- 产品与解决方案
- 行业解决方案
- 服务
- 支持
- 合作伙伴
- 关于我们
-
-
< 返回
-
行业解决方案
热门推荐
-

- 从县域医院数字化转型需求出发,新华三推出与实际应用场景紧密结合的智慧医院解决方案,提升县医院综合能力,助力县域内医疗资源整合共享。
-

- 最新最全的营销资料,千份营销资料,快速获取!
-
-
-
-
< 返回
-
技术服务解决方案
热门推荐
-

- 面向ICT基础设施提供的一款采用通道封闭,包含工程预制的机柜、配电、制冷、监控等功能单元的独立的小型数据中心,为客户提供数据中心整体产品及交付,全面提升客户IT服务管理水平。
-
-
架构咨询
热门推荐
-
- 面向ICT基础设施提供的一款采用通道封闭,包含工程预制的机柜、配电、制冷、监控等功能单元的独立的小型数据中心,为客户提供数据中心整体产品及交付,全面提升客户IT服务管理水平。
-
-
H3C TaaS服务
热门推荐
-
- 面向ICT基础设施提供的一款采用通道封闭,包含工程预制的机柜、配电、制冷、监控等功能单元的独立的小型数据中心,为客户提供数据中心整体产品及交付,全面提升客户IT服务管理水平。
-
-
统一运维
热门推荐
-
- 面向ICT基础设施提供的一款采用通道封闭,包含工程预制的机柜、配电、制冷、监控等功能单元的独立的小型数据中心,为客户提供数据中心整体产品及交付,全面提升客户IT服务管理水平。
-
-
数据中心
热门推荐
-
- 面向ICT基础设施提供的一款采用通道封闭,包含工程预制的机柜、配电、制冷、监控等功能单元的独立的小型数据中心,为客户提供数据中心整体产品及交付,全面提升客户IT服务管理水平。
-
-
云与智能服务
热门推荐
-
- 面向ICT基础设施提供的一款采用通道封闭,包含工程预制的机柜、配电、制冷、监控等功能单元的独立的小型数据中心,为客户提供数据中心整体产品及交付,全面提升客户IT服务管理水平。
-
-
安全服务与运营
热门推荐
-
- 面向ICT基础设施提供的一款采用通道封闭,包含工程预制的机柜、配电、制冷、监控等功能单元的独立的小型数据中心,为客户提供数据中心整体产品及交付,全面提升客户IT服务管理水平。
-
-
技术维护服务
热门推荐
-
- 面向ICT基础设施提供的一款采用通道封闭,包含工程预制的机柜、配电、制冷、监控等功能单元的独立的小型数据中心,为客户提供数据中心整体产品及交付,全面提升客户IT服务管理水平。
-
-
云软件技术支持服务
热门推荐
-
- 面向ICT基础设施提供的一款采用通道封闭,包含工程预制的机柜、配电、制冷、监控等功能单元的独立的小型数据中心,为客户提供数据中心整体产品及交付,全面提升客户IT服务管理水平。
-
-
智能终端服务
热门推荐
-
- 面向ICT基础设施提供的一款采用通道封闭,包含工程预制的机柜、配电、制冷、监控等功能单元的独立的小型数据中心,为客户提供数据中心整体产品及交付,全面提升客户IT服务管理水平。
-
-
商用终端服务
(台式机 笔记本 显示器)热门推荐
-
- 面向ICT基础设施提供的一款采用通道封闭,包含工程预制的机柜、配电、制冷、监控等功能单元的独立的小型数据中心,为客户提供数据中心整体产品及交付,全面提升客户IT服务管理水平。
-
-
-
-
< 返回
-
技术培训与认证
热门推荐
-
-
-
< 返回
- 如何购买
- 案例中心New
- 数字化领航直播间
- 云上展厅
- 新华三商城










概述
- 概述
- 方案价值
- 关键技术
- 相关资源
概述
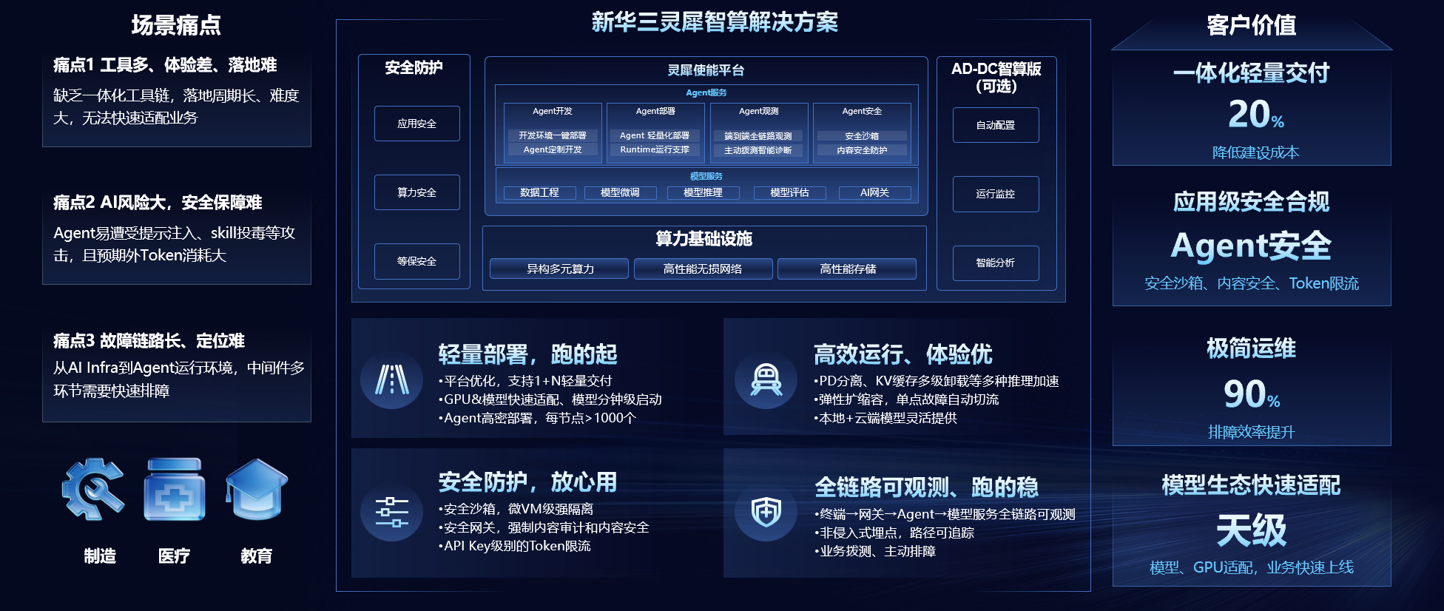
小规模垂类AI应用服务基于大模型部署AI应用场景,可提供数十卡到上百卡级别集群用于中小型企业内部模型推理服务,满足以下典型需求:
1 、大模型高性能运行:针对不同规模的模型,提供单机推理、多机推理、PD分离等多中模式,保障推理服务高效运行
2、多模型适配能力:快速支持DeepSeek、Qwen等主流大模型以及场景化模型的推理适配,保障业务快速上线
3、全栈可观测:支持请求级Trace、P99延迟、显存实时监控,及时发现推理性能瓶颈,基于访问并发需求可快速动态调整推理服务实例
方案价值
-
轻量极简
基于管理节点本地盘优化的存储系统,实现轻量化快速部署,降低建设成本,加速业务上线速度
-
极致性能
基于自研推理引擎的PD分离优化技术,结合RoCE无损网络和超节点,实现长上下文场景(128K)下P99生成延迟降低40%
-
生产级可靠
推理实例多副本反亲和部署,单节点故障自动切流,API-Key级别Token限流,保障推理服务稳定运行
-
开放兼容
支持用户自定义推理引擎和模型,基于统一模型治理,实现模型和客户业务快速适配验证
关键技术
1、统一推理调度:基于模型推理所需资源,自动适配超节点、OAM模组服务器和PCIE标卡服务器,实现算力融合高效调度
2、PD分离引擎优化引擎:适配多种算力资源池,KV Cache多级分离极致支持超长上下文,提升Cache命中率,提升上下文吞吐,降低首Token延迟
3、全栈可观测:从API请求到GPU 的全链路Trace,实现分钟级的定位性能瓶颈和故障恢复
相关资源


