- 产品与解决方案
- 行业解决方案
- 服务
- 支持
- 合作伙伴
- 关于我们





数据库的简单分类
首先,当前数据库简单分为OLTP 数据库和 OLAP 数据库
OLTP,也叫联机事务处理(Online Transaction Processing),表示事务性非常高的系统,一般都是高可用的在线系统,以大并发多事务写入以及小查询为主,评估其系统的时候,一般看其每秒执行的Transaction以及Execute SQL的数量。在这样的系统中,单个数据库每秒处理的写入往往超过几千个,或者是几万个,查询语句的执行量每秒几百甚至几千个。数据密集存储方式都是按行存储,行写入能够提供高速的写入性能。
典型的行写入数据库系统有银行交易系统数据库、证券系统、购票系统等,如银行的业务数据库,就是很典型的行存储数据库。
OLAP,也叫联机分析处理(Online Analytical Processing)系统,有的时候也叫DSS决策支持系统,就是我们说的数据仓库。在这样的系统中,语句的执行量不是考核标准,因为一条语句的执行时间可能会非常长,读取的数据也非常多。所以,在这样的系统中,考核的标准往往是磁盘子系统的吞吐量(带宽),如能达到多少MB/s的流量。对于OLAP系统来说,绝大多数时候数据库上运行着的是报表作业,执行基本上是聚合类的SQL 操作。例如:SUM( ), COUNT( ), AVG( ) 等函数的使用。
OLAP 系统的数据库要求大吞吐量,高速输出的性能保证报表统计的快速完成,提高系统响应时间从而减少用户等待时间。列式存储的数据库非常适合这样的应用场景。
数据库存储原理
关系型数据库系统以二维表的形式呈现数据,比如下面的员工表
RowId | EmpId | Lastname | Firstname | Salary |
001 | 10 | Smith | Joe | 40000 |
002 | 12 | Jones | Mary | 50000 |
003 | 11 | Johnson | Cathy | 44000 |
004 | 22 | Jones | Bob | 55000 |
上面的格式仅仅存在于理论和逻辑中,事实上存储设备要求数据序列化为某种形式。
我们知道对于硬盘来说,最昂贵的操作是查找。为了提高最终性能,所需要的相关数据应该以某种方式去存储从而使“查找”操作尽可能少。硬盘由一系列规定大小的块(block)组成, 通常足以容纳数据表的几行。通过把相关的行存储在块中,仅仅一定数量的块需要被读取从而最小化了查找的数量。
行式存储原理
传统的存储方案是按行序列化数据,如下所示
001:10,Smith,Joe,40000;002:12,Jones,Mary,50000;003:11,Johnson,Cathy,44000;004:22,Jones,Bob,55000;
行式存储系统被设计为以很少的操作就可以返回整行或整条记录。当我们需要获取关于某个特定对象的信息的时候,比如某个用户的联系信息或某件商品信息,这种设计就相当适用。
但是行式存储不适用于对整个数据集的操作。比如,找出工资在40000到50000之间的记录,行式存储系统可能得找遍这个数据集才能找出匹配的所有记录。当数据量相当大时,这些记录存储于分散的不同的磁盘块中,这样相当多的磁盘操作就变得不可避免了。
为了提高这种类型操作的性能,大多数DBMS数据库系统使用索引技术。它把列的值存储在一起,同时与记录ID关联。如下所示
001:40000;002:50000;003:44000;004:55000;
我们可以看到,这里仅仅存储整个数据集的一部分,一般来说索引比整个主表要小很多。扫描小的数据集所需要的磁盘操作当然减少了。然而,当有新的数据写入数据库时,索引需要维护,这个对系统增加了额外的开销。
有些行式存储数据库被设计为完全运行于内存中,及内存数据库。这样的系统不依赖于磁盘操作,对于整个数据库的任何数据访问具有同等时间. (equal-time access) 这样的系统可能会很简单有效,然而它们管理的数据仅限于存储在内存中。
列式存储原理
列式存储系统将某一列的所有值序列化在一起,然后是另一列的所有值。对于我们的例表,数据存储结构如下
10:001,12:002,11:003,22:004;Smith:001,Jones:002,Johnson:003,Jones:004;Joe:001,Mary:002,Cathy:003,Bob:004;40000:001,50000:002,44000:003,55000:004;
这样的结构看起来与行式存储中的索引结构看起来很像,对吧。是的,没错,看起来很接近。
只是,它们之间有显著的区别。行式存储中,主键是rowid(它关联到索引数据);列式存储中,主键是数据本身(关联回rowid),即“数据即索引”。对于常见的查询,如“所有名字叫Jones的人”,仅仅需要一个操作答案将被找到;另外,像一些聚合运算,基于这样的存储结构其性能能得以大幅提高。
行式与列式存储各自优势
基于行的存储是将数据组织成多个行,这样就能在一个操作中找到所有的列。这种做法的缺点是必须每次处理一整行,而不是只处理自己需要的列。不过,这样在处理相同实体的两个或多个列的查询时能够取得更快的速度,而且可以提高更新、插入和删除操作的速度。
基于列的访问存在的缺点是载入速度通常比较慢,因为源数据在外部来源中是以行或者记录的形式表示的。这样做的优点是针对某个列中的值进行简单查询的速度非常快,需要的内部存储资源最少。这表示对某个列中特定值的搜索可以直接进入该列的存储区,而不需要扫描整行的数据。这样也使得数据压缩变得更容易,因为一个列中的数据通常具有相同的数据类型。这种体系结构在处理数据仓库使用的海量数据时没有问题,但不适合需要进行大量以行的方式进行访问和更新操作的联机事物处理。就是这种数据库之一。在由一万亿行组成的测试数据集中,输入数据共很明显,这是一种适合数据仓库的技术。这种技术虽然在压缩和快速访问方面有优势,但也存在插入操作复杂的缺点。
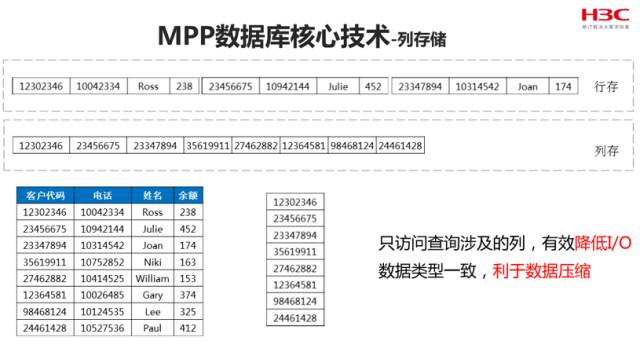
新华三大数据产品DataEngineMPP主要瞄准的是大批量统计的数据仓库市场。所以根据业务的需要选择了批量计算性能高,输出更高效的列式存储技术。

新华三依托先进的IT技术助推新经济,推动国家实现强国富民,与有荣焉。










