- Table of Contents
-
- 06-Layer 3—IP Routing Configuration Guide
- 00-Preface
- 01-Basic IP routing configuration
- 02-Static routing configuration
- 03-OSPF configuration
- 04-IS-IS configuration
- 05-Basic BGP configuration
- 06-Advanced BGP configuration
- 07-Policy-based routing configuration
- 08-IPv6 static routing configuration
- 09-OSPFv3 configuration
- 10-IPv6 policy-based routing configuration
- 11-Routing policy configuration
- 12-DCN configuration
- Related Documents
-
| Title | Size | Download |
|---|---|---|
| 06-Advanced BGP configuration | 549.43 KB |
Tuning and optimizing BGP networks
Setting the TCP MSS for TCP connections
Enabling BGP to establish an EBGP session over multiple hops
Enabling immediate re-establishment of direct EBGP connections upon link failure
Enabling BGP ORF capabilities negotiation
Enabling BGP ORF capabilities negotiation for a peer or peer group
Enabling nonstandard BGP ORF capabilities negotiation for a peer or peer group
Verifying and maintaining BGP ORF
Enabling 4-byte AS number suppression
Disabling BGP session establishment
About disabling BGP session establishment
Disabling BGP session establishment with a peer or peer group (IPv4 peers)
Disabling BGP session establishment with a peer or peer group (IPv6 peers)
Disabling BGP session establishment with all peers or peer groups
Enabling route refresh (IPv4 peers)
Enabling route refresh (IPv6 peers)
Saving updates (IPv4 unicast address family)
Saving updates (IPv6 unicast address family)
Configuring manual soft-reset (IPv4 unicast address family)
Configuring manual soft-reset (IPv6 unicast address family)
Configuring BGP load balancing
Configuring the BGP Additional Paths feature
Configuring BGP optimal route selection delay
Setting the delay time for responding to recursive next hop changes
Enabling routing policy-based nexthop recursion
Configuring peer flap dampening
Protecting an EBGP peer when memory usage reaches level 2 threshold
Setting a DSCP value for outgoing BGP packets
Flushing the suboptimal BGP route to the RIB
BGP network tuning and optimization configuration examples
Example: Configuring BGP load balancing
Example: Configuring the BGP Additional Paths feature
Configuring BGP security features
BGP security feature configuration tasks at a glance
Enabling MD5 authentication for BGP peers
Improving BGP network reliability
BGP network reliability improvement tasks at a glance
Configuring BGP FRR by using a routing policy (IPv4 unicast address family)
Configuring BGP FRR by using a routing policy (IPv6 unicast address family)
Configuring BGP FRR through PIC (IPv4 unicast address family)
Configuring BGP FRR through PIC (IPv6 unicast address family)
Configuring BFD-powered nexthop connectivity detection for BGP FRR
Configuring BGP maintenance features
About BGP isolation and BGP shutdown
IPv4 BGP network reliability improvement configuration examples
Example: Configuring BFD for BGP
IPv6 BGP network reliability improvement configuration examples
Example: Configuring BFD for IPv6 BGP
Example: Configuring IPv6 BGP FRR
Configuring extended BGP features
Extended BGP feature configuration tasks at a glance
Configuring BGP LS route reflection
Specifying an AS number and a router ID for BGP LS messages
Disabling nexthop changing for BGP LS routes
Enabling routing policy-based nexthop recursion for BGP LS routes
Performing manual soft-reset for BGP sessions of LS address family
Verifying and maintaining BGP LS
Extended IPv4 BGP feature configuration examples
Tuning and optimizing BGP networks
Setting the TCP MSS for TCP connections
About this task
BGP typically establishes a multihop TCP connection with a peer. Multiple intermediate devices might fragment BGP packets due to their MTU settings, resulting in frequent packet encapsulations and decapsulations that reduce forwarding efficiency.
To resolve this issue, you can perform this task to set the TCP maximum segment size (MSS) for a peer or peer group. TCP segments sent by the source will not be re-fragmented along the path to the destination.
During TCP connection establishment with the peer or peer group specified in the peer tcp-mss command, the minimum of the following MSSs takes effect:
· The MSS calculated according to the IPv4 MTU set by the ip mtu command on the peer-facing interface.
· The MSS set by the tcp mss command for the peer-facing interface.
· The MSS calculated according to the path MTU detected by TCP path MTU discovery (enabled with the tcp path-mtu-discovery command).
· The MSS set by the peer tcp-mss command.
The MSS is calculated by using the following formula:
MSS = path MTU (or interface MTU) – IP header length – TCP header length
For more information about MTU and MSS, see IP performance optimization configuration in Layer 3—IP Services Configuration Guide.
Restrictions and guidelines
This task might cause BGP session re-establishment. Make sure you understand the potential impact before performing this task.
Procedure
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Set the TCP MSS for a peer or peer group.
peer { group-name | ipv4-address [ mask-length ] | ipv6-address [ prefix-length ] } tcp-mss mss-value
By default, the TCP MSS is not set.
Enabling BGP to establish an EBGP session over multiple hops
About this task
To establish an EBGP session, two routers must have a direct physical link and use directly connected interfaces. If no direct link is available, you must use the peer ebgp-max-hop command to enable BGP to establish an EBGP session over multiple hops and specify the maximum hops.
Procedure (IPv4 peers)
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Enable BGP to establish an EBGP session to an indirectly connected peer or peer group and specify the maximum hop count.
peer { group-name | ipv4-address [ mask-length ] } ebgp-max-hop [ hop-count ]
By default, BGP cannot establish an EBGP session to an indirectly connected peer or peer group.
Procedure (IPv6 peers)
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Enable BGP to establish an EBGP session to an indirectly connected peer or peer group and specify the maximum hop count.
peer { group-name | ipv6-address [ prefix-length ] } ebgp-max-hop [ hop-count ]
By default, BGP cannot establish an EBGP session to an indirectly connected peer or peer group.
Enabling immediate re-establishment of direct EBGP connections upon link failure
About this task
With this feature disabled, when the link to a directly connected EBGP peer goes down, the router does not re-establish a session to the peer until the hold time timer expires. This feature enables BGP to immediately recreate the session in that situation. When this feature is disabled, route flapping does not affect EBGP session state.
Procedure
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Enable immediate re-establishment of direct EBGP connections upon link failure.
ebgp-interface-sensitive
By default, immediate re-establishment of direct EBGP connections is enabled.
Enabling BGP ORF capabilities negotiation
About BGP ORF
BGP Outbound Route Filtering (ORF) saves the system resources by reducing the route updates that are sent between BGP peers.
The BGP peers negotiate the ORF capabilities through Open messages. After completing the negotiation process, the BGP peers can exchange ORF information (local route reception filtering policy) through route refresh messages. Then, only routes that pass both the local route distribution filtering policy and the received route reception filtering policy can be advertised.
Restrictions and guidelines
You can enable the ORF information sending, receiving, or both sending and receiving capabilities on a BGP router. For two BGP peers to successfully negotiate the ORF capabilities, make sure one end has the sending capability and the other end has the receiving capability.
After you enable BGP ORF capabilities negotiation for a peer, the local device negotiates standard ORF capabilities as defined in RFC with the peer. If the peer uses nonstandard ORF, you must also enable nonstandard ORF capabilities negotiation for the peer.
Enabling BGP ORF capabilities negotiation for a peer or peer group
Procedure (IPv4 unicast)
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Enter BGP IPv4 unicast address family view.
address-family ipv4 [ unicast ]
4. Enable BGP ORF capabilities negotiation for a peer or peer group.
peer { group-name | ipv4-address [ mask-length ] | ipv6-address [ prefix-length ] } capability-advertise orf prefix-list { both | receive | send }
By default, BGP ORF capabilities negotiation is disabled for a peer or peer group.
Procedure (IPv6 unicast)
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Enter BGP IPv6 unicast address family view.
address-family ipv6 [ unicast ]
4. Enable BGP ORF capabilities negotiation for a peer or peer group.
peer { group-name | ipv4-address [ mask-length ] | ipv6-address [ prefix-length ] } capability-advertise orf prefix-list { both | receive | send }
By default, BGP ORF capabilities negotiation is disabled for a peer or peer group.
Enabling nonstandard BGP ORF capabilities negotiation for a peer or peer group
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Enable nonstandard BGP ORF capabilities negotiation for a peer or peer group.
peer { group-name | ip-address [ mask-length ] | ipv6-address [ prefix-length ] } capability-advertise orf non-standard
By default, nonstandard BGP ORF capabilities negotiation is disabled for a peer or peer group.
Verifying and maintaining BGP ORF
Perform displays tasks in any view.
· Display the ORF prefix information received by an IPv4 unicast peer.
display bgp [ instance instance-name ] peer ipv4 [ unicast ] ipv4-address received prefix-list
· Display the ORF prefix information received by an IPv6 unicast peer.
display bgp [ instance instance-name ] peer ipv6 [ unicast ] ipv6-address received prefix-list
display bgp [ instance instance-name ] peer ipv6 [ unicast ] ipv4-address received prefix-list
Enabling 4-byte AS number suppression
About this task
BGP supports 4-byte AS numbers. The 4-byte AS number occupies four bytes, in the range of 1 to 4294967295. By default, a device sends an OPEN message to the peer device for session establishment. The OPEN message indicates that the device supports 4-byte AS numbers. If the peer device supports 2-byte AS numbers instead of 4-byte AS numbers, the session cannot be established. To resolve this issue, enable the 4-byte AS number suppression feature. The device then sends an OPEN message to inform the peer that it does not support 4-byte AS numbers, so the BGP session can be established.
Restrictions and guidelines
If the peer device supports 4-byte AS numbers, do not enable the 4-byte AS number suppression feature. Otherwise, the BGP session cannot be established.
Procedure (IPv4 peers)
1. Enter system view.
system-view
2. Enable 4-byte AS number suppression.
peer { group-name | ipv4-address [ mask-length ] } capability-advertise suppress-4-byte-as
By default, 4-byte AS number suppression is disabled.
Procedure (IPv6 peers)
1. Enter system view.
system-view
2. Enable 4-byte AS number suppression.
peer { group-name | ipv6-address [ prefix-length ] } capability-advertise suppress-4-byte-as
By default, 4-byte AS number suppression is disabled.
Disabling BGP session establishment
About disabling BGP session establishment
This task enables you to temporarily tear down BGP sessions to a peer or peer group. You can perform network upgrade and maintenance without deleting and reconfiguring the peers and peer groups. To recover the sessions, execute the undo peer ignore command.
To lower the priority of the routes advertised by BGP, you can specify the graceful keyword in the peer ignore command or the ignore all-peers command, and configure route attribures. BGP peers can then select other peers' routes as optimal routes, which avoids traffic interruption upon wait timer expiration or peer disconnection. To enable BGP to advertise low-priority routes without tearing down BGP sessions, you can set the value for the graceful graceful-time option to 0.
If you specify the graceful keyword in the peer ignore command, BGP performs the following tasks:
1. Starts the wait timer specified with the graceful keyword.
2. Advertises all routes to the specified peer or peer group and changes the attribute of the advertised routes to the specified value.
Advertises routes from the specified peer or peer group to other IBGP peers and peer groups and changes the attribute of the advertised routes to the specified value.
3. Shuts down the session to the specified peer or peer group after the wait timer expires.
If you specify the graceful keyword in the ignore all-peers command, BGP performs the following tasks:
1. Starts the wait timer specified with the graceful keyword.
2. Advertises all routes to all peers and peer groups and changes the attribute of the advertised routes to the specified value.
3. Shuts down all sessions to peers and peer groups after the wait timer expires.
Restrictions and guidelines
For a BGP peer or peer group, the configuration made by the peer ignore command takes precedence over the configuration made by the ignore all-peers command.
Disabling BGP session establishment with a peer or peer group (IPv4 peers)
1. Enter system view.
system-view
2. Disable BGP session establishment with a peer or peer group.
peer { group-name | ipv4-address [ mask-length ] } ignore [ graceful graceful-time { community { community-number | aa:nn } | local-preference preference | med med } * ]
By default, BGP can establish a session to a peer or peer group.
|
|
CAUTION: · If a session has been established to a peer, executing the peer ignore command for the peer tears down the session and clears all related routing information. · If sessions have been established to a peer group, executing the peer ignore command for the peer group tears down the sessions to all peers in the group and clears all related routing information. |
Disabling BGP session establishment with a peer or peer group (IPv6 peers)
1. Enter system view.
system-view
2. Disable BGP session establishment with a peer or peer group.
peer { group-name | ipv6-address [ prefix-length ] } ignore [ graceful graceful-time { community { community-number | aa:nn } | local-preference preference | med med } * ]
By default, BGP can establish a session to a peer or peer group.
|
|
CAUTION: · If a session has been established to a peer, executing the peer ignore command for the peer tears down the session and clears all related routing information. · If sessions have been established to a peer group, executing the peer ignore command for the peer group tears down the sessions to all peers in the group and clears all related routing information. |
Disabling BGP session establishment with all peers or peer groups
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Disable BGP session establishment with all peers or peer groups.
ignore all-peers [ graceful graceful-time { community { community-number | aa:nn } | local-preference preference | med med } * ]
By default, BGP can establish sessions to all peers and peer groups.
|
|
CAUTION: Executing the ignore all-peers command tears down all existing sessions to peers and peer groups and clears all related routing information. |
Configuring BGP soft-reset
About BGP soft-reset
After you modify the route selection policy, for example, modify the preferred value, you must reset BGP sessions to apply the new policy. The reset operation tears down and re-establishes BGP sessions.
To avoid tearing down BGP sessions, you can use one of the following soft-reset methods to apply the new policy:
· Enabling route refresh—The BGP router advertises a ROUTE-REFRESH message to the specified peer, and the peer resends its routing information to the router. After receiving the routing information, the router filters the routing information by using the new policy.
This method requires that both the local router and the peer support route refresh.
· Saving updates—Use the peer keep-all-routes command to save all route updates from the specified peer. After modifying the route selection policy, filter routing information by using the new policy.
This method does not require that the local router and the peer support route refresh but it uses more memory resources to save routes.
· Manual soft-reset—Use the refresh bgp command to enable BGP to send local routing information or advertise a ROUTE-REFRESH message to the specified peer. The peer then resends its routing information. After receiving the routing information, the router filters the routing information by using the new policy.
This method requires that both the local router and the peer support route refresh.
Enabling route refresh (IPv4 peers)
1. Enter system view.
system-view
2. Enable BGP route refresh for a peer or peer group.
¡ Enable BGP route refresh for the specified peer or peer group.
peer { group-name | ipv4-address [ mask-length ] } capability-advertise route-refresh
¡ Enable the BGP route refresh, multi-protocol extension, and 4-byte AS number features for the specified peer or peer group.
undo peer { group-name | ipv4-address [ mask-length ] } capability-advertise conventional
By default, the BGP route refresh, multi-protocol extension, and 4-byte AS number features are enabled.
Enabling route refresh (IPv6 peers)
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Enable BGP route refresh for a peer or peer group.
¡ Enable BGP route refresh for the specified peer or peer group.
peer { group-name | ipv6-address [ prefix-length ] } capability-advertise route-refresh
¡ Enable the BGP route refresh, multi-protocol extension, and 4-byte AS number features for the specified peer or peer group.
undo peer { group-name | ipv6-address [ prefix-length ] } capability-advertise conventional
By default, the BGP route refresh, multi-protocol extension, and 4-byte AS number features are enabled.
Saving updates (IPv4 unicast address family)
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Enter BGP IPv4 unicast address family view.
address-family ipv4 [ unicast ]
4. Save all route updates from the peer or peer group.
peer { group-name | ipv4-address [ mask-length ] | ipv6-address [ prefix-length ] } keep-all-routes
By default, route updates from peers and peer groups are not saved.
This command takes effect only for the routes received after this command is executed.
Saving updates (IPv6 unicast address family)
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Enter BGP IPv6 unicast address family view.
address-family ipv6 [ unicast ]
4. Save all route updates from the peer or peer group.
peer { group-name | ipv4-address [ mask-length ] | ipv6-address [ prefix-length ] } keep-all-routes
By default, route updates from peers and peer groups are not saved.
This command takes effect only for the routes received after this command is executed.
Configuring manual soft-reset (IPv4 unicast address family)
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Enable BGP route refresh for a peer or peer group.
¡ Enable BGP route refresh for the specified peer or peer group.
peer { group-name | ipv4-address [ mask-length ] } capability-advertise route-refresh
¡ Enable the BGP route refresh, multi-protocol extension, and 4-byte AS number features for the specified peer or peer group.
undo peer { group-name | ipv4-address [ mask-length ] } capability-advertise conventional
By default, the BGP route refresh, multi-protocol extension, and 4-byte AS number features are enabled.
4. Execute the quit command twice to return to user view.
quit
5. Perform manual soft-reset. Choose one option as needed:
¡ Perform manual soft-reset on IPv4 sessions in BGP IPv4 address family.
refresh bgp [ instance instance-name ] { ipv4-address [ mask-length ] | all | external | group group-name | internal } { export | import } ipv4 [ unicast ]
¡ Perform manual soft-reset on IPv6 sessions in BGP IPv4 address family.
refresh bgp [ instance instance-name ] { ipv6-address [ prefix-length ] | all | external | group group-name | internal } { export | import } ipv4 [ unicast ]
Configuring manual soft-reset (IPv6 unicast address family)
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Enable BGP route refresh for a peer or peer group.
¡ Enable BGP route refresh for the specified peer or peer group.
peer { group-name | ipv6-address [ prefix-length ] } capability-advertise route-refresh
¡ Enable the BGP route refresh, multi-protocol extension, and 4-byte AS number features for the specified peer or peer group.
undo peer { group-name | ipv6-address [ prefix-length ] } capability-advertise conventional
By default, the BGP route refresh, multi-protocol extension, and 4-byte AS number features are enabled.
4. Execute the quit command twice to return to user view.
quit
5. Perform manual soft-reset. Choose one option as needed:
¡ Perform manual soft-reset on IPv6 sessions in BGP IPv6 address family.
refresh bgp [ instance instance-name ] { ipv6-address [ prefix-length ] | all | external | group group-name | internal } { export | import } ipv6 [ unicast ]
¡ Perform manual soft-reset on IPv4 sessions in BGP IPv6 address family.
refresh bgp [ instance instance-name ] { ipv4-address [ mask-length ] | all | external | group group-name | internal } { export | import } ipv6 [ unicast ]
Configuring BGP load balancing
About this task
Perform this task to specify the maximum number of BGP ECMP routes for load balancing.
Procedure (IPv4 unicast address family)
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. (Optional.) Enable BGP to ignore IGP metrics during optimal route selection.
bestroute igp-metric-ignore
By default, BGP compares IGP metrics during optimal route selection, and selects the route with the smallest IGP metric as the optimal route.
BGP cannot use routes with different IGP metrics to implement load balancing. To resolve this issue, you can use this command.
4. Return to system view.
¡ In BGP instance view:
quit
¡ In BGP-VPN instance view:
quit
quit
5. Enter BGP instance view.
bgp as-number [ instance instance-name ]
6. Enter BGP IPv4 unicast address family view.
address-family ipv4 [ unicast ]
7. Specify the maximum number of BGP ECMP routes for load balancing.
balance [ ebgp | eibgp | ibgp ] number
By default, load balancing is disabled.
8. (Optional.) Enable BGP to ignore the AS_PATH attribute when it implements load balancing.
balance as-path-neglect
By default, BGP does not ignore the AS_PATH attribute when it implements load balancing.
9. (Optional.) Enable BGP to perform load balancing for routes that have different AS_PATH attributes of the same length.
balance as-path-relax [ ebgp | ibgp ]
By default, BGP cannot perform load balancing for routes that have different AS_PATH attributes of the same length.
Procedure (IPv6 unicast address family)
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. (Optional.) Enable BGP to ignore IGP metrics during optimal route selection.
bestroute igp-metric-ignore
By default, BGP compares IGP metrics during optimal route selection, and selects the route with the smallest IGP metric as the optimal route.
BGP cannot use routes with different IGP metrics to implement load balancing. To resolve this issue, you can use this command.
4. Return to system view.
¡ In BGP instance view:
quit
¡ In BGP-VPN instance view:
quit
quit
5. Enter BGP instance view.
bgp as-number [ instance instance-name ]
6. Enter BGP IPv6 unicast address family view.
address-family ipv6 [ unicast ]
7. Specify the maximum number of BGP ECMP routes for load balancing.
balance [ ebgp | eibgp | ibgp ] number
By default, load balancing is disabled.
8. (Optional.) Enable BGP to ignore the AS_PATH attribute when it implements load balancing.
balance as-path-neglect
By default, BGP does not ignore the AS_PATH attribute when it implements load balancing.
9. (Optional.) Enable BGP to perform load balancing for routes that have different AS_PATH attributes of the same length.
balance as-path-relax [ ebgp | ibgp ]
By default, BGP cannot perform load balancing for routes that have different AS_PATH attributes of the same length.
Configuring the BGP Additional Paths feature
About this task
By default, BGP advertises only one optimal route. When the optimal route fails, traffic forwarding will be interrupted until route convergence completes.
The BGP Additional Paths (Add-Path) feature enables BGP to advertise multiple routes with the same prefix and different next hops to a peer or peer group. When the optimal route fails, the suboptimal route becomes the optimal route, which shortens the traffic interruption time.
You can enable the BGP additional path sending, receiving, or both sending and receiving capabilities on a BGP peer. For two BGP peers to successfully negotiate the Additional Paths capabilities, make sure one end has the sending capability and the other end has the receiving capability.
Procedure (IPv4 unicast address family)
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Enter BGP IPv4 unicast address family view.
address-family ipv4 [ unicast ]
4. Configure the BGP Additional Paths capabilities.
peer { group-name | ipv4-address [ mask-length ] | ipv6-address [ prefix-length ] } additional-paths { receive | send } *
By default, no BGP Additional Paths capabilities are configured.
5. Set the maximum number of Add-Path optimal routes that can be advertised to a peer or peer group.
peer { group-name | ipv4-address [ mask-length ] | ipv6-address [ prefix-length ] } advertise additional-paths best number
By default, a maximum of one Add-Path optimal route can be advertised to a peer or peer group.
6. Set the maximum number of Add-Path optimal routes that can be advertised to all peers.
additional-paths select-best best-number
By default, a maximum of one Add-Path optimal route can be advertised to all peers.
Procedure (IPv6 unicast address family)
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Enter BGP IPv6 unicast address family view.
address-family ipv6 [ unicast ]
4. Configure the BGP Additional Paths capabilities.
peer { group-name | ipv4-address [ mask-length ] | ipv6-address [ prefix-length ] } additional-paths { receive | send } *
By default, no BGP Additional Paths capabilities are configured.
5. Set the maximum number of Add-Path optimal routes that can be advertised to a peer or peer group.
peer { group-name | ipv4-address [ mask-length ] | ipv6-address [ prefix-length ] } advertise additional-paths best number
By default, a maximum of one Add-Path optimal route can be advertised to a peer or peer group.
6. Set the maximum number of Add-Path optimal routes that can be advertised to all peers.
additional-paths select-best best-number
By default, a maximum of one Add-Path optimal route can be advertised to all peers.
Configuring BGP optimal route selection delay
About this task
Typically BGP optimal route selection is triggered in real time by the events such as attribute change, configuration change, and route recursion. To avoid packet loss upon switchover between redundant links, you can perform this task to delay optimal route selection.
As shown in Figure 1, BGP runs on all devices in the network. Device A and Device D uses the primary path for communication. When the primary path fails, Device A and Device D switch to the backup path for communication and then back to the primary path after the primary path recovers. In such case, traffic loss might occur if Device A forwards packets through Device B before Device B completes route convergence. You can configure optimal route selection delay on Device A to resolve the issue.

Restrictions and guidelines
Follow these restrictions and guidelines when you configure this feature:
· The optimal route selection delay setting applies only when multiple effective routes with the same prefix exist after a route change occurs.
· For routes being delayed for optimal route selection, modifying the optimal route selection delay timer has the following effects:
¡ If you modify the delay timer to a non-zero value, the routes are not affected, and they still use the original delay timer.
¡ If you execute the undo form of the route-select delay command or modify the delay timer to 0, the device performs optimal route selection immediately.
· The optimal route selection delay configuration does not apply to the following conditions:
¡ A route change is caused by execution of a command or by route withdrawal.
¡ After a route change occurs, only one route exists for a specific destination network.
¡ An active/standby process switchover occurs.
¡ A route change occurs among equal-cost routes.
¡ Only the optimal and suboptimal routes exist when FRR is configured.
¡ Optimal route selection is triggered by a redistributed route.
¡ The next hop of the optimal route changes and a route with the same prefix is waiting for the delay timer to expire.
Procedure (IPv4 unicast address family)
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Enter BGP IPv4 unicast address family view.
address-family ipv4 [ unicast ]
4. Set the optimal route selection delay timer.
route-select delay delay-value
By default, the optimal route selection delay timer is 0 seconds, which means optimal route selection is not delayed.
Procedure (IPv6 unicast address family)
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Enter BGP IPv6 unicast address family view.
address-family ipv6 [ unicast ]
4. Set the optimal route selection delay timer.
route-select delay delay-value
By default, the optimal route selection delay timer is 0 seconds, which means optimal route selection is not delayed.
Setting the delay time for responding to recursive next hop changes
About this task
Next hop changes include the following types:
· Critical next hop changes—Changes that cause route unreachability and service interruption. For example, a BGP route cannot find a recursive next hop (a physical interface) because of network failures.
· Noncritical next hop changes—A recursive or related route changes but the change does not cause route unreachability or service interruption. For example, the recursive next hop (a physical interface) of a BGP route changes but traffic forwarding is not affected.
When recursive or related routes change frequently, configure this feature to reduce unnecessary path selection and update messages and prevent traffic loss.
Restrictions and guidelines
To avoid traffic loss, do not configure this feature if only one route is available to a specific destination.
Set an appropriate delay time based on your network condition. A short delay time cannot reduce unnecessary path selection or update messages, and a long delay time might cause traffic loss.
Procedure (IPv4 unicast address family)
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Enter BGP IPv4 unicast address family view.
address-family ipv4 [ unicast ]
4. Set the delay time for responding to recursive next hop changes.
nexthop recursive-lookup [ non-critical-event ] delay [ delay-value ]
By default, BGP responds to recursive next hop changes immediately.
Procedure (IPv6 unicast address family)
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Enter BGP IPv6 unicast address family view.
address-family ipv6 [ unicast ]
4. Set the delay time for responding to recursive next hop changes.
nexthop recursive-lookup [ non-critical-event ] delay [ delay-value ]
By default, BGP responds to recursive next hop changes immediately.
Enabling routing policy-based nexthop recursion
About this task
When BGP performs nexthop recursion for a route without any constraints, the route might be iterated to an incorrect traffic forwarding path. To resolve this issue, perform this task to enable routing policy-based nexthop recursion. BGP can then iterate routes to the desired forwarding paths under the constraints of the specified routing policy.
With this task performed, a BGP route can take effect only when some of its nexthop recursion results can match a permit node of the specified routing policy. If the recursion results of a route are all filtered out by the specified routing policy, the route is considered unreachable and cannot take effect.
To disable route recursion policy control for the routes received from a peer or peer group, use the peer nexthop-recursive-policy disable command. The nexthop recursive-lookup route-policy command and the protocol nexthop recursive-lookup command then does not take effect on the peer.
Restrictions and guidelines
· The nexthop recursive-lookup route-policy command does not take effect on the routes learned from directly-connected EBGP peers.
· When you configure the nexthop recursive-lookup route-policy command and the protocol nexthop recursive-lookup command, follow these restrictions and guidelines:
¡ If the following conditions exist, only the nexthop recursive-lookup route-policy command takes effect on the routes in a BGP address family:
- You configure the nexthop recursive-lookup route-policy command in the view of the BGP address family.
- You configure the protocol nexthop recursive-lookup command in RIB IPv4 or IPv6 address family view.
¡ If the following conditions exist, BGP performs nexthop recursion for the routes in a BGP address family according to the configuration of the protocol nexthop recursive-lookup command in RIB IPv4 or IPv6 address family view:
- You do not configure the nexthop recursive-lookup route-policy command in the view of the BGP address family.
- You configure the protocol nexthop recursive-lookup command in RIB IPv4 or IPv6 address family view.
For more information about the protocol nexthop recursive-lookup command, see IP routing basics commands in Layer 3—IP Routing Command Reference.
Configuration tasks at a glance
· Enabling routing policy-based nexthop recursion (IPv4 unicast address family)
· Enabling routing policy-based nexthop recursion (IPv6 unicast address family)
· (Optional.) Disabling route recursion policy control for routes received from a peer or peer group
Enabling routing policy-based nexthop recursion (IPv4 unicast address family)
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Enter BGP IPv4 unicast address family view.
address-family ipv4 [ unicast ]
4. Enable routing policy-based nexthop recursion.
nexthop recursive-lookup route-policy route-policy-name
By default, BGP does not perform routing policy-based nexthop recursion for routes.
|
|
CAUTION: Before executing this command, make sure that BGP routes can be iterated to the desired paths under the constraints of the specified routing policy. If the recursion results of a BGP route are all filtered out by the specified routing policy, BGP considers the route unreachable. |
Enabling routing policy-based nexthop recursion (IPv6 unicast address family)
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Enter BGP IPv6 unicast address family view.
address-family ipv6 [ unicast ]
4. Enable routing policy-based nexthop recursion.
nexthop recursive-lookup route-policy route-policy-name
By default, BGP does not perform routing policy-based nexthop recursion for routes.
|
|
CAUTION: Before executing this command, make sure that BGP routes can be iterated to the desired paths under the constraints of the specified routing policy. If the recursion results of a BGP route are all filtered out by the specified routing policy, BGP considers the route unreachable. |
(Optional.) Disabling route recursion policy control for routes received from a peer or peer group
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Disable route recursion policy control for routes received from the specified peer or peer group.
peer { group-name | ip-address [ mask-length ] | ipv6-address [ prefix-length ] } nexthop-recursive-policy disable
By default, the route recursion policy applies to routes received from the peer or peer group.
After you configure this command for a peer or peer group, the following commands then does not take effect on the peer or peer group:
¡ nexthop recursive-lookup route-policy
¡ protocol nexthop recursive-lookup
Configuring peer flap dampening
About this task
Perform this task to dampen a BGP peer when the peer state frequently changes between up and down. BGP increases the idle time of the peer each time the peer comes up until the maximum idle time is reached. To exit the dampened state, the peer must remain in Established state for a time period longer than the minimum established time. After the peer exits the dampened state, BGP resets the idle time of the peer when the peer comes up again.
Set a maximum idle time and a minimum established time based on your network condition.
Procedure
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Configure flap dampening for a peer or peer group.
peer { group-name | ipv4-address | ipv6-address } flap-dampen [ max-idle-time max-time | min-established-time min-time ]*
By default, flap dampening is disabled for all peers and peer groups.
Protecting an EBGP peer when memory usage reaches level 2 threshold
About this task
Memory usage includes the following threshold levels: normal, level 1, level 2, and level 3. When the level 2 threshold is reached, BGP periodically tears down an EBGP session to release memory resources until the memory usage falls below the level 2 threshold. You can configure this feature to avoid tearing down the EBGP session to an EBGP peer when the memory usage reaches the level 2 threshold.
For more information about memory usage thresholds, see hardware resource management configuration in System Management Configuration Guide.
Procedure (IPv4 peers)
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Configure BGP to protect an EBGP peer or peer group when the memory usage reaches the level 2 threshold.
peer { group-name | ipv4-address [ mask-length ] } low-memory-exempt
By default, BGP periodically tears down an EBGP session to release memory resources when level 2 threshold is reached.
Procedure (IPv6 peers)
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Configure BGP to protect an EBGP peer or peer group when the memory usage reaches level 2 threshold.
peer { group-name | ipv6-address [ prefix-length ] } low-memory-exempt
By default, BGP tears down an EBGP session to release memory resources periodically when level 2 threshold is reached.
Setting a DSCP value for outgoing BGP packets
About this task
The DSCP value of an IP packet specifies the priority level of the packet and affects the transmission priority of the packet.
Procedure
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Set a DSCP value for outgoing BGP packets.
peer { group-name | ipv4-address [ mask-length ] | ipv6-address [ prefix-length ] } dscp dscp-value
By default, the DSCP value for outgoing BGP packets is 48.
Flushing the suboptimal BGP route to the RIB
About this task
This feature flushes the suboptimal BGP route to the RIB when the following conditions are met:
· The optimal route is generated by the network command or is redistributed by the import-route command.
· The suboptimal route is received from a BGP peer.
After the suboptimal route is flushed to the RIB on a network, BGP immediately switches traffic to the suboptimal route when the optimal route fails.
For example, the device has a static route to the subnet 1.1.1.0/24 that has a higher priority than a BGP route. BGP redistributes the static route and receives a route to 1.1.1.0/24 from a peer. After the flush suboptimal-route command is executed, BGP flushes the received BGP route to the RIB as the suboptimal route. When the static route fails, BGP immediately switches traffic to the suboptimal route if inter-protocol FRR is enabled. For more information about inter-protocol FRR, see "Configuring basic IP routing."
Procedure
1. Enter system view.
system-view
2. Enter BGP view.
bgp as-number [ instance instance-name ]
3. Flush the suboptimal BGP route to the RIB.
flush suboptimal-route
By default, BGP is disabled from flushing the suboptimal BGP route to the RIB, and only the optimal route is flushed to the RIB.
Resetting BGP sessions
About this task
A reset operation terminates and re-establishes BGP sessions in order to validate configuration changes and update routing information.
Restrictions and guidelines
A reset operation tears down BGP sessions for a short period of time.
Procedure
Perform reset tasks in user view.
· Resets BGP sessions for the IPv4 unicast address family.
reset bgp [ instance instance-name ] { as-number | ipv4-address [ mask-length ] | all | external | group group-name | internal } ipv4 [ unicast ]
reset bgp [ instance instance-name ] ipv6-address [ prefix-length ] ipv4 [ unicast ]
· Resets BGP sessions for the IPv6 unicast address family.
reset bgp [ instance instance-name ] { as-number | ipv6-address [ prefix-length ] | all | external | group group-name | internal } ipv6 [ unicast ]
reset bgp ipv4-address [ mask-length ] ipv6 [ unicast ]
· Resets all BGP sessions.
reset bgp [ instance instance-name ] all
For more information about the reset commands, see Basic BGP commands in Layer 3—IP Routing Command Reference.
BGP network tuning and optimization configuration examples
Example: Configuring BGP load balancing
Network configuration
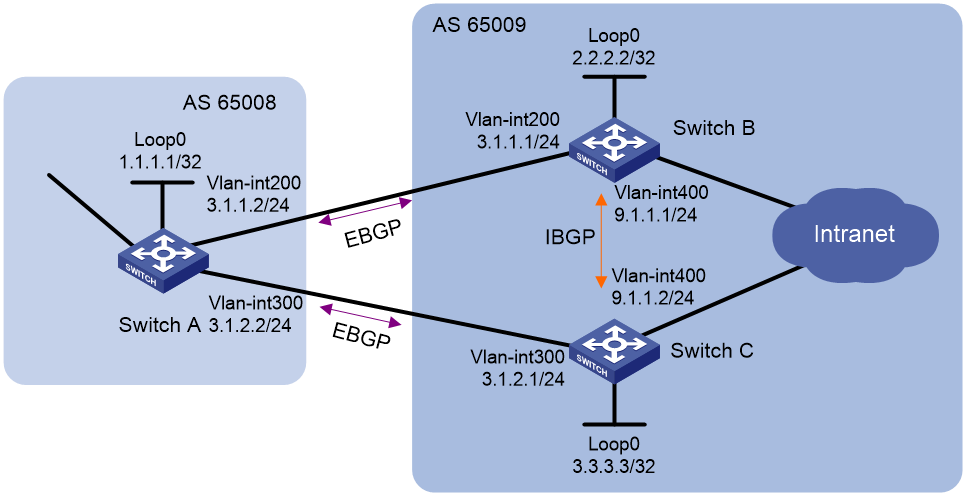
As shown in Figure 2, run EBGP between Switch A and Switch B, and between Switch A and Switch C. Run IBGP between Switch B and Switch C.
Procedure
1. Configure IP addresses for interfaces. (Details not shown.)
2. Configure BGP connections:
¡ On Switch A, establish EBGP connections with Switch B and Switch C. Configure BGP to advertise network 8.1.1.0/24 to Switch B and Switch C, so that Switch B and Switch C can access the internal network connected to Switch A. Configure load balancing over the two EBGP links on Switch A.
¡ On Switch B, establish an EBGP connection with Switch A and an IBGP connection with Switch C. Configure BGP to advertise network 9.1.1.0/24 to Switch A, so that Switch A can access the intranet through Switch B. Configure a static route to interface loopback 0 on Switch C (or use a routing protocol like OSPF) to establish the IBGP connection.
¡ On Switch C, establish an EBGP connection with Switch A and an IBGP connection with Switch B. Configure BGP to advertise network 9.1.1.0/24 to Switch A, so that Switch A can access the intranet through Switch C. Configure a static route to interface loopback 0 on Switch B (or use another protocol like OSPF) to establish the IBGP connection.
# Configure Switch A.
<SwitchA> system-view
[SwitchA] bgp 65008
[SwitchA-bgp-default] router-id 1.1.1.1
[SwitchA-bgp-default] peer 3.1.1.1 as-number 65009
[SwitchA-bgp-default] peer 3.1.2.1 as-number 65009
[SwitchA-bgp-default] address-family ipv4 unicast
[SwitchA-bgp-default-ipv4] peer 3.1.1.1 enable
[SwitchA-bgp-default-ipv4] peer 3.1.2.1 enable
[SwitchA-bgp-default-ipv4] network 8.1.1.0 24
[SwitchA-bgp-default-ipv4] quit
[SwitchA-bgp-default] quit
# Configure Switch B.
<SwitchB> system-view
[SwitchB] bgp 65009
[SwitchB-bgp-default] router-id 2.2.2.2
[SwitchB-bgp-default] peer 3.1.1.2 as-number 65008
[SwitchB-bgp-default] peer 3.3.3.3 as-number 65009
[SwitchB-bgp-default] peer 3.3.3.3 connect-interface loopback 0
[SwitchB-bgp-default] address-family ipv4 unicast
[SwitchB-bgp-default-ipv4] peer 3.1.1.2 enable
[SwitchB-bgp-default-ipv4] peer 3.3.3.3 enable
[SwitchB-bgp-default-ipv4] network 9.1.1.0 24
[SwitchB-bgp-default-ipv4] quit
[SwitchB-bgp-default] quit
[SwitchB] ip route-static 3.3.3.3 32 9.1.1.2
# Configure Switch C.
<SwitchC> system-view
[SwitchC] bgp 65009
[SwitchC-bgp-default] router-id 3.3.3.3
[SwitchC-bgp-default] peer 3.1.2.2 as-number 65008
[SwitchC-bgp-default] peer 2.2.2.2 as-number 65009
[SwitchC-bgp-default] peer 2.2.2.2 connect-interface loopback 0
[SwitchC-bgp-default] address-family ipv4 unicast
[SwitchC-bgp-default-ipv4] peer 3.1.2.2 enable
[SwitchC-bgp-default-ipv4] peer 2.2.2.2 enable
[SwitchC-bgp-default-ipv4] network 9.1.1.0 24
[SwitchC-bgp-default-ipv4] quit
[SwitchC-bgp-default] quit
[SwitchC] ip route-static 2.2.2.2 32 9.1.1.1
# Display the BGP routing table on Switch A.
[SwitchA] display bgp routing-table ipv4
Total number of routes: 3
BGP local router ID is 1.1.1.1
Status codes: * - valid, > - best, d - dampened, h - history,
s - suppressed, S - stale, i - internal, e - external
a – additional-path
Origin: i - IGP, e - EGP, ? - incomplete
Network NextHop MED LocPrf PrefVal Path/Ogn
* > 8.1.1.0/24 8.1.1.1 0 32768 i
* >e 9.1.1.0/24 3.1.1.1 0 0 65009i
* e 3.1.2.1 0 0 65009i
¡ The output shows two valid routes to destination 9.1.1.0/24. The route with next hop 3.1.1.1 is marked with a greater-than sign (>), indicating that it is the optimal route (because the ID of Switch B is smaller). The route with next hop 3.1.2.1 is marked with an asterisk (*), indicating that it is a valid route, but not the optimal route.
¡ By using the display ip routing-table command, you can find only one route to 9.1.1.0/24 with next hop 3.1.1.1 and output interface VLAN-interface 200.
3. Configure loading balancing:
Because Switch A has two routes to reach AS 65009, configuring load balancing over the two BGP routes on Switch A can improve link usage.
# Configure Switch A.
[SwitchA] bgp 65008
[SwitchA-bgp-default] address-family ipv4 unicast
[SwitchA-bgp-default-ipv4] balance 2
[SwitchA-bgp-default-ipv4] quit
[SwitchA-bgp-default] quit
Verifying the configuration
# Display the BGP routing table on Switch A.
[SwitchA] display bgp routing-table ipv4
Total number of routes: 3
BGP local router ID is 1.1.1.1
Status codes: * - valid, > - best, d - dampened, h - history,
s - suppressed, S - stale, i - internal, e - external
a – additional-path
Origin: i - IGP, e - EGP, ? - incomplete
Network NextHop MED LocPrf PrefVal Path/Ogn
* > 8.1.1.0/24 8.1.1.1 0 32768 i
* >e 9.1.1.0/24 3.1.1.1 0 0 65009i
* >e 3.1.2.1 0 0 65009i
· The route 9.1.1.0/24 has two next hops, 3.1.1.1 and 3.1.2.1, both of which are marked with a greater-than sign (>), indicating that they are the optimal routes.
· By using the display ip routing-table command, you can find two routes to 9.1.1.0/24. One has next hop 3.1.1.1 and output interface VLAN-interface 200, and the other has next hop 3.1.2.1 and output interface VLAN-interface 300.
Example: Configuring the BGP Additional Paths feature
Network configuration
As shown in Figure 3, all switches run BGP. EBGP runs between Switch A and Switch B, and between Switch A and Switch C. IBGP runs between Switch B and Switch D, between Switch C and Switch D, and between Switch D and Switch E. Switch D is a route reflector and Switch E is its client.
Configure the BGP Additional Paths feature to enable Switch E to learn routes with the same prefix and different next hops from Switch B and Switch C.
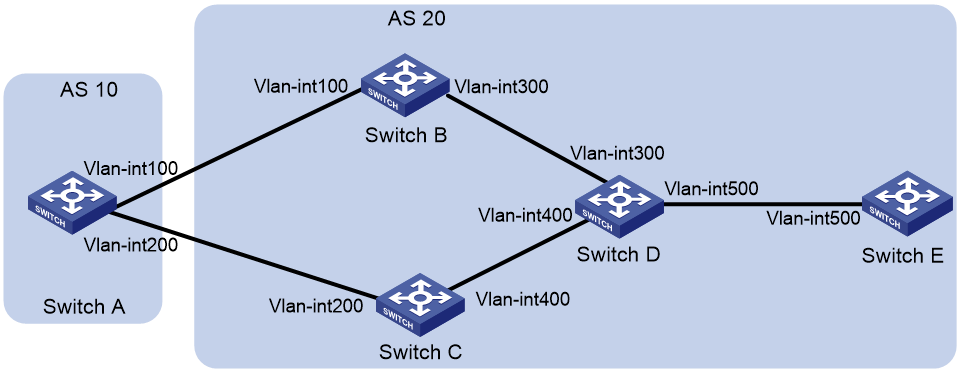
Table 1 Interface and IP address assignment
|
Device |
Interface |
IP address |
Device |
Interface |
IP address |
|
Switch A |
Vlan-int100 |
10.1.1.1/24 |
Switch D |
Vlan-int300 |
30.1.1.1/24 |
|
|
Vlan-int200 |
20.1.1.1/24 |
|
Vlan-int400 |
40.1.1.1/24 |
|
Switch B |
Vlan-int100 |
10.1.1.2/24 |
|
Vlan-int500 |
50.1.1.1/24 |
|
|
Vlan-int300 |
30.1.1.2/24 |
Switch E |
Vlan-int500 |
50.1.1.2/24 |
|
Switch C |
Vlan-int200 |
20.1.1.2/24 |
|
|
|
|
|
Vlan-int400 |
40.1.1.2/24 |
|
|
|
Procedure
1. Configure IP addresses for interfaces. (Details not shown.)
2. Configure BGP connections:
# Configure Switch A.
<SwitchA> system-view
[SwitchA] bgp 10
[SwitchA-bgp-default] peer 10.1.1.2 as-number 20
[SwitchA-bgp-default] peer 20.1.1.2 as-number 20
[SwitchA-bgp-default] address-family ipv4 unicast
[SwitchA-bgp-default-ipv4] peer 10.1.1.2 enable
[SwitchA-bgp-default-ipv4] peer 20.1.1.2 enable
# Configure Switch B.
<SwitchB> system-view
[SwitchB] bgp 20
[SwitchB-bgp-default] peer 10.1.1.1 as-number 10
[SwitchB-bgp-default] peer 30.1.1.1 as-number 20
[SwitchB-bgp-default] address-family ipv4 unicast
[SwitchB-bgp-default-ipv4] peer 10.1.1.1 enable
[SwitchB-bgp-default-ipv4] peer 30.1.1.1 enable
# Configure Switch C.
<SwitchC> system-view
[SwitchC] bgp 20
[SwitchC-bgp-default] peer 20.1.1.1 as-number 10
[SwitchC-bgp-default] peer 40.1.1.1 as-number 20
[SwitchC-bgp-default] address-family ipv4 unicast
[SwitchC-bgp-default-ipv4] peer 20.1.1.1 enable
[SwitchC-bgp-default-ipv4] peer 40.1.1.1 enable
# Configure Switch D.
<SwitchD> system-view
[SwitchD] bgp 20
[SwitchD-bgp-default] peer 30.1.1.2 as-number 20
[SwitchD-bgp-default] peer 40.1.1.2 as-number 20
[SwitchD-bgp-default] peer 50.1.1.2 as-number 20
[SwitchD-bgp-default] address-family ipv4 unicast
[SwitchD-bgp-default-ipv4] peer 30.1.1.2 enable
[SwitchD-bgp-default-ipv4] peer 40.1.1.2 enable
[SwitchD-bgp-default-ipv4] peer 50.1.1.2 enable
# Configure Switch E.
<SwitchE> system-view
[SwitchE] bgp 20
[SwitchE-bgp-default] peer 50.1.1.1 as-number 20
[SwitchE-bgp-default] address-family ipv4 unicast
[SwitchE-bgp-default-ipv4] peer 50.1.1.1 enable
3. Configure Switch A to advertise network 10.1.1.0/24.
[SwitchA-bgp-default-ipv4] network 10.1.1.0 24
4. Set the local switch as the next hop for routes sent to a peer:
# Configure Switch B.
[SwitchB-bgp-default-ipv4] peer 30.1.1.1 next-hop-local
# Configure Switch C.
[SwitchC-bgp-default-ipv4] peer 40.1.1.1 next-hop-local
5. Configure Switch D as a route reflector.
[SwitchD-bgp-default-ipv4] peer 50.1.1.2 reflect-client
6. Configure the Additional Paths feature:
# Enable the additional path sending capability on Switch D.
[SwitchD-bgp-default-ipv4] peer 50.1.1.2 additional-paths send
# Set the maximum number to 2 for Add-Path optimal routes that can be advertised.
[SwitchD-bgp-default-ipv4] additional-paths select-best 2
# Set the maximum number to 2 for Add-Path optimal routes that can be advertised to peer 50.1.1.2.
[SwitchD-bgp-default-ipv4] peer 50.1.1.2 advertise additional-paths best 2
# Enable the additional path receiving capability on Switch E.
[SwitchE-bgp-default-ipv4] peer 50.1.1.1 additional-paths receive
Verifying the configuration
# Display BGP routing information on Switch E.
[Switch E] display bgp routing-table ipv4
Total number of routes: 2
BGP local Switch ID is 50.1.1.2
Status codes: * - valid, > - best, d - dampened, h - history
s - suppressed, S - stale, i - internal, e - external
a - additional-path
Origin: i - IGP, e - EGP, ? - incomplete
Network NextHop MED LocPrf PrefVal Path/Ogn
i 10.1.1.0/24 30.1.1.2 0 100 0 10i
i 40.1.1.2 0 100 0 10i
The output shows that Switch D has learned two routes with the same prefix and different next hops.
Configuring BGP security features
BGP security feature configuration tasks at a glance
To configure BGP security features, perform the following tasks:
· Enabling MD5 authentication for BGP peers
Enabling MD5 authentication for BGP peers
About this task
MD5 authentication provides the following benefits:
· Peer authentication ensures that only BGP peers that have the same password can establish TCP connections.
· Integrity check ensures that BGP packets exchanged between peers are intact.
Procedure (IPv4 peers)
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Enable MD5 authentication for a BGP peer group or peer.
peer { group-name | ipv4-address [ mask-length ] } password { cipher | simple } password
By default, MD5 authentication is disabled.
Procedure (IPv6 peers)
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Enable MD5 authentication for a BGP peer group or peer.
peer { group-name | ipv6-address [ prefix-length ] } password { cipher | simple } password
By default, MD5 authentication is disabled.
Improving BGP network reliability
BGP network reliability improvement tasks at a glance
To improve the BGP network reliability, perform the following tasks:
· Configuring BGP maintenance features
Configuring BGP GR
About this task
Graceful Restart (GR) ensures forwarding continuous when a routing protocol restarts or an active/standby switchover occurs. Two routers are required to complete a GR process. The following are router roles in a GR process:
· GR restarter—Performs GR upon a BGP restart or active/standby switchover.
· GR helper—Helps the GR restarter to complete the GR process.
A device can act as a GR restarter and GR helper at the same time.
BGP GR works as follows:
1. The BGP GR restarter and helper exchange OPEN messages for GR capability negotiation. If both parties have the GR capability, they establish a GR-capable session. The GR restarter sends the GR timer set by the graceful-restart timer restart command to the GR helper in an OPEN message.
2. When an active/standby switchover occurs or BGP restarts, the GR restarter does not remove existing BGP routes from Routing Information Base (RIB) and Forwarding Information Base (FIB). It still uses these routes for packet forwarding, and it starts the RIB purge timer (set by the graceful-restart timer purge-time command). The GR helper marks all routes learned from the GR restarter as stale instead of deleting them. It continues to use these routes for packet forwarding. During the GR process, packet forwarding is not interrupted.
3. After the active/standby switchover or BGP restart completes, the GR restarter re-establishes a BGP session to the GR helper. If the BGP session fails to be established after both the GR timer and the extra timer to wait expire, the GR helper removes the stale routes. To set the extra timer to wait after the restart timer expires, execute the peer graceful-restart timer restart extra command.
4. If the BGP session is established, routing information is exchanged for the GR restarter to retrieve route entries and for the GR helper to recover stale routes.
5. Both the GR restarter and the GR helper start the End-Of-RIB marker waiting timer.
The End-Of-RIB marker waiting time is set by the graceful-restart timer wait-for-rib command. If routing information exchange is not completed within the time, the GR restarter does not receive new routes. The GR restarter updates the RIB with the BGP routes already learned, and removes the aged routes from the RIB. The GR helper removes the stale routes.
6. The GR restarter quits the GR process if routing information exchange is not completed within the RIB purge timer. It updates the RIB with the BGP routes already learned, and removes the aged routes.
When the TCP connection goes down, the hold timer expires, or the address families supporting route exchange change, BGP tears down and then re-establishes the peer sessions, which will cause traffic interruption. To avoid traffic interruption in these cases, enable BGP to reset peer sessions gracefully.
Restrictions and guidelines
Follow these guidelines when you configure BGP GR:
· The End-Of-RIB indicates the end of route updates.
· The maximum time to wait for the End-of-RIB marker configured on the local end is not advertised to the peer. It controls the time for the local end to receive updates from the peer. Set a large value for the maximum time to wait for the End-of-RIB marker when a large number of routes need to be exchanged.
· As a best practice, perform the BGP GR configuration on both the GR restarter and GR helper.
Procedure
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Enable GR capability for BGP.
graceful-restart
By default, GR capability is disabled for BGP.
4. Configure the GR timer.
graceful-restart timer restart timer
The default setting is 150 seconds.
The time that a peer waits to re-establish a session must be less than the hold time.
5. (Optional.) Set the extra time to wait after the restart timer expires.
peer { group-name | ipv4-address [ mask-length ] | ipv6-address [ prefix-length ] } graceful-restart timer restart extra { time | no-limit }
By default, the extra time to wait after the restart timer expires is 0 seconds.
6. Configure the maximum time to wait for the End-of-RIB marker.
graceful-restart timer wait-for-rib timer
The default setting is 600 seconds.
7. Configure the RIB purge timer.
graceful-restart timer purge-time timer
The default setting is 480 seconds.
8. (Optional.) Enable BGP to reset peer sessions gracefully.
graceful-restart peer-reset [ all ]
By default, BGP does not reset peer sessions gracefully.
9. (Optional.) Configure the time that BGP must wait for other protocols to complete GR after BGP completes GR.
bgp update-delay wait-other-protocol seconds
By default, after BGP completes GR, it must wait a maximum of 300 seconds for other protocols to complete GR.
Configuring BFD for BGP
About this task
BGP maintains neighbor relationships based on the keepalive timer and hold timer in seconds. It requires that the hold time must be at least three times the keepalive interval. This mechanism slows down link failure detection. Once a failure occurs on a high-speed link, a large quantity of packets will be dropped before routing convergence completes. BFD for BGP can solve this problem by fast detecting link failures to reduce convergence time.
Before you enable BFD for a BGP peer or peer group, you must establish a BGP session between the local router and the peer or peer group.
For more information about BFD, see High Availability Configuration Guide.
Restrictions and guidelines
Follow these restrictions and guidelines when you configure echo packet mode BFD:
· Echo packet mode BFD is applicable only to directly connected BGP peers.
· Echo packet mode BFD is not applicable to BGP peers established through loopback interfaces.
· For successful BFD session establishment, make sure a source address has been specified for echo packets by using the bfd echo-source-ip or bfd echo-source-ipv6 command.
To detect the link to a BGP peer established through link-local addresses, you must configure single-hop BFD in control packet mode.
To establish a control packet mode BFD session to a BGP peer, you must configure the same BFD detection mode (multi-hop or single-hop) on the local device and the BGP peer.
If you have enabled GR, use BFD with caution because BFD might detect a failure before the system performs GR, which will result in GR failure. If you have enabled both BFD and GR for BGP, do not disable BFD during a GR process to avoid GR failure.
When you configure BFD parameters for a BGP peer or peer group, follow these restrictions and guidelines:
· When you add a peer to a peer group, the peer will inherit the BFD settings of the peer group.
· When you configure BFD parameters for a peer group, the configuration takes effect on all peers in the peer group.
· If you configure a BFD parameter multiple times for a peer or peer group, the most recent configuration takes effect.
For a BGP peer, the most recent configuration of a BFD parameter takes effect regardless of the configuration source.
Procedure (IPv4 peers)
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Enable BFD to detect the link to the specified BGP peer or peer group.
peer { group-name | ipv4-address [ mask-length ] } bfd [ echo | multi-hop | single-hop ]
By default, BFD is disabled.
4. (Optional.) Configure BFD parameters for the specified BGP peer or peer group.
peer { group-name | ipv4-address [ mask-length ] } bfd parameters { detect-multiplier detect-multiplier | min-receive-interval min-receive-interval | min-transmit-interval min-transmit-interval } *
By default, no BFD parameters are configured for a BGP peer or peer group.
Procedure (IPv6 peers)
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Enable BFD to detect the link to the specified IPv6 BGP peer or peer group.
peer { group-name | ipv6-address [ prefix-length ] } bfd [ echo | multi-hop | single-hop ]
By default, BFD is disabled.
4. (Optional.) Configure BFD parameters for the specified BGP peer or peer group.
peer { group-name | ipv6-address [ prefix-length ] } bfd parameters { detect-multiplier detect-multiplier | min-receive-interval min-receive-interval | min-transmit-interval min-transmit-interval } *
By default, no BFD parameters are configured for a BGP peer or peer group.
Configuring BGP FRR
About BGP FRR
When a link fails, the packets on the link are discarded, and a routing loop might occur until BGP completes routing convergence based on the new network topology.
You can enable BGP fast reroute (FRR) to resolve this issue.
Figure 4 Network diagram for BGP FRR
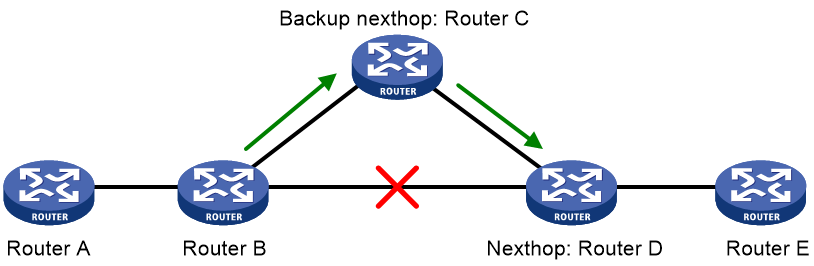
After you configure FRR on Router B as shown in Figure 4, BGP generates a backup next hop Router C for the primary route. BGP uses ARP or BFD echo packet mode in an IPv4 network or ND in an IPv6 network to detect the connectivity to Router D. When the link to Router D fails, BGP directs packets to the backup next hop. At the same time, BGP calculates a new optimal route, and forwards packets over the optimal route.
You can use the following methods to configure BGP FRR:
· Method 1—Execute the pic command in BGP address family view. BGP calculates a backup next hop for each BGP route in the address family if there are two or more unequal-cost routes that reach the destination.
· Method 2—Execute the fast-reroute route-policy command to use a routing policy in which a backup next hop is specified by using the command apply [ ipv6 ] fast-reroute backup-nexthop. The backup next hop calculated by BGP must be the same as the specified backup next hop. Otherwise, BGP does not generate a backup next hop for the primary route. You can also configure if-match clauses in the routing policy to identify the routes protected by FRR.
If both methods are configured, Method 2 takes precedence over Method 1.
Configuring BGP FRR by using a routing policy (IPv4 unicast address family)
1. Enter system view.
system-view
2. Configure the source address of echo packets.
bfd echo-source-ip ipv4-address
By default, no source address is specified for echo packets.
This step is required when BFD echo packet mode is used to detect the connectivity to the next hop of the primary route.
Specify a source IP address that does not belong to any local network.
For more information about this command, see BFD commands in High Availability Command Reference.
3. Create a routing policy and enter routing policy view.
route-policy route-policy-name permit node node-number
For more information about this command, see routing policy commands in Layer 3—IP Routing Command Reference.
4. Set the backup next hop for FRR.
apply fast-reroute backup-nexthop ipv4-address
By default, no backup next hop is set.
For more information about this command, see routing policy commands in Layer 3—IP Routing Command Reference.
5. Return to system view.
quit
6. Enter BGP instance view.
bgp as-number [ instance instance-name ]
7. Enter BGP IPv4 unicast address family view.
address-family ipv4 [ unicast ]
8. Apply a routing policy to FRR for the address family.
fast-reroute route-policy route-policy-name
By default, no routing policy is applied.
The apply fast-reroute backup-nexthop command and apply ipv6 fast-reroute backup-nexthop command can take effect in the applied routing policy. Other apply commands do not take effect.
Configuring BGP FRR by using a routing policy (IPv6 unicast address family)
1. Enter system view.
system-view
2. Create a routing policy and enter routing policy view.
route-policy route-policy-name permit node node-number
For more information about this command, see routing policy commands in Layer 3—IP Routing Command Reference.
3. Set the backup next hop for FRR.
apply ipv6 fast-reroute backup-nexthop ipv6-address
By default, no backup next hop is set.
For more information about this command, see routing policy commands in Layer 3—IP Routing Command Reference.
4. Return to system view.
quit
5. Enter BGP instance view.
bgp as-number [ instance instance-name ]
6. Enter BGP IPv6 unicast address family view.
address-family ipv6 [ unicast ]
7. Apply a routing policy to FRR for the address family.
fast-reroute route-policy route-policy-name
By default, no routing policy is applied.
The apply fast-reroute backup-nexthop and apply ipv6 fast-reroute backup-nexthop commands can take effect in the applied routing policy. Other apply commands do not take effect.
Configuring BGP FRR through PIC (IPv4 unicast address family)
Restrictions and guidelines
This feature might result in routing loops. Use it with caution.
Procedure
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Enter BGP IPv4 unicast address family view.
address-family ipv4 [ unicast ]
4. Enable BGP FRR through PIC.
pic
By default, BGP FRR is disabled.
Configuring BGP FRR through PIC (IPv6 unicast address family)
Restrictions and guidelines
This feature might result in routing loops. Use it with caution.
Procedure
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Enter BGP IPv6 unicast address family view.
address-family ipv6 [ unicast ]
4. Enable BGP FRR through PIC.
pic
By default, BGP FRR is disabled.
Configuring BFD-powered nexthop connectivity detection for BGP FRR
About this task
By default, BGP FRR uses ARP to detect next hop connectivity for the primary route. This method is not efficient at detecting the failure of the primary route. As a result, data loss might occur when the primary route fails, because the backup path might not take over to forward traffic in time. To resolve this issue, enable BFD-powered nexthop connectivity detection for BGP FRR. This feature enables BGP to create an IP FRR BFD session that detects next hop connectivity for the primary route. This can speed up primary and backup route switchover when the next hop of the primary route fails.
Restrictions and guidelines
This feature takes effect and creates an IP FRR BFD session only when the primary route has a backup next hop.
BGP does not support backup next hop calculation for the routes used for load balancing. This command cannot take effect when the primary route is an ECMP route. To resolve this issue, use the primary-path-detect bfd protocol-ecmp bgp command or the primary-path-detect bfd protocol-ecmp bgp4+ command. For more information about the two commands, see basic IP routing commands in Layer 3—IP Routing Command Reference.
BGP can establish a control-mode BFD session with a peer only after negotiation. To use control-mode BFD to detect the next hop of the primary link, perform one of the following tasks:
· Configure the primary-path-detect bfd command on the peer device in the primary link.
This task is applicable when both ends of the primary link are configured with FRR.
· Manually configure a static BFD session that uses the following settings on the peer device in the primary link:
¡ Source IP address: Destination IP address of the BFD session automatically created on the local device in the primary link.
¡ Destination IP address: Source IP address of the BFD session automatically created on the local device in the primary link.
¡ Remote ID: Local ID of the BFD session automatically created on the local device in the primary link.
When you configure echo-mode BFD for nexthop connectivity detection, you only need to configure this feature on the local router.
When another routing protocol (such as OSPF or IS-IS) uses BFD to detect next hop connectivity for the primary route, it also creates a BFD session. If the detected link is the same as the link attached to the next hop of the BGP primary route, BGP reuses the BFD session created by the protocol. In this situation, BGP will not create an additional BFD session.
Procedure
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. (Optional.) Enable BFD-powered nexthop connectivity detection for BGP FRR.
primary-path-detect bfd { ctrl | echo }
By default, BGP FRR uses ARP to detect nexthop connectivity for the primary route.
Configuring BGP maintenance features
About BGP isolation and BGP shutdown
For maintenance purposes, you can use either BGP isolation or BGP shutdown to remove the device from the network. The device will not be used for forwarding traffic from its peers after they reselect an optimal route. Both BGP isolation and BGP shutdown retain the device configuration to reduce maintenance cost.
After maintenance, you can disable BGP isolation or BGP shutdown to add the device back to the network.
Configuring BGP isolation
About this task
To maintain a BGP network device, you can use BGP isolation to remove the device from the network. This feature reduces configuration cost and impact on the network by retaining the device configuration during the maintenance. After maintenance, you can disable BGP isolation to add the device back to the network.
BGP isolation works as follows:
1. BGP withdraws all routes advertised by the device except for the directly-connected routes.
2. BGP keeps all routes learned from its peers.
3. Each peer of the device reselects an optimal route and updates the FIB table. During optimal route selection, the peers can still use the routes advertised by the device to forward traffic.
4. After an optimal route is selected and the FIB table is updated, the peers stop forwarding packets except for those destined for the device to the device. The device is fully isolated from the network and you can upgrade it.
5. After the maintenance, disable BGP isolation on the device to gracefully add it back to the network. After returning to the network, the device advertises and learns routes as follows:
¡ Advertises routes to its peers.
¡ Learns routes if BGP was reset during the isolation.
Restrictions and guidelines
To avoid isolation failure, do not use this feature when GR is enabled for the device.
Procedure
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Enable BGP isolation to gracefully remove the device from the network.
isolate enable
By default, BGP isolation is disabled.
4. Disable BGP isolation to gracefully add the device to the network.
undo isolate enable
Configuring BGP shutdown
About this task
For maintenance purposes, you can use this feature to temporarily disconnect BGP sessions from all peers and peer groups. After maintenance, you can disable this feature to restore these sessions.
Restrictions and guidelines
With this feature enabled, the device tears down all sessions and clears all routing information.
When you configure the shutdown process command together with the peer ignore or ignore all-peers command, follow these restrictions and guidelines:
· Once BGP shutdown is enabled by the shutdown process command, the device cannot establish BGP sessions with all peers and peer groups.
· To disable BGP session establishment with a peer or peer group if you have disabled BGP shutdown, perform one of the following tasks:
¡ Disable BGP session establishment with that peer or peer group by using the peer ignore command.
¡ Disable BGP session establishment with all peers and peer groups by using the ignore all-peers command.
For more information about disabling BGP session establishment, see "Disabling BGP session establishment."
Procedure
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Shut down BGP sessions to all peers and peer groups.
shutdown process
By default, BGP does not shut down sessions to any peers or peer groups.
4. Restore the BGP sessions to add the device back to the network.
undo shutdown process
IPv4 BGP network reliability improvement configuration examples
Example: Configuring BGP GR
Network configuration
As shown in Figure 5, all switches run BGP. EBGP runs between Switch A and Switch B. IBGP runs between Switch B and Switch C.
Enable GR capability for BGP so that the communication between Switch A and Switch C is not affected when an active/standby switchover occurs on Switch B.
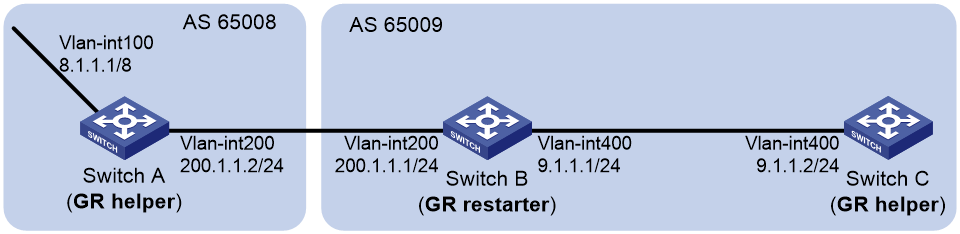
Procedure
1. Configure Switch A:
# Configure IP addresses for interfaces. (Details not shown.)
# Configure the EBGP connection.
<SwitchA> system-view
[SwitchA] bgp 65008
[SwitchA-bgp-default] router-id 1.1.1.1
[SwitchA-bgp-default] peer 200.1.1.1 as-number 65009
# Enable GR capability for BGP.
[SwitchA-bgp-default] graceful-restart
# Inject network 8.0.0.0/8 to the BGP routing table.
[SwitchA-bgp-default] address-family ipv4
[SwitchA-bgp-default-ipv4] network 8.0.0.0
# Enable Switch A to exchange IPv4 unicast routing information with Switch B.
[SwitchA-bgp-default-ipv4] peer 200.1.1.1 enable
2. Configure Switch B:
# Configure IP addresses for interfaces. (Details not shown.)
# Configure the EBGP connection.
<SwitchB> system-view
[SwitchB] bgp 65009
[SwitchB-bgp-default] router-id 2.2.2.2
[SwitchB-bgp-default] peer 200.1.1.2 as-number 65008
# Configure the IBGP connection.
[SwitchB-bgp-default] peer 9.1.1.2 as-number 65009
# Enable GR capability for BGP.
[SwitchB-bgp-default] graceful-restart
# Inject networks 200.1.1.0/24 and 9.1.1.0/24 to the BGP routing table.
[SwitchB-bgp-default] address-family ipv4
[SwitchB-bgp-default-ipv4] network 200.1.1.0 24
[SwitchB-bgp-default-ipv4] network 9.1.1.0 24
# Enable Switch B to exchange IPv4 unicast routing information with Switch A and Switch C.
[SwitchB-bgp-default-ipv4] peer 200.1.1.2 enable
[SwitchB-bgp-default-ipv4] peer 9.1.1.2 enable
3. Configure Switch C:
# Configure IP addresses for interfaces. (Details not shown.)
# Configure the IBGP connection.
<SwitchC> system-view
[SwitchC] bgp 65009
[SwitchC-bgp-default] router-id 3.3.3.3
[SwitchC-bgp-default] peer 9.1.1.1 as-number 65009
# Enable GR capability for BGP.
[SwitchC-bgp-default] graceful-restart
# Enable Switch C to exchange IPv4 unicast routing information with Switch B.
[SwitchC-bgp-default-ipv4] peer 9.1.1.1 enable
Verifying the configuration
Ping Switch C on Switch A. Meanwhile, perform an active/standby switchover on Switch B. The ping operation is successful during the whole switchover process. (Details not shown.)
Example: Configuring BFD for BGP
Network configuration
As shown in Figure 6, configure OSPF as the IGP in AS 200.
· Establish two IBGP connections between Switch A and Switch C. When both paths operate correctly, Switch C uses the path Switch A<—>Switch B<—>Switch C to exchange packets with network 1.1.1.0/24.
· Configure BFD over the path. When the path fails, BFD can quickly detect the failure and notify it to BGP. Then, the path Switch A<—>Switch D<—>Switch C takes effect immediately.

Table 2 Interface and IP address assignment
|
Device |
Interface |
IP address |
Device |
Interface |
IP address |
|
Switch A |
Vlan-int100 |
3.0.1.1/24 |
Switch C |
Vlan-int101 |
3.0.2.2/24 |
|
|
Vlan-int200 |
2.0.1.1/24 |
|
Vlan-int201 |
2.0.2.2/24 |
|
Switch B |
Vlan-int100 |
3.0.1.2/24 |
Switch D |
Vlan-int200 |
2.0.1.2/24 |
|
|
Vlan-int101 |
3.0.2.1/24 |
|
Vlan-int201 |
2.0.2.1/24 |
Procedure
1. Configure IP addresses for interfaces. (Details not shown.)
2. Configure OSPF to ensure that Switch A and Switch C are reachable to each other. (Details not shown.)
3. Configure BGP on Switch A:
# Establish two IBGP connections to Switch C.
<SwitchA> system-view
[SwitchA] bgp 200
[SwitchA-bgp-default] peer 3.0.2.2 as-number 200
[SwitchA-bgp-default] peer 2.0.2.2 as-number 200
[SwitchA-bgp-default] address-family ipv4 unicast
[SwitchA-bgp-default-ipv4] peer 3.0.2.2 enable
[SwitchA-bgp-default-ipv4] peer 2.0.2.2 enable
[SwitchA-bgp-default-ipv4] quit
[SwitchA-bgp-default] quit
# Create IPv4 basic ACL 2000 to permit 1.1.1.0/24 to pass.
[SwitchA] acl basic 2000
[SwitchA-acl-ipv4-basic-2000] rule permit source 1.1.1.0 0.0.0.255
[SwitchA-acl-ipv4-basic-2000] quit
# Create two routing policies to set the MED for route 1.1.1.0/24. The policy apply_med_50 sets the MED to 50, and the policy apply_med_100 sets the MED to 100.
[SwitchA] route-policy apply_med_50 permit node 10
[SwitchA-route-policy-apply_med_50-10] if-match ip address acl 2000
[SwitchA-route-policy-apply_med_50-10] apply cost 50
[SwitchA-route-policy-apply_med_50-10] quit
[SwitchA] route-policy apply_med_100 permit node 10
[SwitchA-route-policy-apply_med_100-10] if-match ip address acl 2000
[SwitchA-route-policy-apply_med_100-10] apply cost 100
[SwitchA-route-policy-apply_med_100-10] quit
# Apply routing policy apply_med_50 to routes outgoing to peer 3.0.2.2, and apply routing policy apply_med_100 to routes outgoing to peer 2.0.2.2.
[SwitchA] bgp 200
[SwitchA-bgp-default] address-family ipv4 unicast
[SwitchA-bgp-default-ipv4] peer 3.0.2.2 route-policy apply_med_50 export
[SwitchA-bgp-default-ipv4] peer 2.0.2.2 route-policy apply_med_100 export
[SwitchA-bgp-default-ipv4] quit
# Enable BFD for peer 3.0.2.2.
[SwitchA-bgp-default] peer 3.0.2.2 bfd
[SwitchA-bgp-default] quit
4. Configure BGP on Switch C:
# Establish two IBGP connections to Switch A.
<SwitchC> system-view
[SwitchC] bgp 200
[SwitchC-bgp-default] peer 3.0.1.1 as-number 200
[SwitchC-bgp-default] peer 2.0.1.1 as-number 200
[SwitchC-bgp-default] address-family ipv4 unicast
[SwitchC-bgp-default-ipv4] peer 3.0.1.1 enable
[SwitchC-bgp-default-ipv4] peer 2.0.1.1 enable
[SwitchC-bgp-default-ipv4] quit
# Enable BFD for peer 3.0.1.1.
[SwitchC-bgp-default] peer 3.0.1.1 bfd
[SwitchC-bgp-default] quit
[SwitchC] quit
Verifying the configuration
# Display detailed BFD session information on Switch C.
<SwitchC> display bfd session verbose
Total Session Num: 1 Up Session Num: 1 Init Mode: Active
IPv4 Session Working in control packet mode:
Local Discr: 513 Remote Discr: 513
Source IP: 3.0.2.2 Destination IP: 3.0.1.1
Session State: Up Interface: N/A
Min Tx Inter: 500ms Act Tx Inter: 500ms
Min Rx Inter: 500ms Detect Inter: 2500ms
Rx Count: 135 Tx Count: 135
Connect Type: Indirect Running Up for: 00:00:58
Hold Time: 2457ms Auth mode: None
Detect Mode: Async Slot: 0
Protocol: BGP
Version: 1
Diag Info: No Diagnostic
The output shows that a BFD session has been established between Switch A and Switch C.
# Display BGP peer information on Switch C.
<SwitchC> display bgp peer ipv4
BGP local router ID: 3.3.3.3
Local AS number: 200
Total number of peers: 2 Peers in established state: 2
* - Dynamically created peer
Peer AS MsgRcvd MsgSent OutQ PrefRcv Up/Down State
2.0.1.1 200 4 5 0 0 00:01:55 Established
3.0.1.1 200 4 5 0 0 00:01:52 Established
The output shows that Switch C has established two BGP connections with Switch A, and both connections are in Established state.
# Display route 1.1.1.0/24 on Switch C.
<SwitchC> display ip routing-table 1.1.1.0 24 verbose
Summary count : 1
Destination: 1.1.1.0/24
Protocol: BGP Process ID: 0
SubProtID: 0x1 Age: 00h00m09s
Cost: 50 Preference: 255
IpPre: N/A QosLocalID: N/A
Tag: 0 State: Active Adv
OrigTblID: 0x1 OrigVrf: default-vrf
TableID: 0x2 OrigAs: 0
NibID: 0x15000001 LastAs: 0
AttrID: 0x1 Neighbor: 3.0.1.1
Flags: 0x10060 OrigNextHop: 3.0.1.1
Label: NULL RealNextHop: 3.0.2.1
BkLabel: NULL BkNextHop: N/A
SRLabel: NULL Interface: Vlan-interface101
BkSRLabel: NULL BkInterface: Invalid
Tunnel ID: Invalid IPInterface: Vlan-interface101
BkTunnel ID: Invalid BKIPInterface: N/A
InLabel: NULL ColorInterface: N/A
SIDIndex: NULL BKColorInterface: N/A
FtnIndex: 0x0 TunnelInterface: N/A
TrafficIndex: N/A BKTunnelInterface: N/A
Connector: N/A PathID: 0x0
SRTunnelID: Invalid
SID Type: N/A NID: Invalid
FlushNID: Invalid BkNID: Invalid
BkFlushNID: Invalid StatFlags: 0x0
Exp: N/A
VpnPeerId: N/A Dscp: N/A
SID: N/A OrigLinkID: 0x0
BkSID: N/A RealLinkID: 0x0
CommBlockLen: 0
The output shows that Switch C communicates with network 1.1.1.0/24 through the path Switch C<—>Switch B<—>Switch A.
# Break down the path Switch C<—>Switch B<—>Switch A and then display route 1.1.1.0/24 on Switch C.
<SwitchC> display ip routing-table 1.1.1.0 24 verbose
Summary count : 1
Destination: 1.1.1.0/24
Protocol: BGP Process ID: 0
SubProtID: 0x1 Age: 00h03m08s
Cost: 100 Preference: 255
IpPre: N/A QosLocalID: N/A
Tag: 0 State: Active Adv
OrigTblID: 0x1 OrigVrf: default-vrf
TableID: 0x2 OrigAs: 0
NibID: 0x15000000 LastAs: 0
AttrID: 0x0 Neighbor: 2.0.1.1
Flags: 0x10060 OrigNextHop: 2.0.1.1
Label: NULL RealNextHop: 2.0.2.1
BkLabel: NULL BkNextHop: N/A
SRLabel: NULL Interface: Vlan-interface201
BkSRLabel: NULL BkInterface: Invalid
Tunnel ID: Invalid IPInterface: Vlan-interface201
BkTunnel ID: Invalid BKIPInterface: N/A
InLabel: NULL ColorInterface: N/A
SIDIndex: NULL BKColorInterface: N/A
FtnIndex: 0x0 TunnelInterface: N/A
TrafficIndex: N/A BKTunnelInterface: N/A
Connector: N/A PathID: 0x0
SRTunnelID: Invalid
SID Type: N/A NID: Invalid
FlushNID: Invalid BkNID: Invalid
BkFlushNID: Invalid StatFlags: 0x0
Exp: N/A
VpnPeerId: N/A Dscp: N/A
SID: N/A OrigLinkID: 0x0
BkSID: N/A RealLinkID: 0x0
CommBlockLen: 0
The output shows that Switch C communicates with network 1.1.1.0/24 through the path Switch C<—>Switch D<—>Switch A.
Example: Configuring BGP FRR
Network configuration
As shown in Figure 7, configure BGP FRR so that when Link B fails, BGP uses Link A to forward traffic.
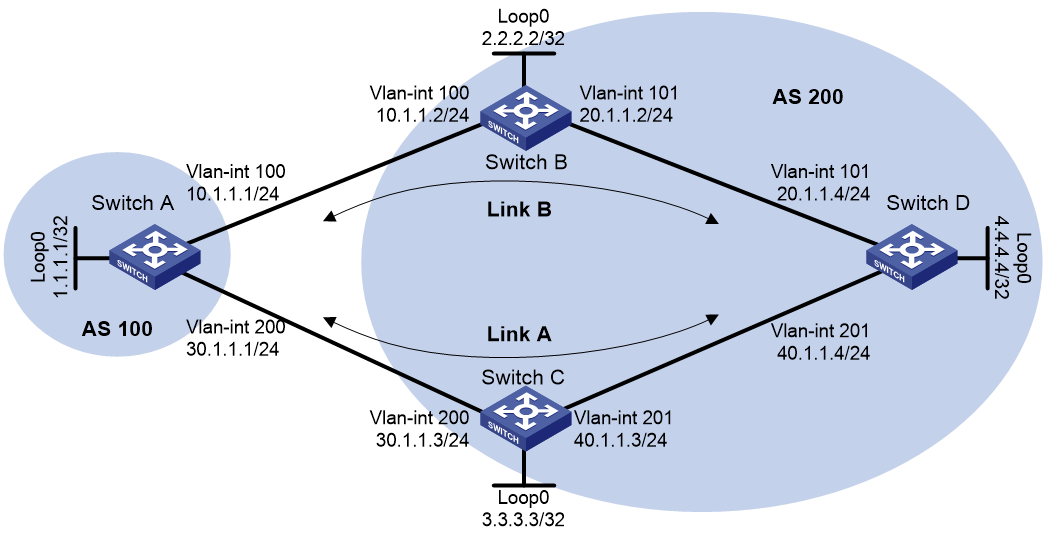
Procedure
1. Configure IP addresses for interfaces. (Details not shown.)
2. Configure OSPF in AS 200 to ensure connectivity among Switch B, Switch C, and Switch D. (Details not shown.)
3. Configure BGP connections:
# Configure Switch A to establish EBGP sessions to Switch B and Switch C, and advertise network 1.1.1.1/32.
<SwitchA> system-view
[SwitchA] bgp 100
[SwitchA-bgp-default] router-id 1.1.1.1
[SwitchA-bgp-default] peer 10.1.1.2 as-number 200
[SwitchA-bgp-default] peer 30.1.1.3 as-number 200
[SwitchA-bgp-default] address-family ipv4 unicast
[SwitchA-bgp-default-ipv4] peer 10.1.1.2 enable
[SwitchA-bgp-default-ipv4] peer 30.1.1.3 enable
[SwitchA-bgp-default-ipv4] network 1.1.1.1 32
# Configure Switch B to establish an EBGP session to Switch A, and an IBGP session to Switch D.
<SwitchB> system-view
[SwitchB] bgp 200
[SwitchB-bgp-default] router-id 2.2.2.2
[SwitchB-bgp-default] peer 10.1.1.1 as-number 100
[SwitchB-bgp-default] peer 4.4.4.4 as-number 200
[SwitchB-bgp-default] peer 4.4.4.4 connect-interface loopback 0
[SwitchB-bgp-default] address-family ipv4 unicast
[SwitchB-bgp-default-ipv4] peer 10.1.1.1 enable
[SwitchB-bgp-default-ipv4] peer 4.4.4.4 enable
[SwitchB-bgp-default-ipv4] peer 4.4.4.4 next-hop-local
[SwitchB-bgp-default-ipv4] quit
[SwitchB-bgp-default] quit
# Configure Switch C to establish an EBGP session to Switch A, and an IBGP session to Switch D.
<SwitchC> system-view
[SwitchC] bgp 200
[SwitchC-bgp-default] router-id 3.3.3.3
[SwitchC-bgp-default] peer 30.1.1.1 as-number 100
[SwitchC-bgp-default] peer 4.4.4.4 as-number 200
[SwitchC-bgp-default] peer 4.4.4.4 connect-interface loopback 0
[SwitchC-bgp-default] address-family ipv4 unicast
[SwitchC-bgp-default-ipv4] peer 30.1.1.1 enable
[SwitchC-bgp-default-ipv4] peer 4.4.4.4 enable
[SwitchC-bgp-default-ipv4] peer 4.4.4.4 next-hop-local
[SwitchC-bgp-default-ipv4] quit
[SwitchC-bgp-default] quit
# Configure Switch D to establish IBGP sessions to Switch B and Switch C, and advertise network 4.4.4.4/32.
<SwitchD> system-view
[SwitchD] bgp 200
[SwitchD-bgp-default] router-id 4.4.4.4
[SwitchD-bgp-default] peer 2.2.2.2 as-number 200
[SwitchD-bgp-default] peer 2.2.2.2 connect-interface loopback 0
[SwitchD-bgp-default] peer 3.3.3.3 as-number 200
[SwitchD-bgp-default] peer 3.3.3.3 connect-interface loopback 0
[SwitchD-bgp-default] address-family ipv4 unicast
[SwitchD-bgp-default-ipv4] peer 2.2.2.2 enable
[SwitchD-bgp-default-ipv4] peer 3.3.3.3 enable
[SwitchD-bgp-default-ipv4] network 4.4.4.4 32
4. Configure preferred values so Link B is used to forward traffic between Switch A and Switch D:
# Configure Switch A to set the preferred value to 100 for routes received from Switch B.
[SwitchA-bgp-default-ipv4] peer 10.1.1.2 preferred-value 100
[SwitchA-bgp-default-ipv4] quit
[SwitchA-bgp-default] quit
# Configure Switch D to set the preferred value to 100 for routes received from Switch B.
[SwitchD-bgp-default-ipv4] peer 2.2.2.2 preferred-value 100
[SwitchD-bgp-default-ipv4] quit
[SwitchD-bgp-default] quit
5. Configure BGP FRR:
# On Switch A, set the source address of BFD echo packets to 11.1.1.1.
[SwitchA] bfd echo-source-ip 11.1.1.1
# Create routing policy frr to set a backup next hop 30.1.1.3 (Switch C) for the route destined for 4.4.4.4/32.
[SwitchA] ip prefix-list abc index 10 permit 4.4.4.4 32
[SwitchA] route-policy frr permit node 10
[SwitchA-route-policy] if-match ip address prefix-list abc
[SwitchA-route-policy] apply fast-reroute backup-nexthop 30.1.1.3
[SwitchA-route-policy] quit
# Use BFD echo packet mode to detect the connectivity to Switch D.
[SwitchA] bgp 100
[SwitchA-bgp-default] primary-path-detect bfd echo
# Apply the routing policy to BGP FRR for BGP IPv4 unicast address family.
[SwitchA-bgp-default] address-family ipv4 unicast
[SwitchA-bgp-default-ipv4] fast-reroute route-policy frr
[SwitchA-bgp-default-ipv4] quit
[SwitchA-bgp-default] quit
# On Switch D, set the source address of BFD echo packets to 44.1.1.1.
[SwitchD] bfd echo-source-ip 44.1.1.1
# Create routing policy frr to set a backup next hop 3.3.3.3 (Switch C) for the route destined for 1.1.1.1/32.
[SwitchD] ip prefix-list abc index 10 permit 1.1.1.1 32
[SwitchD] route-policy frr permit node 10
[SwitchD-route-policy] if-match ip address prefix-list abc
[SwitchD-route-policy] apply fast-reroute backup-nexthop 3.3.3.3
[SwitchD-route-policy] quit
# Use BFD echo packet mode to detect the connectivity to Switch A.
[SwitchD] bgp 200
[SwitchD-bgp-default] primary-path-detect bfd echo
# Apply the routing policy to BGP FRR for BGP IPv4 unicast address family.
[SwitchD-bgp-default] address-family ipv4 unicast
[SwitchD-bgp-default-ipv4] fast-reroute route-policy frr
[SwitchD-bgp-default-ipv4] quit
[SwitchD-bgp-default] quit
Verifying the configuration
# Display detailed information about the route to 4.4.4.4/32 on Switch A. The output shows the backup next hop for the route.
[SwitchA] display ip routing-table 4.4.4.4 32 verbose
Summary count : 1
Destination: 4.4.4.4/32
Protocol: BGP Process ID: 0
SubProtID: 0x2 Age: 00h01m52s
Cost: 0 Preference: 255
IpPre: N/A QosLocalID: N/A
Tag: 0 State: Active Adv
OrigTblID: 0x0 OrigVrf: default-vrf
TableID: 0x2 OrigAs: 200
NibID: 0x15000003 LastAs: 200
AttrID: 0x5 Neighbor: 10.1.1.2
Flags: 0x10060 OrigNextHop: 10.1.1.2
Label: NULL RealNextHop: 10.1.1.2
BkLabel: NULL BkNextHop: 30.1.1.3
SRLabel: NULL Interface: Vlan-interface 100
BkSRLabel: NULL BkInterface: Vlan-interface 200
Tunnel ID: Invalid IPInterface: Vlan-interface 100
BkTunnel ID: Invalid BKIPInterface: N/A
InLabel: NULL ColorInterface: N/A
SIDIndex: NULL BKColorInterface: N/A
FtnIndex: 0x0 TunnelInterface: N/A
TrafficIndex: N/A BKTunnelInterface: N/A
Connector: N/A PathID: 0x0
SRTunnelID: Invalid
SID Type: N/A NID: Invalid
FlushNID: Invalid BkNID: Invalid
BkFlushNID: Invalid StatFlags: 0x0
Exp: N/A
VpnPeerId: N/A Dscp: N/A
SID: N/A OrigLinkID: 0x0
BkSID: N/A RealLinkID: 0x0
CommBlockLen: 0
# Display detailed information about the route to 1.1.1.1/32 on Switch D. The output shows the backup next hop for the route.
[SwitchD] display ip routing-table 1.1.1.1 32 verbose
Summary count : 1
Destination: 1.1.1.1/32
Protocol: BGP Process ID: 0
SubProtID: 0x1 Age: 00h00m36s
Cost: 0 Preference: 255
IpPre: N/A QosLocalID: N/A
Tag: 0 State: Active Adv
OrigTblID: 0x0 OrigVrf: default-vrf
TableID: 0x2 OrigAs: 100
NibID: 0x15000003 LastAs: 100
AttrID: 0x1 Neighbor: 2.2.2.2
Flags: 0x10060 OrigNextHop: 2.2.2.2
Label: NULL RealNextHop: 20.1.1.2
BkLabel: NULL BkNextHop: 40.1.1.3
SRLabel: NULL Interface: Vlan-interface 101
BkSRLabel: NULL BkInterface: Vlan-interface 201
Tunnel ID: Invalid IPInterface: Vlan-interface 101
BkTunnel ID: Invalid BKIPInterface: N/A
InLabel: NULL ColorInterface: N/A
SIDIndex: NULL BKColorInterface: N/A
FtnIndex: 0x0 TunnelInterface: N/A
TrafficIndex: N/A BKTunnelInterface: N/A
Connector: N/A PathID: 0x0
SRTunnelID: Invalid
SID Type: N/A NID: Invalid
FlushNID: Invalid BkNID: Invalid
BkFlushNID: Invalid StatFlags: 0x0
Exp: N/A
VpnPeerId: N/A Dscp: N/A
SID: N/A OrigLinkID: 0x0
BkSID: N/A RealLinkID: 0x0
CommBlockLen: 0
IPv6 BGP network reliability improvement configuration examples
Example: Configuring BFD for IPv6 BGP
Network configuration
As shown in Figure 8, configure OSPFv3 as the IGP in AS 200.
· Establish two IBGP connections between Switch A and Switch C. When both paths operate correctly, Switch C uses the path Switch A<—>Switch B<—>Switch C to exchange packets with network 1200::0/64.
· Configure BFD over the path. When the path fails, BFD can quickly detect the failure and notify it to IPv6 BGP. Then, the path Switch A<—>Switch D<—>Switch C takes effect immediately.
Table 3 Interface and IP address assignment
|
Device |
Interface |
IP address |
Device |
Interface |
IP address |
|
Switch A |
Vlan-int100 |
3000::1/64 |
Switch C |
Vlan-int101 |
3001::3/64 |
|
|
Vlan-int200 |
2000::1/64 |
|
Vlan-int201 |
2001::3/64 |
|
Switch B |
Vlan-int100 |
3000::2/64 |
Switch D |
Vlan-int200 |
2000::2/64 |
|
|
Vlan-int101 |
3001::2/64 |
|
Vlan-int201 |
2001::2/64 |
Procedure
1. Configure IPv6 addresses for interfaces. (Details not shown.)
2. Configure OSPFv3 so that Switch A and Switch C can reach each other. (Details not shown.)
3. Configure IPv6 BGP on Switch A:
# Establish two IBGP connections to Switch C.
<SwitchA> system-view
[SwitchA] bgp 200
[SwitchA-bgp-default] router-id 1.1.1.1
[SwitchA-bgp-default] peer 3001::3 as-number 200
[SwitchA-bgp-default] peer 2001::3 as-number 200
[SwitchA-bgp-default] address-family ipv6
[SwitchA-bgp-default-ipv6] peer 3001::3 enable
[SwitchA-bgp-default-ipv6] peer 2001::3 enable
[SwitchA-bgp-default-ipv6] quit
# Create IPv6 basic ACL 2000 to permit 1200::0/64 to pass.
[SwitchA] acl ipv6 basic 2000
[SwitchA-acl-ipv6-basic-2000] rule permit source 1200:: 64
[SwitchA-acl-ipv6-basic-2000] quit
# Create two routing policies to set the MED for route 1200::0/64. The policy apply_med_50 sets the MED to 50, and the policy apply_med_100 sets the MED to 100.
[SwitchA] route-policy apply_med_50 permit node 10
[SwitchA-route-policy-apply_med_50-10] if-match ipv6 address acl 2000
[SwitchA-route-policy-apply_med_50-10] apply cost 50
[SwitchA-route-policy-apply_med_50-10] quit
[SwitchA] route-policy apply_med_100 permit node 10
[SwitchA-route-policy-apply_med_100-10] if-match ipv6 address acl 2000
[SwitchA-route-policy-apply_med_100-10] apply cost 100
[SwitchA-route-policy-apply_med_100-10] quit
# Apply routing policy apply_med_50 to routes outgoing to peer 3001::3, and apply routing policy apply_med_100 to routes outgoing to peer 2001::3.
[SwitchA] bgp 200
[SwitchA-bgp-default] address-family ipv6 unicast
[SwitchA-bgp-default-ipv6] peer 3001::3 route-policy apply_med_50 export
[SwitchA-bgp-default-ipv6] peer 2001::3 route-policy apply_med_100 export
[SwitchA-bgp-default-ipv6] quit
# Enable BFD for peer 3001::3.
[SwitchA-bgp-default] peer 3001::3 bfd
[SwitchA-bgp-default] quit
4. Configure IPv6 BGP on Switch C:
# Establish two IBGP connections to Switch A.
<SwitchC> system-view
[SwitchC] bgp 200
[SwitchC-bgp-default] router-id 3.3.3.3
[SwitchC-bgp-default] peer 3000::1 as-number 200
[SwitchC-bgp-default] peer 2000::1 as-number 200
[SwitchC-bgp-default] address-family ipv6
[SwitchC-bgp-default-ipv6] peer 3000::1 enable
[SwitchC-bgp-default-ipv6] peer 2000::1 enable
[SwitchC-bgp-default-ipv6] quit
# Enable BFD for peer 3001::1.
[SwitchC-bgp-default] peer 3000::1 bfd
[SwitchC-bgp-default] quit
[SwitchC] quit
Verifying the configuration
# Display detailed BFD session information on Switch C.
<SwitchC> display bfd session verbose
Total Session Num: 1 Up Session Num: 1 Init Mode: Active
IPv6 Session Working in control packet mode:
Local Discr: 513 Remote Discr: 513
Source IP: 3001::3
Destination IP: 3000::1
Session State: Up Interface: N/A
Min Tx Inter: 500ms Act Tx Inter: 500ms
Min Rx Inter: 500ms Detect Inter: 2500ms
Rx Count: 13 Tx Count: 14
Connect Type: Indirect Running Up for: 00:00:05
Hold Time: 2243ms Auth mode: None
Detect Mode: Async Slot: 0
Protocol: BGP4+
Version:1
Diag Info: No Diagnostic
The output shows that a BFD session has been established between Switch A and Switch C.
# Display BGP peer information on Switch C.
<SwitchC> display bgp peer ipv6
BGP local router ID: 3.3.3.3
Local AS number: 200
Total number of peers: 2 Peers in established state: 2
* - Dynamically created peer
Peer AS MsgRcvd MsgSent OutQ PrefRcv Up/Down State
2000::1 200 8 8 0 0 00:04:45 Established
3000::1 200 5 4 0 0 00:01:53 Established
The output shows that Switch C has established two BGP connections with Switch A, and both connections are in Established state.
# Display route 1200::0/64 on Switch C.
<SwitchC> display ipv6 routing-table 1200::0 64 verbose
Summary count : 1
Destination: 1200::/64
Protocol: BGP4+ Process ID: 0
SubProtID: 0x1 Age: 00h01m07s
Cost: 50 Preference: 255
IpPre: N/A QosLocalID: N/A
Tag: 0 State: Active Adv
OrigTblID: 0x1 OrigVrf: default-vrf
TableID: 0xa OrigAs: 0
NibID: 0x25000001 LastAs: 0
AttrID: 0x1 Neighbor: 3000::1
Flags: 0x10060 OrigNextHop: 3000::1
Label: NULL RealNextHop: FE80::20C:29FF:FE4A:3873
BkLabel: NULL BkNextHop: N/A
SRLabel: NULL Interface: Vlan-interface101
BkSRLabel: NULL BkInterface: N/A
Tunnel ID: Invalid IPInterface: Vlan-interface101
BkTunnel ID: Invalid BKIPInterface: N/A
InLabel: NULL ColorInterface: N/A
SIDIndex: NULL BKColorInterface: N/A
FtnIndex: 0x0 TunnelInterface: N/A
TrafficIndex: N/A BKTunnelInterface: N/A
Connector: N/A PathID: 0x0
SRTunnelID: Invalid
SID Type: N/A NID: Invalid
FlushNID: Invalid BkNID: Invalid
BkFlushNID: Invalid StatFlags: 0x0
Exp: N/A
VpnPeerId: N/A Dscp: N/A
SID: N/A OrigLinkID: 0x0
BkSID: N/A RealLinkID: 0x0
CommBlockLen: 0
The output shows that Switch C communicates with network 1200::0/64 through the path Switch C<—>Switch B<—>Switch A.
# Break down the path Switch C<—>Switch B<—>Switch A and then display route 1200::0/64 on Switch C.
<SwitchC> display ipv6 routing-table 1200::0 64 verbose
Summary count : 1
Destination: 1200::/64
Protocol: BGP4+ Process ID: 0
SubProtID: 0x1 Age: 00h00m57s
Cost: 100 Preference: 255
IpPre: N/A QosLocalID: N/A
Tag: 0 State: Active Adv
OrigTblID: 0x1 OrigVrf: default-vrf
TableID: 0xa OrigAs: 0
NibID: 0x25000000 LastAs: 0
AttrID: 0x0 Neighbor: 2000::1
Flags: 0x10060 OrigNextHop: 2000::1
Label: NULL RealNextHop: FE80::20C:29FF:FE40:715
BkLabel: NULL BkNextHop: N/A
SRLabel: NULL Interface: Vlan-interface201
BkSRLabel: NULL BkInterface: N/A
Tunnel ID: Invalid IPInterface: Vlan-interface201
BkTunnel ID: Invalid BKIPInterface: N/A
InLabel: NULL ColorInterface: N/A
SIDIndex: NULL BKColorInterface: N/A
FtnIndex: 0x0 TunnelInterface: N/A
TrafficIndex: N/A BKTunnelInterface: N/A
Connector: N/A PathID: 0x0
SRTunnelID: Invalid
SID Type: N/A NID: Invalid
FlushNID: Invalid BkNID: Invalid
BkFlushNID: Invalid StatFlags: 0x0
Exp: N/A
VpnPeerId: N/A Dscp: N/A
SID: N/A OrigLinkID: 0x0
BkSID: N/A RealLinkID: 0x0
CommBlockLen: 0
The output shows that Switch C communicates with network 1200::0/64 through the path Switch C<—>Switch D<—>Switch A.
Example: Configuring IPv6 BGP FRR
Network configuration
As shown in Figure 9, configure BGP FRR so that when Link B fails, BGP uses Link A to forward traffic.
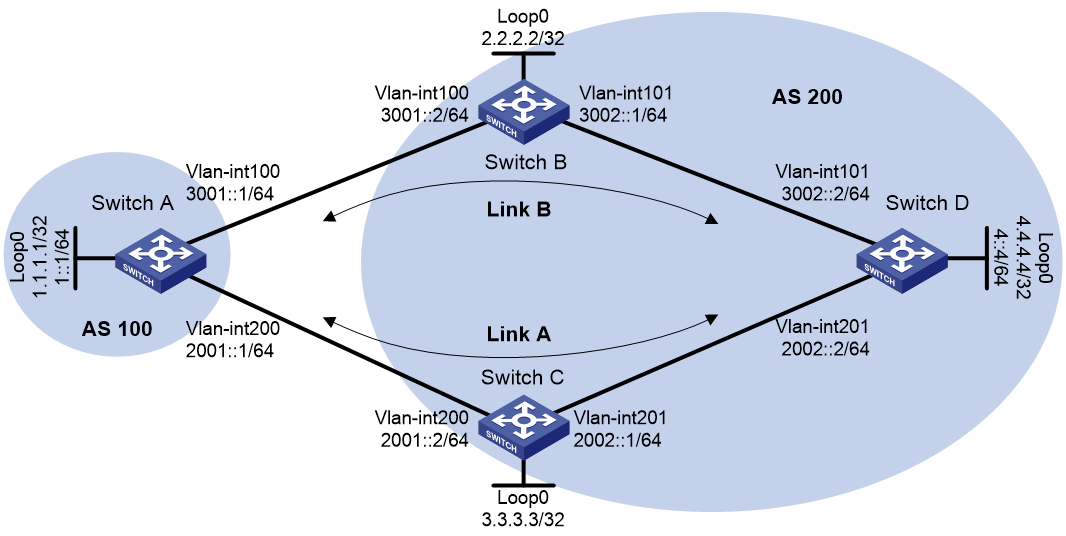
Procedure
1. Configure IPv6 addresses for interfaces. (Details not shown.)
2. Configure OSPFv3 in AS 200 to ensure connectivity among Switch B, Switch C, and Switch D. (Details not shown.)
3. Configure BGP connections:
# Configure Switch A to establish EBGP sessions to Switch B and Switch C, and advertise network 1::/64.
<SwitchA> system-view
[SwitchA] bgp 100
[SwitchA] router-id 1.1.1.1
[SwitchA-bgp-default] peer 3001::2 as-number 200
[SwitchA-bgp-default] peer 2001::2 as-number 200
[SwitchA-bgp-default] address-family ipv6 unicast
[SwitchA-bgp-default-ipv6] peer 3001::2 enable
[SwitchA-bgp-default-ipv6] peer 2001::2 enable
[SwitchA-bgp-default-ipv6] network 1:: 64
[SwitchA-bgp-default-ipv6] quit
[SwitchA-bgp-default] quit
# Configure Switch B to establish an EBGP session to Switch A, and an IBGP session to Switch D.
<SwitchB> system-view
[SwitchB] bgp 200
[SwitchB] router-id 2.2.2.2
[SwitchB-bgp-default] peer 3001::1 as-number 100
[SwitchB-bgp-default] peer 3002::2 as-number 200
[SwitchB-bgp-default] address-family ipv6 unicast
[SwitchB-bgp-default-ipv6] peer 3001::1 enable
[SwitchB-bgp-default-ipv6] peer 3002::2 enable
[SwitchB-bgp-default-ipv6] peer 3002::2 next-hop-local
[SwitchB-bgp-default-ipv6] quit
[SwitchB-bgp-default] quit
# Configure Switch C to establish an EBGP session to Switch A, and an IBGP session to Switch D.
<SwitchC> system-view
[SwitchC] bgp 200
[SwitchC] router-id 3.3.3.3
[SwitchC-bgp-default] peer 2001::1 as-number 100
[SwitchC-bgp-default] peer 2002::2 as-number 200
[SwitchC-bgp-default] address-family ipv6 unicast
[SwitchC-bgp-default-ipv6] peer 2001::1 enable
[SwitchC-bgp-default-ipv6] peer 2002::2 enable
[SwitchC-bgp-default-ipv6] peer 2002::2 next-hop-local
[SwitchC-bgp-default-ipv6] quit
[SwitchC-bgp-default] quit
# Configure Switch D to establish IBGP sessions to Switch B and Switch C, and advertise network 4::/64.
<SwitchD> system-view
[SwitchD] bgp 200
[SwitchD-bgp-default] peer 3002::1 as-number 200
[SwitchD-bgp-default] peer 2002::1 as-number 200
[SwitchD-bgp-default] address-family ipv6 unicast
[SwitchD-bgp-default-ipv6] peer 3002::1 enable
[SwitchD-bgp-default-ipv6] peer 2002::1 enable
[SwitchD-bgp-default-ipv6] network 4:: 64
[SwitchD-bgp-default-ipv6] quit
[SwitchD-bgp-default] quit
4. Configure preferred values so Link B is used to forward traffic between Switch A and Switch D:
# Configure Switch A to set the preferred value to 100 for routes received from Switch B.
[SwitchA-bgp-default-ipv6] peer 3001::2 preferred-value 100
[SwitchA-bgp-default-ipv6] quit
[SwitchA-bgp-default] quit
# Configure Switch D to set the preferred value to 100 for routes received from Switch B.
[SwitchD-bgp-default-ipv6] peer 3002::1 preferred-value 100
[SwitchD-bgp-default-ipv6] quit
[SwitchD-bgp-default] quit
5. Configure BGP FRR:
# On Switch A, create routing policy frr to set a backup next hop 2001::2 (Switch C) for the route destined for 4::/64.
<SwitchA> system-view
[SwitchA] ipv6 prefix-list abc index 10 permit 4:: 64
[SwitchA] route-policy frr permit node 10
[SwitchA-route-policy] if-match ipv6 address prefix-list abc
[SwitchA-route-policy] apply ipv6 fast-reroute backup-nexthop 2001::2
[SwitchA-route-policy] quit
# Apply the routing policy to BGP FRR for BGP IPv6 unicast address family.
[SwitchA] bgp 100
[SwitchA-bgp-default] address-family ipv6 unicast
[SwitchA-bgp-default-ipv6] fast-reroute route-policy frr
[SwitchA-bgp-default-ipv6] quit
[SwitchA-bgp-default] quit
# On Switch D, create routing policy frr to set a backup next hop 2002::1 (Switch C) for the route destined for 1::/64.
<SwitchD> system-view
[SwitchD] ipv6 prefix-list abc index 10 permit 1:: 64
[SwitchD] route-policy frr permit node 10
[SwitchD-route-policy] if-match ipv6 address prefix-list abc
[SwitchD-route-policy] apply ipv6 fast-reroute backup-nexthop 2002::1
[SwitchD-route-policy] quit
# Apply the routing policy to BGP FRR for BGP IPv6 unicast address family.
[SwitchD] bgp 200
[SwitchD-bgp-default] address-family ipv6 unicast
[SwitchD-bgp-default-ipv6] fast-reroute route-policy frr
[SwitchD-bgp-default-ipv6] quit
[SwitchD-bgp-default] quit
Verifying the configuration
# Display detailed information about the route to 4::/64 on Switch A. The output shows the backup next hop for the route.
[SwitchA] display ipv6 routing-table 4:: 64 verbose
Summary count : 1
Destination: 4::/64
Protocol: BGP4+ Process ID: 0
SubProtID: 0x2 Age: 00h00m58s
Cost: 0 Preference: 255
IpPre: N/A QosLocalID: N/A
Tag: 0 State: Active Adv
OrigTblID: 0x0 OrigVrf: default-vrf
TableID: 0xa OrigAs: 200
NibID: 0x25000003 LastAs: 200
AttrID: 0x3 Neighbor: 3001::2
Flags: 0x10060 OrigNextHop: 3001::2
Label: NULL RealNextHop: 3001::2
BkLabel: NULL BkNextHop: 2001::2
SRLabel: NULL Interface: Vlan-interface 100
BkSRLabel: NULL BkInterface: Vlan-interface 200
Tunnel ID: Invalid IPInterface: Vlan-interface 100
BkTunnel ID: Invalid BKIPInterface: N/A
InLabel: NULL ColorInterface: N/A
SIDIndex: NULL BKColorInterface: N/A
FtnIndex: 0x0 TunnelInterface: N/A
TrafficIndex: N/A BKTunnelInterface: N/A
Connector: N/A PathID: 0x0
SRTunnelID: Invalid
SID Type: N/A NID: Invalid
FlushNID: Invalid BkNID: Invalid
BkFlushNID: Invalid StatFlags: 0x0
Exp: N/A
VpnPeerId: N/A Dscp: N/A
SID: N/A OrigLinkID: 0x0
BkSID: N/A RealLinkID: 0x0
CommBlockLen: 0
# Display detailed information about the route to 1::/64 on Switch D. The output shows the backup next hop for the route.
[SwitchD] display ipv6 routing-table 1:: 64 verbose
Summary count : 1
Destination: 1::/64
Protocol: BGP4+ Process ID: 0
SubProtID: 0x1 Age: 00h03m24s
Cost: 0 Preference: 255
IpPre: N/A QosLocalID: N/A
Tag: 0 State: Active Adv
OrigTblID: 0x0 OrigVrf: default-vrf
TableID: 0xa OrigAs: 100
NibID: 0x25000003 LastAs: 100
AttrID: 0x4 Neighbor: 3002::1
Flags: 0x10060 OrigNextHop: 3002::1
Label: NULL RealNextHop: 3002::1
BkLabel: NULL BkNextHop: 2002::1
SRLabel: NULL Interface: Vlan-interface 101
BkSRLabel: NULL BkInterface: Vlan-interface 201
Tunnel ID: Invalid IPInterface: Vlan-interface 101
BkTunnel ID: Invalid BKIPInterface: N/A
InLabel: NULL ColorInterface: N/A
SIDIndex: NULL BKColorInterface: N/A
FtnIndex: 0x0 TunnelInterface: N/A
TrafficIndex: N/A BKTunnelInterface: N/A
Connector: N/A PathID: 0x0
SRTunnelID: Invalid
SID Type: N/A NID: Invalid
FlushNID: Invalid BkNID: Invalid
BkFlushNID: Invalid StatFlags: 0x0
Exp: N/A
VpnPeerId: N/A Dscp: N/A
SID: N/A OrigLinkID: 0x0
BkSID: N/A RealLinkID: 0x0
CommBlockLen: 0
Configuring extended BGP features
Extended BGP feature configuration tasks at a glance
To configure extended BGP features, perform the following tasks:
¡ (Optional.) Configuring BGP LS route reflection
¡ (Optional.) Specifying an AS number and a router ID for BGP LS messages
¡ (Optional.) Disabling nexthop changing for BGP LS routes
¡ (Optional.) Enabling routing policy-based nexthop recursion for BGP LS routes
¡ (Optional.) Performing manual soft-reset for BGP sessions of LS address family
Configuring BGP LS
About BGP LS
The BGP Link State (LS) feature implements inter-domain and inter-AS advertisement of link state database (LSDB) and TE database (TEDB) information.
The device sends the collected link state information to the controller, which implements end-to-end traffic management and scheduling and meets the requirements of intended applications.
Configuring basic BGP LS
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Specify an AS number for an LS peer or peer group.
peer { { ipv4-address [ mask-length ] | ipv6-address [ prefix-length ] } | group-name } as-number as-number
By default, no AS number is specified.
4. Create the BGP LS address family and enter its view.
address-family link-state
5. Enable the device to exchange LS information with the peer or peer group.
peer { group-name | ipv4-address [ mask-length ] | ipv6-address [ prefix-length ] } enable
By default, the device cannot exchange LS information with the peer or peer group.
Configuring BGP LS route reflection
About this task
Perform this task to configure a BGP route reflector and its clients. The route reflector and its clients automatically form a cluster identified by the router ID of the route reflector. The route reflector forwards route updates among its clients.
Procedure
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Enter BGP LS address family view.
address-family link-state
4. Configure BGP LS route reflection.
¡ Configure the device as a route reflector and specify a peer or peer group as its client.
peer { group-name | ipv4-address [ mask-length ] | ipv6-address [ prefix-length ] } reflect-client
By default, no route reflector or client is configured.
¡ (Optional.) Enable route reflection between clients.
reflect between-clients
By default, route reflection between clients is enabled.
This command can reduce the number of IBGP connections in an AS.
¡ (Optional.) Configure the cluster ID of the route reflector.
reflector cluster-id { cluster-id | ipv4-address }
By default, a route reflector uses its own router ID as the cluster ID.
Specifying an AS number and a router ID for BGP LS messages
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Enter BGP LS address family view.
address-family link-state
4. Specify an AS number and a router ID for BGP LS messages.
domain-distinguisher as-number:router-id
By default, the AS number and router ID of the current BGP process are used.
Configure this command to ensure that LS messages sent by devices in the same AS have the same AS number and router ID.
Disabling nexthop changing for BGP LS routes
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Enter BGP LS address family view.
address-family link-state
4. Disable nexthop changing for the BGP LS routes advertised to a peer or peer group
peer { group-name | ipv4-address [ mask-length ] | ipv6-address [ prefix-length ] } next-hop-invariable
By default, the device sets its IP address as the next hop for all routes advertised to an EBGP peer or peer group. It does not set its IP address as the next hop for routes advertised to an IBGP peer or peer group.
Enabling routing policy-based nexthop recursion for BGP LS routes
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Enter BGP LS address family view.
address-family link-state
Enable routing policy-based nexthop recursion for BGP LS routes
nexthop recursive-lookup route-policy route-policy-name
By default, BGP does not perform routing policy-based nexthop recursion for routes.
|
|
CAUTION: Before executing this command, make sure that BGP routes can be iterated to the desired paths under the constraints of the specified routing policy. If the recursion results of a BGP route are all filtered out by the specified routing policy, BGP considers the route unreachable. |
Performing manual soft-reset for BGP sessions of LS address family
1. Enter system view.
system-view
2. Enter BGP instance view.
bgp as-number [ instance instance-name ]
3. Enable BGP route refresh.
¡ Enable BGP route refresh for a peer or peer group.
peer { group-name | ipv4-address [ mask-length ] | ipv6-address [ prefix-length ] } capability-advertise route-refresh
¡ Enable the BGP route refresh, multi-protocol extension, and 4-byte AS number features for a peer or peer group.
undo peer { group-name | ipv4-address [ mask-length ] | ipv6-address [ prefix-length ] } capability-advertise conventional
By default, the BGP route refresh, multi-protocol extension, and 4-byte AS number features are enabled.
4. Perform manual soft-reset for BGP sessions of LS address family:
a. Return to system view.
quit
b. Return to user view.
quit
c. Perform manual soft-reset for BGP sessions of LS address family.
refresh bgp [ instance instance-name ] { ipv4-address [ mask-length ] | ipv6-address [ prefix-length ] | all | external | group group-name | internal } { export | import } link-state
Verifying and maintaining BGP LS
Verifying BGP LS configuration and running status
Perform display tasks in any view.
· Display BGP LS peer group information.
display bgp [ instance instance-name ] group link-state [ group-name group-name ]
· Display BGP LS peer or peer group information.
display bgp [ instance instance-name ] peer link-state [ ipv4-address mask-length | ipv6-address prefix-length | { ipv4-address | ipv6-address | group-name group-name } log-info | [ ipv4-address | ipv6-address ] verbose ]
· Display BGP LS address family information.
display bgp [ instance instance-name ] link-state [ ls-prefix [ advertise-info | as-path | cluster-list ] | peer { ipv4-address | ipv6-address } { advertised | received } [ statistics ] | statistics ]
display bgp [ instance instance-name ] link-state [ color color-value end-point { ipv4 ipv4-address | ipv6 ipv6-address } ]
· Display BGP update group information for the LS address family.
display bgp [ instance instance-name ] update-group link-state [ ipv4-address | ipv6-address ]
Resetting BGP session in the LS address family
To reset BGP sessions in the LS address family, execute the following command in user view:
reset bgp [ instance instance-name ] { as-number | ipv4-address [ mask-length ] | ipv6-address [ prefix-length ] | all | external | group group-name | internal } link-state
Extended IPv4 BGP feature configuration examples
Example: Configuring BGP LS
Network configuration
As shown in Figure 10, all switches run BGP. Run IBGP between Switch A and Switch B, between Switch B and Switch C, and between Switch B and Switch D.
Configure Switch B as a route reflector with client Switch A to allow Switch A to learn LS information advertised by Switch C and Switch D.

Procedure
1. Configure IP addresses for interfaces and configure OSPF on Switch C and Switch D. (Details not shown.)
2. Configure BGP connections:
# Configure Switch A.
<SwitchA> system-view
[SwitchA] bgp 100
[SwitchA-bgp-default] peer 192.1.1.2 as-number 100
[SwitchA-bgp-default] address-family link-state
[SwitchA-bgp-default-ls] peer 192.1.1.2 enable
[SwitchA-bgp-default-ls] quit
[SwitchA-bgp-default] quit
# Configure Switch B.
<SwitchB> system-view
[SwitchB] bgp 100
[SwitchB-bgp-default] peer 192.1.1.1 as-number 100
[SwitchB-bgp-default] peer 193.1.1.1 as-number 100
[SwitchB-bgp-default] peer 194.1.1.1 as-number 100
[SwitchB-bgp-default] address-family link-state
[SwitchB-bgp-default-ls] peer 192.1.1.1 enable
[SwitchB-bgp-default-ls] peer 193.1.1.1 enable
[SwitchB-bgp-default-ls] peer 194.1.1.1 enable
[SwitchB-bgp-default-ls] quit
[SwitchB-bgp-default] quit
# Configure Switch C.
<SwitchC> system-view
[SwitchC] bgp 100
[SwitchC-bgp-default] peer 193.1.1.2 as-number 100
[SwitchC-bgp-default] address-family link-state
[SwitchC-bgp-default-ls] peer 193.1.1.2 enable
[SwitchC-bgp-default-ls] quit
[SwitchC-bgp-default] quit
[SwitchC] ospf
[SwitchC-ospf-1] distribute bgp-ls
[SwitchC-ospf-1] area 0
[SwitchC-ospf-1-area-0.0.0.0] network 0.0.0.0 0.0.0.0
[SwitchC-ospf-1-area-0.0.0.0] quit
[SwitchC-ospf-1] quit
# Configure Switch D.
<SwitchD> system-view
[SwitchD] bgp 100
[SwitchD-bgp-default] peer 194.1.1.2 as-number 100
[SwitchD-bgp-default] address-family link-state
[SwitchD-bgp-default-ls] peer 194.1.1.2 enable
[SwitchD-bgp-default-ls] quit
[SwitchD-bgp-default] quit
[SwitchD] ospf
[SwitchD-ospf-1] distribute bgp-ls
[SwitchD-ospf-1] area 0
[SwitchD-ospf-1-area-0.0.0.0] network 0.0.0.0 0.0.0.0
[SwitchD-ospf-1-area-0.0.0.0] quit
[SwitchD-ospf-1] quit
3. Configure Switch B as the route reflector.
[SwitchB] bgp 100
[SwitchB-bgp-default] address-family link-state
[SwitchB-bgp-default-ls] peer 192.1.1.1 reflect-client
[SwitchB-bgp-default-ls] quit
[SwitchB-bgp-default] quit
Verifying the configuration
# Verify that Switch A has learned LS information advertised by Switch C and Switch D.
[SwitchA] display bgp link-state
Total number of routes: 4
BGP local Switch ID is 192.1.1.1
Status codes: * - valid, > - best, d - dampened, h - history,
s - suppressed, S - stale, i - internal, e - external
a – additional-path
Origin: i - IGP, e - EGP, ? - incomplete
Prefix codes: E link, V node, T4 IPv4 route, T6 IPv6 route, SD SRv6 SID desc
u/U unknown,
I Identifier, N local node, R remote node, L link, P prefix,
L1/L2 ISIS level-1/level-2, O OSPF, O3 OSPFv3,
D direct, S static, B BGP, SS SRv6 SID,
a area-ID, l link-ID, t topology-ID, s ISO-ID,
c confed-ID/ASN, b bgp-identifier, r router-ID,
i if-address, n peer-address, o OSPF Route-type, p IP-prefix
d designated router address/interface ID
i Network : [V][O][I0x0][N[c100][b193.1.1.1][a0.0.0.0][r193.1.1.1]]/376
NextHop : 193.1.1.1 LocPrf : 100
PrefVal : 0 OutLabel : NULL
MED :
Path/Ogn: i
i Network : [V][O][I0x0][N[c100][b194.1.1.1][a0.0.0.0][r194.1.1.1]]/376
NextHop : 194.1.1.1 LocPrf : 100
PrefVal : 0 OutLabel : NULL
MED :
Path/Ogn: i
i Network : [T4][O][I0x0][N[c100][b193.1.1.1][a0.0.0.0][r193.1.1.1]][P[o0x1][p193.1.1.0/24]]/480
NextHop : 193.1.1.1 LocPrf : 100
PrefVal : 0 OutLabel : NULL
MED :
Path/Ogn: i
i Network : [T4][O][I0x0][N[c100][b194.1.1.1][a0.0.0.0][r194.1.1.1]][P[o0x1][p194.1.1.0/24]]/480
NextHop : 194.1.1.1 LocPrf : 100
PrefVal : 0 OutLabel : NULL
MED :
Path/Ogn: i