- 产品与解决方案
- 行业解决方案
- 服务
- 支持
- 合作伙伴
- 关于我们




2023年是人工智能技术风起云涌的一年,从“百模大战”到应用层生态的“百花齐放”,AGI产业迎来爆发期。随着技术的不断发展,AI产业如今已不再是大型企业和组织的专属舞台,越来越多的中小企业和成长型组织也不断加入这一热潮。然而,AI业务应用的高技术门槛和庞大的投入,是客户持续面临的挑战。基于此,新华三携手英特尔打造全新解决方案,助力客户构建自身AI业务。
破局,强强携手激活CPU AI算力
近日,紫光股份旗下新华三集团携手英特尔,推出基于第四代英特尔®至强®可扩展处理器的H3C UniServer R6900 G6大模型微调及推理解决方案,充分释放CPU的AI算力,全面降低了AI训练及推理场景所需的基础设施总体拥有成本,使中小企业能够迅速融入AGI的革新潮流。

该方案可满足7B、13B、30B、34B等大模型微调和推理的不同参数量级,通过检索增强生成技术(Retrieval-Augmented Generation,RAG),可达到与通用大模型接近的理想效果,从而快速实现面向特定领域的AI应用落地部署。
革新,四大技术开辟AGI新天地
H3C UniServer R6900 G6大模型微调及推理解决方案,成功展示了基于中等参数量级(34B及以下)大模型的微调和推理能力。其得益于四大重要技术突破:
英特尔第四代至强平台加速大模型的训练和推理能力
第四代英特尔®至强®可扩展处理器内置的英特尔®AMX加速引擎是面向深度学习工作负载的新一代技术。该技术不仅延续了上一代英特尔至强可扩展处理器的内置AI加速技术,还带来显著的性能提升,非常适合自然语言处理、推荐系统和图像识别等工作负载。英特尔®AMX可提高平铺乘法性能,显著提升吞吐量,使用PyTorch进行实时推理和训练,相比上一代处理器提升了3-10倍的推理和训练性能。
新华三集团四路服务器突破单机算力瓶颈
在微调场景下,部署NVMe硬盘的数量决定了应用性能的高低。H3C UniServer R6900 G6四路服务器单机可部署32块NVMe硬盘,采用高带宽低延迟的UPI互联方案,能够实现CPU算力的高速横向倍增。这意味着可在一个节点上完成所有的计算任务,从而完全避免了分布式训练带来的各种问题,高效助力客户的微调应用。
微调场景下CPU突破显存限制
以Llama-2 30B模型为例,在进行16位浮点数训练时,如果训练批量大小被设定为16并且使用Adam优化器,估算需要600GB左右的显存才能成功完成30B模型的LoRA微调。传统GPU的方案无论是成本还是供应能力,都给中小企业带来了极大的挑战。H3C UniServer R6900 G6服务器可提供高达16TB的内存容量,相比于GPU方案,能够减少显存压缩和多卡间数据通信的消耗,从而更有效地完成微调训练任务,打破显存限制。
突破现有生态的限制
此外,英特尔还提供了一系列基于PyTorch框架的软件优化措施。这些优化被集成在英特尔的IPEX(Intel® Extension for PyTorch)开源软件库中,旨在进一步提升模型的性能和效率。生态体系层面,IPEX配合PyTorch,支持PyTorch框架下90%的主流模型,其中深度优化模型有50个以上。客户只要通过简单几步即可完成BF16混合精度转换,模型即可在保持精度的同时在CPU上高效部署。
得益于成功的生态合作和技术突破,H3C UniServer R6900 G6大模型微调及推理解决方案已在多种尺寸的模型中进行了性能测试,充分验证了性能的优异实力。
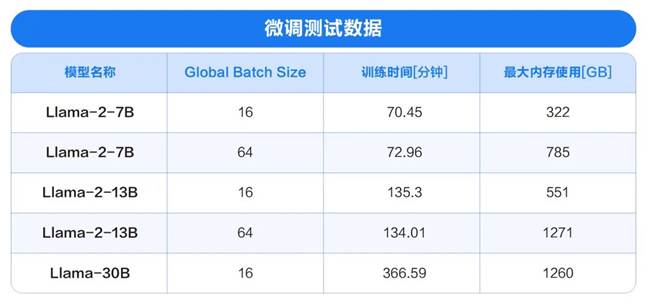
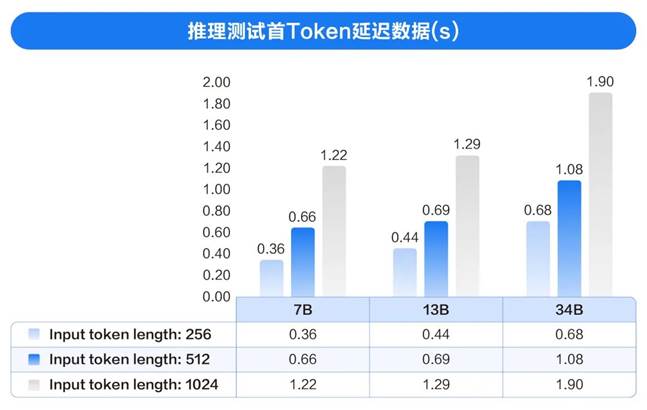
(该测试基于4*Intel 6448H、2TB内存、4TB NVMe
硬盘容量的硬件配置完成)
数字定义世界,AI定义未来。随着数实融合趋势的不断加速,新华三集团将秉持“精耕务实,为时代赋智慧”的理念,持续携手包括英特尔在内的合作伙伴,为百行百业客户提供多样化的智算产品与方案,以“一体·两中枢”的智慧计算体系,不断推进AI产业的变革升级。










