening
5.5 Configuring BGP Routing Attributes
5.6 Adjusting and Optimizing BGP Networks
5.7 Configuring a Large Scale BGP Network
5.7.1 Configuration Prerequisites
5.7.2 Configuring BGP Peer Groups
5.7.3 Configuring BGP Community
5.7.4 Configuring a BGP Router Reflector
5.7.5 Configuring a BGP Confederation
5.8 Displaying and Maintaining BGP Configuration
5.8.2 Resetting BGP Connections
5.8.3 Clearing BGP Information
5.9 BGP Typical Configuration Examples
5.9.2 BGP and IGP Interaction Configuration
5.9.3 BGP Load Balancing and MED Attribute Configuration
5.9.4 BGP Community Configuration
5.9.5 BGP Router Reflector Configuration
5.9.6 BGP Confederation Configuration
5.9.7 BGP Path Selection Configuration
5.10 Troubleshooting BGP Configuration
5.10.1 No BGP Peer Relationship Established
Chapter 6 Routing Policy Configuration
6.1 Introduction to Routing Policy
6.1.3 Routing Policy Application
6.2.2 Defining an IPv4 prefix list
6.2.4 Defining a Community List
6.2.5 Defining an Extended Community List
6.3 Configuring a Routing Policy
6.3.2 Creating a Routing Policy
6.3.3 Defining if-match Clauses for the Routing Policy
6.3.4 Defining apply Clauses for the Routing Policy
6.4 Displaying and Maintaining the Routing Policy
6.5 Routing Policy Configuration Example
6.5.1 Applying Routing Policy When Redistributing IPv4 Routes
6.6 Troubleshooting Routing Policy Configuration
6.6.1 IPv4 Routing Information Filtering Failed
7.1 Introduction to Graceful Restart
7.1.1 Graceful Restart Overview
7.1.2 Basic Mechanism of Graceful Restart
7.1.3 Graceful Restart Mechanism for Several Commonly Used Protocols
7.2 Configuring Graceful Restart
7.2.1 Configuring BGP-based Graceful Restart
7.2.2 Configuring OSPF-based Graceful Restart
7.2.3 Configuring IS-IS-based Graceful Restart
7.3 Displaying and Maintaining Graceful Restart
7.4 Graceful Restart Configuration Example
7.4.1 IS-IS-based Graceful Restart Configuration Example
7.4.2 OSPF-based Graceful Restart Configuration Example
Chapter 1 Static Routing Configuration
& Note:
The term “router” or a router icon used throughout this document represents a generic router or an Ethernet switch running routing protocols.
1.1 Introduction
1.1.1 Static Routing
A static route is a special route that is manually configured by the network administrator. If a network is relatively simple, you only need to configure static routes for the network to work normally. The proper configuration and usage of static routes can improve a network’s performance and ensure bandwidth for important network applications.
The disadvantage of static routing is that, if a fault or a topological change occurs to the network, the route will be unreachable and the network breaks. In this case, the network administrator has to modify the configuration manually.
1.1.2 Default Routes
A default route is a special static route.
Generally, a router selects the default route only when it cannot find any matching entry in the routing table. In a routing table, the default route is in the form of the route to the network 0.0.0.0 (with the mask 0.0.0.0). You can check whether a default route has been configured by running the display ip routing-table command.
1.1.3 Application of Static Routing
You need to be familiar with the following contents while configuring static routes:
1) Destination address and masks
In the ip route-static command, the IPv4 address is in dotted decimal format and the mask can be in either dotted decimal format or the mask length (the digits of consecutive 1s in the mask).
2) Output interface and the next hop address
While configuring static routes, you can specify either the output interface or next hop address. Whether you should specify the output interface or the next hop address depends on the specific occasion.
In fact, all the route entries must specify the next hop address. While forwarding a packet, the corresponding route is determined by searching the routing table for the packet’s destination address. Only after the next hop address is specified, the corresponding link-layer address can be found for the link-layer to forward the packet.
3) Other attributes
You can configure different preferences for different static routes for the purpose of easy routing management policy. For example, while configuring multiple routes to the same destination, using identical preference allows for load sharing while using different preference allows for routing backup.
1.2 Configuring Static Route
1.2.1 Configuration Prerequisites
Before configuring a static route, you need to finish the following tasks:
l Configuring the physical parameters for relative interfaces
l Configuring the link-layer attribute for relative interfaces
l Configuring the IP address for relative interfaces
1.2.2 Configuring Static Routes
Follow these steps to configure a static route:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Configure a static route |
ip route-static ip-address { mask | mask-length } { [ vlan-interface vlan-id ] nexthop-address | NULL interface-number } [ preference preference | description description-info | tag tag-value ]* |
Required |
|
Configure the default preference for a static route |
ip route-static default-preference default-preference-value |
Optional The preference is 60 by default. |
& Note:
l While configuring a static route, it will use the default preference if no value is specified. After resetting the default preference, it is valid only for the newly created static route.
l The description text can describe the usage and function of some specific routes, thus make it easy for you to classify and manage different static routes.
l You can easily control the routes by using the tag set in the routing policy.
l While running the ip route-static command to configure static, configuring all-zero destination address and mask specifies using the default route.
1.3 Displaying and Maintaining Static Routes
After the configuration, you can run the display command in any view to display the running status and configuration effect of the static route configuration.
You can use the delete command in the system view to delete all the static routes configured.
Follow these steps to display and maintain a static route:
|
To do… |
Use the command… |
Remarks |
|
Display the summary of the IP routing table |
display ip routing-table |
Available in any view |
|
Display the details of the IP routing table |
display ip routing-table verbose |
|
|
Display the information of a static route |
display ip routing-table protocol static [ inactive | verbose ] |
|
|
Delete all static routes |
delete static-routes all |
Available In system view |
& Note:
You can use the undo ip route-static demand in the system view to delete a static route, and use the delete state-routes all demand in the system view to delete all the static routes configured (including the default IPv4 routes configured manually) at the same time.
1.4 Example of Static Routes Configuration
I. Network requirements
The switches’ interfaces and the hosts’ IP addresses and masks are shown in the following figure. It requires static routes to connect the hosts for inter-communication.
II. Network diagram

Figure 1-1 Network diagram for static routes
III. Configuration procedure
1) Configuring the interfaces’ IP addresses
Omitted.
2) Configuring the static route
# Configure a default route on SwitchA.
<SwitchA> system-view
[SwitchA] ip route-static 0.0.0.0 0.0.0.0 1.1.4.2
# Configure two static routes on SwitchB.
<SwitchB> system-view
[SwitchB] ip route-static 1.1.1.0 255.255.255.0 1.1.4.1
[SwitchB] ip route-static 1.1.3.0 255.255.255.0 1.1.4.6
# Configure a default route on SwitchC.
<SwitchC> system-view
[SwitchC] ip route-static 0.0.0.0 0.0.0.0 1.1.4.5
3) Configure the hosts
The default gateways for the three hosts PC1, PC2 and PC3 are configured as 1.1.1.1, 1.1.2.1 and 1.1.3.1 respectively.
4) Display the configuration result
# Display the IP route table of SwitchA.
[SwitchA] display ip routing-table
Routing Tables: Public
Destinations : 7 Routes : 7
Destination/Mask Proto Pre Cost NextHop Interface
0.0.0.0/0 Static 60 0 1.1.4.2 Vlan100
1.1.1.0/24 Direct 0 0 1.1.1.1 Vlan200
1.1.1.1/32 Direct 0 0 127.0.0.1 InLoop0
1.1.4.0/30 Direct 0 0 1.1.4.1 Vlan100
1.1.4.1/32 Direct 0 0 127.0.0.1 InLoop0
127.0.0.0/8 Direct 0 0 127.0.0.1 InLoop0
127.0.0.1/32 Direct 0 0 127.0.0.1 InLoop0
# Use the ping command to check the connectivity.
[SwitchA] ping 1.1.3.1
PING 1.1.3.1: 56 data bytes, press CTRL_C to break
Reply from 1.1.3.1: bytes=56 Sequence=1 ttl=254 time=62 ms
Reply from 1.1.3.1: bytes=56 Sequence=2 ttl=254 time=63 ms
Reply from 1.1.3.1: bytes=56 Sequence=3 ttl=254 time=63 ms
Reply from 1.1.3.1: bytes=56 Sequence=4 ttl=254 time=62 ms
Reply from 1.1.3.1: bytes=56 Sequence=5 ttl=254 time=62 ms
--- 1.1.3.1 ping statistics ---
5 packet(s) transmitted
5 packet(s) received
0.00% packet loss
round-trip min/avg/max = 62/62/63 ms
# Use the tracert command to check the connectivity.
[SwitchA] tracert 1.1.3.1
traceroute to 1.1.3.1(1.1.3.1) 30 hops max,40 bytes packet, press CTRL_C to break
1 1.1.4.2 31 ms 32 ms 31 ms
2 1.1.4.6 62 ms 63 ms 62 ms
Chapter 2 RIP Configuration
& Note:
The term “router” in this document refers to a router in a generic sense or an Ethernet switch running routing protocols.
2.1 RIP Overview
RIP is a simple Interior Gateway Protocol (IGP), which is mainly used in small-size networks, such as academic networks and simple structured LANs, and is not applicable in complex networks.
RIP is still widely used in practical networking due to its simple implementation, and easier configuration and maintenance than OSPF and IS-IS.
2.1.1 RIP Working Mechanism
I. Basic concept of RIP
RIP is a Distance-Vector-based routing protocol, using UDP packets for exchanging information through port 520.
RIP uses a hop count to measure the distance to a destination. The hop count is known as metric. The hop count from a router to its directly connected network is 0. The hop count from one router to a directly connected router is 1. To limit convergence time, the range of RIP metric value is from 0 to 15. It is considered infinite if the value is equal to or larger than 16, which means the destination network is unreachable. That is why RIP is not suitable for large-scaled networks.
RIP prevents routing loops by implementing the split horizon and poison reverse functions.
II. RIP routing table
Each RIP router has a routing table containing routing entries of all reachable destinations, and each routing entry contains:
l Destination address: the IP address of a host or a network.
l Next hop: IP address of the adjacent router’s interface to reach the destination.
l Egress interface: Packet outgoing interface.
l Metric: Cost from the local router to the destination.
l Route time: Time elapsed since the routing entry was last updated. The time is reset to 0 every time the routing entry is updated.
l Route tag: Identifies an external route, used in routing policy to flexibly control routes.
III. RIP timers
RIP employs four timers, Update, Timeout, Suppress, and Garbage-Collect.
l The update timer defines the interval between sending routing updates.
l The timeout timer defines the route aging time. If no update for a route is received after the aging time elapses, the metric of the route is set to 16 in the routing table.
l The suppress timer defines how long a RIP route stays in the suppressed state. When the metric of a route is 16, the route enters the suppressed state. In the suppressed state, only routes which come from the same neighbor and whose metric is less than 16 will be received by the router to replace unreachable routes.
l The garbage-collect timer defines the interval from when the metric of a route becomes 16 to when it is deleted from the routing table. During the Garbage-Collect timer length, RIP advertises the route with the routing metric set to 16. If no update is announced for that route after the Garbage-Collect timer expires, the route will be deleted from the routing table.
IV. RIP initialization and running procedure
The following procedure describes how RIP works.
1) After RIP is enabled, the router sends Request messages to neighboring routers. Neighboring routers return Response messages including all information about their routing tables.
2) The router updates its local routing table, and broadcasts the triggered update messages to its neighbors. All routers on the network do the same to keep the latest routing information.
3) The aged routes are deleted to make sure routes are always valid.
V. Routing loops prevention
RIP is a distance-vector (D-V) based routing protocol. Since a RIP router advertises its own routing table to neighbors, routing loops may occur.
RIP uses the following mechanisms to prevent routing loops.
l Counting to infinity. The metric value of 16 is defined as unreachable. When a routing loop occurs, the accumulated metric value of the route will become 16.
l Split horizon. A router does not send the routing information learned from a neighbor to the neighbor to prevent routing loops and save the bandwidth.
l Poison reverse. A router sets the metric of routes received from a neighbor to 16 and sends back these routes to the neighbor.
l Triggered updates. A router advertises updates once the metric of a route is changed rather than after the update period expires to speed up the network convergence.
2.1.2 RIP Version
RIP has two versions, RIP-1 and RIP-2.
RIP-1, a Classful Routing Protocol, supports message advertisement via broadcast only. RIP-1 protocol messages do not carry mask information, which means it can only recognize routing information of natural networks such as Class A, B, C. That is why RIP-1 does not support discontiguous subnet.
RIP-2 is a Classless Routing Protocol. Compared with RIP-1, RIP-2 has the following advantages.
l Supporting route tags. The route tag is used in routing policies to flexibly control routes.
l Supporting masks, route summarization and classless inter-domain routing (CIDR).
l Supporting designated next hop to select the best next hop on broadcast networks.
l Supporting multicast routing update to reduce resource consumption.
l Supporting Plain text authentication and MD5 authentication to enhance security.
& Note:
RIP-2 has two types of message transmission: broadcast and multicast. Multicast is the default type using 224.0.0.9 as the multicast address. The interface working in the RIP-2 broadcast mode can also receive RIP-1 messages.
2.1.3 RIP Message Format
I. RIP-1 message format
A RIP message consists of the Header and up to 25 route entries.
Figure 2-1 shows the format of RIP-1 message.

Figure 2-1 RIP-1 Message Format
l Command: The type of message. 1 indicates Request, 2 indicates Response.
l Version: The version of RIP, 0x01 for RIP-1.
l AFI: Address Family Identifier, 2 for IP.
l IP Address: Destination IP address of the route. It could be a natural address, subnet address or host address.
l Metric: Cost of the route.
II. RIP-2 message format
The format of RIP-2 message is similar with RIP-1. Figure 2-2 shows it.

Figure 2-2 RIP-2 Message Format
The differences from RIP-1 are stated as following.
l Version: Version of RIP. For RIP-2 the value is 0x02.
l Route Tag: Route Tag.
l IP Address: Destination IP address. It could be a natural address, subnet address or host address.
l Subnet Mask: Mask of the destination address.
l Next Hop: Address of the best next hop. 0.0.0.0 indicates that the originator of the route is the best next hop.
III. RIP-2 authentication
RIP-2 sets the AFI field of the first Route Entry to 0xFFFF for authentication. See Figure 2-3.

Figure 2-3 RIP-2 Authentication Message
l Authentication Type: 2 represents plain text authentication, while 3 represents MD5.
l Authentication: Authentication data, including the password information when plain text authentication is adopted. When MD5 authentication is performed, this field contains the key ID, the length of the MD5 authentication key, and the serial number.
& Note:
RFC 1723 only defines plain text authentication. For information about MD5 authentication, refer to RFC2082 “RIP-2 MD5 Authentication”.
2.1.4 RIP Features Supported
The current implementation supports the following RIP features.
l RIP-1 and RIP-2
l RIP Multi-instance
2.1.5 RIP Related RFC
l RFC 1058: Routing Information Protocol
l RFC 1723: RIP Version 2 - Carrying Additional Information
l RFC 1721: RIP Version 2 Protocol Analysis
l RFC 1722: RIP Version 2 Protocol Applicability Statement
l RFC 1724: RIP Version 2 MIB Extension
l RFC 2082: RIP-2 MD5 Authentication
2.2 Configuring RIP Basic Functions
2.2.1 Configuration Prerequisites
Before configuring RIP features, finish the following tasks.
l Configure the link layer protocol.
l Configure IP address on each interface, and make sure all adjacent routers are reachable with each other.
2.2.2 Configuration Procedure
I. Enable RIP and specify networks
Follow these steps to enable RIP:
|
Use the command… |
Remarks |
|
|
Enter system view |
system-view |
–– |
|
Create a RIP process and enter RIP view |
rip [ process-id ] |
Required By default, no RIP process runs |
|
Enable RIP on a specified network |
network network-address |
Required Disabled by default |
& Note:
l If you make some RIP configurations in interface view before enabling RIP, those configurations will take effect after RIP is enabled.
l The router does not handle any routing information on a non specified network after RIP is enabled.
l You can enable RIP on all interfaces using the command network 0.0.0.0.
II. Configuring the interface behavior
Follow these steps to configure the interface behavior:
|
To do… |
Use the command… |
Remarks |
|
|
Enter system view |
system-view |
–– |
|
|
Enter RIP view |
rip [ process-id ] |
–– |
|
|
Disable an or all interfaces from sending routing updates |
silent-interface { all | interface-type interface-number } |
Optional All interfaces can send routing updates by default |
|
|
Return to system view |
quit |
— |
|
|
Enter interface view |
interface interface-type interface-number |
— |
|
|
Configure the interface to receive or send RIP messages |
Enable the interface to receive RIP messages |
rip input |
Optional Enabled by default |
|
Enable the interface to send RIP messages |
rip output |
Optional Enabled by default |
|
III. Configuring the RIP version
You can configure the RIP version in RIP/interface view.
l When no RIP version is configured on an interface and the global RIP version is RIP-1, the RIP version running on the interface is RIP-1.
l When no RIP version is configured on the interface and the global RIP version is RIP-2, the RIP version running on the interface is RIP-2 and RIP-2 messages are sent in multicast.
l When a RIP version is configured on the interface and inconsistent with the global RIP version, the interface RIP version takes priority over the global one. The global RIP version takes effect only when no RIP version is configured on the interface.
Follow these steps to configure the RIP version:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
–– |
|
Enter RIP view |
rip [ process-id ] |
–– |
|
Specify a global RIP version |
version { 1 | 2 } |
Optional RIP-1 by default |
|
Return to system view |
quit |
— |
|
Enter interface view |
interface interface-type interface-number |
–– |
|
Specify a RIP version |
rip version { 1 | 2 [ broadcast | multicast ] } |
Optional RIP-1 by default |
2.3 Configuring RIP Advanced Functions
In some complex network environments, you need to configure advanced RIP functions.
This section covers the following topics:
l Configuring an Additional Routing Metric
l Configuring RIP Route Summarization
l Enabling/Disabling Host Route Reception
l Advertising a Default Route
l Configuring Inbound and Outbound Route Filtering Policies
l Configuring a Priority for RIP
l Configuring RIP Route Redistribution
Before configuring RIP routing feature, finish the following tasks:
l Configure an IP address for each interface, and make sure all routers are reachable.
l Configure basic RIP functions
2.3.1 Configuring an Additional Routing Metric
An additional routing metric can be added to the metric of an inbound/outbound RIP route, namely, the inbound and outbound additional metric.
The outbound additional metric is added to the metric of a sent route, the route’s metric in the routing table is not changed.
The inbound additional metric is added to the metric of a received route before the route is added into the routing table, so the route’s metric is changed.
Follow these steps to configure additional routing metric:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
–– |
|
Enter interface view |
interface interface-type interface-number |
–– |
|
Define an inbound additional routing metric |
rip metricin value |
Optional 0 by default |
|
Define an outbound additional routing metric |
rip metricout value |
Optional 1 by default |
2.3.2 Configuring RIP-2 Route Summarization
The route summarization means that subnet routes in a natural network segment are summarized into a natural mask route and sent to other network segments. This function can reduce the size of routing tables.
Disable the route summarization function if you want to advertise all subnet routes. In addition, you can configure RIP-2 to advertise a local summary IP address on the specified interface.
I. Configure RIP-2 route automatic summarization
Follow these steps to configure RIP-2 automatic route summarization:
|
Use the command… |
Remarks |
|
|
Enter system view |
system-view |
–– |
|
Enter RIP view |
rip [ process-id ] |
–– |
|
Enable RIP-2 automatic route summarization |
summary |
Required Enabled by default |
II. Advertise a summary route
You can configure RIP-2 to advertise a summary route on the specified interface.
To do so, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
–– |
|
Enter RIP view |
rip [ process-id ] |
–– |
|
Disable RIP-2 automatic route summarization |
undo summary |
Required Enabled by default |
|
Return to system view |
quit |
— |
|
Enter interface view |
interface interface-type interface-number |
— |
|
Configure to advertise a summary route |
rip summary-address ip-address { mask | mask-length } |
Required |
2.3.3 Disabling Host Route Reception
Sometimes a router may receive many host routes from the same network, which are not helpful for routing and occupy a large amount of network resources. In this case, you can disable RIP from receiving host routes to save network resources.
Follow these steps to disable RIP from receiving host routes:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enter RIP view |
rip [ process-id ] |
— |
|
Disable RIP from receiving host routes |
undo host-route |
Required Enabled by default |
2.3.4 Advertising a Default Route
Follow these steps to configure RIP to advertise a default route:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
–– |
|
Enter RIP view |
rip [ process-id ] |
–– |
|
Enable RIP to advertise a default route |
default-route originate cost value |
Required Not enabled by default |
& Note:
The router enabled to advertise a default route does not receive default routes from RIP neighbors.
2.3.5 Configuring Inbound/Outbound Route Filtering Policies
Route filtering is supported by the router. You can filter routes by configuring the inbound or outbound route filtering policies via referencing an ACL and IP prefix list. You can also specify to receive only routes from a specified neighbor.
Follow these steps to configure a routing policy:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
–– |
|
Enter RIP view |
rip [ process-id ] |
–– |
|
Define a filtering policy for received routes |
filter-policy { acl-number | ip-prefix ip-prefix-name [ gateway ip-prefix-name ] | gateway ip-prefix-name } import [ interface-type interface-number ] |
Optional By default, RIP does not filter the received routes. |
|
Define a filtering policy for sent routes |
filter-policy { acl-number | ip-prefix ip-prefix-name } export [ protocol [ process-id ] | interface-type interface-number ] |
Optional By default, RIP does not filter the sent routes. |
2.3.6 Configuring a Priority for RIP
Multiple IGP protocols may run in a router. If you want RIP routes to have a higher priority than those learned from other routing protocols, you should assign RIP a smaller priority value to influence optimal route selection.
Follow these steps to configure a priority for RIP:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
–– |
|
Enter RIP view |
rip [ process-id ] |
–– |
|
Configure a priority for RIP |
preference [ route-policy route-policy-name ] value |
Optional 100 by default |
2.3.7 Configuring RIP Route Redistribution
Follow these steps to configure RIP route redistribution:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
–– |
|
Enter RIP view |
rip [ process-id ] |
–– |
|
Configure a default metric for redistributed routes |
default-cost value |
Optional The default metric of a redistributed route is 0 by default. |
|
Redistribute routes from other protocols or processes |
import-route protocol [ process-id | allow-ibgp ] [ cost cost-value | route-policy route-policy-name | tag tag-value ] * |
Required By default, RIP does not redistribute any other protocol route. |
2.4 Optimizing the RIP Network
This section covers the following topics:
l Configuring RIP Timers
l Configuring Split Horizon and Poison Reverse
l Configuring the Maximum Number of Load Balanced Routes
l Configuring RIP Message Check
l Configuring RIP-2 Message Authentication
l Configuring a RIP Neighbor
l Configuring RIP-to-MIB Binding
Finish the following tasks before configuring the RIP network optimization.
l Configure network addresses on interfaces, and make sure neighboring nodes are reachable
l Configure basic RIP functions.
2.4.1 Configuring RIP Timers
Follow these steps to configure RIP timers:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
–– |
|
Enter RIP view |
rip [ process-id ] |
–– |
|
Configure values for RIP timers |
timers { garbage-collect garbage-collect-value | suppress suppress-value | timeout timeout-value | update update-value } * |
Optional By default, 30s for update timer, 180s for timeout timer, 120s for suppress timer, and 240s for garbage-collect timer |
& Note:
Based on the network performance, you should make RIP timers of RIP routers identical to each other to avoid unnecessary traffic or route oscillation.
2.4.2 Configuring the Split Horizon and Poison Reverse
& Note:
If both the split horizon and poison reverse are configured, only the poison reverse function takes effect.
I. Configure the split horizon
The split horizon function disables an interface from sending routes received by the interface itself, so as to prevent routing loops between adjacent routers.
Follow these steps to configure the split horizon function:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enter interface view |
interface interface-type interface-number |
— |
|
Enable split horizon |
rip split-horizon |
Required Enabled by default |
II. Configure the poison reverse
The poison reverse function allows an interface to advertise the routes received by itself, but the metric of these routes is set to 16, making them unreachable.
Follow these steps to configure the poise reserve function:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enter interface view |
interface interface-type interface-number |
— |
|
Enable the poison reverse function |
rip poison-reverse |
Required Disabled by default |
2.4.3 Configuring the Maximum Number of Load Balanced Routes
Follow these steps to configure the maximum number of load balanced routes:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
–– |
|
Enter RIP view |
rip [ process-id ] |
–– |
|
Configure the maximum number of load balanced routes |
maximum load-balancing number |
Required By default, the maximum number of load balanced routes is 4. |
2.4.4 Configuring RIP Message Check
Some fields in the RIP-1 message must be zero. These fields are called zero fields. You can enable the zero field check on received RIP-1 messages. If any such field contains a non-zero value, the RIP-1 message will not be processed. If you are sure that all messages are trusty, you can disable the zero field check to save the CPU processing time.
In addition, you can enable the source IP address validation on received messages. For the message received on an Ethernet interface, RIP compares the source IP address of the message with the IP address of the interface. If they are not in the same network segment, RIP discards the message.
Follow these steps to configure RIP message check:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
–– |
|
Enter RIP view |
rip [ process-id ] |
–– |
|
Enable the zero field check on received RIP-1 messages |
checkzero |
Optional Enabled by default |
|
Enable the source IP address validation on received RIP messages |
validate-source-address |
Optional Enabled by default |
& Note:
l The zero field check is invalid for RIP-2 messages.
l The source IP address validation should be disabled when a non direct RIP neighbor exists.
2.4.5 Configuring RIP-2 Message Authentication
RIP-2 supports two authentication modes: plain text and MD5.
In plain text authentication, the authentication information is sent with the RIP message, which cannot meet high security needs.
Follow these steps to configure RIP-2 message authentication:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
–– |
|
Enter interface view |
interface interface-type interface-number |
–– |
|
Configure RIP-2 authentication mode |
rip authentication-mode { md5 { rfc2082 key-string key-id | rfc2453 key-string } | simple password } |
Required |
2.4.6 Configuring a RIP Neighbor
Usually, RIP sends messages to broadcast or multicast addresses. On non broadcast or multicast links, you need to manually specify a RIP neighbor. If the specified neighbor is not directly connected, you must disable the source address check on update messages.
Follow these steps to configure a RIP neighbor:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
–– |
|
Enter RIP view |
rip [ process-id ] |
–– |
|
Specify a RIP neighbor |
peer ip-address |
Required |
|
Disable source address check on received RIP update messages |
undo validate-source-address |
Required Not disabled by default |
2.4.7 Configuring RIP-to-MIB Binding
Follow these steps to bind RIP to MIB:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
–– |
|
Bind RIP to MIB |
rip mib-binding process-id |
Optional By default, MIB is bound to the RIP process with the smallest process ID |
2.5 Displaying and Maintaining RIP
|
Use the command… |
Remarks |
|
|
Display RIP current status and configuration information |
display rip [ process-id ] |
Available in any view |
|
Display all active routes in RIP database |
display rip process-id database |
|
|
Display RIP interface information |
display rip process-id interface [ interface-type interface-number ] |
|
|
Display routing information about a specified RIP process |
display rip process-id route [ statistics | ip-address { mask | mask-length } | peer ip-address ] |
|
|
Clear the statistics of a RIP process |
reset rip process-id statistics |
Available in user view |
2.6 RIP Configuration Example
2.6.1 Configuring RIP Version
I. Network requirements
As shown in Figure 2-4, enable RIP-2 on all interfaces on Switch A and Switch B.
II. Network diagram

Figure 2-4 Network diagram for RIP configuration
III. Configuration procedure
1) Configure an IP address for each interface (Omitted)
2) Configure basic RIP functions
# Configure Switch A.
<SwitchA> system-view
[SwitchA] rip
[SwitchA-rip-1] network 192.168.1.0
[SwitchA-rip-1] network 172.16.0.0
[SwitchA-rip-1] network 172.17.0.0
[SwitchA-rip-1] quit
# Configure Switch B.
<SwitchB> system-view
[SwitchB] rip
[SwitchB-rip-1] network 192.168.1.0
[SwitchB-rip-1] network 10.0.0.0
[SwitchB-rip-1] quit
# Display the RIP routing table of Switch A.
<SwitchA> display rip 1 route
Route Flags: R - RIP, T - TRIP
P - Permanent, A - Aging, S - Suppressed, G - Garbage-collect
-------------------------------------------------------------------------
Peer 192.168.1.2 on Vlan-interface100
Destination/Mask Nexthop Cost Tag Flags Sec
10.0.0.0/8 192.168.1.2 1 0 RA 27
From the routing table, you can find RIP-1 uses natural mask.
3) Configure RIP version
# Configure RIP-2 on Switch A.
[SwitchA] rip
[SwitchA-rip-1] version 2
[SwitchA-rip-1] undo summary
[SwitchA-rip-1] quit
# Configure RIP-2 on Switch B.
[SwitchB] rip
[SwitchB-rip-1] version 2
[SwitchB-rip-1] undo summary
[SwitchB-rip-1] quit
# Display the RIP routing table on Switch A.
<SwitchA>display rip 1 route
Route Flags: R - RIP, T - TRIP
P - Permanent, A - Aging, S - Suppressed, G - Garbage-collect
-------------------------------------------------------------------------
Peer 192.168.1.2 on Vlan-interface100
Destination/Mask Nexthop Cost Tag Flags Sec
10.2.1.0/24 192.168.1.2 1 0 RA 15
10.1.1.0/24 192.168.1.2 1 0 RA 15
From the routing table, you can see RIP-2 uses classless subnet mask.
& Note:
Since RIP-1 routing information has a long aging time, it will still exist until aged out after RIP-2 is configured.
2.6.2 Configuring RIP Route Redistribution
I. Network requirements
As shown in Figure 2-5, two RIP processes are running on Switch B, which communicates with Switch A through RIP100 and with Switch C through RIP 200.
Configure route redistribution on Switch B, letting the two RIP processes redistribute routes from each other. Set the cost of redistributed routes from RIP 200 to 3. Configure a filtering policy on Switch B to filter out the route 192.168.4.0/24 from RIP200, making the route not advertised to Switch A.
II. Network diagram

Figure 2-5 Network diagram for RIP route redistribution
III. Configuration procesure
1) Configure an IP address for each interface (Omitted).
2) Configure basic RIP functions.
# Enable RIP 100 on Switch A.
<SwitchA> system-view
[SwitchA] rip 100
[SwitchA-rip-100] network 192.168.0.0
[SwitchA-rip-100] network 192.168.1.0
[SwitchA-rip-100] quit
# Enable RIP 100 and RIP 200 on Switch B.
<SwitchB> system-view
[SwitchB] rip 100
[SwitchB-rip-100] network 192.168.1.0
[SwitchB-rip-100] quit
[SwitchB] rip 200
[SwitchB-rip-200] network 192.168.2.0
[SwitchB-rip-200] quit
# Enable RIP 200 on Switch C.
<SwitchC> system-view
[SwitchC] rip 200
[SwitchC-rip-200] network 192.168.2.0
[SwitchC-rip-200] network 192.168.3.0
[SwitchC-rip-200] network 192.168.4.0
[SwitchC-rip-200] quit
# Display the routing table of Switch A.
[SwitchA] display ip routing-table
Routing Tables: Public
Destinations : 7 Routes : 7
Destination/Mask Proto Pre Cost NextHop Interface
127.0.0.0/8 Direct 0 0 127.0.0.1 InLoopBack0
127.0.0.1/32 Direct 0 0 127.0.0.1 InLoopBack0
192.168.0.0/24 Direct 0 0 192.168.0.1 vlan-interface101
192.168.0.1/32 Direct 0 0 127.0.0.1 InLoopBack0
192.168.1.0/24 Direct 0 0 192.168.1.1 Vlan-interface100
192.168.1.1/32 Direct 0 0 127.0.0.1 InLoopBack0
192.168.1.2/32 Direct 0 0 192.168.1.2 Vlan-interface100
3) Configure route redistribution
# Configure route redistribution between the two RIP processes on Switch B.
[SwitchB] rip 100
[SwitchB-rip-100] default cost 3
[SwitchB-rip-100] import-route rip 200
[SwitchB-rip-100] quit
[SwitchB] rip 200
[SwitchB-rip-200] import-route rip 100
[SwitchB-rip-200] quit
# Display the routing table of Switch A.
[SwitchA] display ip routing-table
Routing Tables: Public
Destinations : 10 Routes : 10
Destination/Mask Proto Pre Cost NextHop Interface
127.0.0.0/8 Direct 0 0 127.0.0.1 InLoopBack0
127.0.0.1/32 Direct 0 0 127.0.0.1 InLoopBack0
192.168.0.0/24 Direct 0 0 192.168.0.1 Vlan-interface101
192.168.0.1/32 Direct 0 0 127.0.0.1 InLoopBack0
192.168.1.0/24 Direct 0 0 192.168.1.1 Vlan-interface100
192.168.1.1/32 Direct 0 0 127.0.0.1 InLoopBack0
192.168.1.2/32 Direct 0 0 192.168.1.2 Vlan-interface100
192.168.2.0/24 RIP 100 4 192.168.1.2 Vlan-interface100
192.168.3.0/24 RIP 100 4 192.168.1.2 Vlan-interface100
192.168.4.0/24 RIP 100 4 192.168.1.2 Vlan-interface100
4) Configure an filtering policy to filter redistributed routes
# Define ACL2000 and reference it to a filtering policy to filter routes redistributed from RIP 200 on Switch B.
[SwitchB] acl number 2000
[SwitchB-acl-basic-2000] rule deny source 192.168.4.0 0.0.0.255
[SwitchB-acl-basic-2000] rule permit
[SwitchB-acl-basic-2000] quit
[SwitchB] rip 100
[SwitchB-rip-100] filter-policy 2000 export rip 200
[SwitchB-rip-100] quit
# Display the routing table of Switch A.
[SwitchA] display ip routing-table
Routing Tables: Public
Destinations : 9 Routes : 9
Destination/Mask Proto Pre Cost NextHop Interface
127.0.0.0/8 Direct 0 0 127.0.0.1 InLoopBack0
127.0.0.1/32 Direct 0 0 127.0.0.1 InLoopBack0
192.168.0.0/24 Direct 0 0 192.168.0.1 Vlan-interface101
192.168.0.1/32 Direct 0 0 127.0.0.1 InLoopBack0
192.168.1.0/24 Direct 0 0 192.168.1.1 Vlan-interface100
192.168.1.1/32 Direct 0 0 127.0.0.1 InLoopBack0
192.168.1.2/32 Direct 0 0 192.168.1.2 Vlan-interface100
192.168.2.0/24 RIP 100 4 192.168.1.2 Vlan-interface100
192.168.3.0/24 RIP 100 4 192.168.1.2 Vlan-interface100
2.7 Troubleshooting RIP Configuration
2.7.1 No RIP Updates Received
Symptom:
No RIP updates are received when the links work well.
Analysis:
After enabling RIP, you must use the network command to enable corresponding interfaces. Make sure no interfaces are disabled from handling RIP messages.
If the peer is configured to send multicast messages, the same should be configured on the local end.
Solution:
l Use the display current-configuration command to check RIP configuration
l Use the display rip command to check whether some interface is disabled
2.7.2 Route Oscillation Occurred
Symptom:
When all links work well, route oscillation occurs on the RIP network. After displaying the routing table, you may find some routes appear and disappear in the routing table intermittently.
Analysis:
In the RIP network, make sure all the same timers within the whole network are identical and relationships between timers are reasonable. For example, the timeout timer value should be larger than the update timer value.
Solution:
l Use the display rip command to check the configuration of RIP timers
l Use the timers command to adjust timers properly.
Chapter 3 OSPF Configuration
& Note:
l The term “router” or a router icon used throughout this document represents a generic router or an Ethernet switch running routing protocols.
l OSPF indicates OSPFv2 throughout this document.
3.1 Introduction to OSPF
OSPF has the following features:
l Scope: Supports networks of various sizes and can support several hundred routers
l Fast convergence: Transmits update packets instantly after network topology changes for routing information synchronization in the AS
l Loop-free: Computes routes with the Shortest Path Tree algorithm according to the collected link states so no loop routes are generated from the algorithm itself
l Area partition: Allows an AS to be split into different areas for ease of management and the routing information transmitted between areas is summarized to reduce network bandwidth consumption
l Equal-cost multi-route: Supports multiple equal-cost routes to a destination
l Routing hierarchy: Supports a four-level routing hierarchy that prioritizes the routes into intra-area, inter-area, external type-1, and external type-2 routes
l Authentication: Supports interface-based packet authentication to guarantee the security of packet exchange
l Multicast: Supports packet multicasting via some types of links
3.1.1 Basic Concepts
I. OSPF route computation
OSPF route computation is described as follows:
l Based on the network topology around itself, each router generates Link State Advertisements (LSA) and sends them to other routers in update packets.
l Each OSPF router collects LSAs from other routers to compose a LSDB (Link State Database). An LSA describes the network topology around a router, so the LSDB describes the entire network topology of the AS.
l Each router transforms the LSDB to a weighted directed graph, which actually reflects the topology architecture of the entire network. All the routers have the same graph.
l Each router uses the SPF algorithm to compute a Shortest Path Tree that shows the routes to the nodes in the autonomous system. The router itself is the root of the tree.
II. Router ID
To run OSPF, a router must have a Router ID, which is a 32-bit unsigned integer, the unique identifier of the router in the AS.
You may assign a Router ID to an OSPF router manually. If no Router ID is specified, the system automatically selects one for the router as follows:
l If the loopback interface addresses are available, select the highest IP address among them.
l If no loopback interface is configured, select the highest IP address among addresses of interfaces on the router.
III. OSPF packets
OSPF uses five types of packets:
l Hello Packet: Periodically sent to find and maintain neighbors, containing the values of some timers, information about DR, BDR and known neighbors
l DD packet (Database Description Packet): Describes the digest of each LSA in the LSDB, exchanged between two routers for data synchronization
l LSR (Link State Request) Packet: Requires needed LSAs from the peer. After exchanging the DD packets, the two routers know which LSAs of the neighbor routers are missing from the local LSDBs. In this case, they send LSR packets, requesting the missing LSAs. The packets contain the digests of the missing LSAs.
l LSU (Link State Update) Packet: Transmits the needed LSAs to the peer router
l LSAck (Link State Acknowledgment) Packet: Acknowledges received LSU packets. It contains the Headers of LSAs requiring acknowledgement (a packet can acknowledge multiple LSAs).
IV. LSA types
OSPF sends routing information in LSAs, which as defined in RFC 2328 have the following types:
l Router LSA: Type-1 LSA, Originated by all routers. This LSA describes the collected states of the router's interfaces to an area. Flooded throughout a single area only.
l Network LSA: Type-2 LSA, originated for broadcast and NBMA networks by the Designated Router. This LSA contains the list of routers connected to the network. Flooded throughout a single area only.
l Network Summary LSA: Type-3 LSA, originated by ABRs (Area Border Routers), and flooded throughout the LSA's associated area. Each summary-LSA describes a route to a destination outside the area, yet still inside the AS (an inter-area route).
l ASBR Summary LSA: Type-4 LSA, originated by ABRs and flooded throughout the LSA's associated area. Type 4 summary-LSAs describe routes to ASBR (Autonomous System Boundary Router).
l AS External LSA: Type-5 LSA, originated by ASBRs, and flooded throughout the AS (except Stub and NSSA areas). Each AS-external-LSA describes a route to another Autonomous System.
l NSSA LSA: Type-7 LSA, as defined in RFC 1587, originated by ASBRs in NSSAs (Not-So-Stubby Areas) and flooded throughout a single NSSA. NSSA LSAs describe routes to other ASs.
V. Neighbor and Adjacency
In OSPF, the “Neighbor” and”Adjacency” convey two different concepts.
Neighbor: Two routers that have interfaces to a common network. Neighbor relationships are maintained by, and usually dynamically discovered by, OSPF's Hello packets. When a router starts, it sends a hello packet via the OSPF interface, and the router that receives the hello packet checks parameters carried in the packet. If parameters of the two routers match, they become neighbors.
Adjacency : A relationship formed between selected neighboring routers for the purpose of exchanging routing information. Not every pair of neighboring routers become adjacent, which depends on network types. Only by synchronizing the LSDB via exchanging DD packets and LSAs can two routers become adjacent.
3.1.2 OSPF Area and Route Summarization
I. Area partition
When a large number of OSPF routers are present on a network, LSDBs may become so large that a great amount of storage room is occupied and CPU resources are exhausted performing SPF computation.
In addition, as the topology of a large network is prone to changes, enormous amount of OSPF packets may be created, reducing bandwidth utilization. Each topology change makes all routers perform route calculation.
To solve this problem, OSPF splits an AS into multiple areas, which are identified by area IDs. The boundaries between areas are routers rather than links. A network segment (or a link) can only reside in one area, in other words, an OSPF interface must be specified to belong to its attached area, as shown in figure below.

Figure 3-1 OSPF areas
After area partition, area border routers perform route summarization to reduce the number of LSAs informed to other areas and minimize the effect of topology changes.
II. Classification of Routers
The OSPF router falls into four types according to the position in the AS:
1) Internal Router
All interfaces on an internal router belong to one OSPF area.
2) Area Border Router (ABR)
An area border router belongs to more than two areas, one of which must be the backbone area. It connects the backbone area to a non-backbone area. The connection between an area border router and the backbone area can be physical or logical.
3) Backbone Router
At least one interface of a backbone router must be attached to the backbone area. Therefore, all ABRs and internal routers in area 0 are backbone routers.
4) Autonomous System Border Router (ASBR)
The router exchanging routing information with another AS is an ASBR, which may not reside on the boundary of the AS. It can be an internal router or area border router.

Figure 3-2 OSPF router types
III. Backbone area and virtual links
The AS has a unique area called backbone area, which is responsible for distributing routing information between none-backbone areas. Routing information between non-backbone areas must be forwarded by the backbone area. Therefore, OSPF requires:
l All non-backbone areas must maintain connectivity to the backbone area.
l The backbone area itself must maintain connectivity.
In practice, due to physical limitations, the requirements may not be satisfied. In this case, configuring OSPF virtual links is a solution.
A virtual link is established between two area border routers via a non-backbone area and is configured on both ABRs to take effect. The area that provides the non-backbone area internal route for the virtual link is called transit area.
In the following figure, Area 2 has no direct physical link to the backbone area 0. Configuring a virtual link between ABRs can connect Area 2 to the backbone area.

Figure 3-3 Virtual link application 1
Another application of virtual links is to provide redundant links. If the backbone area cannot maintain internal connectivity due to physical link failure, configuring a virtual link can guarantee logical connectivity in the backbone area, as shown below.

Figure 3-4 Virtual link application 2
The virtual link between the two ABRs acts as a point-to-point connection. Therefore, you can configure interface parameters such as Hello packet interval on the virtual link as they are configured on physical interfaces.
The two ABRs on the virtual link exchange OSPF packets with each other directly, the OSPF routers in between simply convey these OSPF packets as normal IP packets.
IV. Stub area
Stub areas are special areas. The ABR in this area do not distribute AS external routes into the area, so the routing table scale and amount of routing information in this area are reduced significantly.
Stub area configuration is optional, and not every area is qualified to be a stub area. In general, a stub area resides on the border of the AS and is a none-backbone area with only one ABR.
The ABR in a stub area can generate a default route into the area.
Note the following when configuring a stub area:
l A backbone area cannot be a stub area
l The stub command must be configured on routers in a stub area
l A stub area cannot have an ASBR because AS external routes cannot be distributed into the stub area.
l Virtual links cannot transit stub areas.
V. NSSA area
Similar to a stub area, an NSSA area imports no AS external LSA (type5 LSA) but can import type7 LSAs that are generated by the ASBR and distributed throughout the NSSA area. When traveling to the NSSA ABR, type7 LSAs are translated into type5 LSAs by the ABR for advertisement to other areas.
In the following figure, the OSPF AS contains three areas: Area 1, Area 2 and Area 0. The other two ASs employ the RIP protocol. Area 1 is an NSSA area, and the ASBR in it translates RIP routes into type7 LSAs and advertises them throughout Area 1. When these LSAs travel to the NSSA ABR, the ABR translates type7 LSAs to type5 LSAs for advertisement to Area 0 and Area 2.
On the left of the figure, RIP routes are translated into type5 LSAs by the ASBR of Area 2 and distributed into the OSPF AS. However, Area 1 is an NSSA area, so these type5 LSAs cannot travel to Area 1.
Similar to stub areas, virtual links cannot transit NSSA areas.

Figure 3-5 NSSA area application
VI. Route summarization
Route summarization: An ABR or ASBR summarizes routes with the same prefix with a single route and distribute it to other areas.
Via route summarization, routing information between areas and the size of routing tables on routers will be reduced, improving calculation speed of routers.
For example, as shown in the following figure, in Area 19 are three internal routes 19.1.1.0/24, 19.1.2.0/24, and 19.1.3.0/24. By configuring route summarization on the R1, the three routes are summarized with the route 19.1.0.0/16 that is advertised into Area 0.

Figure 3-6 Route summarization
OSPF has two types of route summarization:
1) ABR route summarization
To distribute routing information to other areas, an ABR generates type3 LSAs on a per network segment basis for an attached non-backbone area. If contiguous network segments are available in the area, you can use the abr-summary command to summarize them with a single network segment. The ABR in the area distributes only the summarized LSA to reduce the scale of LSDBs on routers in other areas.
2) ASBR route summarization
If redistribution route summarization is configured on an ASBR, it will summarize redistributed type5 LSAs that fall into the specified address range. If the area is NSSA, it also summarizes type7 LSAs that fall into the specified address range.
If this feature is configured an ABR, it summarizes type5 LSAs translated from type7 LSAs.
VII. Route types
OSPF prioritize routes into four levels:
l Inra-area route
l Inter-area route
l type1 external route
l type2 external route
The intra-area and inter-area routes describe the network topology of the AS, while external routes describe routes to destinations outside the AS. OSPF classifies external routes into two types: type1 and type2.
A type1 external route is an IGP route, such as a RIP or static route, which has high credibility and whose cost is comparable with the cost of an OSPF internal route. The cost from a router to the destination of the type1 external route= the cost from the router to the corresponding ASBR+ the cost from the ASBR to the destination of the external route.
A type2 external route is an EGP route, which has low credibility, so OSPF considers the cost from the ASBR to the destination of the type2 external route is much bigger than the cost from the ASBR to an OSPF internal router. Therefore, the cost from the internal router to the destination of the type2 external route= the cost from the ASBR to the destination of the type2 external route. If two routes to the same destination have the same cost, then take the cost from the router to the ASBR into consideration.
3.1.3 Classification of OSPF Networks
I. OSPF network types
OSPF classifies networks into four types upon the link layer protocol:
l Broadcast: when the link layer protocol is Ethernet or FDDI, OSPF considers the network type broadcast by default. On Broadcast networks, packets are sent to multicast addresses (such as 224.0.0.5 and 224.0.0.6).
l NBMA (Non-Broadcast Multi-Access): when the link layer protocol is Frame Relay, ATM or X.25, OSPF considers the network type as NBMA by default. Packets on these networks are sent to unicast addresses.
l P2MP (point-to-multipoint): by default, OSPF considers no link layer protocol as P2MP, which is a conversion from other network types such as NBMA in general. On P2MP networks, packets are sent to multicast addresses (224.0.0.5).
l P2P (point-to-point): when the link layer protocol is PPP or HDLC, OSPF considers the network type as P2P. On P2P networks, packets are sent to multicast addresses (224.0.0.5).
II. NBMA network configuration principle
Typical NBMA networks are ATM and Frame Relay networks.
You need to perform some special configuration on NBMA interfaces. Since these interfaces cannot broadcast hello packets for neighbor location, you need to specify IP addresses of neighbors manually and configure whether neighbors have DR election right on these interfaces.
An NBMA network is fully meshed, which means any two routers in the NBMA network have a direct virtual link for communication. If direct connections are not available between some routers, the type of interfaces associated should be configured as P2MP, or as P2P for interfaces with only one neighbor.
Differences between NBMA and P2MP networks:
l NBMA networks are fully meshed, non-broadcast and multi access. P2MP networks are not required to be fully meshed.
l It is required to elect the DR and BDR on NBMA networks, while DR and BDR are not available on P2MP networks.
l NBMA is the default network type, while P2MP is a conversion from other network types such as NBMA in general.
l On NBMA networks, packets are unicast, and neighbors are configured manually on routers. On P2MP networks, packets are multicast.
III. DR and BDR
On broadcast or NBMA networks, any two routers exchange routing information with each other. If n routers are present on a network, n(n-1)/2 adjacencies are required. Any change on a router in the network generates traffic for routing information synchronization, consuming network resources. The Designated Router is defined to solve the problem. All other routers on the network send routing information to the DR, which is responsible for advertising link state information.
If the DR fails to work, routers on the network have to elect another DR and synchronize information with the new DR. It is time-consuming and prone to routing calculation errors. The Backup Designated Router (BDR) was introduced to reduce the synchronization period.
The BDR is elected along with the DR and establishes adjacencies for routing information exchange with all other routers. When the DR fails, the BDR will become the new DR in a very short period by avoiding adjacency establishment and DR reelection. Meanwhile, other routers elect another BDR, which requires a relatively long period but has no influence on routing calculation.
Other routers, also known as DRothers, except the DR and BDR establish no adjacency with each other and exchange no routing information, thus, reducing the number of adjacencies on broadcast and NBMA networks.
In the following figure, real lines are Ethernet physical links, and dashed lines represent adjacencies. With the DR and BDR in the network, only seven adjacencies are enough.

Figure 3-7 DR and BDR in a network
IV. DR/BDR election
The DR and BDR in a network are elected by all routers rather than configured manually. The DR priority of a router’s interface attached to the network determines its qualification for DR/BDR election. Interfaces in the network having priorities higher than ‘0” are election candidates.
The election votes are Hello packets. Each router sends the DR elected by itself in a Hello packet to all other routers. If two routers on the network declare themselves as the DR, the router with the higher DR priority wins. If DR priorities are the same, the router with the bigger Router ID wins. In addition, a router with the priority 0 cannot become the DR/BDR.
Note that:
l The DR election is available on broadcast, NBMA interfaces rather than P2P, or P2MP interfaces.
l A DR is an interface of a router and belongs to a single network segment. The router’s other interfaces may be a BDR or DRother.
l After DR/BDR election and then a new router joins, it cannot become the DR immediately even if it has the highest priority on the network.
l The DR may not be the router with the highest priority in a network, and the BDR may not be the router with the second highest priority.
3.1.4 OSPF Packet Formats
OSPF packets are directly encapsulated into IP packets. OSPF has the IP protocol number 89. The OSPF packet format, taking a LSU packet as an example, is shown below.
![]()
Figure 3-8 OSPF packet format
I. OSPF packet header
OSPF packets are classified into five types that have the same packet header, as shown below.

Figure 3-9 OSPF packet header
Major fields in this header:
l Version: OSPF version number, which is 2 for OSPFv2.
l type: OSPF packet type from 1 to 5, corresponding with Hello, DD, LSR, LSU and LSAck respectively.
l Packet length: Total length of the OSPF packet in bytes, including the header
l Autype: Authentication type from 0 to 2, corresponding with non-authentication, simple (plaintext) authentication and MD5 authentication respectively.
l Authentication: Information determined by authentication type, which is not defined for authentication type 0, password information for authentication type 1, information about Key ID, MD5 authentication data length and sequence number for authentication type 2.
& Note:
MD5 authentication data is added following an OSPF packet rather than contained in the Authentication field.
II. Hello packet
As one of the most common OSPF packets, Hello packets are sent to neighbors by a router, including information about values of timers, DR, BDR and neighbors already known. The format is shown below:

Figure 3-10 Hello packet format
Major fields:
l Network Mask: The network mask associated with the router’s sending interface. If two routers have different network masks, they cannot become neighbors.
l HelloInterval: The interval between the router’s Hello packets. If two routers have different intervals, they cannot become neighbors.
l Rtr Pri: DR priority, a value of 0 for which means the router cannot become the DR/BDR.
l RouterDeadInterval: The time value before declaring a silent router down. If two routers have different time values of this kind, they cannot become neighbors.
l Neighbor: Router ID of the neighbor router.
III. DD packet
Two routers exchange Database Description (DD) packets describing their LSDBs for database synchronization, contents in DD packets including the header of each LSA (uniquely representing a LSA). The LSA header occupies small part of an LSA, so reducing traffic between routers. The recipient checks whether the LSA is available using the LSA header.
The DD packet format:

Figure 3-11 DD packet format
Major fields:
l Interface MTU: The size in bytes of the largest IP datagram that can be sent out the associated interface, without fragmentation.
l I (Initial) The Init bit, which is set to 1 if the packet is the first packet in the sequence of Database Description Packets, and set to 0 if not.
l M (More) : The More bit, which is set to 0 if the packet is the last packet in the sequence of DD packets, and set to 1 if more DD Packets are to follow.
l MS (Master/Slave) : The Master/Slave bit. When set to 1, it indicates that the router is the master during the Database Exchange process. Otherwise, the router is the slave.
l DD Sequence Number: Used to sequence the collection of Database Description Packets for ensuring reliability and intactness of DD packets between the master and slave. The initial value is set by the master. The DD sequence number then increments until the complete database description has been sent.
IV. LSR packet
After exchanging DD packets, any two routers know which LSAs of the peer routers are missing from the local LSDBs. In this case, they send LSR (Link State Request) packets, requesting the missing LSAs. The packets contain the digests of the missing LSAs. Figure 3-12shows the LSR packet format.

Major fields:
l LS type: The type number of the LSA to be requested, type 1 for example indicates the Router LSA
l Link State ID: Determined by LSA type
l Advertising Router: The ID of the router that sent the LSA
V. LSU packet
LSU (Link State Update) packets are used to send the requested LSAs to peers, and each packet carries a collection of LSAs. The LSU packet format is shown below.

Figure 3-13 LSU packet format
VI. LSAck packet
LSAack (Link State Acknowledgment) packets are used to acknowledge received LSU packets, contents including LSA headers to describe the corresponding LSAs. Multiple LSAs can be acknowledged in a single Link State Acknowledgment packet. The following figure gives its format.

Figure 3-14 LSAck packet format
VII. LSA header format
All LSAs have the same header, as shown in the following figure.

Figure 3-15 LSA header format
Major fields:
l LS age: The time in seconds elapsed since the LSA was originated. A LSA ages in the LSDB (added 1 per second), but does not in transmission.
l LS type: The type of the LSA
l Link State ID: The contents of this field depend on the LSA's type
l LS sequence number: Used by other routers to judge new and old LSAs.
l length: The length in bytes of the LSA, including the LSA header
VIII. Formats of LSAs
1) Router LSA

Figure 3-16 Router LSA format
Major fields:
l Link State ID: The ID of the router that originated the LSA
l V (Virtual Link): Set to 1 if the router that originated the LSA is a virtual link endpoint.
l E (External): Set to 1 if the router that originated the LSA is an ASBR.
l B (Border): Set to 1 if the router that originated the LSA is an ABR.
l # links: The number of router links (interfaces) to the area, described in the LSA.
l Link ID: Determined by Link type
l Link Data: Determined by Link type
l Type: Link type
l #TOS: The number of different TOS metrics given for this link
l metric: The cost of using this router link
l TOS: IP Type of Service that this metric refers to
l TOS metric: TOS-specific metric information
2) Network LSA
A Network LSA is originated by the DR on a broadcast or NBMA network. The LSA describes all routers attached to the network.

Figure 3-17 Network LSA format
Major fields:
l Link State ID: The interface address of the DR
l Network Mask: The mask of the network (a broadcast or NBMA network)
l Attached Router: The IDs of the routers, which are adjacent to the DR, including the DR itself
3) Summary LSA
Network summary LSAs (type3 LSAs) and ASBR summary LSAs (type4 LSAs) are originated by ABRs. Other than the difference in the Link State ID field, the format of type 3 and 4 summary-LSAs is identical.

Figure 3-18 Summary LSA format
Major fields:
l Link State ID: For a type3 LSA, it is an IP address outside the area; for a type 4 LSA, it is the router ID of an ASBR outside the area.
l Network Mask: The network mask for the type 3 LSA; set to 0.0.0.0 for the type4 LSA
l metric: The metric to the destination
& Note:
A type3 LSA can be used to advertise a default route, having the Link State ID and Network Mask set to 0.0.0.0.
4) AS external LSA
An AS external LSA originates from an ASBR, describing routing information to a destination outside the AS.

Major fields:
l Link State ID: The IP address of another AS to be advertised. When describing a default route, the Link State ID is always set to Default Destination (0.0.0.0) and the Network Mask is set to 0.0.0.0
l Network Mask: The IP address mask for the advertised destination
l E (External Metric): The type of the external metric value, which is set to 1 for type 2 external routes, and set to 0 for type 1 external routes. Refer to Route types for description about external route types
l metric: The metric to the destination
l Forwarding Address: Data traffic for the advertised destination will be forwarded to this address
l External Route Tag: A tag attached to each external route. This is not used by the OSPF protocol itself. It may be used to manage external routes.
5) NSSA external LSA
An NSSA external LSA originates from the ASBR in a NSSA and is flooded in the NSSA area only. It has the same format with the AS external LSA.

Figure 3-20 NSSA external LSA format
3.1.5 OSPF Features Supported
I. Multi-process
With multi-process support, multiple OSPF processes can run on a router simultaneously and independently. Routing information interactions between different processes seem like interactions between different routing protocols. Multiple OSPF processes can use the same RID.
An interface of a router can only belong to a single OSPF process.
II. Authentication
OSPF supports authentication on packets. Only packets that passed the authentication are received. If hello packets cannot pass authentication, no neighbor relationship can be established.
The authentication type for interfaces attached to a single area must be identical. Authentication types include non-authentication, plaintext authentication and MD5 ciphertext authentication. The authentication password for interfaces attached to a network segment must be identical.
3.1.6 Related RFCs
l RFC 1765:OSPF Database Overflow
l RFC 2328: OSPF Version 2
l RFC 3101: OSPF Not-So-Stubby Area (NSSA) Option
l RFC 3137: OSPF Stub Router Advertisement
l RFC 3630: Traffic Engineering Extensions to OSPF Version 2
3.2 OSPF Configuration Task List
To configure OSPF, perform the tasks described in the following sections:
|
Task |
Description |
|
|
Required |
||
|
Optional |
||
|
Optional |
||
|
Optional |
||
|
Optional |
||
|
Optional |
||
|
Optional |
||
|
Optional |
||
|
Optional |
||
|
Optional |
||
|
Optional |
||
|
Optional |
||
|
Optional |
||
|
Optional |
||
|
Optional |
||
|
Optional |
||
|
Optional |
||
|
Optional |
||
|
Optional |
||
|
Optional |
||
|
Optional |
||
|
Optional |
||
|
Optional |
||
|
Making External Route Selection Rules Defined in RFC1583 Compatible |
Optional |
|
|
Optional |
||
3.3 Configuring OSPF Basic Functions
You need to enable OSPF, specify an interface and area ID first before performing other tasks.
3.3.1 Prerequisites
Before configuring OSPF, you have configured the link layer protocol, and IP addresses for interfaces, making neighboring nodes accessible with each other at the network layer.
3.3.2 Configuration Procedure
To ensure OSPF stability, you need to decide on IDs for routers and configure them manually. Any two routers in an AS must have different IDs. In practice, the ID of a router is the IP address of its interface.
OSPF supports multi-process. When a router runs multiple OSPF processes, you need to specify an ID for each process, which takes effect locally and has no interference with packet exchange between routers. Therefore, two routers having different process IDs can exchange packets.
Configurations on routers in an area are performed on the area basis. Wrong configurations may cause communication failure, even routing information block or routing loops between neighboring routers.
To configure OSPF basic functions, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enable OSPF and enter its view |
ospf [ process-id | router-id router-id ]* |
Required Not enabled by default |
|
Configure OSPF process description |
description description |
Optional Not configured by default |
|
Configure an OSPF area and enter OSPF area view |
area area-id |
Required Not configured by default |
|
Configure area description |
description description |
Optional Not configured by default |
|
configure an interface falling into the specified network segment to run OSPF and to belong to the current area |
network ip-address wildcard-mask |
Required Not configure by default |
& Note:
l An OSPF process ID is unique.
l A network segment can only belong to one area to attach an interface to the area.
l It is recommended to configure description for each OSPF process and area to help identify purposes of processes and for ease of management and memorization.
l It is recommended to configure description for each area to help identify purposes of areas and for ease of management and memorization.
3.4 Configuring OSPF Area Parameters
Splitting an OSPF AS into multiple areas reduces the number of LSAs on networks and extends OSPF application. For those non-backbone areas residing on the AS boundary, you can configure them as Stub areas to further reduce the size of routing tables on routers in these areas and the number of LSAs.
A stub area cannot redistribute routes, thus introducing the concept of NSSA, where type 7 LSAs (NSSA External LSAs) are advertised. Type 7 LSAs originate from the ASBR in a NSSA area. When arriving at the ABR in the NSSA area, these LSAs will be translated into type 5 LSAs for advertisement to other areas.
Non-backbone areas exchange routing information via the backbone area. Therefore, the backbone and non-backbone areas, including the backbone itself must maintain connectivity.
If necessary physical links are not available for this connectivity maintenance, you can configure virtual links to solve it.
3.4.1 Prerequisites
Before configuring an OSPF area, you have configured:
l IP addresses for interfaces, making neighboring nodes accessible with each other at network layer.
l OSPF basic functions
3.4.2 Configuration Procedure
To configure OSPF area parameters, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enter OSPF view |
ospf [ process-id | router-id router-id ]* |
— |
|
Enter area view |
area area-id |
— |
|
Configure the area as a stub area |
stub [ no-summary ] |
Optional Not configured by default |
|
Configure the area as an NSSA area |
nssa [ default-route-advertise | no-import-route | no-summary ]* |
Optional Not configured by default |
|
Configure the default route cost of sending packets to the stub or NSSA area |
default-cost cost |
Optional Configured on an ABR only Defaults to 1 |
|
Create and configure a virtual link |
vlink-peer router-id [ hello seconds | retransmit seconds | trans-delay seconds | dead seconds | simple [ plain | cipher ] password | { md5 | hmac-md5 } key-id [ plain | cipher ] password ]* |
Optional Configured on both ends of a virtual link Note that hello and dead parameters must be identical on both ends of the link |
|
Configure the host route |
host-advertise ip-address cost |
Optional Not configured by default |
& Note:
l It is required to use the stub command on routers attached to a stub area.
l It is required to use the nssa command on routers attached to a NSSA area.
3.5 Configuring OSPF Network Types
OSPF classifies networks into four types upon link layer protocols. Since an NBMA network must be fully meshed, namely, any two routers in the network must have a virtual link in between, in most cases, however, the requirement cannot be satisfied, and you need to change the network type using commands.
For routers having no direct link in between, you can configure related interfaces as the P2MP mode. If a router in the NBMA network has only a single peer, you can also configure associated interfaces as the P2P mode.
In addition, when configuring broadcast and NBMA networks, you can specify for interfaces DR priorities for DR/BDR election. In practice, routers having higher reliability should become the DR/BDR.
3.5.1 Prerequisites
Before configuring OSPF network types, you have configured:
l IP addresses for interfaces
l OSPF basic functions
3.5.2 Configuring the OSPF Network Type for an Interface
To configure the OSPF network type for an interface, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enter interface view |
interface interface-type interface-number |
— |
|
Configure the network type |
ospf network-type { broadcast | nbma | p2mp | p2p } |
Required The network type of an interface is broadcast by default |
& Note:
l Configuring a new network type for an interface overwrites the previous network type.
l If any two interfaces are both configured as the broadcast, NBMA or P2MP type, the two interfaces can establish neighbor relationship only when they are on the same network segment.
3.5.3 Configuring an NBMA Neighbor
For NBMA interfaces that cannot broadcast hello packets to find neighbors, you need to specify IP addresses and DR priorities of neighbors manually. To configure a neighbor and its DR priority, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enter OSPF view |
ospf [ process-id | router-id router-id ]* |
— |
|
Specify an NBMA neighbor and its DR priority |
peer ip-address [ dr-priority dr-priority ] |
Required The DR priority of NBMA neighbors defaults to 1 |
3.5.4 Configuring the DR Priority for an OSPF Interface
For broadcast or NBMA interfaces, you can configure DR priorities for DR/BDR election. To configure the DR priority for an OSPF interface, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enter interface view |
interface interface-type interface-number |
— |
|
Configure the DR priority |
ospf dr-priority priority |
Required The DR priority defaults to 1 |
& Note:
The DR priority configured with the ospf dr-priority command and the one with the peer command have the following differences:
l The former is for actual DR election.
3.6 Configuring OSPF Routing Information Management
This section is to configure management for OSPF routing information advertisement and reception, and route redistribution from other protocols.
3.6.1 Prerequisites
To configure this task, you have configured:
l IP addresses for interfaces
l OSPF basic functions
l Corresponding filtering tables if routing information filtering is needed.
3.6.2 Configuring OSPF Route Summarization
OSPF route summarization includes:
l Configure route summarization between OSPF areas on an ABR
l Configure route summarization when redistributing routes into OSPF on an ASBR
To configure route summarization between OSPF areas on an ABR, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enter OSPF view |
ospf [ process-id | router-id router-id ]* |
— |
|
Enter OSPF area view |
area area-id |
— |
|
Configure ABR route summarization |
abr-summary ip-address { mask | mask-length } [ advertise | not-advertise ] [ cost cost ] |
Required Not configured by default |
To configure route summarization when redistributing routes into OSPF on an ASBR, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enter OSPF view |
ospf [ process-id | router-id router-id ]* |
— |
|
Configure ASBR route summarization |
asbr-summary ip-address { mask | mask-length } [ not-advertise | tag tag-value | cost cost ] * |
Required Not configured by default |
3.6.3 Configuring OSPF Inbound Route Filtering
To configure OSPF to filter received routes, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enter OSPF view |
ospf [ process-id | router-id router-id ]* |
— |
|
Configure to filter received routes |
filter-policy { acl-number | ip-prefix ip-prefix-name | gateway ip-prefix-name } import |
Required Not configured by default |
& Note:
Since OSPF is a link state-based internal gateway protocol, routing information is contained in LSAs. However, OSPF cannot filter LSAs. Using the filter-policy import command is to filter routes computed by OSPF, and only routes not filtered are added into the routing table.
3.6.4 Configuring ABR Type3 LSA Filtering
To configure type 3 LSA filtering on an ABR, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
System-view |
— |
|
Enter OSPF view |
ospf [ process-id | router-id router-id ]* |
— |
|
Enter OSPF area view |
area area-id |
— |
|
Configure ABR type3 LSA filtering |
filter { acl-number | ip-prefix ip-prefix-name } { import | export } |
Required Not configured by default |
3.6.5 Configuring OSPF Link Cost
To configure the link cost for an interface, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enter interface view |
interface interface-type interface-number |
— |
|
Configure the cost value of the interface |
ospf cost value |
Required By default, an interface computes its cost according to the baud rate The cost value defaults to 1 for VLAN interfaces |
To configure a bandwidth reference value, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enter OSPF view |
ospf [ process-id | router-id router-id ]* |
— |
|
Configure a bandwidth reference value |
bandwidth-reference value |
Required The value defaults to 100Mbit/s |
& Note:
If the cost value is not configured for an interface, OSPF computes the interface cost value automatically: Interface value= Bandwidth reference value/Interface bandwidth.
3.6.6 Configuring the Maximum Number of OSPF Routes
To configure the maximum number of routes, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enter OSPF view |
ospf [ process-id | router-id router-id ]* |
— |
|
Configure the maximum number of OSPF routes |
maximum-routes { external | inter | intra } number |
Required By default, the maximum number of routes is 16,384. |
3.6.7 Configuring the Maximum Number of Load-balanced Routes
If several routes with the same cost to the same destination are available, configuring them as load-balanced routes can improve link utilization.
To configure the maximum number of load-balanced routes, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enter OSPF view |
ospf [ process-id | router-id router-id ]* |
— |
|
Configure the maximum number of load-balanced routes |
maximum load-balancing maximum |
Required By default, the maximum number of load-balanced routes is 4. |
3.6.8 Configuring OSPF Priority
A router may run multiple routing protocols. The router sets a priority for each protocol, when a route found by several routing protocols, the route found by the protocol with the highest priority will be selected.
To configure the priority for OSPF, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enter OSPF view |
ospf [ process-id | router-id router-id ]* |
— |
|
Configure OSPF route priority |
preference [ ase ] [ route-policy route-policy-name ] value |
Required The priority of OSPF internal routes defaults to 10 The priority of OSPF external routes defaults to 150 |
3.6.9 Configuring OSPF Route Redistribution
To configure OSPF route redistribution, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enter OSPF view |
ospf [ process-id | router-id router-id ] * |
— |
|
Configure OSPF to redistribute routes from other protocols |
import-route protocol [ process-id | allow-ibgp ] [ cost cost | type type | tag tag | route-policy route-policy-name ] * |
Required Not configured by default |
|
Configure OSPF to filter redistributed routes before advertisement |
filter-policy { acl-number | ip-prefix ip-prefix-name } export [ protocol [ process-id ] ] |
Optional Not configured by default |
|
Redistribute a default route |
default-route-advertise [ always | cost cost | type type | route-policy route-policy-name ] * default-route-advertise summary cost cost |
Optional Not redistributed by default Use the default-route-advertise summary command to advertise the type3 LSA of the default route. |
|
Configure the default values of parameters for redistributed routes (cost, route number, tag and type) |
default { cost cost | limit limit | tag tag | type type } * |
Optional By default, the default cost is 1, default upper limit of routes redistributed per time is 1000, default tag is 1 and default type of redistributed routes is type2. |
& Note:
l Using the import-route command cannot redistribute a default external route. To do so, you need to use the default-route-advertise command.
l By filtering redistributed routes, OSPF translates only routes, which are not filtered out, into type5 LSAs or type7 LSAs for advertisement.
l You can configure default values of parameters for redistributed routes, such as the cost, upper limit, tag and type of external routes. The tag is used to indicate information related to protocol, for example, when redistributing BGP routes, OSPF uses the tag to differentiate AS IDs.
3.7 Configuring OSPF Network Optimization
You can optimize your OSPF network in the following ways:
l Change timeout values of OSPF packet timers to adjust the OSPF network convergence speed and network load. On low speed links, you need to consider the delay time for sending LSAs on interfaces.
l Change the interval for SPF calculation to reduce resource consumption caused by frequent network changes.
l Configure OSPF authentication to meet high security requirements of some mission-critical networks.
l Configure OSPF network management functions, such as binding OSPF MIB with a process, sending trap information and collecting log information.
3.7.1 Prerequisites
Before configuring OSPF network optimization, you have configured:
l IP addresses for interfaces
l OSPF basic functions
3.7.2 Configuring OSPF Packet Timers
The hello interval defines the time between hello packets, which must be identical on OSPF neighbors. The longer the interval is, the lower convergence speed and smaller network load are.
On an interface, the dead interval should be at least four times the hello interval.
After sending a LSA to its neighbor, a router waits for the acknowledge packet from the neighbor. Upon no response after the retransmit interval elapses, the router will send again the LSA to the neighbor.
To configure timers for OSPF packets, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enter interface view |
interface interface-type interface-number |
— |
|
Specify the interval between the hello packets sent on the interface. |
ospf timer hello seconds |
Optional The hello interval on P2P, Broadcast interfaces defaults to 10 seconds and defaults to 30 seconds on P2MP and NBMA interfaces. |
|
Specify the interval between poll packets |
ospf timer poll seconds |
Optional The pool interval defaults to 120 seconds. |
|
Set the interval that a device must wait before it declares a neighbor OSPF router down because it has not received a hello packet |
ospf timer dead seconds |
Optional The dead interval defaults to 40 seconds on P2P, Broadcast interfaces and 120 seconds on P2MP and NBMA interfaces. |
|
Specifies the interval between LSA retransmissions |
ospf timer retransmit interval |
Optional The retransmission interval defaults to 5 seconds. |
& Note:
l The hello and dead intervals restore to default values after you change the network type for an interface.
l The retransmission interval should not be so small for avoidance of unnecessary LSA retransmissions. In general, this value is bigger than the round-trip time value of a packet between two adjacencies.
3.7.3 Configuring LSA Transmission Delay Time
Since OSPF packets need time for travelling on links, extending LSA age time with some delay time is necessery, especially for low speed links.
To configure the LSA transmission delay time on an interface, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enter interface view |
interface interface-type interface-number |
— |
|
Set the LSA transmission delay time |
ospf trans-delay seconds |
Required Set to 1 second by default |
3.7.4 Configuring SPF Calculation Interval
Link State Database changes lead to SPF calculations. When an OSPF network changes frequently, a large amount of network resources will be occupied, reducing working efficiency of routers. You can adjust the SPF calculation interval for the network to reduce negative influence. To do so, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enter OSPF view |
ospf [ process-id | router-id router-id ]* |
— |
|
Set the SPF calculation interval |
spf-schedule-interval maximum-interval [ minimum-interval [ incremental-interval ] ] |
Optional By default, the interval is 5 seconds |
& Note:
With this command configured, when network changes are not frequent, SPF calculation applies at the minimum-interval. If network changes become frequent, SPF calculation interval is incremented by incremental-interval•2n-2 (n is the number of calculation times) each time a calculation occurs, up to the maximum-interval.
3.7.5 Configuring LSA Minimum Repeat Arrival Interval
When an interface receives an LSA that is the same with the previously received LSA within a specified interval, the LSA minimum repeat arrival interval, the interface will discard the LSA. To configure the LSA minimum repeat arrival interval, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enter OSPF view |
ospf [ process-id | router-id router-id ] * |
— |
|
Configure the LSA minimum repeat arrival interval |
lsa-arrival-interval interval |
Required Defaults to 1000 milliseconds |
& Note:
It is recommended the interval set by the lsa-arrival-interval command is smaller or equal to the interval set by the lsa-generation-interval command.
3.7.6 Configuring LSA Generation Interval
With this feature configured, you can protect network resources and routers from being over consumed due to frequent network changes.
To configure LSA generation interval, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enter OSPF view |
ospf [ process-id | router-id router-id ] * |
— |
|
Configure the LSA generation interval |
lsa-generation-interval maximum-interval [ minimum-interval [incremental-interval ] ] |
Required By default, the maximum interval is 5 seconds, the minimum interval is 0 millisecond and the incremental interval is 5000 milliseconds. |
& Note:
With this command configured, when network changes are not frequent, LSAs are generated at the minimum-interval. If network changes become frequent, LSA generation interval is incremented by incremental-interval•2n-2 (n is the number of generation times) each time a generation occurs, up to the maximum-interval.
3.7.7 Disabling Interfaces from Sending OSPF Packets
To disable an interface from sending routing information to other routers, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enter OSPF view |
ospf [ process-id | router-id router-id ] * |
— |
|
Disable interfaces from sending OSPF packets |
silent-interface { all | interface-type interface-number } |
Required Not disabled by default |
& Note:
l Different OSPF processes can disable the same interface from sending OSPF packets. Use of the silent-interface command disables only the interfaces associated with the current process rather than interfaces associated with other processes.
l After an OSPF interface is set to silent, other interfaces on the router can still advertise direct routes of the interface in router LSAs, but no OSPF packet can be advertised for the interface to find a neighbor. This configuration can enhance adaptability of OSPF networking and reduce resource consumption.
3.7.8 Configuring Stub Routers
A stub router is used for traffic control. It informs other OSPF routers not to use it to forward data, but they can have a route to the stub router.
In Router LSAs generated by stub routers, metrics for all links are set to the maximum value of 65535.
To configure a router as a stub router, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enter OSPF view |
ospf [ process-id | router-id router-id ] * |
— |
|
Configure the router as a stub router |
stub-router |
Required Not configured by default |
& Note:
A stub router has nothing to do with a stub area.
3.7.9 Configuring OSPF Authentication
By supporting packet authentication, OSPF receives packets that pass the authentication only, so failed packets cannot establish neighboring relationship.
To configure OSPF authentication, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enter OSPF view |
ospf [ process-id | router-id router-id ] * |
— |
|
Enter area view |
area area-id |
— |
|
Configure the authentication mode |
authentication-mode { simple | md5 } |
Required Not configured by default |
|
Exit to OSPF view |
quit |
— |
|
Exit to system view |
quit |
— |
|
Enter interface view |
interface interface-type interface-number |
— |
|
Configure the authentication mode (simple authentication) for the interface |
ospf authentication-mode simple [ plain | cipher ] password |
Optional Not configured by default |
|
Configure the authentication mode (MD5 authentication) for the interface |
ospf authentication-mode { md5 | hmac-md5 } key-id [ plain | cipher ] password |
& Note:
The authentication mode and password for all interfaces attached to the same area must be identical.
3.7.10 Adding Interface MTU into DD Packets
Generally, when an interface sends a DD packet, it adds 0 into the Interface MTU field of the DD packet rather than the interface MTU. To add the interface MTU into DD packets, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enter interface view |
interface interface-type interface-number |
— |
|
Enable OSPF to add interface MTU into DD packets |
ospf mtu-enable |
Required Not enabled by default, that is, the interface fills in a value of 0 |
3.7.11 Configuring the Maximum Number of External LSAs in LSDB
To configure the maximum number of external LSAs in the Link State Database, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enter OSPF view |
ospf [ process-id | router-id router-id ] * |
— |
|
Specify the maximum number of external LSAs in the LSDB |
lsdb-overflow-limit number |
Required No limitation by default |
3.7.12 Making External Route Selection Rules Defined in RFC1583 Compatible
The selection of an external route from multiple LSAs defined in RFC2328 is different from the one defined in RFC1583, to make which compatible, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enter OSPF view |
ospf [ process-id | router-id router-id ] * |
— |
|
Make RFC1583 compatible |
rfc1583 compatible |
Required Compatible by default |
3.7.13 Configuring OSPF Network Management
To Configure OSPF network management, use the following commands:
|
Use the command… |
Remarks |
|
|
Enter system view |
system-view |
— |
|
Bind OSPF MIB to an OSPF process |
ospf mib-binding process-id |
Optional The first OSPF process bound with OSPF MIB by default |
|
Enable OSPF trap |
snmp-agent trap enable ospf [ process-id ] [ ifauthfail | ifcfgerror | ifrxbadpkt | ifstatechange | lsdbapproachoverflow | lsdboverflow | maxagelsa | nbrstatechange | originatelsa | txretransmit | vifauthfail | vifcfgerror | virifrxbadpkt | virifstatechange | viriftxretransmit | virnbrstatechange ] * |
Optional You can enable multiple OSPF traps or specify an OSPF process to send SNMP trap messages |
|
Enter OSPF view |
ospf [ process-id | router-id router-id ] * |
— |
|
Enable messages logging |
enable log [ config | error | state ] |
Optional Not enabled by default |
|
Enable the logging on neighbor state changes |
log-peer-change |
Optional Enabled by default |
3.8 Displaying and Maintaining OSPF
|
To do… |
Use the command… |
Remarks |
|
Display OSPF brief information |
display ospf [ process-id ] brief |
Available in any view |
|
Display OSPF statistics |
display ospf [ process-id ] cumulative |
|
|
Display Link State Database information |
display ospf [ process-id ] lsdb [ brief | { ase | router | network | summary | asbr | nssa | opaque-link | opaque-area | opaque-as } [ link-state-id ] [ originate-router advertising-router-id | self-originate ] ] |
|
|
Display OSPF adjacency information |
display ospf [ process-id ] peer [ interface-type interface-number ] [ neighbor-id ] |
|
|
Display neighbor statistics of OSPF areas |
display ospf [ process-id ] peer statistics |
|
|
Display next hop information |
display ospf [ process-id ] nexthop |
|
|
Display routing table information |
display ospf [ process-id ] routing [ interface interface-type interface-number ] [ nexthop nexthop-address ] |
|
|
Display virtual link information |
display ospf [ process-id ] vlink |
|
|
Display OSPF request queue information |
display ospf [ process-id ] request-queue [ interface-type interface-number ] [neighbor-id ] |
|
|
Display OSPF retransmission queue information |
display ospf [ process-id ] retrans-queue [ interface-type interface-number ] [ neighbor-id ] |
|
|
Display OSPF ABR and ASBR information |
display ospf [ process-id ] abr-asbr |
|
|
Display OSPF interface information |
display ospf [ process-id ] interface [ all | interface-type interface-number ] |
|
|
Display OSPF error information |
display ospf [process-id ] error |
|
|
Display OSPF ASBR summarization information |
display ospf [ process-id ] asbr-summary [ ip-address { mask | mask-length } ] |
|
|
Reset OSPF counters |
reset ospf [ process-id ] counters [ neighbor [ interface-type interface-number ] [ router-id ] ] |
Available in user view |
|
Reset an OSPF process |
reset ospf [ process-id ] process [ graceful-restart ] |
|
|
Remove redistributed routes |
reset ospf [ process-id ] redistribution |
3.9 OSPF Typical Configuration Examples
![]() Caution:
Caution:
In these examples, only commands related to OSPF configuration are described.
3.9.1 Configuring OSPF Basic Functions
I. Network requirements
As shown in the following figure, all switches run OSPF. The AS is split into three areas, in which, SwitchA and SwitchB act as ABRs to forward routing information between areas.
After configuration, all switches can learn routes to every network segment in the AS.
II. Network diagram

Figure 3-21 Network diagram for OSPF basic configuration
III. Configuration procedure
1) Configure IP addresses for interfaces (omitted)
2) Configure OSPF basic functions
# Configure SwitchA
<SwitchA> system-view
[SwitchA] ospf
[SwitchA-ospf-1] area 0
[SwitchA-ospf-1-area-0.0.0.0] network 192.168.0.0 0.0.0.255
[SwitchA-ospf-1-area-0.0.0.0] quit
[SwitchA-ospf-1] area 1
[SwitchA-ospf-1-area-0.0.0.1] network 192.168.1.0 0.0.0.255
[SwitchA-ospf-1-area-0.0.0.1] quit
[SwitchA-ospf-1] quit
# Configure SwitchB
<SwitchB> system-view
[SwitchB] ospf
[SwitchB-ospf-1] area 0
[SwitchB-ospf-1-area-0.0.0.0] network 192.168.0.0 0.0.0.255
[SwitchB-ospf-1-area-0.0.0.0] quit
[SwitchB-ospf-1] area 2
[SwitchB-ospf-1-area-0.0.0.2] network 192.168.2.0 0.0.0.255
[SwitchB-ospf-1-area-0.0.0.2] quit
[SwitchB-ospf-1] quit
# Configure SwitchC
<SwitchC> system-view
[SwitchC] ospf
[SwitchC-ospf-1] area 1
[SwitchC-ospf-1-area-0.0.0.1] network 192.168.1.0 0.0.0.255
[SwitchC-ospf-1-area-0.0.0.1] network 172.16.1.0 0.0.0.255
[SwitchC-ospf-1-area-0.0.0.1] quit
[SwitchC-ospf-1] quit
# Configure SwitchD
<SwitchD> system-view
[SwitchD] ospf
[SwitchD-ospf-1] area 2
[SwitchD-ospf-1-area-0.0.0.2] network 192.168.2.0 0.0.0.255
[SwitchD-ospf-1-area-0.0.0.2] network 172.17.1.0 0.0.0.255
[SwitchD-ospf-1-area-0.0.0.2] quit
[SwitchD-ospf-1] quit
3) Verify the configuration
# Display information about neighbors on SwitchA.
[SwitchA] display ospf peer
OSPF Process 1 with Router ID 192.168.0.1
Neighbors
Area 0.0.0.0 interface 192.168.0.1(Vlan-interface 100)'s neighbors
Router ID: 192.168.0.2 Address: 192.168.0.2 GR State: Normal
State: Full Mode:Nbr is Master Priority: 1
DR: 192.168.0.2 BDR: 192.168.0.1 MTU: 0
Dead timer due in 36 sec
Neighbor is up for 00:15:04
Authentication Sequence: [ 0 ]
Neighbors
Area 0.0.0.1 interface 192.168.1.1(Vlan-interface 200)'s neighbors
Router ID: 172.16.1.1 Address: 192.168.1.2 GR State: Normal
State: Full Mode:Nbr is Slave Priority: 1
DR: 192.168.0.1 BDR: 172.16.1.1 MTU: 0
Dead timer due in 39 sec
Neighbor is up for 00:07:32
Authentication Sequence: [ 0 ]
# Display routing information on SwitchA.
[SwitchA] display ospf routing
OSPF Process 1 with Router ID 192.168.0.1
Routing Tables
Routing for Network
Destination Cost Type NextHop AdvRouter Area
172.16.1.0/24 1563 Stub 192.168.1.2 172.16.1.1 0.0.0.1
172.17.1.0/24 3125 Inter-area 192.168.0.2 192.168.2.1 0.0.0.0
192.168.1.0/24 1562 Stub 192.168.1.1 192.168.0.1 0.0.0.1
192.168.2.0/24 3124 Inter-area 192.168.0.2 192.168.2.1 0.0.0.0
192.168.0.0/24 1562 Stub 192.168.0.1 192.168.0.1 0.0.0.0
Total Nets: 5
Intra Area: 3 Inter Area: 2 ASE: 0 NSSA: 0
# Display the Link State Database on SwitchA.
[SwitchA] display ospf lsdb
OSPF Process 1 with Router ID 192.168.0.1
Link State Data Base
Area: 0.0.0.0
Type LinkState ID AdvRouter Age Len Sequence Metric
Router 192.168.2.1 192.168.2.1 874 48 80000006 1562
Router 192.168.0.1 192.168.0.1 976 48 80000005 1562
Sum-Net 192.168.1.0 192.168.0.1 630 28 80000001 1562
Sum-Net 172.17.1.0 192.168.2.1 411 28 80000001 1563
Sum-Net 192.168.2.0 192.168.2.1 429 28 80000001 1562
Sum-Net 172.16.1.0 192.168.0.1 565 28 80000001 1563
Area: 0.0.0.1
Type LinkState ID AdvRouter Age Len Sequence Metric
Router 192.168.1.2 192.168.1.2 964 48 80000003 1562
Router 192.168.0.1 192.168.0.1 590 48 80000002 1562
Router 172.16.1.1 172.16.1.1 526 60 80000005 1562
Sum-Net 172.17.1.0 192.168.0.1 410 28 80000001 3125
Sum-Net 192.168.2.0 192.168.0.1 428 28 80000001 3124
Sum-Net 192.168.0.0 192.168.0.1 630 28 80000001 1562
# Display the routing table on SwitchD and ping the IP address 172.16.1.1 to check connectivity.
[SwitchD] display ospf routing
OSPF Process 1 with Router ID 192.168.2.2
Routing Tables
Routing for Network
Destination Cost Type NextHop AdvRouter Area
172.16.1.0/24 4687 Inter-area 192.168.2.1 192.168.2.1 0.0.0.2
172.17.1.0/24 1 Stub 172.17.1.1 192.168.2.2 0.0.0.2
192.168.1.0/24 4686 Inter-area 192.168.2.1 192.168.2.1 0.0.0.2
192.168.2.0/24 1562 Stub 192.168.2.2 192.168.2.2 0.0.0.2
192.168.0.0/24 3124 Inter-area 192.168.2.1 192.168.2.1 0.0.0.2
Total Nets: 5
Intra Area: 2 Inter Area: 3 ASE: 0 NSSA: 0
[SwitchD] ping 172.16.1.1
PING 172.16.1.1: 56 data bytes, press CTRL_C to break
Reply from 172.16.1.1: bytes=56 Sequence=1 ttl=253 time=62 ms
Reply from 172.16.1.1: bytes=56 Sequence=2 ttl=253 time=16 ms
Reply from 172.16.1.1: bytes=56 Sequence=3 ttl=253 time=62 ms
Reply from 172.16.1.1: bytes=56 Sequence=4 ttl=253 time=94 ms
Reply from 172.16.1.1: bytes=56 Sequence=5 ttl=253 time=63 ms
--- 172.16.1.1 ping statistics ---
5 packet(s) transmitted
5 packet(s) received
0.00% packet loss
round-trip min/avg/max = 16/59/94 ms
3.9.2 Configuring an OSPF Stub Area
I. Network requirements
Figure 3-22shows an AS is split into three areas, where all switches run OSPF. SwitchA and SwitchB act as ABRs to forward routing information between areas. SwitchD acts as the ASBR, redistributing routes (static routes).
It is required to configure Area1 as a Stub area, reducing LSAs to this area without affecting route reachability.
II. Network diagram

Figure 3-22 OSPF Stub area configuration network diagram
III. Configuration procedure
1) Configure IP addresses for interfaces (omitted).
2) Configure OSPF basic functions (omitted).
3) Configure SwitchD to redistribute static routes.
[SwitchD] ip route-static 200.0.0.0 8 null 0
[SwitchD] ospf
[SwitchD-ospf-1] import-route static
[SwitchD-ospf-1] quit
# Display ABR/ASBR information on SwitchC
[SwitchC] display ospf abr-asbr
OSPF Process 1 with Router ID 172.16.1.1
Routing Table to ABR and ASBR
Type Destination Area Cost Nexthop RtType
Intra-area 192.168.0.1 0.0.0.1 1562 192.168.1.1 ABR
Inter-area 172.17.1.1 0.0.0.1 4686 192.168.1.1 ASBR
# Display OSPF routing table information on SwitchC.
[SwitchC] display ospf routing
OSPF Process 1 with Router ID 172.16.1.1
Routing Tables
Routing for Network
Destination Cost Type NextHop AdvRouter Area
172.16.1.0/24 1 Stub 172.16.1.1 172.16.1.1 0.0.0.1
172.17.1.0/24 4687 Inter-area 192.168.1.1 192.168.0.1 0.0.0.1
192.168.1.0/24 1562 Stub 192.168.1.2 172.16.1.1 0.0.0.1
192.168.2.0/24 4686 Inter-area 192.168.1.1 192.168.0.1 0.0.0.1
192.168.0.0/24 3124 Inter-area 192.168.1.1 192.168.0.1 0.0.0.1
Routing for ASEs
Destination Cost Type Tag NextHop AdvRouter
200.0.0.0/8 10 Type2 1 192.168.1.1 172.17.1.1
Routing for NSSAs
Destination Cost Type Tag NextHop AdvRouter
Total Nets: 6
Intra Area: 2 Inter Area: 3 ASE: 1 NSSA: 0
& Note:
In the above output, since SwitchC resides in a normal OSPF area, its routing table contains an external route.
4) Configure Area1 as a Stub area.
# Configure SwitchA.
[SwitchA] ospf
[SwitchA-ospf-1] area 1
[SwitchA-ospf-1-area-0.0.0.1] stub
[SwitchA-ospf-1-area-0.0.0.1] quit
[SwitchA-ospf-1] quit
# Configure SwitchC.
[SwitchC] ospf
[SwitchC-ospf-1] stub-router
[SwitchC-ospf-1] area 1
[SwitchC-ospf-1-area-0.0.0.1] stub
[SwitchC-ospf-1-area-0.0.0.1] quit
[SwitchC-ospf-1] quit
# Display routing table information on SwitchC
[SwitchC] display ospf routing
OSPF Process 1 with Router ID 172.16.1.1
Routing Tables
Routing for Network
Destination Cost Type NextHop AdvRouter Area
0.0.0.0/0 65536 Inter-area 192.168.1.1 192.168.0.1 0.0.0.1
172.16.1.0/24 1 Stub 172.16.1.1 172.16.1.1 0.0.0.1
172.17.1.0/24 68660 Inter-area 192.168.1.1 192.168.0.1 0.0.0.1
192.168.1.0/24 1562 Stub 192.168.1.2 172.16.1.1 0.0.0.1
192.168.2.0/24 68659 Inter-area 192.168.1.1 192.168.0.1 0.0.0.1
192.168.0.0/24 67097 Inter-area 192.168.1.1 192.168.0.1 0.0.0.1
Total Nets: 6
Intra Area: 2 Inter Area: 4 ASE: 0 NSSA: 0
& Note:
When SwitchC resides in the Stub area, a default route takes the place of the external route.
# Configure to filter type3 LSAs for the Stub area
[SwitchA] ospf
[SwitchA-ospf-1] area 1
[SwitchA-ospf-1-area-0.0.0.1] stub no-summary
[SwitchA-ospf-1-area-0.0.0.1] quit
# Display the OSPF routing table on SwitchC.
[SwitchC] display ospf routing
OSPF Process 1 with Router ID 172.16.1.1
Routing Tables
Routing for Network
Destination Cost Type NextHop AdvRouter Area
0.0.0.0/0 1563 Inter-area 192.168.1.1 192.168.0.1 0.0.0.1
172.16.1.0/24 1 Stub 172.16.1.1 172.16.1.1 0.0.0.1
192.168.1.0/24 1562 Stub 192.168.1.2 172.16.1.1 0.0.0.1
Total Nets: 3
Intra Area: 2 Inter Area: 1 ASE: 0 NSSA: 0
& Note:
After this configuration, routing table entires on the Stub router are further reduced, containing only one default external route.
3.9.3 Configuring an OSPF NSSA Area
I. Network requirements
Figure 3-23 shows an AS is split into three areas, where all routers run OSPF. SwitchA and SwitchB act as ABRs to forward routing information between areas. SwitchD acts as the ASBR, redistributing routes (static routes)
It is required to configure Area1 as an NSSA area, RouterC as the ASBR to redistribute static routes into the AS.
II. Network diagram

Figure 3-23 OSPF NSSA area configuration network diagram
III. Configuration procedure
1) Configure IP addresses for interfaces (omitted).
2) Configure OSPF basic functions (omitted).
3) Configure SwitchD to import external static routes (omitted)
4) Configure Area1 as an NSSA area.
# Configure SwitchA.
[SwitchA] ospf
[SwitchA-ospf-1] area 1
[SwitchA-ospf-1-area-0.0.0.1] nssa default-route-advertise no-summary
[SwitchA-ospf-1-area-0.0.0.0] quit
[SwitchA-ospf-1] quit
# Configure SwitchC.
[SwitchC] ospf
[SwitchC-ospf-1] area 1
[SwitchC-ospf-1-area-0.0.0.1] nssa
[SwitchC-ospf-1-area-0.0.0.1] quit
[SwitchC-ospf-1] quit
& Note:
It is recommended to configure the nssa command with the keyword default-route-advertise no-summary on SwitchA (an ABR) to reduce the routing table size on NSSA routers. On other NSSA routers, using the nssa command is ok.
# Display OSPF routing table information on SwitchC.
[SwitchC] display ospf routing
OSPF Process 1 with Router ID 172.16.1.1
Routing Tables
Routing for Network
Destination Cost Type NextHop AdvRouter Area
0.0.0.0/0 1563 Inter-area 192.168.1.1 192.168.0.1 0.0.0.1
172.16.1.0/24 1 Stub 172.16.1.1 172.16.1.1 0.0.0.1
192.168.1.0/24 1562 Stub 192.168.1.2 172.16.1.1 0.0.0.1
Total Nets: 3
Intra Area: 2 Inter Area: 1 ASE: 0 NSSA: 0
5) Configure SwitchC to redistribute static routes.
[SwitchC] ip route-static 100.0.0.0 8 null 0
[SwitchC] ospf
[SwitchC-ospf-1] import-route static
[SwitchC-ospf-1] quit
# Display OSPF routing table information on SwitchD.
[SwitchD] display ospf routing
OSPF Process 1 with Router ID 172.17.1.1
Routing Tables
Routing for Network
Destination Cost Type NextHop AdvRouter Area
172.16.1.0/24 4687 Inter-area 192.168.2.1 192.168.0.2 0.0.0.2
172.17.1.0/24 1 Stub 172.17.1.1 172.17.1.1 0.0.0.2
192.168.1.0/24 4686 Inter-area 192.168.2.1 192.168.0.2 0.0.0.2
192.168.2.0/24 1562 Stub 192.168.2.2 172.17.1.1 0.0.0.2
192.168.0.0/24 3124 Inter-area 192.168.2.1 192.168.0.2 0.0.0.2
Routing for ASEs
Destination Cost Type Tag NextHop AdvRouter
100.0.0.0/8 10 Type2 1 192.168.2.1 192.168.0.1
Routing for NSSAs
Destination Cost Type Tag NextHop AdvRouter
Total Nets: 6
Intra Area: 2 Inter Area: 3 ASE: 1 NSSA: 0
& Note:
You can see on SwitchD an external route imported from the NSSA area.
3.9.4 Configuring OSPF DR Election
I. Network requirements
In Figure 3-24, Switches A, B, C and D reside on the same network segment, running OSPF. It is required to configure SwitchA as the DR, SwichC as the BDR.
II. Network diagram

Figure 3-24 OSPF DR election configuration network diagram
III. Configuration procedure
1) Configure IP addresses for interfaces (omitted)
2) Configure OSPF basic functions
# Configure SwitchA
<SwitchA> system-view
[Switch A] router id 1.1.1.1
[Switch A] ospf
[Switch A-ospf-1] area 0
[Switch A-ospf-1-area-0.0.0.0] network 196.1.1.0 0.0.0.255
[SwitchA-ospf-1-area-0.0.0.0] quit
[SwitchA-ospf-1] quit
# Configure SwitchB
<SwitchB> system-view
[SwitchB] router id 2.2.2.2
[SwitchB] ospf
[SwitchB-ospf-1] area 0
[SwitchB-ospf-1-area-0.0.0.0] network 196.1.1.0 0.0.0.255
[SwitchB-ospf-1-area-0.0.0.0] quit
[SwitchB-ospf-1] quit
# Configure SwitchC
<SwitchC> system-view
[SwitchC] router id 3.3.3.3
[SwitchC] ospf
[SwitchC-ospf-1] area 0
[SwitchC-ospf-1-area-0.0.0.0] network 196.1.1.0 0.0.0.255
[SwitchC-ospf-1-area-0.0.0.0] quit
[SwitchC-ospf-1] quit
# Configure SwitchD
<SwitchD> system-view
[SwitchD] router id 4.4.4.4
[SwitchD] ospf
[SwitchD-ospf-1] area 0
[SwitchD-ospf-1-area-0.0.0.0] network 196.1.1.0 0.0.0.255
[SwitchD-ospf-1-area-0.0.0.0] quit
[SwitchD-ospf-1] quit
# Display OSPF neighbor information on SwitchA.
[SwitchA] display ospf peer
OSPF Process 1 with Router ID 1.1.1.1
Neighbors
Area 0.0.0.0 interface 192.168.1.1(Vlan-interface1)'s neighbors
Router ID: 2.2.2.2 Address: 192.168.1.2 GR State: Normal
State: 2-Way Mode: None Priority: 1
DR: 192.168.1.4 BDR: 192.168.1.3 MTU: 0
Dead timer due in 38 sec
Neighbor is up for 00:01:31
Authentication Sequence: [ 0 ]
Router ID: 3.3.3.3 Address: 192.168.1.3 GR State: Normal
State: Full Mode: Nbr is Master Priority: 1
DR: 192.168.1.4 BDR: 192.168.1.3 MTU: 0
Dead timer due in 31 sec
Neighbor is up for 00:01:28
Authentication Sequence: [ 0 ]
Router ID: 4.4.4.4 Address: 192.168.1.4 GR State: Normal
State: Full Mode: Nbr is Master Priority: 1
DR: 192.168.1.4 BDR: 192.168.1.3 MTU: 0
Dead timer due in 31 sec
Neighbor is up for 00:01:28
Authentication Sequence: [ 0 ]
SwitchD becomes the DR, SwitchC the BDR.
3) Configure DR priority on interfaces
# Configure SwitchA
[SwitchA] interface vlan-interface 1
[RouterA-Vlan-interface1] ospf dr-priority 100
[RouterA-Vlan-interface1] quit
# Configure SwitchB
[SwitchB] interface vlan-interface 1
[SwitchB-Vlan-interface1] ospf dr-priority 0
[SwitchB-Vlan-interface1] quit
# Configure SwitchC
[SwitchC] interface vlan-interface 1
[SwitchC-Vlan-interface1] ospf dr-priority 2
[SwitchC-Vlan-interface] quit
# Display neighbor information on SwitchD.
[SwitchD] display ospf peer
OSPF Process 1 with Router ID 4.4.4.4
Neighbors
Area 0.0.0.0 interface 192.168.1.4(Vlan-interface1)'s neighbors
Router ID: 1.1.1.1 Address: 192.168.1.1 GR State: Normal
State: Full Mode:Nbr is Slave Priority: 100
DR: 192.168.1.4 BDR: 192.168.1.3 MTU: 0
Dead timer due in 31 sec
Neighbor is up for 00:11:17
Authentication Sequence: [ 0 ]
Router ID: 2.2.2.2 Address: 192.168.1.2 GR State: Normal
State: Full Mode:Nbr is Slave Priority: 0
DR: 192.168.1.4 BDR: 192.168.1.3 MTU: 0
Dead timer due in 35 sec
Neighbor is up for 00:11:19
Authentication Sequence: [ 0 ]
Router ID: 3.3.3.3 Address: 192.168.1.3 GR State: Normal
State: Full Mode:Nbr is Slave Priority: 2
DR: 192.168.1.4 BDR: 192.168.1.3 MTU: 0
Dead timer due in 33 sec
Neighbor is up for 00:11:15
Authentication Sequence: [ 0 ]
The DR and BDR have no change.
& Note:
In the above output, you can find the priority configuration does not take effect immediately.
4) Restart OSPF process (omitted)
# Display neighbor information on SwitchD.
[SwitchD] display ospf peer
OSPF Process 1 with Router ID 4.4.4.4
Neighbors
Area 0.0.0.0 interface 192.168.1.4(Vlan-interface1)'s neighbors
Router ID: 1.1.1.1 Address: 192.168.1.1 GR State: Normal
State: Full Mode: Nbr is Slave Priority: 100
DR: 192.168.1.1 BDR: 192.168.1.3 MTU: 0
Dead timer due in 39 sec
Neighbor is up for 00:01:40
Authentication Sequence: [ 0 ]
Router ID: 2.2.2.2 Address: 192.168.1.2 GR State: Normal
State: 2-Way Mode: None Priority: 0
DR: 192.168.1.1 BDR: 192.168.1.3 MTU: 0
Dead timer due in 35 sec
Neighbor is up for 00:01:44
Authentication Sequence: [ 0 ]
Router ID: 3.3.3.3 Address: 192.168.1.3 GR State: Normal
State: Full Mode: Nbr is Slave Priority: 2
DR: 192.168.1.1 BDR: 192.168.1.3 MTU: 0
Dead timer due in 39 sec
Neighbor is up for 00:01:41
Authentication Sequence: [ 0 ]
RouterA becomes the DR, Router C the BDR.
& Note:
If the neighbor state is full, which means SwitchD has established adjacency with the router. If the neighbor state is 2-way, which means the two switches are neither the DR nor the BDR, and they do not exchange LSAs.
# Display OSPF interface information.
[SwitchA] display ospf interface
OSPF Process 1 with Router ID 1.1.1.1
Interfaces
Area: 0.0.0.0
IP Address Type State Cost Pri DR BDR
192.168.1.1 Broadcast DR 1 100 192.168.1.1 192.168.1.3
[SwitchB] display ospf interface
OSPF Process 1 with Router ID 2.2.2.2
Interfaces
Area: 0.0.0.0
IP Address Type State Cost Pri DR BDR
192.168.1.2 Broadcast DROther 1 0 192.168.1.1 192.168.1.3
& Note:
The interface state DROther means the interface is not the DR/BDR.
3.9.5 Configuring OSPF Virtual Links
I. Network requirements
In Figure 3-25, Area2 has no direct connection to Area0, the backbone, and Area1 acts as the Transit Area to connect Area2 to Area0 via a configured virtual link between SwitchB and SwitchC.
After configuration, SwitchA can learn routes in Area2.
II. Network diagram
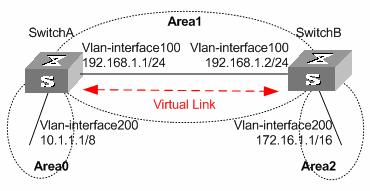
Figure 3-25 Network diagram for OSPF virtual link configuration
III. Configuration procedure
1) Configure IP addresses for interfaces (omitted)
2) Configure OSPF basic functions
# Configure SwitchA
<SwitchA> system-view
[SwitchA] ospf 1 router-id 1.1.1.1
[SwitchA-ospf-1] area 0
[SwitchA-ospf-1-area-0.0.0.0] network 10.0.0.0 0.255.255.255
[SwitchA-ospf-1-area-0.0.0.0] quit
[SwitchA-ospf-1] area 1
[SwitchA-ospf-1-area-0.0.0.1] network 192.168.1.0 0.0.0.255
[SwitchA-ospf-1-area-0.0.0.1] quit
# Configure SwitchB
<SwitchB> system-view
[SwitchB] ospf 1 router-id 2.2.2.2
[SwitchB-ospf-1] area 1
[SwitchB-ospf-1-area-0.0.0.1] network 192.168.1.0 0.0.0.255
[SwitchB-ospf-1-area-0.0.0.1] quit
[SwitchB-ospf-1] area 2
[SwitchB–ospf-1-area-0.0.0.2] network 172.16.0.0 0.0.255.255
[SwitchB–ospf-1-area-0.0.0.2] quit
# Display OSPF routing table on SwitchA
[SwitchA] display ospf routing
OSPF Process 1 with Router ID 1.1.1.1
Routing Tables
Routing for Network
Destination Cost Type NextHop AdvRouter Area
10.0.0.0/8 1 Stub 10.1.1.1 1.1.1.1 0.0.0.0
192.168.1.0/24 1562 Stub 192.168.1.1 1.1.1.1 0.0.0.1
Total Nets: 2
Intra Area: 2 Inter Area: 0 ASE: 0 NSSA: 0
& Note:
Since Area2 has no direct connection to Area0, the routing table of RouterA has no route to Area2.
3) Configure a virtual link
# Configure SwitchA
[SwitchA] ospf
[SwitchA-ospf-1] area 1
[SwitchA-ospf-1-area-0.0.0.1] vlink-peer 2.2.2.2
[SwitchA-ospf-1-area-0.0.0.1] quit
[SwitchA-ospf-1] quit
# Configure SwitchB
[SwitchB] ospf 1
[SwitchB-ospf-1] area 1
[SwitchB-ospf-1-area-0.0.0.1] vlink-peer 1.1.1.1
[SwitchB-ospf-1-area-0.0.0.1] quit
# Display OSPF routing table on SwitchA
[SwitchA] display ospf routing
OSPF Process 1 with Router ID 1.1.1.1
Routing Tables
Routing for Network
Destination Cost Type NextHop AdvRouter Area
172.16.1.1/16 1563 Inter 192.168.1.2 2.2.2.2 0.0.0.0
10.0.0.0/8 1 Stub 10.1.1.1 1.1.1.1 0.0.0.0
192.168.1.0/24 1562 Stub 192.168.1.1 1.1.1.1 0.0.0.1
Total Nets: 3
Intra Area: 2 Inter Area: 1 ASE: 0 NSSA: 0
Switch A learned route 172.16.1.1/16 to Area2.
3.10 Troubleshooting OSPF Configuration
3.10.1 No OSPF Neighbor Relationship Established
I. Symptom
No OSPF neighbor relationship can be established.
II. Analysis
If the physical link and lower protocols work well, check OSPF parameters configured on interfaces. Interfaces connecting two neighbor routers must have the same parameters, such as the area ID, network segment and mask (a P2P or virtual link may have different network segments and masks), network type. If the network type is broadcast or NBMA, at least one interface must have a DR priority higher than 0.
III. Processing steps
1) Display neighbor information using the display ospf peer command.
2) Display OSPF interface information using the display ospf interface command.
3) Ping the neighbor router’s IP address to check connectivity.
4) Check OSPF timers. The dead interval on an interface must be at least four times the hello interval.
5) On an NBMA network, using the peer ip-address command to specify the neighbor manually is required.
6) On an NBMA or a broadcast network, at least one connected interface must have a DR priority higher than 0.
3.10.2 Incorrect Routing Information
I. Symptom
OSPF cannot find routes to other areas.
II. Analysis
The backbone area must maintain connectivity to all other areas. If a router connects to more than one area, at least one area must be connected to the backbone. The backbone cannot be configured as a Stub area.
In a Stub area, all routers cannot receive external routes, and all interfaces connected to the Stub area must be assoiated with the Stub area.
III. Processing steps
1) Use the display ospf peer command to display neighbors.
2) Use the display ospf interface command to display OSPF interface information.
3) Use the display ospf lsdb command to display Link State Database information.
4) Display information about area configuration using the display current-configuration configuration command. If more than two areas are configured, at least one area is connected to the backbone.
5) In a Stub area, all routers attached to which are configured with the stub command. In an NSSA area, all interface connected to which are configured with the nssa command.
6) If a virtual link is configured, use the display ospf vlink command to check the neighbor state.
Chapter 4 IS-IS Configuration
& Note:
The term “router” in this document refers to a router in a generic sense or an Ethernet switch running routing protocols.
4.1 IS-IS Overview
The Intermediate System-to-Intermediate System (IS-IS) is a dynamic routing protocol designed by the International Organization for Standardization (ISO) to operate on the connectionless network protocol (CLNP).
The IS-IS routing protocol has been modified and extended in RFC 1195 by the International Engineer Task Force (IETF) for application in both TCP/IP and OSI reference models, and the new one is called Integrated IS-IS or Dual IS-IS.
IS-IS is an interior gateway protocol (IGP) used within an Autonomous System. It adopts the Shortest Path First (SPF) algorithm for route calculation.
4.1.1 Basic Concepts
I. IS-IS terminology
l Intermediate system (IS). An IS, similar to a router in TCP/IP, is the basic unit in IS-IS protocol to generate and propagate routing information. In the following text, an IS equals to a router.
l End system (ES). An ES refers to a host system in TCP/IP. ISO defines the ES-IS protocol for communication between an ES and an IS, therefore an ES does not participate in the IS-IS process.
l Routing domain (RD). A group of ISs exchange routing information with the same routing protocol in a routing domain.
l Area. An area is a division unit in a routing domain. The IS-IS protocol allows a routing domain to be divided into multiple areas.
l Link State Database (LSDB). All link states in the network consist of the LSDB. There is at least one LSDB in each IS. The IS uses SPF algorithm and LSDB to generate its own routes.
l Link State Protocol Data Unit or Link State Packet (LSP). Each IS can generate a LSP which contains all the link state information of the IS. Each IS collects all the LSPs in the local area to generate its own LSDB.
l Network Protocol Data Unit (NPDU). An NPDU is a network layer protocol packet in ISO, which is equivalent to an IP packet in TCP/IP.
l Designated IS. On a broadcast network, the designated router is also known as the designated IS or a pseudonode.
l Network service access point (NSAP). The NSAP is the ISO network layer address. It identifies an abstract network service access point and describes the network address in the ISO reference model.
II. IS-IS address structure
1) NSAP
As shown in Figure 4-1, the NSAP address consists of the Initial Domain Part (IDP) and the Domain Specific Part (DSP). The IDP equals to the network ID of the IP address, and the DSP equals to the subnet and host IDs.
The IDP, defined by ISO, includes the Authority and Format Identifier (AFI) and the Initial Domain Identifier (IDI).
The DSP includes the High Order DSP (HODSP), the System ID and SEL, where the HODSP identifies the area, the System ID identifies the host, and the SEL indicates the type of service.
The length of IDP and DSP is variable. The length of the NSAP address varies from 8 bytes to 20 bytes.

Figure 4-1 NSAP address structure
2) Area address
The area address is composed of the IDP and the HODSP of the DSP, which identify the area and the routing domain. Different routing domains cannot have the same area address.
Generally, a router only needs one area address, and all nodes in the same routing domain must share the same area address. However, a router can have three area addresses at most to support smooth area merging, partitioning and switching.
3) System ID
The system ID identifies the host or router uniquely. It has a fixed length of 48 bits (6 bytes).
The system ID is used in cooperation with the Router ID in practical. For example, a router uses the IP address 168.10.1.1 of the Loopback 0 as the Router ID, the system ID in IS-IS can be obtained in the following way:
l Extend each decimal number of the IP address to 3 digits by adding 0s from the left, like 168.010.001.001;
l Divide the extended IP address into 3 sections with 4 digits in each section to get the System ID 1680.1000.1001.
There are other methods to define a system ID. Just make sure it can uniquely identify a host or router.
4) SEL
The NSAP Selector (SEL), sometimes present in N-SEL, is similar with the protocol identifier in IP. Different transport layer protocols use different SELs. All SELs in IP are 00.
5) Routing method
Since the area is explicitly defined in the address structure, the Level-1 router can easily recognize the packets sent out of the area. These packets are forwarded to the Level-2 router.
The Level-1 router makes routing decisions based on the system ID. If the destination is not in the area, the packet is forwarded to the nearest Level-1-2 router.
The Level-2 router routes packets across areas according to the area address.
III. NET
The Network Entity Title (NET) is an NSAP with SEL of 0. It indicates the network layer information of the IS itself, where SEL=0 means no transport layer information. Therefore, the length of NET equals to NSAP, in the range 8 bytes to 20 bytes.
Generally, a router only needs one NET, but it can have three NETs at most for smooth area merging and partitioning. When you configure multiple NETs, make sure their system IDs are the same.
For example, a NET is ab.cdef.1234.5678.9abc.00, where,
Area = ab.cdef, System ID = 1234.5678.9abc, and SEL = 00.
4.1.2 IS-IS Area
I. Two-level hierarchy
IS-IS uses two-level hierarchy in the routing domain to support large scale routing networks. A large routing domain is divided into multiple Areas. The Level-1 router is in charge of forwarding routes within an area, and the Level-2 router is in charge of forwarding routes between areas.
II. Level-1 and Level-2
1) Level-1 router
The Level-1 router only establishes the neighbor relationship with Level-1 and Level-1-2 routers in the same area. The LSDB maintained by the Level-1 router contains the local area routing information. It directs the packets out of the area to the nearest Level-1-2 router.
2) Level-2 router
The Level-2 router establishes the neighbor relationships with the Level-2 and Level-1-2 routers in the same or in different areas. It maintains a Level-2 LSDB which contains inter area routing information. All the Level-2 and Level-1-2 routers must be contiguous to form the backbone in a routing domain. Only Level-2 routers can directly communicate with routers outside the routing domain.
3) Level-1-2 router
A router with both Level-1 and Level-2 router functions is called a Level-1-2 router. It can establish the Level-1 neighbor relationship with the Level-1 and Level-1-2 routers in the same area, or establish Level-2 neighbor relationship with the Level-2 and Level-1-2 routers in different areas. A Level-1 router must be connected to other areas via a Level-1-2 router. The Level-1-2 router maintains two LSDBs, where the Level-1 LSDB is for routing within the area, and the Level-2 LSDB is for routing between areas.
& Note:
l The Level-1 routers in different areas can not establish the neighbor relationship.
l The neighbor relationship establishment of Level-2 routers has nothing to do with area.
Figure 4-2 shows a network topology running the IS-IS protocol. Area 1 is a set of Level-2 routers, called backbone network. The other four areas are non-backbone networks connected to the backbone through Level-1-2 routers.

Figure 4-3 shows another network topology running the IS-IS protocol. The Level-1-2 routers connect the Level-1 and Level-2 routers, and also form the IS-IS backbone together with the Level-2 routers. There is no area defined as the backbone in this topology. The backbone is composed of all contiguous Level-2 and Level-1-2 routers which can reside in different areas.

& Note:
The IS-IS backbone does not need to be a specific Area.
Both the IS-IS Level-1 and Level-2 routers use the SPF algorithm generate the Shortest Path Tree (SPT).
III. Interface routing hierarchy type
You can configure the routing type for each interface. For a Level-1-2 router, one interface may establish Level-1 adjacency with a router, and another one may establish Level-2 adjacency with another router. You can limit the adjacency type by configuring the routing hierarchy on the interface. For example, the level-1 interface can only establish Level-1 adjacency, while the level-2 interface can only establish Level-2 adjacency.
By having this function, you can prevent the Level-1 hello packets from propagating to the Level-2 backbone through the Lever-1-2 router. This can result in bandwidth saving.
IV. Route leaking
An IS-IS routing domain is comprised of only one Level-2 area and multiple Level-1 areas. A Level-1 area is connected with the Level-2 area rather than other Level-1 areas.
The routing information of the Level-1 area is sent to the Level-2 area through the Level-1-2 router. Therefore, the Level-2 router knows the routing information of the entire IS-IS routing domain but does not share the information with the Level-1 area by default.
Since the Level-1 router simply sends the routing information for destinations outside the area to the nearest Level-1-2 router, this may cause a problem that the best path cannot be selected.
To solve this problem, route leaking was introduced. The Level-2 router can advertise the Level-2 routing information to a specified Level-1 area. By having the routing information of other areas, the Level-1 router can make a better routing choice for the packets destined outside the area.
4.1.3 IS-IS Network Type
I. Network type
IS-IS supports two network types:
l Broadcast network, such as Ethernet, Token-Ring.
l Point-to-point network, such as PPP, HDLC.
& Note:
For the Non-Broadcast Multi-Access (NBMA) network, such as ATM, you need to configure point-to-point or broadcast network on its configured subinterfaces. IS-IS does not run on Point to Multipoint (P2MP) links.
II. DIS and pseudonodes
On an IS-IS broadcast network, a router has to be selected as the Designated Intermediate System (DIS).
The Level-1 and Level-2 DISs are selected respectively. You can assign different priorities for different level DIS selections. The higher a router’s priority is, the more likelihood the router becomes the DIS. If there are multiple routers with the same highest DIS priority, the one with the highest SNPA (Subnetwork Point of Attachment) address (which is the MAC address on a broadcast network) will be selected. A router can be the DIS for different levels.
As shown in Figure 4-4, the same level routers and non-DIS routers on the same network segment can establish adjacencies. This is different from OSPF.

Figure 4-4 DIS in the IS-IS broadcast network
The DIS creates and updates pseudonodes as well as their LSP to describe all routers on the network.
The pseudonode emulates a virtual node on the broadcast network. It is not a real router. In IS-IS, it is identified by the system ID and one bye Circuit ID (a non zero value) of the DIS.
Using pseudonodes can reduce LSPs, the resources used by SPF and simplify the network topology.
& Note:
On IS-IS broadcast networks, all routers are adjacent with each other. The DIS is responsible for the synchronization of their LSDBs.
4.1.4 IS-IS PDU Format
I. PDU header format
The IS-IS packets are encapsulated into link layer frames. The Protocol Data Unit (PDU) consists of two parts, the headers and the variable length field, where the headers can be further divided into the common header and the specific header. The common headers are the same for all PDUs, while the specific headers vary by PDU type. The following figure shows the PDU format.
![]()
Figure 4-5 PDU format
II. Common header format
Figure 4-6 shows the common header format.

Figure 4-6 PDU common header format
l Intradomain Routing Protocol Discriminator: Set to 0x83.
l Length Indicator: The length of the PDU header, including both common and specific headers, present in bytes.
l Version/Protocol ID Extension: Set to 1(0x01).
l ID Length: The length of the NSAP address and NET ID.
l R(Reserved): Set to 0.
l PDU Type: For detail information, refer to Table 4-1.
l Version: Set to 1(0x01).
l Maximum Area Address: Maximum number of area addresses supported.
Table 4-1 PDU type
|
Type |
PDU Type |
Acronym |
|
15 |
Level-1 LAN IS-IS hello PDU |
L1 LAN IIH |
|
16 |
Level-2 LAN IS-IS hello PDU |
L2 LAN IIH |
|
17 |
Point-to-Point IS-IS hello PDU |
P2P IIH |
|
18 |
Level-1 Link State PDU |
L1 LSP |
|
20 |
Level-2 Link State PDU |
L2 LSP |
|
24 |
Level-1 Complete Sequence Numbers PDU |
L1 CSNP |
|
25 |
Level-2 Complete Sequence Numbers PDU |
L2 CSNP |
|
26 |
Level-1 Partial Sequence Numbers PDU |
L1 PSNP |
|
27 |
Level-2 Partial Sequence Numbers PDU |
L2 PSNP |
III. Hello
The hello packet is used by routers to establish and maintain the neighbor relationship. It is also called IS-to-IS hello PDU (IIH). For broadcast network, the Level-1 router uses the Level-1 LAN IIH; and the Level-2 router uses the Level-2 LAN IIH. The P2P IIH is used on point-to-point network.
Figure 4-7 illustrates the hello packet format in broadcast networks, where the grey fields are common header.

Figure 4-7 L1/L2 LAN IIH format
l Reserved/Circuit Type: The first 6 bits are reserved with value 0. The last 2 bits indicates router types: 00 means reserved, 01 indicates L1, 10 indicates L2, and 11 indicates L1/2.
l Source ID: The system ID of the router advertising the hello packet.
l Holding Time: If no hello packets are received from a neighbor within the holding time, the neighbor is considered dead.
l PDU Length: The total length of the PDU in bytes.
l Priority: DIS priority.
l LAN ID: Includes the system ID and one byte pseudonode ID.
Figure 4-8 shows the hello packet format on the point-to-point network.

Figure 4-8 P2P IIH format
Instead of the priority and LAN ID fields in the LAN IIH, the P2P IIH has a Local Circuit ID field.
IV. LSP packet format
The Link State PDUs (LSP) carries link state information. There are two types: Level-1 LSP and Level-2 LSP. The Level-2 LSP is sent by the Level-2 router, and the Level-1 LSP is sent by the Level-1 router. The level-1-2 router can sent both types of the LSPs.
Two types of LSPs have the same format, as shown in Figure 4-9.

Figure 4-9 L1/L2 LSP format
l PDU Length: Total length of the PDU in bytes.
l Remaining Lifetime: LSP remaining lifetime in seconds.
l LSP ID: Consists of the system ID, the pseudonode ID (one bye) and the LSP fragment number (one byte).
l Sequence Number: LSP sequence number.
l Checksum: LSP checksum.
l P (Partition Repair): Only related with L2 LSP, indicates whether the router supports partition repair.
l ATT (Attachment): Generated by the L1/L1 router, only related with L1 LSP, indicates that the router generating the LSP is connected with multiple areas.
l OL (LSDB Overload): Indicates that the LSDB is not complete because the router is running out of system resources. In this condition, other routers will not send packets to the overloaded router, except packets destined to the networks directly connected to the router. For example, in Figure 4-10, Router A uses Router B to forward its packets to Router C in normal condition. Once other routers know the OL field on Router B is set to 1, Router A will send packets to Router C via Router D and Router E, but still send to Router B packets destined to the network directly connected to Router B.

l IS Type: Type of the router generating the LSP.
V. SNP format
The Sequence Number PDU (SNP) confirms the latest received LSPs. It is similar to the Acknowledge packet, but more efficient.
SNP contains Complete SNP (CSNP) and Partial SNP (PSNP), which are further divided into Level-1 CSNP, Level-2 CSNP, Level-1 PSNP and Leval-2 PSNP.
CSNP covers the summary of all LSPs in the LSDB to synchronize the LSDB between neighboring routers. On broadcast networks, CSNP is sent by the DIS periodically (10s by default). On point-to-point networks, CSNP is only sent during the first adjacency establishment.
The CSNP packet format is shown in Figure 4-11.

Figure 4-11 L1/L2 CSNP format
PSNP only contains the sequence numbers of one or multiple latest received LSPs. It can acknowledge multiple LSPs at one time. When LSDBs are not synchronized, a PSNP is used to request new LSPs from neighbors.
Figure 4-12 shows the PSNP packet format.

Figure 4-12 L1/L2 PSNP format
VI. TLV
The variable fields of PDU are composed of multiple Type-Length-Value (TLV) sets. Figure 4-13 shows the TLV format.

Figure 4-13 TLV format
Table 4-2 shows different PDUs contain different TLVs.
Table 4-2 TLV name and the corresponding PDU type
|
TLV Code |
Name |
PDU Type |
|
1 |
Area Addresses |
IIH, LSP |
|
2 |
IS Neighbors (LSP) |
LSP |
|
4 |
Partition Designated Level2 IS |
L2 LSP |
|
6 |
IS Neighbors (MAC Address) |
LAN IIH |
|
7 |
IS Neighbors (SNPA Address) |
LAN IIH |
|
8 |
Padding |
IIH |
|
9 |
LSP Entries |
SNP |
|
10 |
Authentication Information |
IIH, LSP, SNP |
|
128 |
IP Internal Reachability Information |
LSP |
|
129 |
Protocols Supported |
IIH, LSP |
|
130 |
IP External Reachability Information |
L2 LSP |
|
131 |
Inter-Domain Routing Protocol Information |
L2 LSP |
|
132 |
IP Interface Address |
IIH, LSP |
Code 1 to 10 of TLV are defined in ISO 10589 (code 3 and 5 are not shown in the table), and others are defined in RFC 1195.
4.1.5 IS-IS Features Supported
I. Multiple processes
IS-IS supports multiple processes. Multiple processes allow a designated IS-IS process to work in concert with a group of interfaces. This means that a router can run multiple IS-IS processes, and each process corresponds to a unique group of interfaces.
II. Management tag
Management tag carries the management information of the IP address prefixes and BGP community attribute. It controls the redistribution from other routing protocols.
III. LSP fragment extension
If a PDU is too large to fit into a LSP, IS-IS will break it into multiple LSP fragments, which are identified by the LSP identifier field. It is 1 byte long, so an IS-IS router can generate 256 fragments at most.
LSP fragment extension feature allows the IS-IS router to generate more LSP fragments. This feature is implemented by enabling the network management to add additional system IDs to the router. Each system ID represents a virtual system, and each virtual system can generate 256 LSP fragments. With additional system IDs added, an IS-IS router can generate more LSP fragments.
1) Terms
l Originating System
An IS-IS process can act as multiple virtual routers to advertise LSPs. The originating system is the real IS-IS process.
l System-ID
The system ID of the Originating System.
l Additional System-ID
The additional system ID is allocated by the network management. Each additional system ID can generate 256 additional or extended LSP fragments. The additional system ID and the system ID must be unique in the entire routing domain.
l Virtual System
Virtual System is identified by the additional system ID and generates extended LSP fragments, which carry the additional system ID in the LSP ID.
2) Operation modes
The LSP fragment extension feature can be implemented under two modes based on router type.
l mode-1: It applies to the network where some routers do not support LSP fragment extension. In this mode, the originating system announces a link to each LSP virtual system and vice versa. The virtual systems work as the routers connected to the originating system. The drawback of this mode is that only leaf information is advertised in the LSPs of the virtual systems.
l mode-2: It applies to the network where all routers support LSP fragment extension. In this mode, all routers know which originating system a virtual system belongs to when receiving LSPs from the virtual system, and there is no limitation on the link state information of the LSPs.
IV. Dynamic host name mapping mechanism
The dynamic host name mapping mechanism provides the mapping between the host names and the system IDs for the IS-IS routers. The dynamic host name information is announced in the dynamic host name TLV of a LSP.
This mechanism also provides the mapping between a host name and the DIS of a broadcast network, which is announced in a dynamic host name TLV of a pseudonode LSP.
A host name is intuitionally easier to remember than a system ID. After enabling this feature on the router, you can see the host names instead of system IDs after using the display command.
4.1.6 Protocols and Standards
l ISO 10589 ISO IS-IS Routing Protocol
l ISO 9542 ES-IS Routing Protocol
l ISO 8348/Ad2 Network Services Access Points
l RFC 1195 - Use of OSI IS-IS for Routing in TCP/IP and Dual Environments
l RFC 2763 - Dynamic Hostname Exchange Mechanism for IS-IS
l RFC 2966 - Domain-wide Prefix Distribution with Two-Level IS-IS
l RFC 2973 - IS-IS Mesh Groups
l RFC 3277 - IS-IS Transient Blackhole Avoidance
l RFC 3358 - Optional Checksums in ISIS
l RFC 3373 - Three-Way Handshake for IS-IS Point-to-Point Adjacencies
l RFC 3567 - Intermediate System to Intermediate System (IS-IS) Cryptographic Authentication
l RFC 3719 - Recommendations for Interoperable Networks using IS-IS
l RFC 3786 - Extending the Number of IS-IS LSP Fragments Beyond the 256 Limit
l RFC 3787 - Recommendations for Interoperable IP Networks using IS-IS
l RFC 3784 - IS-IS extensions for Traffic Engineering
l RFC 3847 - Restart signaling for IS-IS
4.2 IS-IS Configuration Task List
The following table describes the IS-IS configuration tasks.
|
Configuration Task |
Remarks |
|
|
Required |
||
|
Optional |
||
|
Required |
||
|
Optional |
||
|
Optional |
||
|
Optional |
||
|
Optional |
||
|
Optional |
||
|
Optional |
||
|
Optional |
||
|
Optional |
||
|
Optional |
||
|
Optional |
||
|
Optional |
||
|
Optional |
||
|
Optional |
||
|
Optional |
||
|
Optional |
||
|
Optional |
||
4.3 Configuring IS-IS Basic Functions
4.3.1 Configuration Prerequisites
Before the configuration, accomplish the following tasks first:
l Configure the link layer protocol.
l Configure an IP address for each interface, and make sure all nodes are reachable.
4.3.2 Configuration Procedure
Follow these steps to configure IS-IS basic functions:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
–– |
|
Enable IS-IS routing process and enter its view |
isis [ process-id ] |
Required Not enabled by default |
|
Assign a network entity title (NET) |
network-entity net |
Required Not assigned by default |
|
Specify a router type |
is-level { level-1 | level-1-2 | level-2 } |
Optional The default type is level-1-2. |
|
Return to system view |
quit |
–– |
|
Enter interface view |
interface interface-type interface-number |
–– |
|
Enable an IS-IS process on the interface |
isis enable [ process-id ] [ silent ] |
Required Disabled by default |
|
Specify network type for the interface as P2P |
isis circuit-type p2p |
Optional By default, the network type of an interface depends on the physical media. The network type of a VLAN interface is broadcast. |
|
Specify the adjacency type for the interface |
isis circuit-level [ level-1 | level-1-2 | level-2 ] |
Optional The default type is level-1-2. |
& Note:
If a router’s type is configured as Level-1 or Level-2, the type of interfaces must be the same, which cannot be changed using the isis circuit-level command. However, an interface’s type can be changed with this command when the router’s type is Level-1-2 for the establishment of a specific level adjacency.
4.4 Configuring IS-IS Routing Information Control
4.4.1 Configuration Prerequisites
Before the configuration, accomplish the following tasks first:
l Configure an IP address on each interface, and make sure all nodes are reachable.
l Configure basic IS-IS functions
4.4.2 Configuring IS-IS Protocol Priority
A router can run multiple routing protocols. When a route to the same destination is learned by multiple routing protocols, the one with the highest protocol priority wins.
Follow these steps to configure the IS-IS protocol priority.
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
–– |
|
Enter IS-IS view |
isis [ process-id ] |
–– |
|
Specify an IS-IS priority |
preference [ route-policy route-policy-name | preference ] * |
Optional 15 by default |
4.4.3 Configuring IS-IS Link Cost
There are three ways to configure the interface link cost, from high to low priority:
l Interface cost: Assign a link cost for a single interface.
l Global cost: Assign a link cost for all interfaces.
l Automatically calculated cost: Calculate the link cost based on the bandwidth of an interface.
I. Configure an IS-IS cost for an interface
Follow these steps to configure an interface’s cost:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
–– |
|
Enter IS-IS view |
isis [ process-id ] |
–– |
|
Specify a cost style |
cost-style { narrow | wide | wide-compatible | { compatible | narrow-compatible } [ relax-spf-limit ] } |
Optional narrow by default |
|
Return to system view |
quit |
–– |
|
Enter interface view |
interface interface-type interface-number |
Required |
|
Specify a cost for the interface |
isis cost value [ level-1 | level-2 ] |
Optional Not specified by default |
II. Configure a global IS-IS cost
Follow these steps to configure global IS-IS cost:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enter IS-IS view |
isis [ process-id ] |
— |
|
Specify an IS-IS cost style |
cost-style { narrow | wide | wide-compatible | { compatible | narrow-compatible } [ relax-spf-limit ] } |
Optional Defaulted as narrow. |
|
Specify a global IS-IS cost |
circuit-cost value [ level-1 | level-2 ] |
Required Not specified by default. |
III. Enable automatic IS-IS cost calculation
Follow these steps to enable automatic IS-IS cost calculation:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enter IS-IS view |
isis [ process-id ] |
— |
|
Specify an IS-IS cost style |
cost-style { narrow | wide | wide-compatible | { compatible | narrow-compatible } [ relax-spf-limit ] } |
Optional narrow by default |
|
Configure a bandwidth reference value for automatic IS-IS cost calculation |
bandwidth-reference value |
Optional 100 Mbps by default |
|
Enable automatic IS-IS cost calculation |
auto-cost enable |
Required Disabled by default. |
& Note:
The priority of an interface’s cost from high to low is: the cost configured with the isis cost command, the global cost configured with the circuit-cost command, the cost automatically calculated after the auto-cost command is used, the default cost. The default cost of an interface is 10.
4.4.4 Configuring the Maximum Number of Load Balanced Routes
If there are more than one equal cost routes to the same destination, the traffic can be load balanced to enhance path efficiency.
Follow these steps to configure the maximum number of load balanced routes:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
–– |
|
Enter IS-IS view |
isis [ process-id ] |
–– |
|
Specify the maximum number of load balanced routes |
maximum load-balancing number |
Optional By default, the maximum number of equal-cost load balanced routes is 4. |
4.4.5 Configuring IS-IS Route Summarization
This task is to configure a summary route, so routes falling into the network range of the summary route are summarized with one route for advertisement. Doing so can reduce the size of routing tables, as well as the LSP and LSDB generated by the router itself. Both IS-IS and redistributed routes can be summarized.
Follow these steps to configure route summarization:
|
To do… |
Use the command... |
Remarks |
|
Enter system view |
system-view |
— |
|
Enter IS-IS view |
isis [ process-id ] |
–– |
|
Configure IS-IS route summarization |
summary ip-address { mask | mask-length } [ avoid-feedback | generate_null0_route | tag tag | [ level-1 | level-1-2 | level-2 ] ] * |
Required Not configured by default |
& Note:
The cost of the summary route is the lowest cost among those summarized routes.
4.4.6 Advertising a Default Route
Follow these steps to advertise a default route:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
–– |
|
Enter IS-IS view |
isis [ process-id ] |
— |
|
Advertise a default route |
default-route-advertise [ route-policy route-policy-name ] [ level-1 | level-2 | level-1-2 ] |
Optional By default, this function is disabled. |
& Note:
The default route is only advertised to routers at the same level. You can use a routing policy to generate the default route only when a local routing entry is matched by the policy.
4.4.7 Configuring Inbound Route Filtering
Follow these steps to configure inbound route filtering:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
–– |
|
Enter IS-IS view |
isis [ process-id ] |
–– |
|
Configure inbound route filtering |
filter-policy { acl-number | ip-prefix ip-prefix-name | route-policy policy-name } import |
Required Not configured by default |
4.4.8 Configuring Route Redistribution
Follow these steps to configure IS-IS route redistribution from other routing protocols:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
–– |
|
Enter IS-IS view |
isis [ process-id ] |
–– |
|
Redistribute routes from other routing protocols |
import-route { isis [ process-id ] | ospf [ process-id ] | rip [ process-id ] | bgp [ allow-ibgp ] | direct | static } [ cost value | cost-type { external | internal } | [ level-1 | level-1-2 | level-2 ] | route-policy route-policy-name | tag tag-value ] * |
Required No route is redistributed by default. If no level is specified, routes are redistributed into the Level-2 routing table by default. |
|
Configure a filtering policy to filter redistributed routes |
filter-policy { acl-number | ip-prefix ip-prefix-name | route-policy route-policy-name } export [ isis process-id | ospf process-id | rip process-id | bgp | direct | static] |
Optional Not configured by default |
4.4.9 Configuring Route Leaking
With this feature enabled, the Level-1-2 router can advertise both Level-1 and Level-2 area routing information to the Level-1 router.
Follow these steps to configure the route leaking:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
–– |
|
Enter IS-IS view |
isis [ process-id ] |
–– |
|
Enable route leaking |
import-route isis level-2 into level-1 [ filter-policy { acl-number | ip-prefix ip-prefix-name | route-policy route-policy-name } | tag tag-value ] * |
Required Disabled by default |
& Note:
l If a filter policy is specified, only routes passing it can be advertised into Level-1 area.
l You can specify a routing policy in the import-route isis level-2 into level-1 command to filter routes from Level-2 to Level-1. Other routing policies specified for route reception and redistribution does not affect the route leaking.
4.5 Tuning and Optimizing IS-IS Network
4.5.1 Configuration Prerequisites
Before the configuration, accomplish the following tasks first:
l Configure an IP address on each interface, and make sure all nodes are reachable.
l Configure basic IS-IS functions
4.5.2 Configuring a DIS Priority for an Interface
On an IS-IS broadcast network, a router should be selected as the DIS at a specific level, Level-1 or Level-2. You can specify a DIS priority at a level for an interface. The bigger the interface’s priority value, the more likelihood it becomes the DIS.
Follow these steps to configure a DIS priority for an interface:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
–– |
|
Enter interface view |
interface interface-type interface-number |
–– |
|
Specify a DIS priority for the interface |
isis dis-priority value [ level-1 | level-2 ] |
Optional 64 by default |
& Note:
If multiple routers in the broadcast network have the same highest DIS priority, the router with the highest MAC address becomes the DIS. This rule applies even all routers’ DIS priority is 0.
4.5.3 Configuring IS-IS Timers
Follow these steps to configure the IS-IS timers:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
–– |
|
Enter interface view |
interface interface-type interface-number |
–– |
|
Specify the interval between hello packets |
isis timer hello seconds [ level-1 | level-2 ] |
Optional 10 seconds by default |
|
Specify the number of hello packets; within the time for receiving the specified hello packets, if no hello packets are received on the interface, the neighbor is considered dead. |
isis timer holding-multiplier value [ level-1 | level-2 ] |
Optional 3 by default |
|
Specify the interval for sending CSNP packets |
isis timer csnp seconds [ level-1 | level-2 ] |
Optional 10 seconds by default |
|
Specify the interval for sending LSP packets |
isis timer lsp time [ count count ] |
Optional 33 milliseconds by default |
|
Specify the LSP retransmission interval on the point-to-point link |
isis timer retransmit seconds |
Optional 5 seconds by default |
& Note:
l On the broadcast link, you can specify different intervals for Level-1 and Level-2 hello packets. The point-to-point link does not distinguish between Level-1 and Level-2 hello packets, so you need not specify a level.
l Hello packets are used to establish and maintain neighbor relationships. If no hello packets are received from a neighbor within the time for receiving the specified hello packets, the neighbor is considered dead.
l CSNPs are sent by the DIS on a broadcast network for LSDB synchronization. If no Level-1 or Level-2 is included, the specified CSNP interval applies to the current level.
l On a point-to-point link, if there is no response to a LSP sent by the local router within the specified retransmission interval, the LSP is considered lost, and the same LSP will be retransmitted. On broadcast links, responses to the sent LSPs are not required.
l The interval between hello packets sent by the DIS is 1/3 the hello interval set by the isis timer hello command.
4.5.4 Configuring LSP Parameters
An IS-IS router periodically advertises all the local LSPs to maintain the LSP synchronization in the entire area.
A LSP is given an aging time when generated by the router. When the LSP is received by another router, its aging time begins to decrease. If the receiving router does not get the update for the LSP within the aging time, the LSP will be deleted from the LSDB.
The router will discard a LSP with incorrect checksum. You can configure the router to ignore the incorrect checksum, which means a LSP will be processed even with an incorrect LSP checksum.
On the NBMA network, the router will flood a new LSP received from an interface to other interfaces. This can cause the LSP re-flooding on the high connectivity networks. To avoid this problem, you can make a mesh group of interfaces. The interface in this group will only flood the new LSP to interfaces outside the mesh group.
Follow these steps to configure the LSP parameters:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
–– |
|
Enter IS-IS view |
isis [ process-id ] |
–– |
|
Specify a LSP refresh interval |
timer lsp-refresh seconds |
Optional 900 seconds by default |
|
Specify the maximum LSP aging time |
timer lsp-max-age seconds |
Optional 1200 seconds by default |
|
Specify LSP generation interval |
timer lsp-generation max-interval [ min-interval [ inc-interval ] ] [ level-1 | level-2 ] |
Optional 2 seconds by default |
|
Enable the LSP flash flooding function |
flash-flood [ flood-count flooding-count | max-timer-interval flooding-interval | [ level-1 | level-2 ] ] * |
Optional Not enabled by default |
|
Enable the checksum ignoring function |
ignore-lsp-checksum-error |
Optional Disabled by default |
|
Specify the maximum size of the originated Level-1 or Level-2 LSP |
lsp-length originate size [ level-1 | level-2 ] |
Optional Both are 1497 bytes by default |
|
Specify the maximum size of the received Level-1 or Level-2 LSP |
lsp-length receive size |
Optional Both are 1497 bytes by default |
|
Enable LSP fragment extension |
lsp-fragments-extend [ level-1 | level-2 | level-1-2 ] [ mode-1 | mode-2 ] |
Optional Disabled by default |
|
Create a virtual system |
virtual-system virtual-system-id |
Optional Not created by default |
|
Return to system view |
quit |
–– |
|
Enter interface view |
interface interface-type interface-number |
–– |
|
Add the interface to a mesh group |
isis mesh-group [ mesh-group-number | mesh-blocked ] |
Optional Not added by default |
& Note:
At least one virtual system needs to be created to generate extended LSP fragments.
4.5.5 Configuring SPF Parameters
When the LSDB changes in an IS-IS network, a routing calculation starts. If the changes happen frequently, it will take a lot of system resources. You can set the interval for SPF calculation for efficiency consideration.
The SPF calculation may occupy the CPU for a long time when the routing entries are too many. You can split the SPF calculation time into multiple durations with a default interval of 10s in between.
Follow these steps to configure the SPF parameters:
|
To do… |
Use the command... |
Remarks |
|
Enter system view |
system-view |
–– |
|
Enter IS-IS view |
isis [ process-id ] |
–– |
|
Configure the SPF calculation intervals |
timer spf max-interval [ min-interval [ inc-interval ] ] |
Optional By default, the maximum interval is 10 seconds, the minimum interval is 0 milliseconds, and the incremental interval is 0 milliseconds. |
|
Specify the SPF calculation duration |
spf-slice-size duration-time |
Optional Not specified by default The default is 0, meaning the SPF calculation time is not split. |
4.5.6 Configuring Dynamic Host Name Mapping
Follow these steps to configure the dynamic host name mapping:
|
To do… |
Use the command... |
Remarks |
|
Enter system view |
system-view |
–– |
|
Enter IS-IS view |
isis [ process-id ] |
–– |
|
Assign a local host name |
is-name sys-name |
Required No name is assigned by default. |
|
Assign a remote host name and create a mapping between the host name and a system ID |
is-name map sys-id map-sys-name |
Optional One system ID only maps to one name. No name is assigned by default |
|
Return to system view |
quit |
–– |
|
Enter interface view |
interface interface-type interface-number |
–– |
|
Assign a DIS name for the local network |
isis dis-name symbolic-name |
Optional Not assigned by default This command is only applicable on the router with dynamic host name mapping enabled. It is invalid on point-to-point links. |
& Note:
The local host name on the local IS overwrites the remote host name on the remote IS.
4.5.7 Configuring IS-IS Authentication
For area authentication, the area authentication password is encapsulated into the Level-1 LSP, CSNP, and PSNP packets. On area authentication enabled routers in the same area, the authentication mode and password must be same.
For routing domain authentication, the domain authentication password is encapsulated into the Level-2 LSP, CSNP, and PSNP packets. The domain authentication enabled Level-2 routers in the backbone must adopt the same authentication mode and share the same password.
The authentication configured on an interface applies to the hello packet in order to authenticate neighbors. All interfaces within a network must share the same authentication password at the same level.
Follow these steps to configure the authentication function:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
–– |
|
Enter IS-IS view |
isis [ process-id ] |
–– |
|
Specify the area authentication mode |
area-authentication-mode { simple | md5 } password [ ip | osi ] |
Required No authentication is enabled for Level-1 routing information, and no password is specified by default. |
|
Specify the routing domain authentication mode |
domain-authentication-mode { simple | md5 } password [ ip | osi ] |
Required No authentication is enabled for Level-2 routing information, and no password is specified by default. |
|
Return to system view |
quit |
–– |
|
Enter interface view |
interface interface-type interface-number |
–– |
|
Specify the authentication mode and password |
isis authentication-mode { simple | md5 } password [ { level-1 | level-2 } [ ip | osi ] ] |
Optional No authentication and password are available by default. |
& Note:
The level-1 and level-2 keywords in the isis authentication-mode command are only supported on VLAN interface of the switch, and the interface must be configured with the isis enable command.
4.5.8 Configuring LSDB Overload Tag
When the overload tag is set on a router, other routers will not send packets to the router except for the packets destined to the network directly connected to the router.
The overload tag can be used for troubleshooting as well. You can temporarily isolate a router from the IS-IS network by setting the overload tag.
Follow these steps to configure the LSDB overload tag:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
–– |
|
Enter IS-IS view |
isis [ process-id ] |
–– |
|
Configure the overload tag |
set-overload [ on-startup start-from-nbr system-id [ timeout [ nbr-timeout ] ] ] [ allow { interlevel | external } * ] set-overload [ on-startup [ wait-for-bgp ] [ timeout ] ] [ allow { interlevel | external } * ] |
Required Not configured by default |
4.5.9 Logging the Adjacency Changes
Follow these steps to configure this task:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
–– |
|
Enter IS-IS view |
isis [ process-id ] |
–– |
|
Enable to log the adjacency changes |
log-peer-change |
Required Enabled by default |
& Note:
With this feature enabled, the state information of the adjacency is displayed on the configuration terminal.
4.5.10 Enabling an Interface to Send Small Hello Packets
Follow these steps to enable an interface to send small hello packets (without the padding field):
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
–– |
|
Enter interface view |
interface interface-type interface-number |
–– |
|
Enable the interface to send small hello packets that have no padding field |
isis small-hello |
Required Standard hello packets are sent by default. |
4.5.11 Enabling IS-IS Trap
Follow these steps to enable IS-IS trap:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
–– |
|
Enter IS-IS view |
isis [ process-id ] |
–– |
|
Enable SNMP Trap |
is-snmp-traps enable |
Required Enabled by default |
4.6 Displaying and Maintaining IS-IS Configuration
|
To do… |
Use the command… |
Remarks |
|
Display brief IS-IS information |
display isis brief [ process-id ] |
Available in any view |
|
Display information about IS-IS enabled interfaces |
display isis interface [ verbose ] [ process-id ] |
Available in any view |
|
Display IS-IS license information |
display isis license |
Available in any view |
|
Display IS-IS LSDB information |
display isis lsdb [ [ l1 | l2 | level-1 | level-2 ] | [ lsp-id LSPID | lsp-name lspname ] | local | verbose ] * [ process-id ] |
Available in any view |
|
Display IS-IS mesh group information |
display isis mesh-group [ process-id ] |
Available in any view |
|
Display the mapping table between the host name and system ID |
display isis name-table [ process-id ] |
Available in any view |
|
Display IS-IS neighbor information |
display isis peer [ verbose ] [ process-id ] |
Available in any view |
|
Display IS-IS routing information |
display isis route [ ipv4 ] [ [ level-1 | level-2 ] | verbose ] * [ process-id ] |
Available in any view |
|
Display SPF calculation log information |
display isis spf-log [ process-id ] |
Available in any view |
|
Display statistic about an IS-IS process |
display isis statistics [ level-1 | level-2 | level-1-2 ] [ process-id ] |
Available in any view |
|
Clear the data structure information of an IS-IS process |
reset isis all [ process-id ] |
Available in user view |
|
Clear the data structure information of an IS-IS neighbor |
reset isis peer system-id [ process-id ] |
Available in user view |
4.7 IS-IS Configuration Example
4.7.1 IS-IS Basic Configuration
I. Network requirements
As shown in Figure 4-14, Switch A, B, C and Switch D reside in an IS-IS AS. Switch A and B are Level-1 switches, Switch D is a Level-2 switch and Switch C is a Level-1-2 switch. Switch A, B and C are in area 10, while Switch D is in area 20.
II. Network diagram
Figure 4-14 Network diagram for IS-IS basic configuration
III. Configuration procedure
1) Configure IP addresses for interfaces (omitted)
2) Configure IS-IS
# Configure Switch A.
<SwitchA> system-view
[SwitchA] isis 1
[SwitchA-isis-1] is-level level-1
[SwitchA-isis-1] network-entity 10.0000.0000.0001.00
[SwitchA-isis-1] quit
[SwitchA] interface vlan-interface 100
[SwitchA-Vlan-interface100] isis enable 1
[SwitchA-Vlan-interface100] quit
# Configure Switch B.
<SwitchB> system-view
[SwitchB] isis 1
[SwitchB-isis-1] is-level level-1
[SwitchB-isis-1] network-entity 10.0000.0000.0002.00
[SwitchB-isis-1] quit
[SwitchB] interface vlan-interface 200
[SwitchB-Vlan-interface200] isis enable 1
[SwitchB-Vlan-interface200] quit
# Configure Switch C.
<SwitchC> system-view
[SwitchC] isis 1
[SwitchC-isis-1] network-entity 10.0000.0000.0003.00
[SwitchC-isis-1] quit
[SwitchC] interface vlan-interface 100
[SwitchC-Vlan-interface100] isis enable 1
[SwitchC-Vlan-interface100] quit
[SwitchC] interface vlan-interface 200
[SwitchC-Vlan-interface200] isis enable 1
[SwitchC-Vlan-interface200] quit
[SwitchC] interface vlan-interface 300
[SwitchC-Vlan-interface300] isis enable 1
[SwitchC-Vlan-interface300] quit
# Configure Switch D.
<SwitchD> system-view
[SwitchD] isis 1
[SwitchD-isis-1] is-level level-2
[SwitchD-isis-1] network-entity 20.0000.0000.0004.00
[SwitchD-isis-1] quit
[SwitchD] interface vlan-interface 100
[SwitchD-Vlan-interface100] isis enable 1
[SwitchD-Vlan-interface100] quit
[SwitchD] interface vlan-interface 300
[SwitchD-Vlan-interface300] isis enable 1
[SwitchD-Vlan-interface300] quit
3) Verify the configuration
# Display the IS-IS LSDB of each switch to check the LSP integrity.
[SwitchA] display isis lsdb
Database information for ISIS(1)
--------------------------------
Level-1 Link State Database
LSPID Seq Num Checksum Holdtime Length ATT/P/OL
--------------------------------------------------------------------------
0000.0000.0001.00-00* 0x00000004 0xdf5e 1096 68 0/0/0
0000.0000.0002.00-00 0x00000004 0xee4d 1102 68 0/0/0
0000.0000.0002.01-00 0x00000001 0xdaaf 1102 55 0/0/0
0000.0000.0003.00-00 0x00000009 0xcaa3 1161 111 1/0/0
0000.0000.0003.01-00 0x00000001 0xadda 1112 55 0/0/0
*-Self LSP, +-Self LSP(Extended), ATT-Attached, P-Partition, OL-Overload
[SwitchB] display isis lsdb
Database information for ISIS(1)
--------------------------------
Level-1 Link State Database
LSPID Seq Num Checksum Holdtime Length ATT/P/OL
--------------------------------------------------------------------------
0000.0000.0001.00-00 0x00000006 0xdb60 988 68 0/0/0
0000.0000.0002.00-00* 0x00000008 0xe651 1189 68 0/0/0
0000.0000.0002.01-00* 0x00000005 0xd2b3 1188 55 0/0/0
0000.0000.0003.00-00 0x00000014 0x194a 1190 111 1/0/0
0000.0000.0003.01-00 0x00000002 0xabdb 995 55 0/0/0
*-Self LSP, +-Self LSP(Extended), ATT-Attached, P-Partition, OL-Overload
[SwitchC] display isis lsdb
Database information for ISIS(1)
--------------------------------
Level-1 Link State Database
LSPID Seq Num Checksum Holdtime Length ATT/P/OL
--------------------------------------------------------------------------
0000.0000.0001.00-00 0x00000006 0xdb60 847 68 0/0/0
0000.0000.0002.00-00 0x00000008 0xe651 1053 68 0/0/0
0000.0000.0002.01-00 0x00000005 0xd2b3 1052 55 0/0/0
0000.0000.0003.00-00* 0x00000014 0x194a 1051 111 1/0/0
0000.0000.0003.01-00* 0x00000002 0xabdb 854 55 0/0/0
*-Self LSP, +-Self LSP(Extended), ATT-Attached, P-Partition, OL-Overload
Level-2 Link State Database
LSPID Seq Num Checksum Holdtime Length ATT/P/OL
--------------------------------------------------------------------------
0000.0000.0003.00-00* 0x00000012 0xc93c 842 100 0/0/0
0000.0000.0004.00-00 0x00000026 0x331 1173 84 0/0/0
0000.0000.0004.01-00 0x00000001 0xee95 668 55 0/0/0
*-Self LSP, +-Self LSP(Extended), ATT-Attached, P-Partition, OL-Overload
[SwitchD] display isis lsdb
Database information for ISIS(1)
--------------------------------
Level-2 Link State Database
LSPID Seq Num Checksum Holdtime Length ATT/P/OL
-------------------------------------------------------------------------------
0000.0000.0003.00-00 0x00000013 0xc73d 1003 100 0/0/0
0000.0000.0004.00-00* 0x0000003c 0xd647 1194 84 0/0/0
0000.0000.0004.01-00* 0x00000002 0xec96 1007 55 0/0/0
*-Self LSP, +-Self LSP(Extended), ATT-Attached, P-Partition, OL-Overload
# Display the IS-IS routing information of each switch. Level-1 switches should have a default route with the next hop being the Level-1-2 switch. The Level-2 switch should have both routing information of Level-1 and Level-2.
[SwitchA] display isis route
Route information for ISIS(1)
-----------------------------
ISIS(1) IPv4 Level-1 Forwarding Table
-------------------------------------
IPV4 Destination IntCost ExtCost ExitInterface NextHop Flags
--------------------------------------------------------------------------
10.1.1.0/24 10 NULL Vlan100 Direct R/L/-
10.1.2.0/24 20 NULL Vlan100 10.1.1.1 R/-/-
192.168.0.0/24 20 NULL Vlan100 10.1.1.1 R/-/-
0.0.0.0/0 10 NULL Vlan100 10.1.1.1 R/-/-
Flags: R-Added to RM, L-Advertised in LSPs, U-Up/Down Bit Set
[SwitchC] display isis route
Route information for ISIS(1)
-----------------------------
ISIS(1) IPv4 Level-1 Forwarding Table
-------------------------------------
IPV4 Destination IntCost ExtCost ExitInterface NextHop Flags
--------------------------------------------------------------------------
192.168.0.0/24 10 NULL Vlan300 Direct R/L/-
10.1.1.0/24 10 NULL Vlan100 Direct R/L/-
10.1.2.0/24 10 NULL Vlan200 Direct R/L/-
Flags: R-Added to RM, L-Advertised in LSPs, U-Up/Down Bit Set
ISIS(1) IPv4 Level-2 Forwarding Table
-------------------------------------
IPV4 Destination IntCost ExtCost ExitInterface NextHop Flags
--------------------------------------------------------------------------
192.168.0.0/24 10 NULL Vlan300 Direct R/L/-
10.1.1.0/24 10 NULL Vlan100 Direct R/L/-
10.1.2.0/24 10 NULL Vlan200 Direct R/L/-
172.16.0.0/16 20 NULL Vlan300 192.168.0.2 R/-/-
Flags: R-Added to RM, L-Advertised in LSPs, U-Up/Down Bit Set
[SwitchD] display isis route
Route information for ISIS(1)
-----------------------------
ISIS(1) IPv4 Level-2 Forwarding Table
-------------------------------------
IPV4 Destination IntCost ExtCost ExitInterface NextHop Flags
--------------------------------------------------------------------------
192.168.0.0/24 10 NULL Vlan300 Direct R/L/-
10.1.1.0/24 20 NULL Vlan300 192.168.0.1 R/-/-
10.1.2.0/24 20 NULL Vlan300 192.168.0.1 R/-/-
172.16.0.0/16 10 NULL Vlan100 Direct R/L/-
Flags: R-Added to RM, L-Advertised in LSPs, U-Up/Down Bit Set
4.7.2 DIS Selection Configuration
I. Network requirements
As shown in Figure 4-15, Switch A, B, C and Switch D reside in IS-IS area 10 on a broadcast network (Ethernet). Switch A and Switch B are Level-1-2 routers, Switch C is a Level-1 router, and Switch D is a Level-2 router.
Change the DIS priority of Switch A to make it selected as the Level-1-2 DIS router.
II. Network diagram

Figure 4-15 Network diagram for DIS selection
III. Configuration procedure
1) Configure an IP address for each interface (omitted)
2) Enable IS-IS
# Configure Switch A.
<SwitchA> system-view
[SwitchA] isis 1
[SwitchA-isis-1] network-entity 10.0000.0000.0001.00
[SwitchA-isis-1] quit
[SwitchA] interface vlan-interface 100
[SwitchA-Vlan-interface100] isis enable 1
[SwitchA-Vlan-interface100] quit
# Configure Switch B.
<SwitchB> system-view
[SwitchB] isis 1
[SwitchB-isis-1] network-entity 10.0000.0000.0002.00
[SwitchB-isis-1] quit
[SwitchB] interface vlan-interface 100
[SwitchB-Vlan-interface100] isis enable 1
[SwitchB-Vlan-interface100] quit
# Configure Switch C.
<SwitchC> system-view
[SwitchC] isis 1
[SwitchC-isis-1] network-entity 10.0000.0000.0003.00
[SwitchC-isis-1] is-level level-1
[SwitchC-isis-1] quit
[SwitchC] interface vlan-interface 100
[SwitchC-Vlan-interface100] isis enable 1
[SwitchC-Vlan-interface100] quit
# Configure Switch D.
<SwitchD> system-view
[SwitchD] isis 1
[SwitchD-isis-1] network-entity 10.0000.0000.0004.00
[SwitchD-isis-1] is-level level-2
[SwitchD-isis-1] quit
[SwitchD] interface vlan-interface 100
[SwitchD-Vlan-interface100] isis enable 1
[SwitchD-Vlan-interface100] quit
# Display information about IS-IS neighbors of Switch A.
[SwitchA] display isis peer
Peer information for ISIS(1)
----------------------------
System Id: 0000.0000.0002
Interface: Vlan-interface100 Circuit Id: 0000.0000.0003.01
State: Up HoldTime: 21s Type: L1(L1L2) PRI: 64
System Id: 0000.0000.0003
Interface: Vlan-interface100 Circuit Id: 0000.0000.0003.01
State: Up HoldTime: 27s Type: L1 PRI: 64
System Id: 0000.0000.0002
Interface: Vlan-interface100 Circuit Id: 0000.0000.0004.01
State: Up HoldTime: 28s Type: L2(L1L2) PRI: 64
System Id: 0000.0000.0004
Interface: Vlan-interface100 Circuit Id: 0000.0000.0004.01
State: Up HoldTime: 30s Type: L2 PRI: 64
# Display information about IS-IS interfaces of Switch A.
[SwitchA] display isis interface
Interface information for ISIS(1)
---------------------------------
Interface: Vlan-interface100
Id IPV4.State IPV6.State MTU Type DIS
001 Up Down 1497 L1/L2 No/No
# Display information about IS-IS interfaces of Switch C.
[SwitchC] display isis interface
Interface information for ISIS(1)
---------------------------------
Interface: Vlan-interface100
Id IPV4.State IPV6.State MTU Type DIS
001 Up Down 1497 L1/L2 Yes/No
# Display information about IS-IS interfaces of Switch D.
[SwitchD] display isis interface
Interface information for ISIS(1)
---------------------------------
Interface: Vlan-interface100
Id IPV4.State IPV6.State MTU Type DIS
001 Up Down 1497 L1/L2 No/Yes
& Note:
By using the default DIS priority, Switch C is the Level-1 DIS, and Switch D is the Level-2 DIS. The pseudonodes of Level-1 and Level-2 are 0000.0000.0003.01 and 0000.0000.0004.01 respectively.
3) Configure the DIS priority of Switch A.
[SwitchA] interface vlan-interface 100
[SwitchA-Vlan-interface100] isis dis-priority 100
[SwitchA-Vlan-interface100] quit
# Display IS-IS neighbors of Switch A.
[SwitchA] display isis peer
Peer information for ISIS(1)
----------------------------
System Id: 0000.0000.0002
Interface: Vlan-interface100 Circuit Id: 0000.0000.0001.01
State: Up HoldTime: 21s Type: L1(L1L2) PRI: 64
System Id: 0000.0000.0003
Interface: Vlan-interface100 Circuit Id: 0000.0000.0001.01
State: Up HoldTime: 27s Type: L1 PRI: 64
System Id: 0000.0000.0002
Interface: Vlan-interface100 Circuit Id: 0000.0000.0001.01
State: Up HoldTime: 28s Type: L2(L1L2) PRI: 64
System Id: 0000.0000.0004
Interface: Vlan-interface100 Circuit Id: 0000.0000.0001.01
State: Up HoldTime: 30s Type: L2 PRI: 64
# Display information about IS-IS interfaces of Switch A.
[SwitchA] display isis interface
Interface information for ISIS(1)
---------------------------------
Interface: Vlan-interface100
Id IPV4.State IPV6.State MTU Type DIS
001 Up Down 1497 L1/L2 Yes/Yes
& Note:
After the DIS priority configuration, Switch A becomes the Level-1-2 DIS, and the pseudonode is 0000.0000.0001.01.
# Display information about IS-IS neighbors and interfaces of Switch C.
[SwitchC] display isis peer
Peer information for ISIS(1)
----------------------------
System Id: 0000.0000.0002
Interface: Vlan-interface100 Circuit Id: 0000.0000.0001.01
State: Up HoldTime: 25s Type: L1 PRI: 64
System Id: 0000.0000.0001
Interface: Vlan-interface100 Circuit Id: 0000.0000.0001.01
State: Up HoldTime: 7s Type: L1 PRI: 100
[SwitchC] display isis interface
Interface information for ISIS(1)
---------------------------------
Interface: Vlan-interface100
Id IPV4.State IPV6.State MTU Type DIS
001 Up Down 1497 L1/L2 No/No
# Display information about IS-IS neighbors and interfaces of Switch D.
[SwitchD] display isis peer
Peer information for ISIS(1)
----------------------------
System Id: 0000.0000.0001
Interface: Vlan-interface100 Circuit Id: 0000.0000.0001.01
State: Up HoldTime: 9s Type: L2 PRI: 100
System Id: 0000.0000.0002
Interface: Vlan-interface100 Circuit Id: 0000.0000.0001.01
State: Up HoldTime: 28s Type: L2 PRI: 64
[SwitchD] display isis interface
Interface information for ISIS(1)
---------------------------------
Interface: Vlan-interface100
Id IPV4.State IPV6.State MTU Type DIS
001 Up Down 1497 L1/L2 No/No
Chapter 5 BGP Configuration
& Note:
The term “router” in this document refers to a router in a generic sense or an Ethernet switch running routing protocols, and BGP refers to BGP-4 in this document.
5.1 BGP Overview
Three early versions of BGP are BGP-1 (RFC1105), BGP-2 (RFC1163) and BGP-3 (RFC1267). The current version in use is BGP-4 (RFC1771). BGP-4 is rapidly becoming the de facto Internet exterior routing protocol standard and is commonly used between ISPs.
The characteristics of BGP are as follows:
l Focusing on the control of route propagation and the selection of optimal routes rather than the discovery and calculation of routes, which makes BGP, an external routing protocol different from internal routing protocols such as OSPF and RIP
l Using TCP as its transport layer protocol to enhance its reliability
l Supporting CIDR
l Substantially reducing bandwidth occupation by advertising updated routes only and applicable to advertising a great amount of routing information on the Internet
l Eliminating routing loops completely by adding AS path information to BGP routes
l Providing abundant routing policies, allowing implementing flexible route filtering and selection
l Easy to extend, satisfying new network developments
A router advertising BGP messages is called a BGP speaker, which exchanges new routing information with other BGP speakers. When a BGP speaker receives a new route or a route better than the current one from another AS, it will advertise the route to all the other BGP speakers in the local AS.
BGP speakers call each other peers, and several associated peers form a peer group.
BGP runs on a router in one of the following two modes:
l IBGP (Interior BGP)
l EBGP (External BGP)
The BGP is called IBGP when it runs within an AS and is called EBGP when it runs between ASs.
5.1.1 Formats of BGP Messages
I. Message header format
BGP message involves five types:
l Open message
l Update message
l Notification message
l Keep-alive message
l Route-refresh message
They have the same header, as shown below:

Figure 5-1 BGP message header
l Marker: The 16-octet field is used for BGP authentication calculation. If no authentication information is available, then the Marker must be all ones.
l Length: The 2-octet unsigned integer indicates the total length of the message.
l Type: This 1-octet unsigned integer indicates the type code of the message. The following type codes are defined: 1–Open 2-Update 3-Notification 4–Keepalive 5–Route-refresh. The former four are defined in RFC1771, the latter one defined in RFC2918.
II. Open
After a TCP connection is established, the first message sent by each side is an Open message for peer relationship establishment. The Open message contains the following fields:

Figure 5-2 BGP open message format
l Version: This 1-octet unsigned integer indicates the protocol version number of the message. The current BGP version number is 4.
l My Autonomous System: This 2-octet unsigned integer indicates the Autonomous System number of the sender.
l Hold Time: When establishing peer relationship, two parties negotiate an identical Hold time. If no Keepalive or Update is received from a peer after the Hold time elapses, the BGP connection is considered down.
l BGP Identifier: In IP address format, identifying the BGP router
l Opt Parm Len (Optional Parameters Length): Length of optional parameters, set to 0 if no optional parameter is available
III. Update
The Update message is used to exchange routing information between peers. It can advertise a feasible route or remove multiple unfeasible routes. Its format is shown below:

Figure 5-3 BGP Update message format
Each Update message can advertise a group of feasible routes with similar attributes, which are contained in the Network Layer Reachable Information field. The Path Attributes field carries attributes of these routes that are used by BGP for routing. Each message can also carry multiple withdrawn routes in the Withdrawn Routes field.
l Unfeasible Routes Length: The total length of the Withdrawn Routes field in octets. A value of 0 indicates neither route is being withdrawn from service, nor Withdrawn Routes field is present in this Update message.
l Withdrawn Routes: This is a variable length field that contains a list of IP prefixes of routes that are being withdrawn from service.
l Total Path Attribute Length: Total length of the Path Attributes field in octets. A value of 0 indicates that no Network Layer Reachability Information field is present in this Update message.
l Path Attributes: List of path attributes related to NLRI. Each path attribute is a triple <attribute type, attribute length, attribute value> of variable length. BGP uses these attributes to avoid routing loops, perform routing and protocol extension.
l NLRI (Network Layer Reachability Information): Reachability information is encoded as one or more 2-tuples of the form <length, prefix>.
IV. Notification
A Notification message is sent when an error is detected. The BGP connection is closed immediately after sending it. Notification message format is shown below:

Figure 5-4 BGP Notification message format
l Error Code: Type of Notification.
l Error Subcode: Specific information about the nature of the reported error.
l Data: Used to diagnose the reason for the Notification. The contents of the Data field depend upon the Error Code and Error Subcode. Erroneous part of data is recorded. The Data field length is variable.
V. Keepalive
Keepalive messages are sent between peers to maintain connectivity. Its format contains only the message header.

Figure 5-5 BGP Route-refresh message format
AFI: Address Family Identifier.
Res: Reserved. Set to 0.
SAFI: Subsequent Address Family Identifier.
5.1.2 Path Attributes
This section discusses the path attributes of the Update message.
I. Classification of path attributes
Path attributes fall into four categories:
l Well-known mandatory: Must be recognized by all BGP routers and must be included in every update message. Routing information error occurs without this attribute.
l Well-known discretionary: Can be recognized by all BGP routers and optional to be included in every update message as needed.
l Optional transitive: Transitive attribute between ASs. A BGP router not supporting this attribute can still receive routes with this attribute and advertise them to other peers.
l Optional non-transitive: If a BGP router does not support this attribute, it will not advertise routes with this attribute.
The usage of each BGP path attributes is described in the following table.
Table 5-1 Usage of BGP path attributes
|
Name |
Category |
|
ORIGIN |
Well-known mandatory |
|
AS_PATH |
Well-known mandatory |
|
NEXT_HOP |
Well-known mandatory |
|
LOCAL_PREF |
Well-known discretionary |
|
ATOMIC_AGGREGATE |
Well-known discretionary |
|
AGGREGATOR |
Optional transitive |
|
COMMUNITY |
Optional transitive |
|
MULTI_EXIT_DISC (MED) |
Optional non-transitive |
|
ORIGINATOR_ID |
Optional non-transitive |
|
CLUSTER_LIST |
Optional non-transitive |
II. Usage of BGP path attributes
1) ORIGIN
ORIGIN is a well-known mandatory attribute and defines the origin of routing information and how a route becomes a BGP route. It involves three types:
l IGP: Has the highest priority. Routes added to the BGP routing table using the network command have the IGP attribute.
l EGP: Has the second highest priority. Routes obtained via EGP have the EGP attribute.
l incomplete: Has the lowest priority. The source of routes with this attribute is unknown. Routes redistributed using the import-route command have the incomplete attribute.
2) AS_PATH
AS_PATH is a well-known mandatory attribute. This attribute identifies the autonomous systems through which routing information carried in this Update message has passed. When a route is advertised from the local AS to another AS, each passed AS number is added into the AS_PATH attribute, thus the receiver can determine ASs to route massages back. The number of the AS closest with the receiver’s AS is leftmost, as shown below:

Figure 5-6 AS_PATH attribute
In general, a BGP router receives no routes containing the local AS number to avoid routing loops.
& Note:
The current implementation supports using the peer allow-as-loop command to receive routes containing the local AS number to meet special requirements.
AS_PATH attribute can be used for route selection and filtering. BGP gives priority to the route with the shortest AS_PATH length if other factors are the same. As shown in the above figure, the BGP router in AS50 gives priority to the route passing AS40 for sending information to the destination 8.0.0.0.
In some applications, you can apply a routing policy to control BGP route selection by modifying the AS path length.
By configuring an AS path filtering list, you can filter routes based on AS numbers contained in the AS_PATH attribute.
3) NEXT_HOP
Different from IGP, the NEXT_HOP attribute of BGP may not be the IP address of a neighboring router. It involves three types of values, as shown in Figure 5-7.
l When advertising a self-originated route to an EBGP peer, a BGP speaker sets the NEXT_HOP for the route to the address of its sending interface.
l When sending a received route to an EBGP peer, a BGP speaker sets the NEXT_HOP for the route to the address of the sending interface.
l When sending a route received from an EBGP peer to an IBGP peer, a BGP speaker does not modify the NEXT_HOP attribute. If load-balancing is configured, the NEXT_HOP attribute will be modified. For load-balancing information, refer to BGP Route Selection.

4) MED (MULTI_EXIT_DISC)
The MED attribute is exchanged between two neighboring ASs, each of which will not advertise the attribute to any other AS.
Similar with metrics used by IGP, MED is used to determine the best route for traffic going into an AS. When a BGP router obtains multiple routes to the same destination but with different next hops, it considers the route with the smallest MED value the best route if other conditions are the same. As shown below, traffic from AS10 to AS20 travels through Router B that is selected according to MED.

Figure 5-8 MED attribute
In general, BGP compares MEDs of routes to the same AS only.
& Note:
The current implementation supports using the compare-different-as-med command to force BGP to compare MED values of routes to different ASs.
5) LOCAL_PREF
This attribute is exchanged between IBGP peers only, thus not advertised to any other AS. It indicates the priority of a BGP router.
LOCAL_PREF is used to determine the best route for traffic leaving the local AS. When a BGP router obtains from several IBGP peers multiple routes to the same destination but with different next hops, it considers the route with the highest LOCAL_PREF value as the best route. As shown below, traffic from AS20 to AS10 travels through Router C that is selected according to LOCAL_PREF.

Figure 5-9 LOCAL_PREF attribute
6) COMMUNITY
The COMMUNITY attribute is used to simplify routing policy usage and ease management and maintenance. It is a collection of destination addresses having identical attributes, without physical boundaries in between, having nothing to do with local AS. Well known community attributes include:
l Internet: By default, all routes belong to the Internet community. Routes with this attribute can be advertised to all BGP peers.
l No_Export: After received, routes with this attribute cannot be advertised out the local AS or out the local confederation but can be advertised to other sub-ASs in the confederation (for confederation information, refer to Settlements for Problems Caused by Large Scale BGP Networks).
l No_Advertise: After received, routes with this attribute cannot be advertised to other BGP peers.
l No_Export_Subconfed: After received, routes with this attribute cannot be advertised out the local AS or other ASs in the local confederation.
5.1.3 BGP Route Selection
I. Route selection rule
The current BGP implementation supports the following route selection rule:
l Discard routes with unreachable NEXT_HOP first
l Select the route with the highest Preferred_value
l Select the route with the highest LOCAL_PREF
l Select the route originated by the local router
l Select the route with the shortest AS-PATH
l Select ORIGIN IGP, EGP, Incomplete routes in turn
l Select the route with the lowest MED value
l Select routes learned from EBGP, confederation, IBGP in turn
l Select the route with the smallest next hop cost
l Select the route with the shortest CLUSTER_LIST
l Select the route with the smallest ORIGINATOR_ID
l Select the route advertised by the router with the smallest Router ID
& Note:
l CLUSTER_IDs of router reflectors form a CLUSTER_LIST. If a router reflector receives a route that contains its own CLUSTER ID in the CLUSTER_LIST, the router discards the route to avoid routing loop.
l If load balancing is configured, the system selects available routes to implement load balancing.
II. Route selection with BGP load balancing
The next hop of a BGP route may not be a directly connected neighbor. One of the reasons is next hops in routing information exchanged between IBGPs are not modified. In this case, the router finds the direct route via IGP route entries to reach the next hop. The direct route is called reliable route. The process of finding a reliable route to reach a next hop is route recursion.
The system supports BGP load balancing based on route recursion, namely if reliable routes are load balanced (suppose three next hop addresses), BGP generates the same number of next hops to forward packets. Note that BGP load balancing based on route recursion is always enabled by the system rather than configured using command.
BGP differs from IGP in the implementation of load balancing in the following:
l IGP routing protocols such as RIP, OSPF compute metrics of routes, and then implement load balancing on routes with the same metric and to the same destination. The route selection criterion is metric.
l BGP has no route computation algorithm, so it cannot implement load balancing according to metrics of routes. However, BGP has abundant route selection rules, through which, it selects available routes for load balancing and adds load balancing to route selection rules.
& Note:
l BGP implements load balancing only on routes that have the same AS_PATH length, ORIGIN attribute, LOCAL_PREF and MED.
l BGP load balancing is applicable between EBGPs, IBGPs and between confederations.
l If multiple routes to the same destination are available, BGP selects routes for load balancing according to the configured maximum number of load balanced routes.

Figure 5-10 Network diagram for BGP load balancing
In the above figure, Router D and Router E are IBGP peers of Router C. Router A and Router B both advertise a route destined for the same destination to Router C. If load balancing is configured and the two routes have the same AS_PATH length, ORIGIN attribute, LOCAL_PREF and MED, Router C adds both the two routes to its route table for load balancing. After that, Router C forwards routes to Router D and Router E only once, with AS_PATH unchanged, NEXT_HOP changed to Router C’s address. Other BGP transitive attributes apply according to route selection rules.
III. BGP route advertisement rule
The current BGP implementation supports the following route advertisement rules:
l When multiple available routes exist, a BGP speaker advertises only the best route to its peers.
l A BGP speaker advertises only routes used by itself.
l A BGP speaker advertises routes learned from EBGPs to all BGP peers, including both EBGP and IBGP peers.
l A BGP speaker does not advertise routes learned from IBGPs to IBGP peers.
l A BGP speaker advertises routes learned from IBGPs to EBGP peers. Note that if information synchronization is disabled between BGP and IGP, IBGP routes are advertised to EBGP peers. If enabled, only IGP advertises the IBGP routes can these routes be advertised to EBGP peers.
l A BGP speaker advertises all routes to a newly connected peer.
5.1.4 IBGP and IGP Information Synchronization
The routing Information synchronization between IBGP and IGP is for avoidance of giving wrong directions to routers outside of the local AS.
If a non-BGP router works in an AS, a packet forwarded via the router may be discarded due to unreachable destination. As shown in Figure 5-11, Router E learned a route 8.0.0.0/8 from Router D via BGP. Then Router E sends a packet to Router A through Router D, which finds from its routing table that Router B is the next hop (configured using the peer next-hop-local command). Since Router D learned the route to Router B via IGP, it forwards the packet to Router C using route recursion. Router C has no idea about the route 8.0.0.0/8, so it discards the packet.

Figure 5-11 IBGP and IGP synchronization
If synchronization is configured in this example, the IBGP router (Router D) checks the learned IBGP route from its IGP routing table first. Only the route is available in the IGP routing table can the IBGP router add the route into its BGP routing table and advertise the route to the EBGP peer.
You can disable the synchronization feature in the following cases:
l The local AS is not a transitive AS (AS20 is a transitive AS in the above figure).
l IBGP routers in the local AS are fully meshed.
5.1.5 Settlements for Problems Caused by Large Scale BGP Networks
I. Route summarization
The size of BGP routing table on a large network is very large, and using route summarization can reduce the routing table size.
By summarizing multiple routes with one route, a BGP router advertises only the summary route rather than all routes.
Currently, the system supports both manual and automatic summarization. The latter allows controlling the attribute of a summary route and deciding whether to advertise the route.
II. Route dampening
BGP route dampening is used to solve the issue of route instability such as route flaps, that is, a route comes up and disappears in the routing table frequently.
When a route flap occurs, the routing protocol sends an update to its neighbor, and then the neighbor needs to recalculate routes and modify the routing table. Therefore, frequent route flaps consume large bandwidth and CPU resources even affect normal operation of the network.
In most cases, BGP protocol is used in complex networks, where route changes are very frequent. To solve the problem caused by route flaps, BGP uses route dampening to suppress unstable routes.
BGP route dampening uses a penalty value to judge the stability of a route. The bigger the value, the less stable the route. Each time a route flap occurs (the state changing of a route from active to inactive is a route flap), BGP adds a penalty value (1000, which is a fixed number and cannot be changed) to the route. When the penalty value of the route exceeds the suppress value, the route is suppressed, that is, it is neither added into the routing table, nor advertised to other BGP peers.
The penalty value of the suppressed route will reduce to half of the suppress value after a period of time. This period is called Half-life. When the value decreases to the reusable threshold value, the route is added into the routing table and advertised to other BGP peers in update packets.

Figure 5-12 BGP route dampening
III. Peer group
A peer group is a collection of peers with the same attributes. When a peer joins the peer group, the peer obtains the same configuration as the peer group. If configuration of the peer group is changed, configuration of group members is also changed.
There are many peers in a large BGP network. Some of these peers may be configured with identical commands. The peer group feature simplifies configuration of this kind.
When a peer is added into a peer group, the peer must have the same route update policy as the peer group to improve route distribution efficiency.
![]() Caution:
Caution:
If an option is configured both for a peer and for the peer group, the latest configuration takes effect.
IV. Community
A peer group makes peers in it enjoy the same policy, while a community makes a group of BGP routers in several ASs enjoy the same policy. Community is a path attribute and advertised between BGP peers, without being limited by AS.
A BGP router can modify the community attribute for a route before sending it to other peers.
V. Router reflector
IBGP peers should be fully meshed to maintain connectivity. Suppose there are n routers in an AS, the number of IBGP connections is n(n-1)/2. If there are many IBGP peers, much network and CPU resources will be consumed.
Using router reflector can solve the issue. In an AS, a router acts as a router reflector, and other routers act as clients connecting to the router reflector, which forwards (reflects) routing information between clients. BGP connections between clients are not established.
The router neither a router reflector nor a client is a non-client, which has to establish connections to all the router reflector and non-clients, as shown below.

Figure 5-13 Network diagram for router reflector
The router reflector and clients form a cluster. In some cases, you can configure more than one router reflector in a cluster to improve network reliability and prevent single point failure, as shown in the following figure. The configured router reflectors must have the same Cluster_ID to avoid routing loops.

Figure 5-14 Network diagram for router reflectors
When clients of a router reflector are fully meshed, route reflection is unnecessary because it consumes more bandwidth resources. The system supports using related commands to disable route reflection in this case.
& Note:
After route reflection is disabled between clients, routes between clients and non-clients can still be reflected.
VI. Confederation
Confederation is another method to deal with growing IBGP connections in ASs. It splits an AS into multiple sub-ASs. In each sub AS, IBGP peers are fully meshed, and EBGP connections are established between sub-ASs, as shown below:

Figure 5-15 Confederation network diagram
From the perspective of a non-confederation speaker, it needs not know sub-ASs in the confederation. The ID of the confederation is the number of the AS, in the above figure, AS200 is the confederation ID.
The deficiency of confederation is: when changing an AS into a confederation, you need to reconfigure your routers, and the topology will be changed.
In large-scale BGP networks, both router reflector and confederation can be used.
5.1.6 MP-BGP
I. Overview
The legacy BGP-4 supports IPv4, but does not support some other network layer protocols like IPv6.
To support more network layer protocols, IETF extended BGP-4 by introducing Multiprotocol Extensions for BGP-4 (MP-BGP), which is defined in RFC2858.
Routers supporting MP-BGP can communicate with routers not supporting MP-BGP.
II. MP-BGP extended attributes
In BGP-4, the three types of attributes for IPv4, namely NLRI, NEXT_HOP and AGGREGATOR (contains the IP address of the speaker generating the summary route) are all carried in updates.
To support multiple network layer protocols, BGP-4 puts information about network layer into NLRI and NEXT_HOP. MP-BGP introduced two path attributes:
l MP_REACH_NLRI: Multiprotocol Reachable NLRI, for advertising available routes and next hops
l MP_UNREACH_NLRI: Multiprotocol Unreachable NLRI, for withdrawing unfeasible routes
The above two attributes are both Optional non-transitive, so BGP speakers not supporting multi-protocol ignore the two attributes, not forwarding them to peers.
III. Address family
MP-BGP employs address family to differentiate network layer protocols. For address family values, refer to RFC 1700 (Assigned Numbers). Currently, the system supports multiple MP-BGP extensions, including IPv6 extension. Different extensions are configured in respective address family view.
& Note:
This chapter gives no detail commands related to specific extension configuration in MP-BGP address family view.
5.1.7 Protocols and Standards
l RFC1771: A Border Gateway Protocol 4 (BGP-4)
l RFC2858: Multiprotocol Extensions for BGP-4
l RFC3392: Capabilities Advertisement with BGP-4
l RFC2918: Route Refresh Capability for BGP-4
l RFC2439: BGP Route Flap Damping
l RFC1997: BGP Communities Attribute
l RFC2796: BGP Route Reflection
l RFC3065: Autonomous System Confederations for BGP
Features in draft stage include Graceful Restart and extended community attributes.
5.2 BGP Configuration Task List
To configure BGP, perform the tasks described in the following sections:
|
Task |
Description |
|
|
Required |
||
|
Optional |
||
|
Optional |
||
|
Optional |
||
|
Optional |
||
|
Optional |
||
|
Optional |
||
|
Optional |
||
|
Required |
||
|
Required |
||
|
Configuring a Large Scale BGP Network
|
Optional |
|
|
Optional |
||
|
Optional |
||
|
Optional |
||
5.3 Configuring BGP Basic Functions
The section describes basic BGP configuration.
& Note:
l This section does not differentiate BGP and MP-BGP.
l Since BGP employs TCP, you need to specify IP addresses of peers, which may not be neighboring routers. Using logic links can also establish BGP peer relationships. In general, IP addresses of loopback interfaces are used to improve stability of BGP connections.
5.3.1 Prerequisites
The Neighboring nodes are accessible to each other at the network layer.
You need to decide on:
l The local AS number and Router ID
l IPv4 addresses and AS numbers of peers
l Source interface of updates
5.3.2 Configuration Procedure
To configure BGP basic functions, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
|
Enter system view |
system-view |
— |
|
|
Enter BGP view |
bgp as-number |
— |
|
|
Specify a Router ID |
router-id ip-address |
Optional If no loopback interface address or no interface address is configured, the task becomes required |
|
|
Specify the AS number for a peer or a peer group |
peer { group-name | ip-address } as-number as-number |
Required Not specified by default |
|
|
Configure description for a peer or a peer group |
peer { group-name | ip-address } description description-text |
Optional |
|
|
Enable IPv4 unicast address family for all peers |
default ipv4-unicast |
Optional Enabled by default |
|
|
Enable a peer or a peer group |
Optional Enabled by default |
||
|
Disable the session with a peer or peer group |
peer { group-name | ip-address } ignore |
Optional Not disabled by default |
|
|
Enable the logging on peer changes |
Enable BGP logging globally |
log-peer-change |
Optional Enabled by default |
|
Enable logging for a peer or peer group |
peer { group-name | ip-address } log-change |
Optional Enabled by default |
|
|
Specify the preferred value for routes received from a peer or peer group |
peer { group-name | ip-address } preferred-value value |
Optional The preferred value defaults to 0 |
|
|
Specify the source interface of route updates sent to a peer/peer group |
peer { group-name | ip-address } connect-interface interface-type interface-number |
Optional By default, BGP employs the source interface of the best routing updates |
|
|
Allow establishing EBGP connection to a non directly connected peer/peer group |
peer { group-name | ip-address } ebgp-max-hop [ hop-count ] |
Optional Not allowed by default. By specifying hop-count, you can specify the max hops for the EBGP connection |
|
l It is required to specify for a BGP router a router ID, a 32-bit unsigned integer and the unique identifier of a router.
l You need to create a peer group before configuring it. Refer to Configuring BGP Peer Groups for creating a peer group.
l You can specify a router ID manually. If not, the system selects an IP address as the router ID. The selection sequence is the highest IP address among loopback addresses, the highest IP address of interfaces if no loopback address is available. It is recommended to specify a loopback interface address as the router ID to enhance network reliability.
l To guarantee updates sending in case of interface failure, you can specify the source interface of updates as a loopback interface.
l In general, direct physical links should be available between EBGP peers. If not, you can use the peer ebgp-max-hop command to establish a TCP connection over multiple hops between two peers. You need not use this command for directly connected EBGP peers, which employ loopback interfaces for peer relationship establishment.
5.4 Controlling Route Distribution and Reception
5.4.1 Prerequisites
Before configuring this task, you have completed:
l BGP basic configuration.
You also need to decide on:
l A summary mode and route
l ACL number
l Filtering direction (distribution/reception) and a routing policy name
l Route dampening parameters: Half-life, threshold value
5.4.2 Configuring BGP Route Redistribution
BGP can advertise the routing information of the local AS to peering ASs, and it redistributes routing information from IGP into BGP routing table rather than self-finding. During route redistribution, it can filter routing information according to different routing protocols.
To configure BGP route redistribution, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enter BGP view |
bgp as-number |
— |
|
Enable BGP to redistribute default route into the BGP routing table |
default-route imported |
Optional Not enabled by default |
|
Redistribute routes from another protocol |
import-route protocol [ process-id [ med med-value | route-policy route-policy-name ]* ] |
Required Not redistributed by default |
|
Advertise a network to the BGP routing table |
network ip-address [ mask | mask-length ] [ short-cut | route-policy route-policy-name ] |
Optional Not advertised by default |
& Note:
l The ORIGIN attribute of routes redistributed using the import-route command is Incomplete.
l The ORIGIN attribute of routes obtained using the network command is IGP.
l Network routes to be advertised must be in the local routing table, and using a routing policy makes routes control more flexible.
5.4.3 Configuring BGP Route Summarization
To reduce the routing table size on medium and large BGP networks, you need to configure route summarization on peers. BGP supports two summarization types: automatic and manual.
l Automatic summarization: Summarizes redistributed IGP subnets. If configured, BGP advertises only a summary natural network rather than subnets redistributed from IGP. Default routes and routes redistributed using the network command can not be summarized.
l Manual summarization: Summarizes BGP local routes. The manual summary routes have higher priority than automatic ones.
To configure BGP route summarization, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
|
Enter system view |
system-view |
— |
|
|
Enter BGP view |
bgp as-number |
— |
|
|
Configure BGP route summarization |
Configure automatic route summarization |
summary automatic |
Required to choose either No route summarization is enabled by default |
|
Configure manual route summarization |
aggregate ip-address { mask | mask-length } [ as-set | attribute-policy route-policy-name | detail-suppressed | origin-policy route-policy-name | suppress-policy route-policy-name ]* |
||
5.4.4 Advertising a Default Route
To advertise a default route to a peer or peer group, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enter BGP view |
bgp as-number |
— |
|
Advertise a default route to a peer or peer group |
peer { group-name | ip-address } default-route-advertise [ route-policy route-policy-name ] |
Required Not advertised by default |
& Note:
After the peer default-route-advertise command is executed, the local router sends a default route with the next hop being itself to the specified peer/peer group, regardless of whether the default route is available in the routing table.
5.4.5 Configuring BGP Routing Distribution Policy
To configure BGP route distribution policy, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enter BGP view |
bgp as-number |
— |
|
Filter outbound routes |
filter-policy { acl-number | ip-prefix ip-prefix-name } export [ isis process-id | ospf process-id | rip process-id | direct | static ] |
Required Not filtered by default You can configure filter policies as required. If you configure multiple filter policies, they will be applied in the following order: l filter-policy export l peer filter-policy export l peer as-path-acl export l peer ip-prefix export l peer route-policy export A filter policy can be executed only after the previous one is passed; routing information can be advertised only after passing all the filter policies configured. |
|
Apply a routing policy to routes advertised to a peer/peer group |
peer { group-name | ip-address } route-policy route-policy-name export |
|
|
Specify an ACL to filer routing information advertised to a peer/peer group |
peer { group-name | ip-address } filter-policy acl-number export |
|
|
Specify an AS path ACL to filer routing information advertised to a peer/peer group |
peer { group-name | ip-address } as-path-acl as-path-acl-number export |
|
|
Specify an IP prefix list to filer routing information advertised to a peer/peer group |
peer { group-name | ip-address } ip-prefix ip-prefix-name export |
![]() Caution:
Caution:
The router only advertises routes passing the specified filter.
5.4.6 Configuring BGP Routing Reception Policy
To configure BGP routing reception policy, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enter BGP view |
bgp as-number |
— |
|
Filter incoming routes |
filter-policy { acl-number | ip-prefix ip-prefix-name } import |
Required Not filtered by default You can configure filter policies as required. If you configure multiple filter policies, they will be applied in the following order: l filter-policy import l peer filter-policy import l peer as-path-acl import l peer ip-prefix import l peer route-policy import A filter policy can be executed only after the previous one is passed; routing information can be received only after passing all the filter policies configured. |
|
Apply a routing policy to routes from a peer/peer group |
peer { group-name | ip-address } route-policy policy-name import |
|
|
Specify an ACL to filter routing information imported from a peer/peer group |
peer { group-name | ip-address } filter-policy acl-number import |
|
|
Specify an AS path ACL to filter routing information imported from a peer/peer group |
peer { group-name | ip-address } as-path-acl as-path-acl-number import |
|
|
Specify an IP prefix list to filter routing information imported from a peer/peer group |
peer { group-name | ip-address } ip-prefix ip-prefix-name import |
|
|
Specify the maximum number of routes that can be imported from a peer/peer group |
peer { group-name | ip-address } route-limit limit [ percentage ] |
Optional The maximum number is not limited by default |
![]() Caution:
Caution:
l Only routes permitted by the specified policy can be added into the local BGP routing table.
l Members of a peer group can have different inbound routing policies.
5.4.7 Configuring BGP and IGP Route Synchronization
By default, when a BGP router receives an IBGP route, it only checks the reachability of the route next hop. If the synchronization feature is configured, only after the IBGP route is available in the IGP routing table can the route be advertised to EBGP peers.
To configure BGP and IGP synchronization, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enter BGP view |
bgp as-number |
— |
|
Enable synchronization between BGP and IGP |
synchronization |
Required Not enabled by default |
5.4.8 Configuring BGP Route Dampening
The function of this feature is to suppress unstable routes, neither adding them to the local routing table nor advertising them to BGP peers.
To configure BGP route dampening, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enter BGP view |
bgp as-number |
— |
|
Configure BGP route dampening |
dampening [ half-life-reachable half-life-unreachable reuse suppress ceiling | route-policy route-policy-name ]* |
Required Not configured by default half-life-reachable defaults to 15 minutes, half-life-unreachable defaults to 15 minutes, reuse defaults to 750, suppress defaults to 2000, and ceiling defaults to 16000. |
5.5 Configuring BGP Routing Attributes
5.5.1 Prerequisites
Before configuring this task, you have configured BGP basic functions.
You need to decide on:
l BGP preference value
l LOCAL_PREF value
l MED value
5.5.2 Configuration Procedure
Since BGP has many route attributes, you can use them to adjust BGP routing policy.
To configure BGP route attributes, use the following commands:
|
To do… |
Use the command… |
Remarks |
||
|
Enter system view |
system-view |
— |
||
|
Enter BGP view |
bgp as-number |
— |
||
|
Configure preference values for external, internal, local routes |
preference { external-preference internal-preference local-preference | route-policy route-policy-name } |
Optional The default preference values of external, internal and local routes are 255, 255, 130 respectively. |
||
|
Configure the default value for local preference |
default local-preference value |
Optional The value defaults to 100 |
||
|
Configure the MED attribute |
Configure the default MED value for the local router |
default med med-value |
Optional The value defaults to 0 |
|
|
Enable to compare MED values of routes from different ASs |
compare-different-as-med |
Optional Not enabled by default |
||
|
Enable to compare MED values of routes from each AS |
bestroute compare-med |
Optional Not enabled by default |
||
|
Enable to compare MED values of routes from confederation peers |
bestroute med-confederation |
Optional Not enabled by default |
||
|
Advertise routes to a peer/peer group with the local router being the next hop |
peer { group-name | ip-address } next-hop-local |
Optional To make sure an IBGP peer can find the correct next hop, you can configure routes advertised to the peer to use the local router as the next hop. |
||
|
Configure the AS_PATH attribute |
Configure repeating times of local AS number in routes received from a peer/peer group |
peer { group-name | ip-address } allow-as-loop [ number ] |
Optional The number of repeating times defaults to 1 |
|
|
Neglect the AS_PATH attribute for best route selection |
bestroute as-path-neglect |
Optional Not neglected by default |
||
|
Specify a fake AS number for a peer/peer group |
peer { group-name | ip-address } fake-as as-number |
Optional Not specified by default |
||
|
Substitute local AS number for the AS number of a peer/peer group indicated in the AS_PATH attribute |
peer { group-name | ip-address } substitute-as |
Optional |
||
|
Configure to carry only the public AS number in the AS_PATH attribute in updates sent to a peer/peer group |
peer { group-name | ip-address } public-as-only |
Optional By default, BGP updates carry private AS number |
||
![]() Caution:
Caution:
l Using a routing policy can specify a preference for routes meeting its filtering conditions. Routes not meeting the conditions use the default preference.
l The route with the smallest MED value is selected as the best external route of the AS if other conditions are identical.
l If BGP load balancing is configured, the local router sets the next hop of outbound routes for a peer/peer group to itself regardless of whether the peer next-hop-local command is configured.
l In general, BGP checks whether the AS_PATH attribute of a route from a peer contains the local AS number. If so, it discards the route to avoid routing loops.
l You can configure a fake AS number to hide the real local AS number as needed. The fake AS number applies to EBGP peers only, that is, EBGP peers in other ASs can only find the fake local AS number.
l The peer { group-name | ip-address } substitute-as command is used only in special networking environments. Inappropriate use of the command may cause routing loops.
5.6 Adjusting and Optimizing BGP Networks
This task involves the following parts:
1) BGP timers
After establishing a BGP connection, two routers send keepalive messages periodically to each other to keep the connection. If a router receives no keepalive message from the peer after the hold time elapses, it tears down the connection.
When establishing a BGP connection, the two parties compare their hold times, taking the shorter one as the common hold time.
2) Reset BGP connections
After modifying a route selection policy, you have to reset BGP connections to make the new one take effect, causing a short time disconnection. The current BGP implementation supports the route-refresh feature. With this feature enabled on all BGP routers in a network, when a policy is modified on a router, the router advertises a route-refresh message to its peers, which then send their routing information back to the router. Therefore, the local router can perform dynamic routing information update and apply the new policy without tearing down connections.
If a router not supporting route-refresh exists in the network, you need to configure the peer keep-all-routes command on the local router to save all route updates, and then use the refresh bgp command to soft reset BGP connections, which can refresh the BGP routing table and apply the new policy without needing to teardown BGP connections.
3) BGP authentication
BGP employs TCP as the transport protocol. To enhance security, you can configure BGP to perform MD5 authentication when establishing a TCP connection. BGP MD5 authentication is not for BGP packets. It is used to set passwords for TCP connections. If not passing the authentication, a TCP connection fails.
5.6.2 Prerequisites
Before configuring this task, you have configured:
l BGP basic functions
You need to decide on:
l Values of BGP timers
l Interval for sending updates
l MD5 authentication password
5.6.3 Configuration Procedure
To adjust and optimize BGP networks, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
|
Enter system view |
system-view |
— |
|
|
Enter BGP view |
bgp as-number |
— |
|
|
Configure BGP timers |
Configure keepalive interval and hold time |
timer keepalive keepalive hold holdtime |
Optional The keepalive interval defaults to 60 seconds, holdtime defaults to 180 seconds. Timers configured using the timer command have lower priority than timers configured using the peer timer command. |
|
Configure keepalive interval and holdtime for a peer/peer group |
peer { group-name | ip-address } timer keepalive keepalive hold holdtime |
||
|
Configure the interval for sending the same update to a peer/peer group |
peer { group-name | ip-address } route-update-interval seconds |
Optional The intervals for sending the same update to an IBGP peer and an EBGP peer default to 15 seconds and 30 seconds |
|
|
Configure BGP soft reset |
Disable BGP route-refresh and multi-protocol extensions for a peer/peer group |
peer { group-name | ip-address } capability-advertise conventional |
Optional Enabled by default |
|
Enable BGP route refresh for a peer/peer group |
peer { group-name | ip-address } capability-advertise route-refresh |
Optional Enabled by default |
|
|
Keep all routes imported from a peer/peer group, making them not filtered by the inbound policy |
peer { group-name | ip-address } keep-all-routes |
Optional Not configured by default With this command used, routes from the specified peer/peer group will be kept. When the soft reset is performed on BGP connections, the system uses this routing information to generate BGP routes |
|
|
Perform soft reset on BGP connections |
quit |
Optional |
|
|
quit |
|||
|
refresh bgp { all | ip-address | group group-name | external | internal } { export | import } |
|||
|
system-view |
Enter BGP view |
||
|
bgp as-number |
|||
|
Clear the EBGP session on any interface that becomes down |
ebgp-interface-sensitive |
Optional The function is enabled by default |
|
|
Perform MD5 authentication when establishing a TCP connection |
peer { group-name | ip-address } password { cipher | simple } password |
Optional Not performed by default |
|
|
Configure the number of BGP load balanced routes |
balance number |
Optional The number range and default vary by device |
|
![]() Caution:
Caution:
l The maximum keepalive interval should be 1/3 of the holdtime and no less than 1 second. The holdtime is no less than 3 seconds unless it is set to 0.
l Performing BGP soft reset can refresh the routing table and apply the new policy.
l BGP soft reset requires all routers in the network to support route-refresh. If not, you need to use the peer keep-all-routes command to save all routes imported from peers for soft reset.
5.7 Configuring a Large Scale BGP Network
In a large-scale BGP network, configuration and maintenance become difficult due to so many peers. In this case, configuring peer groups makes management easier and improves route distribution efficiency. Peer group includes IBGP peer group, where peers belong to the same AS, and EBGP peer group, where peers belong to different ASs. If peers in an EBGP group belong to the same external AS, the EBGP peer group is a pure EBGP peer group, and if not, a mixed EBGP peer group.
Configuring BGP community can also help simplify routing policy management, and community has much larger management range than peer group by controlling routing policies of multiple BGP routers.
To guarantee connectivity between IBGP peers, you need to make them fully meshed, but it becomes unpractical when there are too many IBGP peers. Using router reflector or confederation can solve it. In a large-scale AS, both of them can be used.
5.7.1 Configuration Prerequisites
Before configuring this task, you have
l made network layer accessible between peering nodes
You need to decide on:
l Type, name, peers of a peer group
l Name of a routing policy for community application
l Roles (client, non-client) played by routers for router reflector application
l ID and AS number for confederation application
5.7.2 Configuring BGP Peer Groups
To do so, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
|
Enter system view |
system-view |
— |
|
|
Enter BGP view |
bgp as-number |
— |
|
|
Configure an IBGP peer group |
Create an IBGP peer group |
group group-name [ internal ] |
Optional You can add multiple peers into the group. The system will create these peers automatically and sets AS number to the local AS number in BGP view. |
|
Add a peer into the IBGP peer group |
peer ip-address group group-name [ as-number as-number ] |
||
|
Configure an EBGP peer group |
Create an EBGP peer group |
group group-name external |
Optional You can add multiple peers into the group. The system creates these peers automatically and sets AS number to the local AS number in BGP view. |
|
Specify the AS number for the group |
peer group-name as-number as-number |
||
|
Add a peer into the group |
peer ip-address group group-name [ as-number as-number ] |
||
|
Configure a mixed EBGP peer group |
Create an EBGP peer group |
group group-name external |
Optional You can add multiple peers into the group. |
|
Specify a peer and the AS number for the peer respectively |
peer ip-address as-number as-number |
||
|
Add a peer into the group |
peer ip-address group group-name [ as-number as-number ] |
||
![]() Caution:
Caution:
l You need not specify the AS number when creating an IBGP peer group.
l If there are peers in a peer group, you can neither change the AS number of the group nor use the undo command to remove the AS number
l You need to specify the AS number for each peer in a mixed EBGP peer group.
5.7.3 Configuring BGP Community
To configure BGP community, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enter BGP view |
bgp as-number |
— |
|
Configure to advertise community attribute to a peer/peer group |
peer { group-name | ip-address } advertise-community |
Required Not configured by default |
|
Apply a routing policy to routes advertised to a peer/peer group |
peer { group-name | ip-address } route-policy route-policy-name export |
Required Not configured by default |
![]() Caution:
Caution:
l When configuring BGP community, you need to configure a routing policy to define the community attribute, and apply the routing policy to route advertisement.
l For routing policy configuration, refer to Routing Policy Configuration.
5.7.4 Configuring a BGP Router Reflector
To configure a BGP router reflector, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enter BGP view |
bgp as-number |
— |
|
Configure the router as a router reflector and specify a peer/peer group as a client |
peer { group-name | ip-address } reflect-client |
Required Not configured by default |
|
Enable route reflection between clients |
reflect between-clients |
Optional Enabled by default |
|
Configure the cluster ID of the router reflector |
reflector cluster-id cluster-id |
Optional By default, a router reflector uses its router ID as the cluster ID |
![]() Caution:
Caution:
l In general, it is not required to make clients of a router reflector fully meshed. The router reflector forwards routing information between clients. If clients are fully meshed, you can disable route reflection between clients to reduce routing metrics.
l In general, a cluster has only one router reflector, and the router ID is used to identify the cluster. You can configure multiple router reflectors to improve network stability. In this case, you need to specify the same cluster ID for these router reflectors to avoid routing loops.
5.7.5 Configuring a BGP Confederation
To configure a BGP confederation, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
|
Enter system view |
system-view |
— |
|
|
Enter BGP view |
bgp as-number |
— |
|
|
Configure a BGP confederation |
Configure the confederation ID |
confederation id as-number |
Required Not configured by default |
|
Specify sub-ASs contained in the confederation |
confederation peer-as as-number-list |
||
|
Configure compatibility of the confederation |
confederation nonstandard |
Optional By default, a confederation is compatible with RFC 3065. |
|
![]() Caution:
Caution:
l A confederation contains 32 sub-ASs at most. The as-number of a sub AS takes effect in the confederation only.
l If routers not compliant with RFC 3065 exist in the confederation, you can use the confederation nonstandard command to make the local router compatible with these routers.
5.8 Displaying and Maintaining BGP Configuration
5.8.1 Displaying BGP
|
To do… |
Use the command… |
Remarks |
|
Display peer group information |
display bgp group [ group-name ] |
Available in any view |
|
Display BGP advertised routing information |
display bgp network |
|
|
Display AS path information |
display bgp paths [ as-regular-expression ] |
|
|
Display BGP peer/peer group information |
display bgp peer [ ip-address { log-info | verbose } | group-name log-info | verbose ] |
|
|
Display BGP routing table information |
display bgp routing-table [ ip-address [ { mask | mask-length } [ longer-prefixes ] ] ] |
|
|
Display routing information matched by a AS path ACL |
display bgp routing-table as-path-acl as-path-acl-number |
|
|
Display CIDR routing information |
display bgp routing-table cidr |
|
|
Display BGP community routing information |
display bgp routing-table community [ aa:nn&<1-13> ] [ no-advertise | no-export | no-export-subconfed ]* [ whole-match ] |
|
|
Display routing information matched by a BGP community list |
display bgp routing-table community-list { basic-community-list-number [ whole-match ] | adv-community-list-number }&<1-16> |
|
|
Display BGP dampened routing information |
||
|
Display BGP dampening parameter information |
display bgp routing-table dampening parameter |
|
|
Display routing information originating from different ASs |
display bgp routing-table different-origin-as |
|
|
Display routing flap statistics |
display bgp routing-table flap-info [ regular-expression as-regular-expression | as-path-acl as-path-acl-number | ip-address [ { mask | mask-length } [ longer-match ] ] ] |
|
|
Display routing information sent to/received from a peer |
display bgp routing-table peer ip-address { advertised-routes | received-routes } [ network-address [ mask | mask-length ] | statistic ] |
|
|
Display routing information matched by a regular expression |
display bgp routing-table regular-expression as-regular-expression |
|
|
Display BGP routing statistics |
display bgp routing-table statistic |
5.8.2 Resetting BGP Connections
|
To do… |
Use the command… |
Remarks |
|
Reset all BGP connections |
reset bgp all |
Available in user view |
|
Reset the BGP connection to an AS |
reset bgp as-number |
|
|
Reset the BGP connection to a peer |
reset bgp ip-address [ flap-info ] |
|
|
Reset all EBGP connections |
reset bgp external |
|
|
Reset the BGP connection to a peer group |
reset bgp group group-name |
|
|
Reset all IBGP connections |
reset bgp internal |
|
|
Reset all IPv4 unicast BGP connections |
reset bgp ipv4 all |
5.8.3 Clearing BGP Information
|
To do… |
Use the command… |
Remarks |
|
Clear dampening routing information and release suppressed routes |
reset bgp dampening [ network-address [ mask | mask-length ] ] |
Available in user view |
|
Clear route flap information |
reset bgp flap-info [ regexp as-path-regexp | as-path-acl as-path-acl-number | ip-address [ mask | mask-length ] ] |
5.9 BGP Typical Configuration Examples
5.9.1 BGP Basic Configuration
I. Network requirements
In Figure 5-16 are all BGP switches. Between SwitchA and SwitchB is an EBGP connection. SwitchB, SwitchC and SwitchD are IBGP fully meshed.
II. Network diagram
Figure 5-16 BGP basic configuration
III. Configuration procedure
1) Configure IP addresses for interfaces (omitted)
2) Configure IBGP connections
# Configure SwitchB.
<SwitchB> system-view
[SwitchB] bgp 65009
[SwitchB-bgp] router-id 2.2.2.2
[SwitchB-bgp] peer 9.1.1.2 as-number 65009
[SwitchB-bgp] peer 9.1.3.2 as-number 65009
[SwitchB-bgp] quit
# Configure SwitchC.
<SwitchC> system-view
[SwitchC] bgp 65009
[SwitchC-bgp] router-id 3.3.3.3
[SwitchC-bgp] peer 9.1.3.1 as-number 65009
[SwitchC-bgp] peer 9.1.2.2 as-number 65009
[SwitchC-bgp] quit
# Configure SwitchD.
<SwitchD> system-view
[SwitchD] bgp 65009
[SwitchD-bgp] router-id 4.4.4.4
[SwitchD-bgp] peer 9.1.1.1 as-number 65009
[SwitchD-bgp] peer 9.1.2.1 as-number 65009
[SwitchD-bgp] quit
3) Configure the EBGP connection
# Configure SwitchA.
<SwitchA> system-view
[SwitchA] bgp 65008
[SwitchA-bgp] router-id 1.1.1.1
[SwitchA-bgp] peer 200.1.1.1 as-number 65009
# Advertise network 8.0.0.0/8 to the BGP routing table.
[SwitchA-bgp] network 8.0.0.0
[SwitchA-bgp] quit
# Configure SwitchB.
[SwitchB] bgp 65009
[SwitchB-bgp] peer 200.1.1.2 as-number 65008
[SwitchB-bgp] quit
# Display peer information on SwitchB.
[SwitchB] display bgp peer
BGP local router ID : 2.2.2.2
Local AS number : 65009
Total number of peers : 3 Peers in established state : 3
Peer V AS MsgRcvd MsgSent OutQ PrefRcv Up/Down State
9.1.3.2 4 65009 7 9 0 0 00:05:13 Established
9.1.1.2 4 65009 6 6 0 0 00:03:00 Established
200.1.1.2 4 65008 3 2 0 1 00:00:39 Established
You can find SwitchB has established BGP connections to other routers.
# Display BGP routing table information on SwitchA.
[SwitchA] display bgp routing-table
Total Number of Routes: 1
BGP Local router ID is 1.1.1.1
Status codes: * - valid, > - best, d - damped,
h - history, i - internal, s - suppressed, S - Stale
Origin : i - IGP, e - EGP, ? - incomplete
Network NextHop MED LocPrf PrefVal Path/Ogn
*> 8.0.0.0 0.0.0.0 0 0 i
# Display BGP routing table information on SwitchB.
[SwitchB] display bgp routing-table
Total Number of Routes: 1
BGP Local router ID is 2.2.2.2
Status codes: * - valid, > - best, d - damped,
h - history, i - internal, s - suppressed, S - Stale
Origin : i - IGP, e - EGP, ? - incomplete
Network NextHop MED LocPrf PrefVal Path/Ogn
*> 8.0.0.0 200.1.1.2 0 0 65008i
# Display routing table information on SwitchC.
[SwitchC] display bgp routing-table
Total Number of Routes: 1
BGP Local router ID is 3.3.3.3
Status codes: * - valid, > - best, d - damped,
h - history, i - internal, s - suppressed, S - Stale
Origin : i - IGP, e - EGP, ? - incomplete
Network NextHop MED LocPrf PrefVal Path/Ogn
i 8.0.0.0 200.1.1.2 0 100 0 65008i
& Note:
From the above outputs, you can find SwitchA learned no route to AS65009, and SwitchC learned network 8.0.0.0 but the next hop 200.1.1.2 is unreachable, thus the route is invalid.
4) Redistribute direct routes
# Configure SwitchB.
[SwitchB] bgp 65009
[SwitchB-bgp] import-route direct
# Display BGP routing table information on SwitchA.
[SwitchA] display bgp routing-table
Total Number of Routes: 4
BGP Local router ID is 1.1.1.1
Status codes: * - valid, > - best, d - damped,
h - history, i - internal, s - suppressed, S - Stale
Origin : i - IGP, e - EGP, ? - incomplete
Network NextHop MED LocPrf PrefVal Path/Ogn
*> 8.0.0.0 0.0.0.0 0 0 i
*> 9.1.1.0/24 200.1.1.1 0 0 65009?
*> 9.1.3.0/24 200.1.1.1 0 0 65009?
* 200.1.1.0 200.1.1.1 0 0 65009?
# Display BGP routing table information on SwitchC.
[SwitchC] display bgp routing-table
Total Number of Routes: 4
BGP Local router ID is 3.3.3.3
Status codes: * - valid, > - best, d - damped,
h - history, i - internal, s - suppressed, S - Stale
Origin : i - IGP, e - EGP, ? - incomplete
Network NextHop MED LocPrf PrefVal Path/Ogn
*>i 8.0.0.0 200.1.1.2 0 100 0 65008i
*>i 9.1.1.0/24 9.1.3.1 0 100 0 ?
* i 9.1.3.0/24 9.1.3.1 0 100 0 ?
*>i 200.1.1.0 9.1.3.1 0 100 0 ?
You can find the route 8.0.0.0 becomes valid with the next hop being Switch A.
# Ping 8.1.1.1 on SwitchC.
[SwitchC] ping 8.1.1.1
PING 8.1.1.1: 56 data bytes, press CTRL_C to break
Reply from 8.1.1.1: bytes=56 Sequence=1 ttl=254 time=4 ms
Reply from 8.1.1.1: bytes=56 Sequence=2 ttl=254 time=3 ms
Reply from 8.1.1.1: bytes=56 Sequence=3 ttl=254 time=7 ms
Reply from 8.1.1.1: bytes=56 Sequence=4 ttl=254 time=3 ms
Reply from 8.1.1.1: bytes=56 Sequence=5 ttl=254 time=3 ms
--- 8.1.1.1 ping statistics ---
5 packet(s) transmitted
5 packet(s) received
0.00% packet loss
round-trip min/avg/max = 3/4/7 ms
5.9.2 BGP and IGP Interaction Configuration
I. Network requirements
As shown below, OSPF is used as the IGP protocol in AS65009, where SwitchC is a non-BGP switch. Between SwitchA and SwitchB is an EBGP connection.
II. Network diagram
Figure 5-17 Network diagram for BGP and IGP interaction
III. Configuration procedure
1) Configure IP addresses for interfaces (omitted)
2) Configure OSPF (omitted)
3) Configure the EBGP connection
# Configure SwitchA.
<SwitchA> system-view
[SwitchA] bgp 65008
[SwitchA-bgp] router-id 1.1.1.1
[SwitchA-bgp] peer 3.1.1.1 as-number 65009
# Advertise network 8.1.1.0/24 to the BGP routing table.
[SwitchA-bgp] network 8.1.1.0 24
[SwitchA-bgp] quit
# Configure SwitchB.
<SwitchB> system-view
[SwitchB] bgp 65009
[SwitchB-bgp] peer 3.1.1.2 as-number 65008
[SwitchB-bgp] quit
4) Configure BGP and IGP interaction
# Configure BGP to redistribute routes from OSPF on SwitchB.
[SwitchB] bgp 65009
[SwitchB-bgp] import-route ospf 1
[SwitchB-bgp] quit
# Display routing table information on SwitchA.
[SwitchA] display bgp routing-table
Total Number of Routes: 3
BGP Local router ID is 1.1.1.1
Status codes: * - valid, > - best, d - damped,
h - history, i - internal, s - suppressed, S - Stale
Origin : i - IGP, e - EGP, ? - incomplete
Network NextHop MED LocPrf PrefVal Path/Ogn
*> 8.1.1.0/24 0.0.0.0 0 0 i
*> 9.1.1.0/24 3.1.1.1 0 0 65009?
*> 9.1.2.0/24 3.1.1.1 2 0 65009?
# Configure OSPF to redistribute routes from BGP on SwitchB.
[SwitchB] ospf
[SwitchB-ospf-1] import-route bgp
[SwitchB-ospf-1] quit
# Display routing table information on SwitchC.
<SwitchC> display ip routing-table
Routing Tables: Public
Destinations : 7 Routes : 7
Destination/Mask Proto Pre Cost NextHop Interface
8.1.1.0/24 O_ASE 150 1 9.1.1.1 Vlan300
9.1.1.0/24 Direct 0 0 9.1.1.2 Vlan300
9.1.1.2/32 Direct 0 0 127.0.0.1 InLoop0
9.1.2.0/24 Direct 0 0 9.1.2.1 Vlan400
9.1.2.1/32 Direct 0 0 127.0.0.1 InLoop0
127.0.0.0/8 Direct 0 0 127.0.0.1 InLoop0
127.0.0.1/32 Direct 0 0 127.0.0.1 InLoop0
5) Configure route automatic summarization
# Configure route automatic summarization on SwitchB.
[RouterB] bgp 65009
[RouterB-bgp] summary automatic
# Display BGP routing table information on SwitchA.
[SwitchA] display bgp routing-table
Total Number of Routes: 2
BGP Local router ID is 1.1.1.1
Status codes: * - valid, > - best, d - damped,
h - history, i - internal, s - suppressed, S - Stale
Origin : i - IGP, e - EGP, ? - incomplete
Network NextHop MED LocPrf PrefVal Path/Ogn
*> 8.1.1.0/24 0.0.0.0 0 0 i
*> 9.0.0.0 3.1.1.1 0 65009?
# Use ping for verification.
[SwitchA] ping -a 8.1.1.1 9.1.2.1
PING 9.1.2.1: 56 data bytes, press CTRL_C to break
Reply from 9.1.2.1: bytes=56 Sequence=1 ttl=254 time=4 ms
Reply from 9.1.2.1: bytes=56 Sequence=2 ttl=254 time=3 ms
Reply from 9.1.2.1: bytes=56 Sequence=3 ttl=254 time=3 ms
Reply from 9.1.2.1: bytes=56 Sequence=4 ttl=254 time=3 ms
Reply from 9.1.2.1: bytes=56 Sequence=5 ttl=254 time=3 ms
--- 9.1.2.1 ping statistics ---
5 packet(s) transmitted
5 packet(s) received
0.00% packet loss
round-trip min/avg/max = 3/3/4 ms
5.9.3 BGP Load Balancing and MED Attribute Configuration
I. Network requirements
l Configure BGP on all switches; SwitchA is in AS65008, SwitchB and C in AS65009.
l Between SwitchA and B, SwitchA and C are EBGP connections, and an IBGP connection is between SwitchB and C.
II. Network diagram
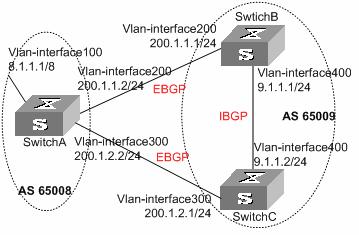
Figure 5-18 Network diagram
III. Configuration procedure
1) Configure IP addresses for interfaces (omitted)
2) Configure BGP connections
# Configure SwitchA
<SwitchA> system-view
[SwitchA] bgp 65008
[SwitchA-bgp] router-id 1.1.1.1
[SwitchA-bgp] peer 200.1.1.1 as-number 65009
[SwitchA-bgp] peer 200.1.2.1 as-number 65009
# Advertise route 8.0.0.0/8 to BGP routing table.
[SwitchA-bgp] network 8.0.0.0 255.0.0.0
[SwitchA-bgp] quit
# Configure SwitchB
<SwitchB> system-view
[SwitchB] bgp 65009
[SwitchB-bgp] router-id 2.2.2.2
[SwitchB-bgp] peer 200.1.1.2 as-number 65008
[SwitchB-bgp] peer 9.1.1.2 as-number 65009
[SwitchB-bgp] network 9.1.1.0 255.255.255.0
[SwitchB-bgp] quit
# Configure SwitchC
<SwitchC> system-view
[SwitchC] bgp 65009
[SwitchC-bgp] router-id 3.3.3.3
[SwitchC-bgp] peer 200.1.2.2 as-number 65008
[SwitchC-bgp] peer 9.1.1.1 as-number 65009
[SwitchC-bgp] network 9.1.1.0 255.255.255.0
[SwitchC-bgp] quit
# Display the routing table on SwitchA.
[SwitchA] display bgp routing-table
Total Number of Routes: 3
BGP Local router ID is 1.1.1.1
Status codes: * - valid, > - best, d - damped,
h - history, i - internal, s - suppressed, S - Stale
Origin : i - IGP, e - EGP, ? - incomplete
Network NextHop MED LocPrf PrefVal Path/Ogn
*> 8.0.0.0 0.0.0.0 0 0 i
*> 9.1.1.0/24 200.1.1.1 0 0 65009i
* 200.1.2.1 0 0 65009i
Two routes to 9.1.1.0/24 are available, and the one with the next hop being 200.1.1.1 is the optimal because the ID of SwitchB is smaller.
3) Configure loading balancing
# Configure SwitchA
[SwitchA] bgp 65008
[SwitchA-bgp] balance 2
[SwitchA-bgp] quit
# Display the routing table on SwitchA.
[SwitchA] display bgp routing-table
Total Number of Routes: 3
BGP Local router ID is 1.1.1.1
Status codes: * - valid, > - best, d - damped,
h - history, i - internal, s - suppressed, S - Stale
Origin : i - IGP, e - EGP, ? - incomplete
Network NextHop MED LocPrf PrefVal Path/Ogn
*> 8.0.0.0 0.0.0.0 0 0 i
*> 9.1.1.0/24 200.1.1.1 0 0 65009i
*> 200.1.2.1 0 0 65009i
The route 9.1.1.0/24 has two next hops 200.1.1.1 and 200.1.2.1, and both are the optimal.
4) Configure MED
# Configure the default MED of SwitchB.
[SwitchB] bgp 65009
[SwitchB-bgp] default med 100
# Display the routing table on SwitchA.
[SwitchA] display bgp routing-table
Total Number of Routes: 3
BGP Local router ID is 1.1.1.1
Status codes: * - valid, > - best, d - damped,
h - history, i - internal, s - suppressed, S - Stale
Origin : i - IGP, e - EGP, ? - incomplete
Network NextHop MED LocPrf PrefVal Path/Ogn
*> 8.0.0.0 0.0.0.0 0 0 i
*> 9.1.1.0/24 200.1.2.1 0 0 65009i
* 200.1.1.1 100 0 65009i
From the above information, you can find the route with the next hop 200.1.2.1 is the best route, because its MED (0) is smaller than the MED (100) of the other route with the next hop 200.1.1.1 (SwitchB).
5.9.4 BGP Community Configuration
I. Network requirements
SwitchB establishes EBGP connections with SwitchA and C. Configure No_Export community attribute on SwitchA to make routes from AS 10 not advertised by AS 20 to any other AS.
II. Network diagram
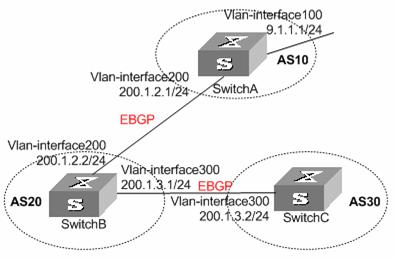
Figure 5-19 BGP community configuration network diagram
III. Configuration procedure
1) Configure IP addresses for interfaces (omitted)
2) Configure EBGP
# Configure SwitchA
<SwitchA> system-view
[SwitchA] bgp 10
[SwitchA-bgp] router-id 1.1.1.1
[SwitchA-bgp] peer 200.1.2.2 as-number 20
[SwitchA-bgp] network 9.1.1.0 255.255.255.0
[SwitchA-bgp] quit
# Configure SwitchB
<SwitchB> system-view
[SwitchB] bgp 20
[SwitchB-bgp] router-id 2.2.2.2
[SwitchB-bgp] peer 200.1.2.1 as-number 10
[SwitchB-bgp] peer 200.1.3.2 as-number 30
[SwitchB-bgp] quit
# Configure SwitchC
<SwitchC> system-view
[SwitchC] bgp 30
[SwitchC-bgp] router-id 3.3.3.3
[SwitchC-bgp] peer 200.1.3.1 as-number 20
[SwitchC-bgp] quit
# Display the BGP routing table on SwitchB.
[SwitchB] display bgp routing-table 9.1.1.0
BGP local router ID : 2.2.2.2
Local AS number : 20
Paths: 1 available, 1 best
BGP routing table entry information of 9.1.1.0/24:
From : 200.1.2.1 (1.1.1.1)
Original nexthop: 200.1.2.1
AS-path : 10
Origin : igp
Attribute value : MED 0, pref-val 0, pre 255
State : valid, external, best,
Advertised to such 1 peers:
200.1.3.2
SwitchB advertised routes to SwitchC in AS30.
# Display the routing table on SwitchC.
[SwitchC] display bgp routing-table
Total Number of Routes: 1
BGP Local router ID is 3.3.3.3
Status codes: * - valid, > - best, d - damped,
h - history, i - internal, s - suppressed, S - Stale
Origin : i - IGP, e - EGP, ? - incomplete
Network NextHop MED LocPrf PrefVal Path/Ogn
*> 9.1.1.0/24 200.1.3.1 0 20 10i
SwitchC learned route 9.1.1.0/24 from SwitchB.
3) Configure BGP community
# Configure a routing policy
[SwitchA] route-policy comm_policy permit node 0
[SwitchA-route-policy] apply community no-export
[SwitchA-route-policy] quit
# Apply the routing policy
[SwitchA] bgp 10
[SwitchA-bgp] peer 200.1.2.2 route-policy comm_policy export
[SwitchA-bgp] peer 200.1.2.2 advertise-community
# Display the routing table on SwitchB.
[SwitchB] display bgp routing-table 9.1.1.0
BGP local router ID : 2.2.2.2
Local AS number : 20
Paths: 1 available, 1 best
BGP routing table entry information of 9.1.1.0/24:
From : 200.1.2.1 (1.1.1.1)
Original nexthop: 200.1.2.1
Community : No-Export
AS-path : 10
Origin : igp
Attribute value : MED 0, pref-val 0, pre 255
State : valid, external, best,
Not advertised to any peers yet
The route 9.1.1.0/24 is not available in the routing table of SwitchC.
5.9.5 BGP Router Reflector Configuration
I. Network requirements
In the following figure, all switches run BGP.
l Between SwitchA and SwitchB is an EBGP connection, between SwitchC and SwitchB, SwitchC and SwitchD are IBGP connections.
l SwitchC is a router reflector with clients SwitchB and D.
l SwitchD can learn route 1.0.0.0/8 from SwitchC.
II. Network diagram

Figure 5-20 BGP router reflector configuration network diagram
III. Configuration procedure
1) Configure IP addresses for interfaces (omitted)
2) Configure BGP connections
# Configure SwitchA
<SwitchA> system-view
[SwitchA] bgp 100
[SwitchA-bgp] router-id 1.1.1.1
[SwitchA-bgp] peer 192.1.1.2 as-number 200
# Advertise network 1.0.0.0/8 to the BGP routing table.
[SwitchA-bgp] network 1.0.0.0
[SwitchA-bgp] quit
# Configure SwitchB
<SwitchB> system-view
[SwitchB] bgp 200
[SwitchB-bgp] router-id 2.2.2.2
[SwitchB-bgp] peer 192.1.1.1 as-number 100
[SwitchB-bgp] peer 193.1.1.1 as-number 200
[SwitchB-bgp] peer 193.1.1.1 next-hop-local
[SwitchB-bgp] quit
# Configure SwitchC
<SwitchC> system-view
[SwitchC] bgp 200
[SwitchC-bgp] router-id 3.3.3.3
[SwitchC-bgp] peer 193.1.1.2 as-number 200
[SwitchC-bgp] peer 194.1.1.2 as-number 200
[SwitchC-bgp] quit
# Configure SwitchD
<SwitchD> system-view
[SwitchD] bgp 200
[SwitchD-bgp] router-id 4.4.4.4
[SwitchD-bgp] peer 194.1.1.1 as-number 200
[SwitchD-bgp] quit
3) Configure router reflector
# Configure SwitchC
[SwitchC] bgp 200
[SwitchC-bgp] peer 193.1.1.2 reflect-client
[SwitchC-bgp] peer 194.1.1.2 reflect-client
[SwitchC-bgp] quit
4) Verify the above configuration
# Display the BGP routing table on SwitchB.
[SwitchB] display bgp routing-table
Total Number of Routes: 1
BGP Local router ID is 200.1.2.2
Status codes: * - valid, > - best, d - damped,
h - history, i - internal, s - suppressed, S - Stale
Origin : i - IGP, e - EGP, ? - incomplete
Network NextHop MED LocPrf PrefVal Path/Ogn
*> 1.0.0.0 192.1.1.1 0 0 100i
# Display the BGP routing table on SwitchD.
[SwitchD] display bgp routing-table
Total Number of Routes: 1
BGP Local router ID is 4.4.4.4
Status codes: * - valid, > - best, d - damped,
h - history, i - internal, s - suppressed, S - Stale
Origin : i - IGP, e - EGP, ? - incomplete
Network NextHop MED LocPrf PrefVal Path/Ogn
i 1.0.0.0 193.1.1.2 100 0 100i
SwitchD learned route 1.0.0.0/8 from SwitchC.
5.9.6 BGP Confederation Configuration
I. Network requirements
To reduce IBGP connections in AS 200, split it into three sub-ASs, AS65001, AS65002 and AS65003. Switches in AS65001 are fully meshed.
II. Network diagram
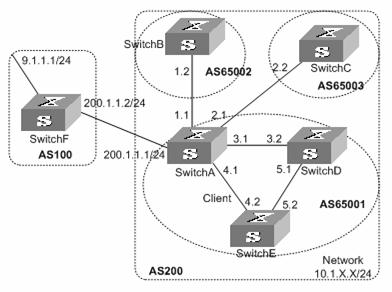
Figure 5-21 BGP confederation network diagram
III. Configuration procedure
1) Configure IP addresses for interfaces (omitted)
2) Configure BGP confederation
# Configure SwitchA
<SwitchA> system-view
[SwitchA] bgp 65001
[SwitchA-bgp] router-id 1.1.1.1
[SwitchA-bgp] confederation id 200
[SwitchA-bgp] confederation peer-as 65002 65003
[SwitchA-bgp] peer 10.1.1.2 as-number 65002
[SwitchA-bgp] peer 10.1.1.2 next-hop-local
[SwitchA-bgp] peer 10.1.2.2 as-number 65003
[SwitchA-bgp] peer 10.1.2.2 next-hop-local
[SwitchA-bgp] quit
# Configure SwitchB
<SwitchB> system-view
[SwitchB] bgp 65002
[SwitchB-bgp] router-id 2.2.2.2
[SwitchB-bgp] confederation id 200
[SwitchB-bgp] confederation peer-as 65001 65003
[SwitchB-bgp] peer 10.1.1.1 as-number 65001
[SwitchB-bgp] quit
# Configure SwitchC
<SwitchC> system-view
[SwitchC] bgp 65003
[SwitchC-bgp] router-id 3.3.3.3
[SwitchC-bgp] confederation id 200
[SwitchC-bgp] confederation peer-as 65001 65002
[SwitchC-bgp] peer 10.1.2.1 as-number 65001
[SwitchC-bgp] quit
3) Configure IBGP connections in AS65001.
# Configure SwitchA
[SwitchA] bgp 65001
[SwitchA-bgp] peer 10.1.3.2 as-number 65001
[SwitchA-bgp] peer 10.1.3.2 next-hop-local
[SwitchA-bgp] peer 10.1.4.2 as-number 65001
[SwitchA-bgp] peer 10.1.4.2 next-hop-local
[SwitchA-bgp] quit
# Configure SwitchD
<SwitchD> system-view
[SwitchD] bgp 65001
[SwitchD-bgp] router-id 4.4.4.4
[SwitchD-bgp] confederation id 200
[SwitchD-bgp] peer 10.1.3.1 as-number 65001
[SwitchD-bgp] peer 10.1.5.2 as-number 65001
[SwitchD-bgp] quit
# Configure SwitchE
<SwitchE> system-view
[SwitchE] bgp 65001
[SwitchE-bgp] router-id 5.5.5.5
[SwitchE-bgp] confederation id 200
[SwitchE-bgp] peer 10.1.4.1 as-number 65001
[SwitchE-bgp] peer 10.1.5.1 as-number 65001
[SwitchE-bgp] quit
4) Configure the EBGP connection between AS100 and AS200.
# Configure SwitchA
[SwitchA] bgp 65001
[SwitchA-bgp] peer 200.1.1.2 as-number 100
[SwitchA-bgp] quit
# Configure SwitchF
<SwitchF> system-view
[SwitchF] bgp 100
[SwitchF-bgp] router-id 6.6.6.6
[SwitchF-bgp] peer 200.1.1.1 as-number 200
[SwitchF-bgp] network 9.1.1.0 255.255.255.0
[SwitchF-bgp] quit
5) Verify above configuration
# Display the routing table on SwitchB.
[SwitchB] display bgp routing-table
Total Number of Routes: 1
BGP Local router ID is 2.2.2.2
Status codes: * - valid, > - best, d - damped,
h - history, i - internal, s - suppressed, S - Stale
Origin : i - IGP, e - EGP, ? - incomplete
Network NextHop MED LocPrf PrefVal Path/Ogn
*>i 9.1.1.0/24 10.1.1.1 100 0 (65001)
100i
[SwitchB] display bgp routing-table 9.1.1.0
BGP local router ID : 2.2.2.2
Local AS number : 65002
Paths: 1 available, 1 best
BGP routing table entry information of 9.1.1.0/24:
From : 10.1.1.1 (1.1.1.1)
Relay Nexthop : 0.0.0.0
Original nexthop: 10.1.1.1
AS-path : (65001) 100
Origin : igp
Attribute value : localpref 100, pref-val 0, pre 255
State : valid, external-confed, best,
Not advertised to any peers yet
# Display the BGP routing table on SwitchD.
[SwitchD] display bgp routing-table
Total Number of Routes: 1
BGP Local router ID is 4.4.4.4
Status codes: * - valid, > - best, d - damped,
h - history, i - internal, s - suppressed, S - Stale
Origin : i - IGP, e - EGP, ? - incomplete
Network NextHop MED LocPrf PrefVal Path/Ogn
*>i 9.1.1.0/24 10.1.3.1 0 100 0 100i
[SwitchD] display bgp routing-table 9.1.1.0
BGP local router ID : 4.4.4.4
Local AS number : 65001
Paths: 1 available, 1 best
BGP routing table entry information of 9.1.1.0/24:
From : 10.1.3.1 (1.1.1.1)
Relay Nexthop : 0.0.0.0
Original nexthop: 10.1.3.1
AS-path : 100
Origin : igp
Attribute value : MED 0, localpref 100, pref-val 0, pre 255
State : valid, internal, best,
Not advertised to any peers yet
5.9.7 BGP Path Selection Configuration
I. Network requirements
l In the figure below, all switches run BGP. Between SwitchA and SwitchB, SwitchA and SwitchC are EBGP connections. Between SwitchB and SwitchD, SwitchD and SwitchC are IBGP connections.
l OSPF is the IGP protocol in AS 200.
l Configure routing policies, making SwitchD use the route 1.0.0.0/8 from SwitchC as the optimal.
II. Network diagram
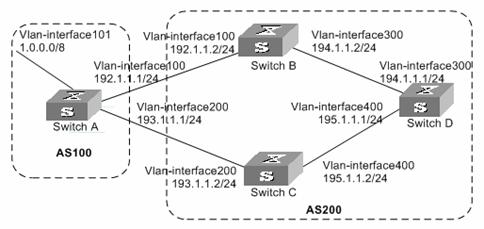
Figure 5-22 BGP path selection configuration network diagram
III. Configuration procedure
1) Configure IP addresses for interfaces (omitted).
2) Configure OSPF on SwitchB, C, and D.
# Configure SwitchB
<SwitchB> system-view
[SwitchB] ospf
[SwitchB-ospf] area 0
[SwitchB-ospf-1-area-0.0.0.0] network 192.1.1.0 0.0.0.255
[SwitchB-ospf-1-area-0.0.0.0] network 194.1.1.0 0.0.0.255
[SwitchB-ospf-1-area-0.0.0.0] quit
[SwitchB-ospf-1] quit
# Configure SwitchC
<SwitchC> system-view
[SwitchC] ospf
[SwitchC-ospf] area 0
[SwitchC-ospf-1-area-0.0.0.0] network 193.1.1.0 0.0.0.255
[SwitchC-ospf-1-area-0.0.0.0] network 195.1.1.0 0.0.0.255
[SwitchC-ospf-1-area-0.0.0.0] quit
[SwitchC-ospf-1] quit
# Configure SwitchD
<SwitchD> system-view
[SwitchD] ospf
[SwitchD-ospf] area 0
[SwitchD-ospf-1-area-0.0.0.0] network 194.1.1.0 0.0.0.255
[SwitchD-ospf-1-area-0.0.0.0] network 195.1.1.0 0.0.0.255
[SwitchD-ospf-1-area-0.0.0.0] quit
[SwitchD-ospf-1] quit
3) Configure BGP connections
# Configure SwitchA
<SwitchA> system-view
[SwitchA] bgp 100
[SwitchA-bgp] peer 192.1.1.2 as-number 200
[SwitchA-bgp] peer 193.1.1.2 as-number 200
# Advertise network 1.0.0.0/8 to the BGP routing table on SwitchA.
[SwitchA-bgp] network 1.0.0.0 8
[SwitchA-bgp] quit
# Configure SwitchB.
[SwitchB] bgp 200
[SwitchB-bgp] peer 192.1.1.1 as-number 100
[SwitchB-bgp] peer 194.1.1.1 as-number 200
[SwitchB-bgp] quit
# Configure SwitchC
[SwitchC] bgp 200
[SwitchC-bgp] peer 193.1.1.1 as-number 100
[SwitchC-bgp] peer 195.1.1.1 as-number 200
[SwitchC-bgp] quit
# Configure SwitchD
[SwitchD] bgp 200
[SwitchD-bgp] peer 194.1.1.2 as-number 200
[SwitchD-bgp] peer 195.1.1.2 as-number 200
[SwitchD-bgp] quit
4) Configure attributes for route 1.0.0.0/8, making SwitchD give priority to the route learned from SwitchC.
l Configure a higher MED value for the route 1.0.0.0/8 advertised from SwitchA to peer 192.1.1.2.
# Define an ACL numbered 2000 to permit route 1.0.0.0/8.
[SwitchA] acl number 2000
[SwitchA-acl-basic-2000] rule permit source 1.0.0.0 0.255.255.255
[SwitchA-acl-basic-2000] quit
# Define two routing policies, apply_med_50, which sets the MED for route 1.0.0.0/8 to 50, and apply_med_100, which sets the MED for route 1.0.0.0/8 to 100.
[SwitchA] route-policy apply_med_50 permit node 10
[SwitchA-route-policy] if-match acl 2000
[SwitchA-route-policy] apply cost 50
[SwitchA-route-policy] quit
[SwitchA] route-policy apply_med_100 permit node 10
[SwitchA-route-policy] if-match acl 2000
[SwitchA-route-policy] apply cost 100
[SwitchA-route-policy] quit
# Apply routing policy apply_med_50 to the route advertised to peer 193.1.1.2 (SwitchC), and apply_med_100 to the route advertised to peer 192.1.1.2 (SwitchB).
[SwitchA] bgp 100
[SwitchA-bgp] peer 193.1.1.2 route-policy apply_med_50 export
[SwitchA-bgp] peer 192.1.1.2 route-policy apply_med_100 export
[SwitchA-bgp] quit
# Display the BGP routing table on SwitchD.
[SwitchD] display bgp routing-table
Total Number of Routes: 2
BGP Local router ID is 194.1.1.1
Status codes: * - valid, > - best, d - damped,
h - history, i - internal, s - suppressed, S - Stale
Origin : i - IGP, e - EGP, ? - incomplete
Network NextHop MED LocPrf PrefVal Path/Ogn
*>i 1.0.0.0 193.1.1.1 50 100 0 100i
* i 192.1.1.1 100 100 0 100i
You can find route 1.0.0.0/8 is the optimal.
l Configure different local preferences on SwitchB and C for route 1.0.0.0/8, making SwitchD give priority to the route from SwitchC.
# Define an ACL numbered 2000 on Router C, letting pass route 1.0.0.0/8.
[SwitchC] acl number 2000
[SwitchC-acl-basic-2000] rule permit source 1.0.0.0 0.255.255.255
[SwitchC-acl-basic-2000] quit
# Configure a routing policy named localpref on SwitchC, set the local preference of route 1.0.0.0/8 to 200 (the default is 100).
[SwitchC] route-policy localpref permit node 10
[SwitchC-route-policy] if-match acl 2000
[SwitchC-route-policy] apply local-preference 200
[SwitchC-route-policy] quit
# Apply routing policy localpref to routes from peer 193.1.1.1.
[SwitchC] bgp 200
[SwitchC-bgp] peer 193.1.1.1 route-policy localpref import
[SwitchC-bgp] quit
# Display the routing table on SwitchD.
[SwitchD] display bgp routing-table
Total Number of Routes: 2
BGP Local router ID is 194.1.1.1
Status codes: * - valid, > - best, d - damped,
h - history, i - internal, s - suppressed, S - Stale
Origin : i - IGP, e - EGP, ? - incomplete
Network NextHop MED LocPrf PrefVal Path/Ogn
*>i 1.0.0.0 193.1.1.1 0 200 0 100i
* i 192.1.1.1 0 100 0 100i
You can find route 1.0.0.0/8 from SwitchD to SwitchC is the optimal.
5.10 Troubleshooting BGP Configuration
5.10.1 No BGP Peer Relationship Established
I. Symptom
Display BGP peer information using the display bgp peer command. The state of the connection to the peer cannot become established.
II. Analysis
To become BGP peers, any two routers need to establish a TCP session using port 179 and exchange open messages successfully.
III. Processing steps
1) Use the display current-configuration command to verify the peer’s AS number.
2) Use the display bgp peer command to verify the peer’s IP address.
3) If the loopback interface is used, check whether the connect-interface command is configured.
4) If the peer is a non-direct EBGP peer, check whether the peer ebgp-max-hop command is configured.
5) Check whether a route to the peer is available in the routing table.
6) Use the ping command to check connectivity.
7) Use the display tcp status command to check the TCP connection.
8) Check whether an ACL disabling TCP port 179 is configured.
Chapter 6 Routing Policy Configuration
The term “router” in this document refers to a router in a generic sense or an Ethernet switch running routing protocols.
6.1 Introduction to Routing Policy
6.1.1 Routing Policy
A routing policy is used on the router for route inspection, filtering, attributes modifying when routes are received, advertised, or redistributed.
When distributing or receiving routing information, a router can apply some policy to filter routing information, for example, a router handles only routing information that matches some rules, or a routing protocol redistributes from other protocols only routes matching some rules and modifies some attributes of these routes to satisfy its needs.
To implement a routing policy, you need define a set of match criteria according to attributes in routing information, such as destination address, advertising router’s address. The match criteria can be set beforehand and then apply them to a routing policy for route distribution, reception and redistribution.
6.1.2 Filters
Routing protocols can use six filters: ACL, IP prefix list, AS path ACL, community list, extended community list and routing policy.
I. ACL
ACL involves IPv4 ACL. When defining an ACL, you can specify IP addresses and prefixes to match destinations or next hops of routing information.
For ACL configuration, refer to ACL operation.
II. IP prefix list
IP prefix list plays a role similar to ACL, but it is more flexible than ACL and easier to understand. When an IP prefix list is applied to filtering routing information, its matching object is the destination address of routing information. Moreover, you can specify the gateway option to indicate that only routing information advertised by certain routers will be received.
An IP prefix list is identified by its name. Each IP prefix list can comprise multiple items, and each item, which is identified by an index number, can specify a matching range in network prefix format. The index number indicates the matching sequence of items in the IP prefix list.
During matching, the router compares the packet with the items in the ascending order. If one item is matched, the IP prefix list filter is passed, and the packet will not go to the next item.
III. AS-path ACL
AS path ACL is only applicable to BGP. There is an AS-path field in the BGP packet. An AS path ACL specifies matching conditions according to the AS-path field.
IV. Community list
Community list only applies to BGP. The BGP packet contains a community attribute field to identify a community. A community list specifies matching conditions based on the community attribute.
V. Routing policy
A routing policy is used to match against some attributes in given routing information and modify the attributes of the information if matching conditions are satisfied. It can reference the above mentioned filters to define its own match criteria.
A routing policy can comprise multiple nodes, which are in logic OR relationship. Each node is a matching unit, and the system compares each node to a packet in the order of node sequence number. Once a node is matched, the routing policy is passed and the packet will not go through the next node.
Each node comprises a list of if-match and apply clauses. The if-match clauses define the match criteria. The matching objects are some attributes of routing information. The different if-match clauses on a node is in logical AND relationship. Only when the matching conditions specified by all the if-match clauses on the node are satisfied, can routing information pass the node. The apply clauses specify the actions performed after the node is passed, concerning the attribute settings for routing information.
6.1.3 Routing Policy Application
A routing policy is applied in two ways:
l When redistributing routes from other routing protocols, a routing protocol accepts only routes passing the routing policy.
l When receiving or advertising routing information, a routing protocol uses the routing policy to filter routing information.
6.2 Defining Filtering Lists
6.2.1 Prerequisites
Before configuring this task, you need to decide on:
l IP-prefix list name
l Matching address range
6.2.2 Defining an IPv4 prefix list
Identified by name, each IPv4 prefix list can comprise multiple items. Each item specifies a matching address range in the form of network prefix identified by index number.
During matching, the system compares the route to each item identified by index number in the ascending order. If one item is matched, the route passes the IP-prefix list, without needing to match the next item.
To define an IPv4 prefix list, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Define an IPv4 prefix list |
ip ip-prefix ip-prefix-name [ index index-number ] { permit | deny } ip-address mask-length [ greater-equal min-mask-length ] [ less-equal max-mask-length ] |
Required Not defined by default |
& Note:
If all items are set to the deny mode, no routes can pass the IPv4 prefix list. Therefore, you need to define the permit 0.0.0.0 0 less-equal 32 item following multiple deny mode items to allow other IPv4 routing information to pass.
For example, the following configuration filters routes 10.1.0.0/16, 10.2.0.0/16 and 10.3.0.0/16, but allows other routes to pass.
<Sysname> system-view
[Sysname] ip ip-prefix abc index 10 deny 10.1.0.0 16
[Sysname] ip ip-prefix abc index 20 deny 10.2.0.0 16
[Sysname] ip ip-prefix abc index 30 deny 10.3.0.0 16
[Sysname] ip ip-prefix abc index 40 permit 0.0.0.0 0 less-equal 32
6.2.3 Defining an AS Path ACL
You can define multiple items for an AS path ACL that is identified by number. During matching, the relation between items is logical OR, that is, if the route matches one of these items, it passes the AS path ACL.
To define an AS path ACL, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Define an AS path ACL |
ip as-path-acl as-path-acl-number { deny | permit } regular-expression |
Required Not defined by default |
6.2.4 Defining a Community List
You can define multiple items for a community list that is identified by number. During matching, the relation between items is logic OR, that is, if routing information matches one of these items, it passes the community list.
To define a community list, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
|
Enter system view |
system-view |
— |
|
|
Define a community list |
Define a basic community list |
ip community-list basic-comm-list-num { deny | permit } [ community-number-list ] [ internet | no-advertise | no-export | no-export-subconfed ] * |
Required to define either; Not defined by default |
|
Define an advanced community list |
ip community-list adv-comm-list-num { deny | permit } regular-expression |
||
6.2.5 Defining an Extended Community List
You can define multiple items for an extended community list that is identified by its number. During matching, the relation between items is logic OR, that is, if routing information matches one of these items, it passes the extended community list.
To define an extended community list, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Define an extended community list |
ip extcommunity-list ext-comm-list-number { deny | permit } { rt route-target }&<1-16> |
Required Not defined by default |
6.3 Configuring a Routing Policy
A routing policy is used to filter routing information according to some attributes, and modify some attributes of the routing information that matches the routing policy. Match criteria can be configured using filters above mentioned.
A routing policy can comprise multiple nodes, each node contains:
l if-match clauses: Define the match criteria that routing information must satisfy. The matching objects are some attributes of routing information.
l apply clauses: Specify the actions performed after specified match criteria are satisfied, concerning attribute settings for passed routing information.
6.3.1 Prerequisites
Before configuring this task, you have completed:
l Filtering list configuration
l Routing protocol configuration
You also need to decide on:
l Name of the routing policy, node sequence numbers
l Match criteria
l Attributes to be modified
6.3.2 Creating a Routing Policy
To create a routing policy, use the following commands:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Create a routing policy and enter its view |
route-policy route-policy-name { permit | deny } node node-number |
Required Not created by default |
& Note:
l If a node is specified as permit, routing information meeting the node’s conditions will be handled using the apply clauses of this node, without needing to match the next node. If routing information does not meet the node’s conditions, it will go to the next node for matching.
l If a node is specified as deny, the apply clauses of the node will not be executed. When routing information meets all if-match clauses, it cannot pass the node, nor can it go to the next node. If route information cannot meet any if-match clause of the node, it will go to the next node for matching.
l When a routing policy is defined with more than one node, at least one node should be configured using the permit keyword. If the routing policy is used to filter routing information, routing information that does not meet any node’s conditions cannot pass the routing policy. If all nodes of the routing policy are set using the deny keyword, no routing information can pass it.
6.3.3 Defining if-match Clauses for the Routing Policy
To define if-match clauses for a route-policy, use the following command:
|
To do… |
Use the command… |
Remarks |
|
|
Enter system view |
system-view |
— |
|
|
Enter routing policy view |
route-policy route-policy-name { permit | deny } node node-number |
— |
|
|
Define if-match clauses to match IPv4 routing information(source/destination address, next hop) |
Specifies an ACL to match destinations in IPv4 routing information |
if-match acl acl-number |
Optional Not configured by default |
|
Specifies an IP prefix list to match destinations in IPv4 routing information |
if-match ip-prefix ip-prefix-name |
||
|
Match next hop or source address in IPv4 routing information |
if-match ip { next-hop | route-source } { acl acl-number | ip-prefix ip-prefix-name } |
Optional Not configured by default |
|
|
Set conditions to match AS path field of BGP routing information |
if-match as-path as-path-acl-number&<1-16> |
Optional Not configured by default |
|
|
Match community attribute of BGP routing information |
if-match community { basic-community-list-number [ whole-match ] | adv-community-list-number }&<1-16> |
Optional Not configured by default |
|
|
Match route cost of routing information |
if-match cost value |
Optional Not configured by default |
|
|
Match outbound interface of routing information |
if-match interface { interface-type interface-number }&<1-16> |
Optional Not configured by default |
|
|
Match types of routes |
if-match route-type { internal | external-type1 | external-type2 | external-type1or2 | is-is-level-1 | is-is-level-2 | nssa-external-type1 | nssa-external-type2 | nssa-external-type1or2 } * |
Optional Not configured by default |
|
|
Match the tag of RIP, OSPF, IS-IS routes |
if-match tag value |
Optional Not configured by default |
|
& Note:
l The if-match clauses of a route-policy are in logic AND relationship, namely, routing information has to satisfy all if-match clauses before executed with apply clauses.
l You can specify no or multiple if-match clauses for a routing policy. If no if-match clause is specified, and the routing policy is in permit mode, all routing information can pass the node, or in deny mode, no routing information can pass.
6.3.4 Defining apply Clauses for the Routing Policy
To define apply clauses for a route-policy, use the following command:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enter routing policy view |
route-policy route-policy-name { permit | deny } node node-number |
— |
|
Set AS_Path of BGP routing information |
Optional Not set by default |
|
|
Specify a community list according to which to delete community attributes of BGP routing information |
apply comm-list comm-list-number delete |
Optional Not configured by default |
|
Set community attribute of BGP routing information |
apply community { none | additive | { community-number&<1-16> | aa:nn&<1-16> | no-export-subconfed | no-export | no-advertise } * [ additive ] } |
Optional Not set by default |
|
Set the cost of routing information |
apply cost [ + | - ] value |
Optional Not set by default |
|
Set the cost type of routing information |
apply cost-type [ external | internal | type-1 | type-2 ] |
Optional Not set by default |
|
Set the next hop for IPv4 routing information |
apply ip-address next-hop ip-address |
Optional Not set by default |
|
Redistribute routes to a specified ISIS level |
apply isis { level-1 | level-1-2 | level-2 } |
Optional Not configured by default |
|
Set the local preference of BGP routing information |
apply local-preference preference |
Optional Not set by default |
|
Set origin attributes of BGP routing information |
apply origin { igp | egp as-number | incomplete } |
Optional Not set by default |
|
Set routing protocol preference |
apply preference preference |
Optional Not set by default |
|
Set the preferred value of BGP routing information |
apply preferred-value preferred-value |
Optional Not set by default |
|
Set the tag field of RIP, OSPF and IS-IS routing information |
apply tag value |
Optional Not set by default |
& Note:
The apply ip-address next-hop command does not apply to redistributed IPv4 routes.
6.4 Displaying and Maintaining the Routing Policy
|
To do… |
Use the command… |
Remarks |
|
Display BGP AS path ACL information |
display ip as-path-acl [ as-path-acl-number ] |
Available in any view |
|
Display BGP community list information |
display ip community-list [ basic-community-list-number | adv-community-list-number ] |
|
|
Display IPv4 prefix list statistics |
display ip ip-prefix [ ip-prefix-name ] |
|
|
Display routing policy information |
display route-policy [ route-policy-name ] |
|
|
Clear IPv4 prefix list statistics |
reset ip ip-prefix [ ip-prefix-name ] |
Available in user view |
6.5 Routing Policy Configuration Example
6.5.1 Applying Routing Policy When Redistributing IPv4 Routes
I. Network Requirements
l Switch B exchanges routing information with Switch A via OSPF, with Switch C via IS-IS.
l On Switch B, configure route redistribution from IS-IS to OSPF and apply a routing policy to set attributes of redistributed routes, setting the cost of route 172.17.1.0/24 to 100, tag of route 172.17.2.0/24 to 20.
II. Network diagram
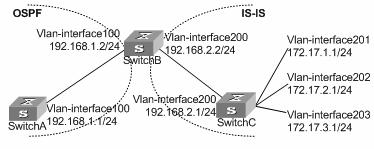
Figure 6-1 Network diagram for routing policy application to route redistribution
III. Configuration procedure
1) Specify IP addresses for interfaces (omitted).
2) Configure IS-IS
# Configure Switch C.
<SwitchC> system-view
[SwitchC] isis
[SwitchC-isis-1] is-level level-2
[SwitchC-isis-1] network-entity 10.0000.0000.0001.00
[SwitchC-isis-1] quit
[SwitchC] interface vlan-interface 200
[SwitchC-Vlan-interface200] isis enable
[SwitchC-Vlan-interface200] quit
[SwitchC] interface vlan-interface 201
[SwitchC-Vlan-interface201] isis enable
[SwitchC-Vlan-interface201] quit
[SwitchC] interface vlan-interface 202
[SwitchC-Vlan-interface202] isis enable
[SwitchC-Vlan-interface202] quit
[SwitchC] interface vlan-interface 203
[SwitchC-Vlan-interface203] isis enable
[SwitchC-Vlan-interface203] quit
# Configure Switch B.
<SwitchB> system-view
[SwitchB] isis
[SwitchB-isis-1] is-level level-2
[SwitchB-isis-1] network-entity 10.0000.0000.0002.00
[SwitchB-isis-1] quit
[SwitchB] interface vlan-interface 200
[SwitchB-Vlan-interface200] isis enable
[SwitchB-Vlan-interface200] quit
3) Configure OSPF and route redistribution
# Configure Switch A: enable OSPF.
<SwitchA> system-view
[SwitchA] ospf
[SwitchA-ospf-1] area 0
[SwitchA-ospf-1-area-0.0.0.0] network 192.168.1.0 0.0.0.255
[SwitchA-ospf-1-area-0.0.0.0] quit
[SwitchA-ospf-1] quit
# Configure Switch B: enable OSPF and redistribute routes from IS-IS.
[SwitchB] ospf
[SwitchB-ospf-1] area 0
[SwitchB-ospf-1-area-0.0.0.0] network 192.168.1.0 0.0.0.255
[SwitchB-ospf-1-area-0.0.0.0] quit
[SwitchB-ospf-1] import-route isis 1
[SwitchB-ospf-1] quit
# Display OSPF routing table on Switch A to view redistributed routes.
[SwitchA] display ospf routing
OSPF Process 1 with Router ID 192.168.1.1
Routing Tables
Routing for Network
Destination Cost Type NextHop AdvRouter Area
192.168.1.0/24 1 Transit 192.168.1.1 192.168.1.1 0.0.0.0
Routing for ASEs
Destination Cost Type Tag NextHop AdvRouter
172.17.1.0/24 1 Type2 1 192.168.1.2 192.168.2.2
172.17.2.0/24 1 Type2 1 192.168.1.2 192.168.2.2
172.17.3.0/24 1 Type2 1 192.168.1.2 192.168.2.2
192.168.2.0/24 1 Type2 1 192.168.1.2 192.168.2.2
Total Nets: 5
Intra Area: 1 Inter Area: 0 ASE: 4 NSSA: 0
4) Configure filtering lists
# Configure an ACL with the number of 2002, letting pass route 172.17.2.0/24.
[SwitchB] acl number 2002
[SwitchB-acl-basic-2002] rule permit source 172.17.2.0 0.0.0.255
[SwitchB-acl-basic-2002] quit
# Configure an IP prefix list named prefix-a, letting pass route 172.17.1.0/24.
[SwitchB] ip ip-prefix prefix-a index 10 permit 172.17.1.0 24
5) Configure a routing policy.
[SwitchB] route-policy isis2ospf permit node 10
[SwitchB-route-policy] if-match ip-prefix prefix-a
[SwitchB-route-policy] apply cost 100
[SwitchB-route-policy] quit
[SwitchB] route-policy isis2ospf permit node 20
[SwitchB-route-policy] if-match acl 2002
[SwitchB-route-policy] apply tag 20
[SwitchB-route-policy] quit
[SwitchB] route-policy isis2ospf permit node 30
[SwitchB-route-policy] quit
6) Apply the routing policy to route redistribution.
# Configure Switch B: apply the routing policy when redistributing routes.
[SwitchB] ospf
[SwitchB-ospf-1] import-route isis 1 route-policy isis2ospf
[SwitchB-ospf-1] quit
# Display OSPF routing table on Switch A. You can find the cost of route 172.17.1.0/24 is 100, tag of route 172.17.1.0/24 is 20, and other external routes have no change.
[SwitchA] display ospf routing
OSPF Process 1 with Router ID 192.168.1.1
Routing Tables
Routing for Network
Destination Cost Type NextHop AdvRouter Area
192.168.1.0/24 1 Transit 192.168.1.1 192.168.1.1 0.0.0.0
Routing for ASEs
Destination Cost Type Tag NextHop AdvRouter
172.17.1.0/24 1 Type2 1 192.168.1.2 192.168.2.2
172.17.2.0/24 1 Type2 1 192.168.1.2 192.168.2.2
172.17.3.0/24 1 Type2 1 192.168.1.2 192.168.2.2
192.168.2.0/24 1 Type2 1 192.168.1.2 192.168.2.2
Total Nets: 5
Intra Area: 1 Inter Area: 0 ASE: 4 NSSA: 0
6.6 Troubleshooting Routing Policy Configuration
6.6.1 IPv4 Routing Information Filtering Failed
I. Symptom
Filtering routing information failed, while routing protocol runs normally.
II. Analysis
At least one item of the IP prefix list should be configured as permit mode, and at least one node in the Route-policy should be configured as permit mode.
III. Processing procedure
1) Use the display ip ip-prefix command to display IP prefix list.
2) Use the display route-policy command to display route policy information.
Chapter 7 GR Configuration
& Note:
The term “router” in this document refers to a router in a generic sense or an Ethernet switch running routing protocols.
7.1 Introduction to Graceful Restart
7.1.1 Graceful Restart Overview
Graceful Restart ensures the continuity of packet forwarding when a routing protocol restarts.
The mechanism of Graceful Restart works as follows: after the routing protocol on a Graceful Restart capable device has restarted, the device will notify its neighbors to temporarily preserve its adjacency with them and the routing information. The neighbors will help the restarting device to update its routing information and to restore it to the state prior to the restart in minimal time. The routing and forwarding remain highly stable across the restart, the packet forwarding path remains the same, and the whole system can forward IP packets continuously. Hence, it is called “Graceful Restart”.
7.1.2 Basic Mechanism of Graceful Restart
I. Basic concepts in Graceful Restart
A router with the Graceful Restart feature enabled is called a Graceful Restart capable router. It can perform a Graceful Restart when its routing protocol restarts. Routers that are not Graceful Restart capable will follow the normal restart procedures after a routing protocol restart.
l GR Restarter: Graceful restarting router, the router whose routing protocol has restarted due to administrator instructions or network failure. It must be Graceful Restart capable.
l GR Helper: The neighbor of the GR Restarter, which helps the GR Restarter to retain the routing information. It must be Graceful Restart capable.
l GR Session: A Graceful Restart session, which is the negotiation between the GR Restarter and the GR Helper. A GR session includes restart notification and communications across restart. Through this session, GR Restarter and GR Helper can know the GR capability of each other.
l GR Time: The time taken for the GR Restarter and the GR Helper to establish a session between them. Upon detection of the down state of a neighbor, the GR Helper will preserve the topology and routing information sent from the GR Restarter for a period as specified by the GR Time.
II. Graceful Restart communication procedure
Configure a device as GR Restarter in a network. This device and its GR Helper must support GR or be GR capable. Thus, when GR Restarter restarts, its GR Helper can know its restart process.
& Note:
l In some cases, GR Restarter and GR Helper can replace with each other.
l If a router is to perform a Graceful Restart, it must have the ability to preserve the routing information in the routing table (forwarding table). Routers that fail to meet this can only act as the GR Helper.
The communication procedure between the GR Restarter and the GR Helper works as follows:
1) A GR session is established between the GR Restarter and the GR Helper.

Figure 7-1 A GR session is established between the GR Restarter and the GR Helper
As illustrated in Figure 7-1, Router A works as GR Restarter, Router B, Router C and Router D are the GR Helpers of Router A. A GR session is established between the GR Restarter and the GR Helper.
2) GR Restarter restarting

Figure 7-2 Restarting process for the GR Restarter
As illustrated in Figure 7-2. The GR Helper detects that the GR Restarter has restarted its routing protocol and assumes that it will recover within the GR Time. Before the GR Time expires, the GR Helper will neither terminate the session with the GR Restarter nor delete the topology or routing information of the latter.
3) GR Restarter signaling to GR Helper

Figure 7-3 The GR Restarter signals to the GR Helper(s) after restart
As illustrated in Figure 7-3, after the GR Restarter has recovered, it will signal to all its neighbors and will reestablish GR Session.
4) The GR Restarter obtaining topology and routing information from the GR Helper

Figure 7-4 The GR Restarter obtains topology and routing information from the GR Helper
As illustrated in Figure 7-4, the GR Restarter obtains the necessary topology and routing information from all its neighbors through the GR sessions between them and calculates its own routing table based on this information.
7.1.3 Graceful Restart Mechanism for Several Commonly Used Protocols
I. BGP-based Graceful Restart
1) To establish a session with its peer, a BGP-based GR Restarter needs to send an OPEN message first to its peer including its Graceful Restart Capability.
2) Upon receipt of this message, the peer is aware that the sending router is capable of Graceful Restart. It will use the OPEN messages to exchange the Graceful Restart Capability with the GR Restarter and to establish a GR session with it. If neither party has the Graceful Restart Capability, the session established between them will not be Graceful Restart Capable.
3) The GR session between the GR Restarter and the GR Helper goes down when a BGP restarts. A Graceful Restart Capable GR Helper will mark all routes associated with the GR Restarter as stale. However, during the configured GR Time, it still uses these routes in packet forwarding, ensuring that no packet will be lost when routing information from its peer is recollected.
4) After the restart, the GR Restarter will reestablish the GR session with its peer and send new GR messages notifying the completion of restart. Routing information can be exchanged between the peers and used by the GR Restarter in creating the new routing table (forwarding table) in place of the stale routing information. Thus the BGP routing convergence is complete.
II. OSPF-based Graceful Restart
When an OSPF-based GR Restarter restarts its OSPF, it needs to perform the following two tasks in order to update its link-state database with its neighbor.
1) To obtain once again effective OSPF adjacency while retaining the original one.
2) To obtain once again link-state database information.
Before the restart, the GR Restarter originates Grace-LSA negotiation GR capability. During the restart, the GR Helper continues to advertise its adjacency with the GR Restarter.
After the restart, the GR Restarter will send an OSPF GR signal to its neighbor so that the adjacency is not reset. In this way, the GR Restarter can restore its adjacency with its neighbor upon receiving the responses from the latter.
Upon the reestablishment of the adjacency, the GR Restarter will update its link-state database with all of its GR Capable neighbors and exchange routing information with them. After that, the GR Restarter will update its own routing table (forwarding table) based on the new routing information and delete the stale routes. In this way, the OSPF routing convergence is complete.
III. IS-IS-based Graceful Restart
When an IS-IS based GR Restarter restarts its IS-IS, it needs to perform the following two tasks in order to update its link state database with its neighbor.
l To obtain once again effective IS-IS adjacency while retaining the original one.
l To obtain once again link-state database information.
After the restart, the GR Restarter will send an IS-IS GR signal to its adjacent GR Helper so that the adjacency is not reset. In this way, the GR Restarter can restore its adjacency with its IS-IS neighbor upon receiving responses from the latter.
After the adjacency has been reestablished, the GR Restarter will update its link-state database with all of its GR Capable IS-IS neighbors and exchange routing information with them. After that, the GR Restarter will update its own routing table (forwarding table) based on the new routing information and delete and the stale routes. In this way, the IS-IS routing convergence is complete.
7.2 Configuring Graceful Restart
H3C S3610&S5510 series support the Graceful Restart (GR) function. After GR is enabled (except being configured as GR Helper of OSPF), the system determines whether the device is to serve as GR Restarter or GR Helper based on real application.
For example, when a user restarts a routing process (OSPF/IS-IS), the current device will serve as GR Restarter, while the peer device will serve as GR Helper. If a user on the peer device restarts a routing process (OSPF/IS-IS), the current device will serve as GR Helper, while the peer device will serve as GR Restarter.
Graceful Restart configuration can be normally achieved by enabling the Graceful Restart Capability. The time parameters can be configured if necessary, but under normal circumstances the defaults should be used.
Note that, with BGP-based Graceful Restart, H3C S3610&S5510 series act as GR Helpers only.
7.2.1 Configuring BGP-based Graceful Restart
Follow these steps to configure GR on the GR Helper:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enable BGP, and enter its view |
bgp as-number |
Required Disabled by default |
|
Enable Graceful Restart Capability for BGP |
graceful-restart |
Required Disabled by default |
|
Configure the maximum time allowed for the peer to reestablish a BGP session |
graceful-restart timer restart timer |
Optional Defaults to 360 seconds |
|
Configure the maximum time to wait for the End-of-RIB marker |
graceful-restart timer wait-for-rib timer |
Optional Defaults to 180 seconds |
|
Note: End-of-RIB = End of Router-Information-Base |
||
& Note:
l In general the maximum time allowed for the peer to reestablish a BGP session should be less than the HOLDTIME carried in the OPEN message. Upon detection of the termination of the session, the GR Helper will wait for a period of time as specified by the GR Time before it reestablishes the BGP session.
l The End-of-RIB marker can be used to indicate that the updated routing information has been sent.
7.2.2 Configuring OSPF-based Graceful Restart
I. Configuring OSPF-based GR Restarter
Follow these steps to configure GR on the GR Restarter:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enable OSPF and enter its view |
ospf [ process-id | router-id router-id ] * |
Required Disabled by default |
|
Enable the use of link-local signaling |
enable link-local-signaling |
Required Disabled by default |
|
Enable out-of-band resynchronization |
enable out-of-band-resynchronization |
Required Disabled by default |
|
Enable Graceful Restart Capability for OSPF |
graceful-restart |
Required Disabled by default |
II. Configuring OSPF-based GR Helper
Follow these steps to configure GR on the GR Helper:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enable OSPF, and enter OSPF view |
ospf [ process-id | router-id router-id ] * |
Required Disabled by default |
|
Enable the use of link-local signaling |
enable link-local-signaling |
Required Disabled by default |
|
Enable out-of-band resynchronization |
enable out-of-band-resynchronization |
Required Disabled by default |
|
Configure the GR Helper Capability and specify the routers for which the current router can serve as a GR Helper |
graceful-restart help { acl-number | prefix prefix-list } |
Required Disabled by default. |
7.2.3 Configuring IS-IS-based Graceful Restart
An ISIS restart may cause the termination of the adjacency between a restarting router and its neighbors, resulting in transient network disconnection.
IS-IS-based Graceful Restart can help to solve this problem by notifying its neighbors its restarting state to allow them to reestablish the adjacency without removing it. The IS-IS-based Graceful Restart provides the following enhancements:
l In the event of an ISIS restart, a Graceful Restart Capable device will resend connection requests to its neighbors instead of terminating their neighboring relationship.
l Graceful Restart has minimized the disruption on network traffic caused by the waiting occurred due to data synchronization before LSP packets generation.
l For a router starts for the first time, in LSP packets overload bit is set to achieve database synchronization, which ensures no loopback is created in a network.
Graceful Restart Interval is configured as the Remaining Lifetime contained in the IS-IS Hello PDU so that the adjacency between a GR Restarter and its neighbors can be maintained across restart.
Setting the SA bit is to suppress the advertisement of the adjacency to the restarting router in the Hello PDU across restart. In this way, the neighbors of the GR Restarter will not advertise the adjacency within the specified period until the completion of data synchronization between the GR Restarter and its GR Helpers. This feature helps to effectively avoid the possible black holes across GR restart due to the sending or receiving of LSP.
Follow these steps to configure GR on the GR Restarter GR Helper respectively:
|
To do… |
Use the command… |
Remarks |
|
Enter system view |
system-view |
— |
|
Enable IS-IS, and enter IS-IS view. |
isis [ process-id ] |
Required Disabled by default |
|
Enable Graceful Restart Capability for IS-IS |
graceful-restart |
Required Disabled by default |
|
Set the Graceful Restart interval |
graceful-restart interval timer |
Optional Defaults to 300 seconds |
|
Configure to set the SA (Suppress-Advertisement) bit during restart |
graceful-restart suppress-sa |
Optional By default, the SA bit is clear. |
7.3 Displaying and Maintaining Graceful Restart
|
To do… |
Use the command… |
Remarks |
|
Display the Graceful Restart state for IS-IS |
display isis graceful-restart status [ level-1 | level-2 ] [ process-id ] |
Available in any view |
|
Restart OSPF Graceful Restart |
reset ospf [ process-id ] process graceful-restart |
Required Available in user view |
7.4 Graceful Restart Configuration Example
7.4.1 IS-IS-based Graceful Restart Configuration Example
I. Network requirements
Switch A, Switch B, and Switch C belong to the same domain and use IS-IS as their routing protocol. Switch A acts as GR Restarter, while Switch B and Switch C act as GR Helpers, as illustrated in Figure 7-5.
II. Network diagram
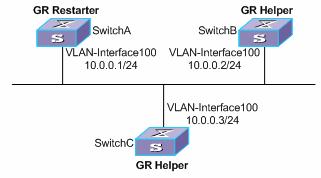
Figure 7-5 IS-IS-based Graceful Restart configuration example
III. Configuration procedure
What follows is a Graceful Restart configuration example based on Switch A. Configurations for Switch B and Switch C are similar.
# Enable IS-IS Graceful Restart on Switch A and configure the Graceful Restart Interval.
<SwitchA> system-view
[SwitchA] isis 1
[SwitchA-isis-1] graceful-restart
[SwitchA-isis-1] graceful-restart interval 150
The adjacency between Switch A, Switch B, and Switch C is established and information can be exchanged between them. The IS-IS on Switch A has restarted, which puts Switch A into a restart state. Switch A sends connection requests to its neighbors through the Graceful Restart mechanism to update the database. Its restart status can be displayed using the display isis graceful-restart status command.
# Restart Switch A and check the restart status.
<SwitchA> reset isis all 1
Warning : Reset ISIS process? [Y/N]:y
<SwitchA> display isis graceful-restart status
Restart information for ISIS(1)
-------------------------------
IS-IS(1) Level-1 Restart Status
Restart Interval: 150
SA Bit Not Supported
Total Number of Interfaces = 1
Restart Status: RESTART COMPLETE
IS-IS(1) Level-2 Restart Status
Restart Interval: 150
SA Bit Not Supported
Total Number of Interfaces = 1
Restart Status: RESTART COMPLETE
7.4.2 OSPF-based Graceful Restart Configuration Example
I. Network requirements
There are three neighboring switches in the network, Switch A, Switch B, and Switch C, in which Switch A acts as the GR Restarter whereas Switch B and Switch C are the GR Helpers. An ACL is configured so that Switch B acts as the GR Helper of Switch A only, while Switch C can act as the GR Helper of any GR-capable device.
II. Network diagram
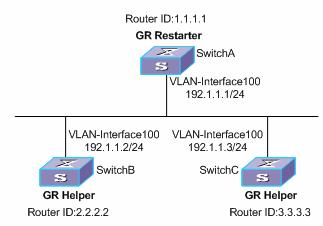
Figure 7-6 OSPF-based Graceful Restart configuration example
III. Configuration procedure
1) Configure Switch A.
<SwitchA> system-view
[SwitchA] interface vlan-interface 100
[SwitchA-Vlan-interface100] ip address 192.1.1.1 255.255.255.0
[SwitchA-Vlan-interface100] quit
[SwitchA] router id 1.1.1.1
[SwitchA] ospf 100
[SwitchA-ospf-100] enable link-local-signaling
[SwitchA-ospf-100] enable out-of-band-resynchronization
[SwitchA-ospf-100] area 0
[SwitchA-ospf-100-area-0.0.0.0] network 192.1.1.0 0.0.0.255
[SwitchA-ospf-100-area-0.0.0.0] quit
2) Configure Switch B.
<SwitchB> system-view
[SwitchB] acl number 2000
[SwitchB-acl-basic-2000] rule 10 permit source 192.1.1.1 0.0.0.0
[SwitchB-acl-basic-2000] quit
[SwitchB] interface vlan-interface 100
[SwitchB-Vlan-interface100] ip address 192.1.1.2 255.255.255.0
[SwitchB-Vlan-interface100] quit
[SwitchB] router id 2.2.2.2
[SwitchB] ospf 100
[SwitchB-ospf-100] enable link-local-signaling
[SwitchB-ospf-100] enable out-of-band-resynchronization
[SwitchB-ospf-100] graceful-restart help 2000
[SwitchB-ospf-100] area 0
[SwitchB-ospf-100-area-0.0.0.0] network 192.1.1.0 0.0.0.255
[SwitchB-ospf-100-area-0.0.0.0] quit
3) Configure Switch C.
<SwitchC> system-view
[SwitchC] interface vlan-interface 100
[SwitchC-Vlan-interface100] ip address 192.1.1.3 255.255.255.0
[SwitchC-Vlan-interface100] quit
[SwitchC] router id 3.3.3.3
[SwitchC] ospf 100
[SwitchC-ospf-100] enable link-local-signaling
[SwitchC-ospf-100] enable out-of-band-resynchronization
[SwitchC-ospf-100] area 0
[SwitchC-ospf-100-area-0.0.0.0] network 192.1.1.0 0.0.0.255
[SwitchC-ospf-100-area-0.0.0.0] quit
4) After the configurations on Switch A, Switch B and Switch C are completed and the switches are running steadily, start GR on Switch A.
<SwitchA> reset ospf 100 process graceful-restart