- 产品与解决方案
- 行业解决方案
- 服务
- 支持
- 合作伙伴
- 关于我们




手册下载
H3C UniServer R4930 G3服务器
故障处理手册
资料版本:6W101-20230104
Copyright © 2022-2023 新华三技术有限公司 版权所有,保留一切权利。
非经本公司书面许可,任何单位和个人不得擅自摘抄、复制本文档内容的部分或全部,并不得以任何形式传播。
除新华三技术有限公司的商标外,本手册中出现的其它公司的商标、产品标识及商品名称,由各自权利人拥有。
本文档中的信息可能变动,恕不另行通知。
对服务器进行操作之前,请仔细了解以下安全信息,以免造成数据丢失等严重后果。
服务器运行安全注意事项如下:
(1)专业的服务器工程师才能运行该服务器。
(2)请将服务器放在干净、平稳的工作台或地面上进行维护。
(3)运行服务器前,请确保所有线缆均连接正确。
(4)为避免组件表面过热造成人身伤害,请确保设备和内部系统组件冷却后再操作。
(5)当服务器与其他设备上下叠加安装在机柜中时,请确保两个设备之间留出垂直方向2mm以上的空隙。
服务器运行过程中人身安全注意事项如下:
(1)为避免人身伤害或服务器损坏,请务必使用随产品包装附带的电源线缆。
(2)安装人员在安装过程中,如果发现可能导致人身受到伤害或设备受到损坏时,应当立即终止操作,向项目负责人进行报告,并采取行之有效的保护措施。
(3)禁止在雷雨天气进行操作,包括但不限于搬运设备、安装机柜、安装电源线等。
(4)搬运设备时,不能超过当地法律或法规所允许单人搬运的最大重量。要充分考虑安装人员当时的身体状况,务必不能超越安装人员所能承受的重量。
为避免设备损坏,操作服务器时,还需注意以下事项:
(1)服务器必须安装在标准19英寸机柜中。
(2)机柜的支撑脚要完全触地,且机柜的全部重量应由支撑脚承担。
(3)当有多个机柜时,请将机柜连接在一起。
(4)请做好机柜安装的部署工作,将最重的设备安装在机柜底部。安装顺序为从机柜底部到顶部,即优先安装最重的设备。
(5)将服务器安装到机柜或从机柜中拉出时(尤其当服务器脱离滑道时),要求四个人协同工作,以平稳抬起服务器。当安装位置高于胸部时,则可能需第五个人帮助调整服务器的方位。
(6)每次只能从机柜中拉出一台设备,否则会导致机柜不稳固。
(7)将服务器从机柜中拉出或推入前,请确保机柜稳固。
(8)为确保充分散热,请在未使用的机柜位置安装假面板。
人体或其它导体释放的静电可能会损坏主板和对静电敏感的部件,由静电造成的损坏会缩短主板和部件的使用寿命。为避免静电损害,请注意以下事项:
(1)在运输和存储设备时,请将部件装入防静电包装中。
(2)将静电敏感部件送达不受静电影响的工作区前,请将它们放在防静电包装中保管。
(3)先将部件放置在防静电工作台上,然后再将其从防静电包装中取出。
(4)在没有防静电措施的情况下,请勿触摸组件上的插针、线缆和电路元器件等敏感元件。
在取放或安装部件时,用户可采取以下一种或多种接地方法以防止静电释放:
(1)佩戴防静电腕带,并将腕带的另一端良好接地。请将腕带紧贴皮肤,且确保其能够灵活伸缩。
(2)在工作区内,请穿上防静电服和防静电鞋,并佩戴防静电手套。
(3)请使用导电的现场维修工具。
(4)请使用防静电的可折叠工具垫和便携式现场维修工具包。
故障处理是指利用合理的方法,逐步找出故障原因并解决。其指导思想是将由故障可能的原因所构成的一个大集合缩减(或隔离)成若干个小的子集,使问题的复杂度迅速下降,最终找到问题的根本原因,并采取合适的措施进行排除。详细的故障处理流程如图3.1示。

图3.1故障处理流程图
对故障处理流程作详细说明,具体如表3‑1。
表3‑1故障处理流程说明
|
步骤 |
说明 |
|
故障处理前准备工作 |
准备故障诊断和处理所需的软硬件工具和相关手册。详细信息请参见第4章:故障诊断前的准备工作。 |
|
故障信息收集 |
收集故障现场信息,如现象描述、设备型号、操作系统及具体操作等。针对具体问题请联系技术支持,判断收集哪些类型的现场信息。 收集有助于故障诊断定位的相关日志信息。详细信息请参见第5章:收集信息。 |
|
判断故障是否与产品相关 |
判断故障是否与产品相关。 如果是与产品相关的故障问题,请深入定位故障原因。 如果是与产品无关的故障问题,即上层业务软件或操作系统产生的故障,建议优先联系业务软件或操作系统供应商处理。 |
|
故障定位与诊断 |
基于收集到的故障信息,采用合适的故障定位方法找到故障根因。详细信息请参见第6章:诊断和故障定位。 |
|
故障处理 |
根据故障根因,确定并实施故障排除措施。具体故障问题的处理建议仍参见第6章:诊断和故障定位。 |
|
联系售后工程师 |
如果在故障处理过程中遇到难以确定或解决的问题,通过指导文档依旧无法解决,请联系技术工程师协助处理。 |
|
故障处理相关资源 |
故障处理过程中可能需要诊断工具或版本升级,可根据具体需求获取如下相关资源: 版本升级相关信息请参见第7章:版本升级; 故障处理过程中可能用到的软件和配置工具请参见第4章:故障诊断前准备工作; 故障诊断过程中可能用到的相关资源请参见11故障诊断相关资源。 |
在开始故障诊断前,请做好相关准备工作。
Ø 熟悉服务器产品知识;阅读产品配套资料,比如产品用户指南。
Ø 熟悉服务器上的安全标识。
Ø 熟悉服务器硬件架构。
Ø 熟悉服务器前后面板指示灯。
Ø 熟悉服务器上运行的系统。
Ø 熟悉服务器正常运行的物理环境要求。
Ø 熟悉硬件的常用操作,如上下电、部件更换。
Ø 熟悉软件的常用操作,如日志收集、固件升级。
Ø 熟悉维护服务器的流程。
Ø 熟悉服务器的操作系统兼容性、部件兼容性。
所需的远程维护工具如表4‑1所示。
表4‑1远程维护工具
|
工具简介 |
|
|
Xshell |
第三方远程访问工具,用于远程登录操作系统及查看串口信息等。 |
|
Ipmitool |
Ipmitool提供一个简单的命令行界面,可独立于操作系统管理系统硬件组件,对系统运行情况进行管理和监视。 |
所需的RAID卡配置工具如表4‑2所示。
表4‑2 RAID卡工具
|
工具名称 |
支持的存储卡 |
工具简介 |
|
storcli64 |
存储控制器型号: 9361-8i、9560-8i、9560-16i |
LSI存储控制卡操作系统下的命令行管理工具。包括存储卡配置信息获取、RAID盘的创建与删除、日志收集等 |
服务器日常维护所使用的硬件工具,如表4‑3所示。
表4‑3 硬件工具
|
工具名称 |
工具作用 |
|
螺丝刀 |
拆卸服务器机箱、挡片等部位的螺丝 |
|
万用表 |
检查主板电路等 |
|
防静电手套&衣服 |
防止损坏服务器 |
|
串口线 |
访问串口,定位问题 |
|
显示器 |
故障排查时,实时显示服务器运行界面 |
|
示波器 |
测量电压和时序 |
服务器发生故障,需要收集日志信息进行故障诊断。请在故障发生后的第一时间进行数据收集,保证数据原始性。主要包括基本信息、操作系统日志、BMC日志等。
在客户请求故障处理前,应收集基本信息。基本信息收集项如表5‑1所示。其中:必填通用信息,同时选填RAID卡信息与网卡信息。
表5‑1基本信息收集表
|
分类 |
项目 |
信息 |
填写说明 |
|
通 用 信 息 |
客户名称 |
|
填写客户名称 |
|
机型名称 |
|
填写机型信息 |
|
|
产品序列号 |
|
即产品SN号 |
|
|
OS版本 |
|
根据具体问题,判断是否需确认OS版本 |
|
|
BMC版本 |
|
确认BMC版本 |
|
|
BIOS版本 |
|
确认BIOS版本 |
|
|
问题名称 |
|
一句话描述问题,xx机型xx问题 |
|
|
问题详述 |
|
描述问题的详细故障现象; 出现问题时,机器运行的业务 |
|
|
故障前动作 |
|
如修改RAID配置、修改网络配置等 |
|
|
故障后操作、结果 |
|
如更换RAID卡后,故障未解决等; 更换网卡后,故障未解决等 |
|
|
发生时间 |
|
故障初次报修时间和历次报修记录 |
|
|
故障概率 |
|
问题的故障概率: 同批次21台机器出现1台,填写1/21; 故障频次: 如某台此故障出现3次,每次间隔1天 |
|
|
RAID 卡 信 息 |
RAID卡类型 |
|
RAID卡控制器型号 |
|
RAID级别 |
|
多少块硬盘组了什么级别的RAID |
|
|
RAID卡固件版本 |
|
RAID卡FW 版本 |
|
|
RAID卡驱动版本 |
|
RAID卡驱动信息 |
|
|
RAID卡日志收集 |
|
RAID卡日志 |
|
|
背板型号 |
|
SAS直通背板/Expander背板 |
|
|
硬盘配置 |
|
硬盘型号、数量、安装位置 |
|
|
硬盘固件版本 |
|
硬盘FW版本 |
|
|
硬盘日志收集 |
|
硬盘日志 |
|
|
网 卡 信 息 |
网卡类型 |
|
板载网卡/外插网卡/OCP |
|
固件版本 |
|
网卡FW 版本 |
|
|
驱动版本 |
|
网卡驱动信息 |
|
|
网卡日志收集 |
|
网卡日志 |
服务器运行过程中的所有事件(包括报错),在操作日志系统中均有记录。因此,收集操作系统日志,有助于研发人员进行Debug。本节收集操作系统日志,将以Windows系统日志和Linux系统日志为例。
在Windows系统下,针对是否有蓝屏现象,需分情况讨论。
(1)无蓝屏现象时,请执行以下操作:
①在操作系统下单击【计算机/管理】菜单项,打开服务器管理器;
②单击【工具/事件查看器】菜单项,打开事件查看器;
③单击【Windows日志/系统/将所有事件另存为】菜单项,导出并保存日志文件。
(2)有蓝屏现象时,请执行以下操作:
①截屏或拍照保存蓝屏错误代码信息;
②重启后收集“C:\WINDOWS\Minidump\”路径下的全部文件。
在Linux系统下直接收集日志。
主要涉及:/var/log目录下的日志。具体日志文件名称、文件对应信息与文件收集指令见表5‑2。
表5‑2 linux系统下日志收集指令
|
文件名称 |
收集指令 |
指令含义 |
|
/var/log/secure |
cp /var/log/secure* |
安全日志 |
|
/var/log/mcelog |
cp /var/log/mcelog* |
定位MCE错误需要的日志信息 |
|
/var/log/message |
cp /var/log/message* |
常规系统日志文件 |
|
/var/log/cron |
cp /var/log/cron* |
定制任务日志文件 |
|
/var/log/boot.log |
cp /var/log/boot.log |
本次启动日志,log格式 |
|
/var/log/boot.msg |
cp /var/log/boot.msg |
本次启动日志,msg格式 |
|
/var/log/boot.omsg |
cp /var/log/boot.omsg |
启动日志(本次启动的前一次过程日志) |
综上,5.2.1节和5.2.2节为Windows、Linux系统下系统的日志收集方法。而其余系统的日志收集方法,请咨询技术支持。
BMC(Baseboard Management Controller,全称基板管理控制器),是独立于系统之外的小型操作系统,负责服务器的硬件状态管理、操作系统管理、健康状态管理、功耗管理等核心功能。
BMC日志包括:①BMC常规信息;②BMC SEL日志(System Event Log,全称系统事件日志);③BMC黑匣子日志。
BMC常规信息包括:BMC版本、BIOS版本、时间、SDR、CPLD版本信息等。
BMC SEL日志(System Event Log),全称系统事件日志,下文系统事件日志均以SEL日志表示。
SEL日志记录主要设备的状态变化,传感器的历史变化以及规范定义的标准事件。SEL日志的功能特性如下:
最多支持3639个条目。
支持循环模式,且循环模式为默认模式。当SEL已满时,最旧的日志将被丢弃,新产生的日志被保留。
SEL记录方式设置为循环存储模式时,SEL记录存满后会自动滑动记录新的日志和丢弃最早记录的日志;
SEL记录方式设置为线性存储模式时,SEL记录存满后则无法再继续记录日志。
支持通过BMC WEB或IPMI CMD导出。
支持通过SNMPTrap、Syslog通知事件到远程客户端。
SEL日志记录遵循IPMI规范,当IPMI标准事件被触发后,SEL日志就会被记录。SEL日志按照日志输出内容,可细分为:阈值型、通用型和传感器特定型。不同事件类型如表5‑3所示。
表5‑3不同事件日志类型
|
类型 |
描述 |
事件举例 |
|
阈值型 |
传感器会设定一定的阈值,根据传感器当前读值与阈值比较,触发日志告警。例如:温度、电压,风扇转速等传感器。 |
传感器:所有阈值类传感器 事件:根据当前传感器读数与阈值比较,会有以下6种事件: Upper NonRecoverable Threshold Upper Critical Threshold Upper NonCritical Threshold Lower None Recoverable Threshold Lower Critical Threshold Lower None Critical Threshold |
|
通用型 |
表示一些和部件类型无关的通用状态型传感器日志告警。例如在位、拔插、可预测性故障。 |
传感器:风扇状态、ME状态等 事件:根据当前传感器状态码,有以下4种事件: State Deasserted State Asserted Predictive Failure deasserted Predictive Failure asserted |
|
传感器特定型 |
特定类型传感器的离散量,指示离散状态信息特定于传感器类型。例如:CPU状态、内存状态、硬盘状态,PCIE卡状态等传感器。 |
传感器:CPU状态 事件:根据当前传感器状态码,有以下13种事件: IERR Thermal Trip FRB1/BIST failure FRB1/Hang in POST failure FRB3/Processor Start up/Initialization failure Configuration Error SMBIOS ‘Uncorrectable CPU-complex Error’ Processor presence detected Processor disabled Terminator Automatically Throttled Machine Check Exception Correctable Machine CheckError |
以上是关于BMC SEL日志的基本说明。而SEL日志的收集,可通过BMC WEB页面或Ipmitool工具实现。
(1)通过BMC WEB获取SEL日志
通过BMC IP登录BMC WEB UI。导航至“日志->日志查询”,此页面显示所有基于传感器的日志,用户可以配置事件类型、事件发生时间段参数,对系统事件日志进行过滤。如图5.1所示。
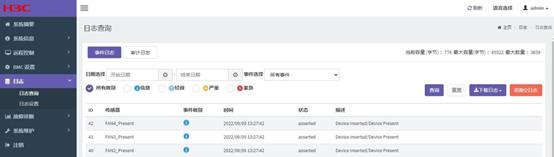
图5.1 BMC WEB获取SEL日志界面
SEL日志中不同ID对应的信息如表5‑4所示。
表5‑4 SEL日志中不同ID信息
|
ID |
SEL中的事件ID |
|
传感器 |
传感器名称,可通过ipmitool sdr elist查看该设备上所有传感器名称 |
|
事件级别 |
事件的紧急程度: 轻微、严重、紧急 |
|
时间 |
事件生成时间 |
|
状态 |
当前状态 |
|
描述 |
事件详细信息 |
日志下载过程中,相关步骤如表5‑5所示。
表5‑5日志下载相关步骤含义
|
参数 |
描述 |
|
查询 |
选择事件类型、传感器和起止日期进行过滤搜索 |
|
动作 |
用过滤器选项(事件类型、传感器名称、起止时间),查看设备中记录的特定事件 |
|
重置 |
清空筛选条件 |
|
下载日志 |
下载事件日志到本地 |
|
清空日志 |
该选项将删除所有现有传感器日志记录并新增条‘sel被清除’的日志 |
(2)通过ipmitool获取SEL日志
系统下使用命令:“ipmitool sel list”,可列出当前设备上所有传感器的历史事件记录。显示的日志信息包含ID,日期,时间,传感器名称,描述和状态。如图5.2所示。
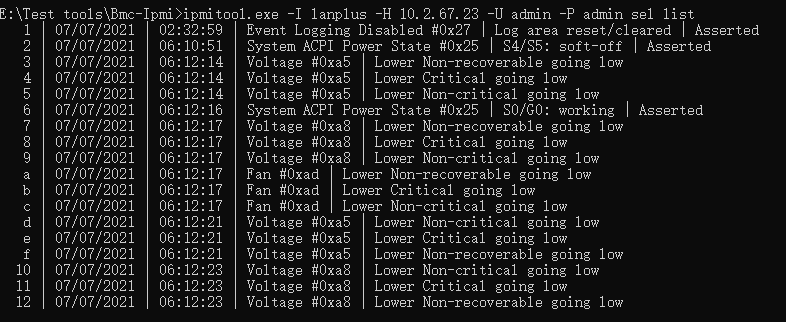
图5.2 ipmitool指令界面
附:SEL日志含义分析实例
①开机实例日志:6 | 07/07/2021 | 06:12:16 | System ACPI Power State #0x25 | S0/G0: working | Asserted
②温度过高日志告警实例:21 | 07/07/2021 | 06:27:08 | Temperature #0x18 | Upper Non-critical going high
③PCIE 故障实例:22 | 07/07/2021 | 08:25:10 | Critical Interrupt #0xe4| Bus Correctable error
BMC黑匣子日志包括:BMC记录截屏信息、BMC报错日志和监控信息、BMC配置信息和状态信息、BMC网络及线程信息。
(2)通过BMC WEB收集
通过BMC IP登录BMC WEB UI。导航至“故障诊断->服务器黑匣子”,此页面下载服务器异常前的BMC调试信息,以供分析使用。如图5.3所示。
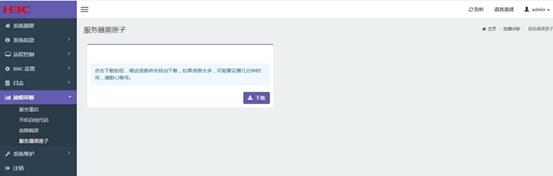
图5.3服务器黑匣子日志收集界面
具体文件包含义如表5‑6所示。
表5‑6黑匣子日志文件包含义
|
文件包 |
描述 |
|
capturescreen.tar |
收集BMC记录截屏信息 |
|
bmcloginfo.tar |
收集BMC报错日志和监控信息 |
|
bmcstatusinfo.tar |
收集BMC配置信息和状态信息 |
|
bmcsysteminfo.tar |
收集BMC网络及线程信息 |
Ø 工具名称
storcli
Ø 工具简介
服务器出现与RAID卡相关的故障时,需搜集RAID卡的日志与状态信息,以供后台分析。storcli工具针对RAID卡进行日志收集,在不同操作系统下有不同版本,可直接在系统下使用。
同时,针对系统死机、崩溃,无法在系统下搜集RAID卡日志的情况,storcli工具同样提供UEFI版本。此时,可将storcli工具拷贝至USB设备中,然后在BIOS下进入UEFI环境进行日志收集。
Ø 使用方法
控制器详细信息:storcli/c0 show all
背板详细信息:storcli /c0/eall show all
硬盘详细信息:storcli /c0/eall/sall show all
查看RAID组列的详细信息:storcli /c0/vall show all
查看RAID卡FirmwareTermLog:storcli /c0 show termlog
查看RAID卡alilog:storcli /c0 show alilog
查看链路的Phyerrorcounter(适用于LSI的RAID控制器):storcli /cx/pall show all
查看背板端的Phyerrorcounter(只适用于使用LSI Expander芯片的背板,我司全系产品所使用的Expander背板均采用LSI Expander芯片):storcli /cx/eall show phyerrorcounters
查看硬盘端的Phyerrorcounter(适用于SAS接口硬盘,SATA接口硬盘提示不支持此操作):storcli /cx/eall/sall show phyerrorcounters
综上,将以上日志搜集命令导出到文件保存,对RAID卡相关问题的分析具有重要的意义。许多问题可以通过日志追踪操作过程以及问题原因。在处理客户故障时,如果怀疑问题与RAID卡有关,建议在条件允许的情况下优先搜集日志信息。
诊断须知:
所有操作必须获得客户出具的书面授权;
所有操作必须在数据已备份或迁移,确保数据无丢失风险的情况下执行。
在进行故障诊断时,请遵循以下原则:
先诊断外部,后诊断内部
诊断故障时,先排查外部环境因素,如电源中断、对接设备故障等;然后再诊断设备内部因素,如硬件安装是否到位、操作系统运行是否正常。
先诊断整体,后诊断局部
诊断故障时,先根据服务器的健康状态指示灯或登录BMC Web界面,了解服务器的整体健康状态,再结合故障现象和相关日志进一步定位具体的故障点。对于硬件无法识别、带宽降速等问题,先整体梳理硬件拓扑,列出所有可能的故障点,再确定方案,逐一排查。
先诊断主要问题,后诊断次要问题
诊断故障时,优先定位客户关注且影响严重的问题;再诊断影响较小的问题。
先诊断高级别告警,后诊断低级别告警
分析告警时,首先分析高级别告警,如紧急或严重告警;然后再分析低级别告警,如轻微告警。
(1)提前做好故障处理前的准备工作,包括:
服务器工作环境确认。确保服务器供电充足,且物理环境满足设备稳定运行要求,包括空间和通风、温度、湿度、洁净度、高度和接地等。物理环境的具体要求,请参见产品用户指南。
移除服务器上的第三方外接设备,包括光驱、U盘、移动硬盘等。
参考4.2准备软件工具和4.3准备硬件工具准备好故障诊断所需的工具和软件。
(2)参考5收集故障相关信息收集故障相关的日志信息,并记录故障发生的时间、频率、报错截屏等信息。
当故障现象或故障原因不明确时,建议按通用诊断流程图进行诊断,详见图6.1。

图6.1通用故障诊断流程图
如上图,在整个故障处理过程中,主要涉及:开机故障诊断流程、POST故障诊断流程、OS安装指南、RAID卡/硬盘/虚拟盘故障诊断流程、操作系统引导故障诊断流程、内存故障诊断流程、网卡故障诊断流程等。
对通用故障诊断流程作详细说明,具体如表6‑1。
表6‑1故障处理流程说明
|
步骤 |
说明 |
|
收集BMC日志 |
在进行故障诊断前,优先收集BMC日志作为补充材料,以便后续充分地进行故障分析,见图6.2 |
|
判断是否正常开机 |
通过开机故障诊断流程判断,见图6.3 |
|
判断是否正常进入POST阶段 |
通过POST阶段故障诊断流程判断,见图6.4 |
|
判断OS是否正常引导 |
通过OS引导故障诊断流程判断,见图6.5 |
|
判断是否正常出现启动引导项 |
|
|
判断OS下内存是否正常 |
通过内存故障诊断流程判断,见图6.9 |
|
判断OS下网络是否正常 |
通过网卡故障诊断流程判断,见图6.10 |
|
判断问题是否均已经解决 |
若问题还未解决,需联系售后工程师 |
同时,在故障处理之初,可通过查阅BMC告警信息,来确认是否是部件故障,具体见6.4节。后续可通过更换故障件的方式,解决问题。详见图6.2。

图6.2 BMC告警信息诊断流程图
如上图所示,在故障处理之初,可通过BMC事件日志、Health指示灯来判定:BMC是否出现告警。
根据BMC事件日志,需进一步确认:是否可以获取故障信息,从而判定到底由何部件引起故障。后续可通过及时更换部件,确认问题是否解决。
若BMC告警信息无法确认故障原因,还可通过health指示灯进行辅助判断。
若依据BMC告警信息无法解决问题,可进一步参考开机故障诊断流程。详见图6.3。

图6.3开机故障诊断流程图
如上图所示,若通过BMC告警信息无法排除故障,可进一步参考开机故障诊断流程。
在上电后,优先判断系统电源指示灯的情况:若此时灯灭,可尝试重新插拔电源线、更换电源,从而查看问题是否解决;若此时绿色常亮或闪烁,说明服务器正常开机;若此时亮黄灯,需进一步确认Health指示灯情况,必要时需联系售后工程师。
若服务器开机hang在POST阶段,可进一步参考POST故障流程。详见图6.4。

图6.4 POST阶段故障诊断流程图
如上图所示,若服务器在POST阶段hang机,可通过对比POST阶段代码说明,推断引起故障的具体原因,并尝试通过更换对应部件解决问题。若通过对比POST阶段代码无法查明具体原因,需进一步联系售后工程师。
若怀疑故障与操作系统引导有关,可进一步参考操作系统引导故障诊断流程。详见图6.5。
图6.5操作系统引导故障诊断流程图
如上图所示,若服务器顺利通过POST阶段,但在OS启动与引导阶段出问题,需做如下确认:系统盘是否无松动,紧密连接;BIOS中系统引导顺序是否正确。若问题仍存在,可考虑重新安装操作系统解决。若问题仍旧存在,可进一步联系售后工程师。
若怀疑是故障与RAID卡有关,可进一步参考RAID卡故障诊断流程。详见图6.6。

图6.6 RAID卡故障诊断流程图
如上图所示,若发现RAID卡报错或出现异常,可通过重新插拔、更换的方式尝试解决。RAID卡报错可能与RAID组建、硬盘降级、掉线等因素相关,具体可参照下文:物理硬盘故障诊断流程、虚拟硬盘故障诊断流程。
若有需要,可进一步联系售后工程师。
若怀疑故障与物理硬盘有关,可进一步参考物理硬盘故障流程。详见图6.7。

图6.7物理硬盘故障诊断流程图
如上图所示,若发现物理硬盘报错或出现异常,可通过重新插拔、更换硬盘的方式尝试解决。同时,可结合收集到的硬盘日志、OS日志、BMC日志,判定业务运行过程中的问题。
若有需要,可进一步联系售后工程师。
若怀疑故障与虚拟硬盘有关,可进一步参考虚拟硬盘故障流程。详见图6.8。
图6.8虚拟硬盘故障诊断流程图
如上图所示,若发现虚拟硬盘出现异常,需确认虚拟硬盘状态为Offline还是Degraded,是否可通过手动恢复到Online状态。同时,若发现硬盘出现故障,需对故障硬盘进行替换,再重新创建虚拟盘,观察虚拟盘是否为Optimal状态。
若有需要,可进一步联系售后工程师。

图6.9内存故障诊断流程图
如上图所示,若发现内存报错或出现异常,可通过重新插拔、更换内存或主板等部件的方式解决。
若有需要,可进一步联系售后工程师。
若怀疑是网卡出现问题,可进一步参考网卡故障流程。详见图6.10。

图6.10网卡故障诊断流程图
如上图所示,若发现网卡报错或出现异常,可通过重新插拔、更换网卡的方式解决。
在进行故障处理与分析时,需优先确认BIOS或OS下是否能识别到网卡。若可以识别,再判断到底是何原因引起:是否修改了网络或网卡配置;是否升级了系统内核、网卡固件或驱动;是否更改了服务器硬件配置等。
若有需要,可进一步联系售后工程师。
用户可通过BMC告警信息,进行详细地诊断与故障定位。其中,告警信息涉及:Chassis告警说明、CPU告警说明、内存告警说明、硬盘告警说明、电源告警说明、风扇告警说明等。
下文是BMC记录的各类服务器告警类型,并从告警含义、系统影响、可能原因以及故障建议等方面进行说明,以便技术支持工程师和维护工程师查阅,同时形成详细而完备的文档供用户使用参考。
|
(1)进风口温度过高严重告警 (Inlet Temp) |
|
|
告警解释 |
l 告警描述:Upper Critical l 当进风口温度传感器检测到进风口温度高于严重告警阈值时,产生此告警 l 产生此告警的传感器名称为:Inlet Temp |
|
告警属性 |
l 告警级别:严重 l 可自动清除:是 |
|
对系统的影响 |
l 进风口温度过高会影响设备各器件的性能,出现运行不稳定的情况 l 如果进风口温度没有下降,该告警会一直存在,将导致系统温度进一步升高,产生更高级别的告警 |
|
可能原因 |
l 环境温度过高 l 进风口堵塞 |
|
处理步骤 |
① 将服务器运行环境温度控制在其正常工作温度范围内,数分钟后查看告警是否消失 ② 检查服务器进风口是否堵塞,若堵塞则清理进风口 ③ 检查服务器之间的空槽位或间隔是否已加假面板或挡板,为服务器之间的空槽位或间隔安装假面板或挡板,检查告警是否消失 ④ 联系厂商技术支持工程师处理 |
|
(2)进风口温度过高紧急告警 (Inlet Temp) |
|
|
告警解释 |
l 告警描述: Upper Non-Recoverable l 当进风口温度传感器检测到进风口温度高于紧急告警阈值时,产生此告警 l 产生此告警的传感器名称为:Inlet Temp |
|
告警属性 |
l 告警级别:严重 l 可自动清除:是 |
|
对系统的影响 |
l 进风口温度过高会影响设备各器件的性能,出现运行不稳定的情况 l 如果进风口温度没有下降,该告警会一直存在,将导致系统温度进一步升高,产生更高级别的告警 |
|
可能原因 |
l 环境温度过高 l 进风口堵塞 |
|
处理步骤 |
① 将服务器运行环境温度控制在其正常工作温度范围内,数分钟后查看告警是否消失 ② 检查服务器进风口是否堵塞,若堵塞则清理进风口 ③ 检查服务器之间的空槽位或间隔是否已加假面板或挡板,为服务器之间的空槽位或间隔安装假面板或挡板,检查告警是否消失 ④ 联系厂商技术支持工程师处理 |
|
(3)出风口温度过高严重告警 (Outlet Temp) |
|
|
告警解释 |
l 告警描述: Upper Critical l 当出风口温度传感器检测到进风口温度高于严重告警阈值时,产生此告警 l 产生此告警的传感器名称为:Outlet Temp |
|
告警属性 |
l 告警级别:严重 l 可自动清除:是 |
|
对系统的影响 |
l 出风口温度过高会影响设备各器件的性能,出现运行不稳定的情况 l 如果出风口温度没有下降,该告警会一直存在,将导致系统温度进一步升高,产生更高级别的告警 |
|
可能原因 |
l 环境温度过高 l 进风口堵塞 |
|
处理步骤 |
① 将服务器运行环境温度控制在其正常工作温度范围内,数分钟后查看告警是否消失 ② 检查服务器出风口是否堵塞,若堵塞则清理出风口 ③ 检查服务器之间的空槽位或间隔是否已加假面板或挡板,为服务器之间的空槽位或间隔安装假面板或挡板,检查告警是否消失 ④ 联系厂商技术支持工程师处理 |
|
(4)出风口温度过高紧急告警 (Outlet Temp) |
|
|
告警解释 |
l 告警描述: Upper Non-Recoverable l 当出风口温度传感器检测到进风口温度高于紧急告警阈值时,产生此告警 l 产生此告警的传感器名称为:Outlet Temp |
|
告警属性 |
l 告警级别:严重 l 可自动清除:是 |
|
对系统的影响 |
l 当出风口温度高于紧急告警阈值时,设备运行在超高温环境下,会严重降低设备各器件性能,影响设备寿命,增加能耗,影响业务,甚至发生宕机 |
|
可能原因 |
l 环境温度过高 l 出风口堵塞 |
|
处理步骤 |
① 将服务器运行环境温度控制在其正常工作温度范围内,数分钟后查看告警是否消失 ② 检查服务器出风口是否堵塞,若堵塞则清理出风口 ③ 检查服务器之间的空槽位或间隔是否已加假面板或挡板,为服务器之间的空槽位或间隔安装假面板或挡板,检查告警是否消失 ④ 联系厂商技术支持工程师处理 |
|
(1)CPU 温度过高严重告警 (CPUN Temp) |
|
|
告警解释 |
l 告警描述: Upper Critical l 当传感器检测到 CPU 温度高于严重告警阈值时,产生此告警 l 产生此告警的传感器名称为:CPUN Temp (N 表示服务器 CPU 编号) |
|
告警属性 |
l 告警级别:严重 l 可自动清除:是 |
|
对系统的影响 |
l CPU 温度过高,会导致 CPU 运行不稳定,如果告警一直存在,设备会自动关机或重启,导致业务中断,数据丢失 |
|
可能原因 |
l 环境温度过高 l 进风口堵塞 l 出风口堵塞 l 风扇模块故障 l 散热器接触不良 l CPU 业务量过大 |
|
处理步骤 |
① 将服务器运行温度控制在其正常工作范围内,数分钟后查看告警是否消失 ② 检查服务器进风口和出风口是否存在堵塞,若存在堵塞则清理 ③ 检查服务器内部是否正确安装导风罩,安装导风罩,检查告警是否消失 ④ 检查服务器之间的空槽位或间隔是否已加假面板或挡板,为服务器之间的空槽位或间隔安装假面板或挡板,检查告警是否消失 ⑤ 检查CPU使用率是否过大,若业务量过大则关闭非紧急业务降低 CPU 负载 ⑥ 检查风扇模块是否存在告警,若存在告警则插拔或更换告警的风扇模块 ⑦ 关机,打开机箱检查散热器是否正常,若有接触不良等情况,则重新安装散热器后开机,数分钟后查看告警是否消失 ⑧ 联系厂商技术支持工程师处理 |
|
(2)CPU 温度过高紧急告警 (CPUN Temp) |
|
|
告警解释 |
l 告警描述: Upper Non-Recoverable l 当传感器检测到 CPU 温度高于紧急告警阈值时,产生此告警 l 产生此告警的传感器名称为:CPUN Temp (N 表示服务器 CPU 编号) |
|
告警属性 |
l 告警级别:严重 l 可自动清除:是 |
|
对系统的影响 |
l CPU 产生温度过高紧急告警时,系统将会启动自我保护,强制主板下电,业务终止,未保存数据将会丢失 |
|
可能原因 |
l 环境温度过高 l 进风口堵塞 l 出风口堵塞 l 风扇模块故障 l 散热器接触不良 l CPU 业务量过大 |
|
处理步骤 |
① 将服务器运行温度控制在其正常工作范围内,数分钟后查看告警是否消失 ② 检查服务器进风口和出风口是否存在堵塞,若存在堵塞则清理 ③ 检查服务器内部是否正确安装导风罩,安装导风罩,检查告警是否消失 ④ 检查服务器之间的空槽位或间隔是否已加假面板或挡板,为服务器之间的空槽位或间隔安装假面板或挡板,检查告警是否消失 ⑤ 检查 CPU 使用率是否过大,若业务量过大则关闭非紧急业务降低 CPU 负载 ⑥ 检查风扇模块是否存在告警,若存在告警则插拔或更换告警的风扇模块 ⑦ 关机,打开机箱检查散热器是否正常,若有接触不良等情况,则重新安装散热器后开机,数分钟后查看告警是否消失 ⑧ 联系厂商技术支持工程师处理 |
|
(3)CPU 核心温度过高紧急告警 (CPUN Status) |
|
|
告警解释 |
l 告警描述: Thermal Trip l 当 CPU 核心温度过高时,CPU 主动上报超温信号,产生此告警 l 产生此告警的传感器名称为:CPUN Status (N 表示服务器 CPU 编号) |
|
告警属性 |
l 告警级别:严重 l 可自动清除:是 |
|
对系统的影响 |
l CPU 核心超温时,系统会启动自我保护,强制主板下电,业务终止,未保存数据丢失 |
|
可能原因 |
l 环境温度过高 l 进风口堵塞 l 出风口堵塞 l 风扇模块故障 l 散热器接触不良 l CPU 业务量过大 |
|
处理步骤 |
① 将服务器运行温度控制在其正常工作范围内,数分钟后查看告警是否消失 ② 检查服务器进风口和出风口是否存在堵塞,若存在堵塞则清理 ③ 检查服务器内部是否正确安装导风罩,安装导风罩,检查告警是否消失 ④ 检查服务器之间的空槽位或间隔是否已加假面板或挡板,为服务器之间的空槽位或间隔安装假面板或挡板,检查告警是否消失 ⑤ 检查 CPU 使用率是否过大,若业务量过大则关闭非紧急业务降低 CPU 负载 ⑥ 检查风扇模块是否存在告警,若存在告警则插拔或更换告警的风扇模块 ⑦ 关机,打开机箱检查散热器是否正常,若有接触不良等情况,则重新安装散热器后开机,数分钟后查看告警是否消失 ⑧ 联系厂商技术支持工程师处理 |
|
(4)CPU 占用率过高严重 / 紧急告警 (CPU Cups) |
|
|
告警解释 |
l 告警描述:Upper Critical / Upper Non-Recoverable l CPU 占用率超过设定的严重和紧急告警阈值时,产生此告警 l 产生此告警的传感器名称为:CPU Cups |
|
告警属性 |
l 告警级别:严重 / 紧急 l 可自动清除:是 |
|
对系统的影响 |
l CPU占用率过高可能导致系统无法调度某些进程,影响系统性能 |
|
可能原因 |
l 正在运行的进程过多 l 某个进程占用过多的 CPU 资源 l 服务器被攻击或感染病毒 l CPU 占用率告警阈值设置太低 |
|
处理步骤 |
① 进入 OS 查看是否存在当前不需要运行但占用大量 CPU 资源的任务,结束这种任务,检查告警是否消失 ② 查看 CPU 占用率告警阈值设置是否合理,若太低,重新设置阈值,检查告警是否消失 ③ 联系厂商技术支持工程师处理 |
|
(5)CPU 内部错误紧急告警 (CPUN Status) |
|
|
告警解释 |
l 告警描述: IERR l 当 CPU 出现内部错误时,产生此告警 l 产生此告警的传感器名称为:CPUN Status |
|
告警属性 |
l 告警级别:紧急 l 可自动清除:是 |
|
对系统的影响 |
l CPU 内部错误会使操作系统无法正常运行,业务无法正常进行,造成重启或死机 |
|
可能原因 |
l CPU、内存、主板等硬件故障 l OS 不兼容、逻辑状态异常等软件故障 |
|
处理步骤 |
① 确认服务器是否正确安装当前设备支持的 OS ,安装支持的 OS ,检查告警是否消失 ② 将产生告警的 CPU 与正常 CPU 互换位置,确认故障部件,更换故障的 CPU,检查告警是否消失 ③ 更换主板,检查告警是否消失 ④ 联系厂商技术支持工程师处理 |
|
(6)CPU 自检错误严重告警 (CPUN Status) |
|
|
告警解释 |
l 告警描述: FRB1/BIST failure l 当 CPU 发生自检错误时,产生此告警 l 产生此告警的传感器名称为:CPUN Status (N 表示服务器 CPU 编号) |
|
告警属性 |
l 告警级别:严重 l 可自动清除:是 |
|
对系统的影响 |
l CPU 自检错误会导致系统无法正常启动,或启动后业务无法正常运行 |
|
可能原因 |
l CPU 故障 l 主板故障 |
|
处理步骤 |
① 将服务器安全下电并重新插拔电源线后上电启动,检查告警是否消失 ② 更换 CPU ,检查告警是否消失 ③ 更换主板,检查告警是否消失 ④ 联系厂商技术支持工程师处理 |
|
(7)CPU 配置错误严重告警 (CPUN Status) |
|
|
告警解释 |
l 告警描述: Configuration Error DMI l 当 CPU 出现硬件可恢复错误、非致命错误、致命错误时,产生此告警 l 产生此告警的传感器名称为:CPUN Status (N 表示服务器 CPU 编号) |
|
告警属性 |
l 告警级别:严重 l 可自动清除:是 |
|
对系统的影响 |
l CPU 配置错误会导致系统无法正常运行 |
|
可能原因 |
l CPU 故障 l CPU 所属内存故障 l CPU 所属 PCIe 设备故障 |
|
处理步骤 |
① 将服务器安全重启,检查告警是否消失 ② 更换CPU ,检查告警是否消失 ③ 联系厂商技术支持工程师处理 |
|
(1)内存温度过高严重告警 (CPUN DIMM Temp) |
|
|
告警解释 |
l 告警描述: Upper Critical l 当检测到内存温度高于严重告警阈值时,产生此告警 l 产生此告警的传感器名称为:CPUN DIMM Temp (N 表示服务器 CPU 编号) |
|
告警属性 |
l 告警级别:严重 l 可自动清除:是 |
|
对系统的影响 |
l 内存温度过高会对系统性能产生较大影响,导致系统运行不稳定,无法正常工作等;持续存在此告警将触发更高级别的告警 |
|
可能原因 |
l 环境温度过高 l 进风口堵塞 l 出风口堵塞 l 风扇模块故障 l 散热器接触不良 l CPU 业务量过大 |
|
处理步骤 |
① 将服务器运行温度控制在其正常工作范围内,数分钟后查看告警是否消失 ② 检查服务器进风口和出风口是否存在堵塞,若存在堵塞则清理 ③ 检查服务器内部是否正确安装导风罩,安装导风罩,检查告警是否消失 ④ 检查服务器之间的空槽位或间隔是否已加假面板或挡板,为服务器之间的空槽位或间隔安装假面板或挡板,检查告警是否消失 ⑤ 检查系统业务量是否过大,若业务量过大则关闭非紧急业务降低系统压力 ⑥ 检查风扇模块是否存在告警,若存在告警则插拔或更换告警的风扇模块 ⑦ 联系厂商技术支持工程师处理 |
|
(2)内存温度过高紧急告警 (CPUN DIMM Temp) |
|
|
告警解释 |
l 告警描述: Upper Non-Recoverable l 当检测到内存温度高于紧急告警阈值时,产生此告警 l 产生此告警的传感器名称为:CPUN DIMM Temp (N 表示服务器 CPU 编号) |
|
告警属性 |
l 告警级别:紧急 l 可自动清除:是 |
|
对系统的影响 |
l 内存温度过高会对系统性能产生较大影响,导致系统运行不稳定,无法正常工作,重启宕机等 |
|
可能原因 |
l 环境温度过高 l 进风口堵塞 l 出风口堵塞 l 风扇模块故障 l 系统业务量过大 |
|
处理步骤 |
① 将服务器运行温度控制在其正常工作范围内,数分钟后查看告警是否消失 ② 检查服务器进风口和出风口是否存在堵塞,若存在堵塞则清理 ③ 检查服务器内部是否正确安装导风罩,安装导风罩,检查告警是否消失 ④ 检查服务器之间的空槽位或间隔是否已加假面板或挡板,为服务器之间的空槽位或间隔安装假面板或挡板,检查告警是否消失 ⑤ 检查系统业务量是否过大,若业务量过大则关闭非紧急业务降低系统压力 ⑥ 检查风扇模块是否存在告警,若存在告警则插拔或更换告警的风扇模块 ⑦ 联系厂商技术支持工程师处理 |
|
(3)内存不可纠正错误紧急告警 (CPUN ChannelNum DimmNum Status) |
|
|
告警解释 |
l 告警描述: Uncorrectable ECC / other uncorrectable memory error l 当内存发生不可纠正错误时,产生此告警 l 产生此告警的传感器名称为:CPUN CD Status (N 表示服务器 CPU 编号,C 表示内存 Channel号,D 表示内存 Dimm 号) |
|
告警属性 |
l 告警级别:紧急 l 可自动清除:是 |
|
对系统的影响 |
l 内存发生不可纠正错误时,可能会导致业务中断、系统停止响应或重启 |
|
可能原因 |
l 内存故障 |
|
处理步骤 |
① 重新拔插产生告警的内存,检查告警是否消失 ② 将产生告警的内存与正常内存互换位置,检查告警是否随内存迁移 ③ 更换内存,检查告警是否消失 ④ 更换主板,检查告警是否消失 ⑤ 联系厂商技术支持工程师处理 |
|
(4)内存可纠正错误严重告警 (CPUN ChannelNum DimmNum Status) |
|
|
告警解释 |
l 告警描述: Correctable ECC / other correctable memory error logging limit reached l 当内存发生可纠正错误且可纠正错误日志记录已满时,产生此告警 l 产生此告警的传感器名称为:CPUN CD Status (N 表示服务器 CPU 编号,C 表示内存 Channel号,D 表示内存 Dimm 号) |
|
告警属性 |
l 告警级别:严重 l 可自动清除:是 |
|
对系统的影响 |
l 发生该告警时,内存错误可纠正,通常服务器可以继续正常使用 |
|
可能原因 |
l 内存发生可纠正错误 |
|
处理步骤 |
① 请选择合适的时间和环境更换内存,检查告警是否消失 ② 联系厂商技术支持工程师处理 |
|
(1)硬盘温度过高严重告警 (HDDN Temp) |
|
|
告警解释 |
l 告警描述: Upper Critical l 当检测到硬盘温度高于严重告警阈值时,产生此告警 l 产生此告警的传感器名称为:HDDN Temp (N 表示 HDD 编号) |
|
告警属性 |
l 告警级别:严重 l 可自动清除:是 |
|
对系统的影响 |
l 硬盘温度过高将导致系统读写数据能力降低,进而导致系统性能下降,甚至瘫痪,此告警持续存在将触发更高级别的告警 |
|
可能原因 |
l 环境温度过高 l 进风口堵塞 l 出风口堵塞 l 风扇模块故障 l 数据读写量大 |
|
处理步骤 |
① 将服务器运行温度控制在其正常工作范围内,数分钟后查看告警是否消失 ② 检查服务器进风口和出风口是否存在堵塞,若存在堵塞则清理 ③ 检查服务器内部是否正确安装导风罩,安装导风罩,检查告警是否消失 ④ 检查服务器之间的空槽位或间隔是否已加假面板或挡板,为服务器之间的空槽位或间隔安装假面板或挡板,检查告警是否消失 ⑤ 检查是否存在频繁读写大量数据的非紧急业务,若存在则暂时关闭该业务 ⑥ 检查风扇模块是否存在告警,若存在告警则插拔或更换告警的风扇模块 ⑦ 联系厂商技术支持工程师处理 |
|
(2)硬盘温度过高紧急告警 (HDDN Temp) |
|
|
告警解释 |
l 告警描述: Upper Non-Recoverable l 当检测到硬盘温度高于紧急告警阈值时,产生此告警 l 产生此告警的传感器名称为:HDDN Temp (N 表示 HDD 编号) |
|
告警属性 |
l 告警级别:紧急 l 可自动清除:是 |
|
对系统的影响 |
l 硬盘温度过高会导致系统读写数据能力下降,进而导致系统性能下降,甚至瘫痪 |
|
可能原因 |
l 环境温度过高 l 进风口堵塞 l 出风口堵塞 l 风扇模块故障 l 数据读写量大 |
|
处理步骤 |
① 将服务器运行温度控制在其正常工作范围内,数分钟后查看告警是否消失 ② 检查服务器进风口和出风口是否存在堵塞,若存在堵塞则清理 ③ 检查服务器内部是否正确安装导风罩,安装导风罩,检查告警是否消失 ④ 检查服务器之间的空槽位或间隔是否已加假面板或挡板,为服务器之间的空槽位或间隔安装假面板或挡板,检查告警是否消失 ⑤ 检查是否存在频繁读写大量数据的非紧急业务,若存在则暂时关闭该业务 ⑥ 检查风扇模块是否存在告警,若存在告警则插拔或更换告警的风扇模块 ⑦ 联系厂商技术支持工程师处理 |
|
(3)硬盘故障严重告警 (HDDN Status) |
|
|
告警解释 |
l 告警描述: Hot Plug l 当硬盘被拔出或故障,Raid 阵列故障或异常时,产生此告警 l 产生此告警的传感器名称为:HDDN Status (N 表示 HDD 编号) |
|
告警属性 |
l 告警级别:严重 l 可自动清除:是 |
|
对系统的影响 |
l 当硬盘异常或故障时,会使数据读写异常,导致系统可靠性降低,运行异常 |
|
可能原因 |
l 硬盘被人为拔出 l 硬盘故障 |
|
处理步骤 |
① 检查告警的硬盘是否被拔出,安装硬盘,检查告警是否消失 ② 重新拔插产生告警的硬盘,检查告警是否消失 ③ 更换告警相关的硬盘,检查告警是否消失 ④ 联系厂商技术支持工程师处理 |
|
(4)硬盘生命期临界严重告警 (HDDN Status) |
|
|
告警解释 |
l 告警描述: Reach the life threshold l 当硬盘使用时长到达期限时,产生此告警 l 产生此告警的传感器名称为:HDDN Status (N 表示 HDD 编号) |
|
告警属性 |
l 告警级别:紧急 l 可自动清除:是 |
|
对系统的影响 |
l 硬盘生命时长到达期限会导致数据异常的概率大大提高,使系统可靠性下降,运行异常 |
|
可能原因 |
l 硬盘生命期达到临界 |
|
处理步骤 |
① 做好数据的冗余备份后更换硬盘 ② 联系厂商技术支持工程师处理 |
|
(5)AIC 固态硬盘温度过高严重告警 (AICN Temp) |
|
|
告警解释 |
l 告警描述: Upper Critical l 当检测到硬盘温度高于严重告警阈值时,产生此告警 l 产生此告警的传感器名称为:AICN Temp (N 表示 AIC 硬盘编号) |
|
告警属性 |
l 告警级别:严重 l 可自动清除:是 |
|
对系统的影响 |
l 硬盘温度过高将导致系统读写数据能力降低,进而导致系统性能下降,甚至瘫痪,此告警持续存在将触发更高级别的告警 |
|
可能原因 |
l 环境温度过高 l 进风口堵塞 l 出风口堵塞 l 风扇模块故障 l 数据读写量大 |
|
处理步骤 |
① 将服务器运行温度控制在其正常工作范围内,数分钟后查看告警是否消失 ② 检查服务器进风口和出风口是否存在堵塞,若存在堵塞则清理 ③ 检查服务器内部是否正确安装导风罩,安装导风罩,检查告警是否消失 ④ 检查服务器之间的空槽位或间隔是否已加假面板或挡板,为服务器之间的空槽位或间隔安装假面板或挡板,检查告警是否消失 ⑤ 检查是否存在频繁读写大量数据的非紧急业务,若存在则暂时关闭该业务 ⑥ 检查风扇模块是否存在告警,若存在告警则插拔或更换告警的风扇模块 ⑦ 联系厂商技术支持工程师处理 |
|
(6)AIC 固态硬盘温度过高紧急告警 (AICN Temp) |
|
|
告警解释 |
l 告警描述: Upper Non-Recoverable l 当检测到硬盘温度高于严重告警阈值时,产生此告警 l 产生此告警的传感器名称为:AICN Temp (N 表示 AIC 硬盘编号) |
|
告警属性 |
l 告警级别:紧急 l 可自动清除:是 |
|
对系统的影响 |
l 硬盘温度过高将导致系统读写数据能力降低,进而导致系统性能下降,甚至瘫痪 |
|
可能原因 |
l 环境温度过高 l 进风口堵塞 l 出风口堵塞 l 风扇模块故障 l 数据读写量大 |
|
处理步骤 |
① 将服务器运行温度控制在其正常工作范围内,数分钟后查看告警是否消失 ② 检查服务器进风口和出风口是否存在堵塞,若存在堵塞则清理 ③ 检查服务器内部是否正确安装导风罩,安装导风罩,检查告警是否消失 ④ 检查服务器之间的空槽位或间隔是否已加假面板或挡板,为服务器之间的空槽位或间隔安装假面板或挡板,检查告警是否消失 ⑤ 检查是否存在频繁读写大量数据的非紧急业务,若存在则暂时关闭该业务 ⑥ 检查风扇模块是否存在告警,若存在告警则插拔或更换告警的风扇模块 ⑦ 联系厂商技术支持工程师处理 |
|
(7)M.2 固态硬盘温度过高严重告警 (M2N Temp) |
|
|
告警解释 |
l 告警描述: Upper Critical l 当检测到硬盘温度高于严重告警阈值时,产生此告警 l 产生此告警的传感器名称为:M2N Temp (N 表示 M2 硬盘编号) |
|
告警属性 |
l 告警级别:严重 l 可自动清除:是 |
|
对系统的影响 |
l 硬盘温度过高将导致系统读写数据能力降低,进而导致系统性能下降,甚至瘫痪,此告警持续存在将触发更高级别的告警 |
|
可能原因 |
l 环境温度过高 l 进风口堵塞 l 出风口堵塞 l 风扇模块故障 l 数据读写量大 |
|
处理步骤 |
① 将服务器运行温度控制在其正常工作范围内,数分钟后查看告警是否消失 ② 检查服务器进风口和出风口是否存在堵塞,若存在堵塞则清理 ③ 检查服务器内部是否正确安装导风罩,安装导风罩,检查告警是否消失 ④ 检查服务器之间的空槽位或间隔是否已加假面板或挡板,为服务器之间的空槽位或间隔安装假面板或挡板,检查告警是否消失 ⑤ 检查是否存在频繁读写大量数据的非紧急业务,若存在则暂时关闭该业务 ⑥ 检查风扇模块是否存在告警,若存在告警则插拔或更换告警的风扇模块 ⑦ 联系厂商技术支持工程师处理 |
|
(8)M.2 固态硬盘温度过高紧急告警 (M2N Temp) |
|
|
告警解释 |
l 告警描述: Upper Non-Recoverable l 当检测到硬盘温度高于紧急告警阈值时,产生此告警 l 产生此告警的传感器名称为:AICN Temp (N 表示 M2 硬盘编号) |
|
告警属性 |
l 告警级别:紧急 l 可自动清除:是 |
|
对系统的影响 |
l 硬盘温度过高会导致系统读写数据能力下降,进而导致系统性能下降,甚至瘫痪 |
|
可能原因 |
l 环境温度过高 l 进风口堵塞 l 出风口堵塞 l 风扇模块故障 l 数据读写量大 |
|
处理步骤 |
① 将服务器运行温度控制在其正常工作范围内,数分钟后查看告警是否消失 ② 检查服务器进风口和出风口是否存在堵塞,若存在堵塞则清理 ③ 检查服务器内部是否正确安装导风罩,安装导风罩,检查告警是否消失 ④ 检查服务器之间的空槽位或间隔是否已加假面板或挡板,为服务器之间的空槽位或间隔安装假面板或挡板,检查告警是否消失 ⑤ 检查是否存在频繁读写大量数据的非紧急业务,若存在则暂时关闭该业务 ⑥ 检查风扇模块是否存在告警,若存在告警则插拔或更换告警的风扇模块 ⑦ 联系厂商技术支持工程师处理 |
|
(1)电源故障严重告警 (PSUN Status) |
|
|
告警解释 |
l 告警描述: Power Supply Failure detected l 当检测到服务器电源模块故障时,产生此警告 l 产生此告警的传感器名称为:PSUN Status (N 表示服务器电源模块编号) |
|
告警属性 |
l 告警级别:严重 l 可自动清除:是 |
|
对系统的影响 |
l 电源故障时,会降低电源寿命,影响系统供电;或是单板下电,影响系统业务 |
|
可能原因 |
l 电源模块故障 |
|
处理步骤 |
① 重新插拔产生告警的电源,检查告警是否消失 ② 更换电源模块,查看告警是否消失 ③ 联系厂商技术支持工程师处理 |
|
(2)电源故障紧急告警 (PSUN Status) |
|
|
告警解释 |
l 告警描述: Power Supply input lost (AC/DC) l 当检测到电源模块在位,但供电中断时,产生此告警 l 产生此告警的传感器名称为:PSUN Status (N 表示服务器电源模块编号) |
|
告警属性 |
l 告警级别:紧急 l 可自动清除:是 |
|
对系统的影响 |
l 电源模块异常,影响设备供电 |
|
可能原因 |
l 电源线未连接 l 电源模块故障 |
|
处理步骤 |
① 重新拔插告警的电源模块的线缆,检查告警是否消失 ② 更换电源线缆,检查告警是否消失 ③ 更换电源模块,查看告警是否消失 ④ 联系厂商技术支持工程师处理 |
|
(1)风扇热插拔严重告警 (In / Out FanN Present) |
|
|
告警解释 |
l 告警描述: Hot Plug l 风扇发生热插拔时,产生此告警 l 产生此告警的传感器名称为:In / Out FanN Present (N表示服务器风扇编号) |
|
告警属性 |
l 告警级别:严重 l 可自动清除:是 |
|
对系统的影响 |
l 影响系统散热功能,降低设备性能 |
|
可能原因 |
l 风扇被热插拔 l 风扇与主板或硬盘背板接触不良 |
|
处理步骤 |
① 检查风扇是否被插拔过 ② 更换风扇模块,检查告警是否消失 ③ 联系厂商技术支持工程师处理 |
用户可通过开机BIOS自检界面的POST代码,快速、准确地诊断发生故障的组件及其故障信息,同时结合BMC系统中的事件日志,以便获取该组件的详细故障信息。从而帮助用户快速排除故障,使服务器各组件和系统保持良好的运行状况。下表反应了不同代码所代表的不同故障描述与反馈。
表6‑2检查点范围
|
状态代码范围 |
描述 |
|
0x01–0x0B |
执行SEC |
|
0x0C–0x0F |
Sec错误 |
|
0x10–0x2F |
PEI执行截止于内存检测 |
|
0x30–0x4F |
内存检测后执行PEI |
|
0x50–0x5F |
PEI错误 |
|
0x60–0x8F |
DXE执行BDS |
|
0x90–0xCF |
执行BDS |
|
0xD0–0xDF |
DXE错误 |
|
0xE0–0xE8 |
S3重启(PEI) |
|
0xE9–0xEF |
S3重启的错误(PEI) |
|
0xF0–0xF8 |
恢复(PEI) |
|
0xF9–0xFF |
恢复的错误(PEI) |
表6‑3标准检查点:SEC阶段
|
状态代码 |
描述 |
|
0x00 |
注意使用 |
|
过程代码 |
描述 |
|
0x01 |
启动,复位检测(软/硬) |
|
0x02 |
加载微码前进行AP初始化 |
|
0x03 |
加载微码前进行北桥初始化 |
|
0x04 |
加载微码前进行南桥初始化 |
|
0x05 |
加载微码前进行OEM初始化 |
|
0x06 |
加载微码 |
|
0x07 |
加载微码后进行AP初始化 |
|
0x08 |
加载微码后进行北桥初始化 |
|
0x09 |
加载微码后进行南桥初始化 |
|
0x0A |
加载微码后进行OEM初始化 |
|
0x0B |
高速缓存初始化 |
|
SEC错误的代码 |
描述 |
|
0x0C–0x0D |
用于保留可能出现的AMISEC错误的代码 |
|
0x0E |
没有发现微码 |
|
0x0F |
没有发现微码 |
表6‑4标准检查点:PEI阶段
|
进程代码 |
描述 |
|
0x10 |
PCI核启动 |
|
0x11 |
开启预内存初始化 |
|
0x12 |
预内存CPU初始化(CPU模块具体话) |
|
0x13 |
预内存CPU初始化(CPU模块具体话) |
|
0x14 |
预内存CPU初始化(CPU模块具体话) |
|
0x15 |
开启预内存北桥初始化 |
|
0x16 |
预内存北桥初始化(北桥模块具体化) |
|
0x17 |
预内存北桥初始化(北桥模块具体化) |
|
0x18 |
预内存北桥初始化(北桥模块具体化) |
|
0x19 |
开启预内存北南桥初始化(南桥模块具体化) |
|
0x1A |
开启预内存北南桥初始化(南桥模块具体化) |
|
0x1B |
开启预内存北南桥初始化(南桥模块具体化) |
|
0x1C |
开启预内存北南桥初始化(南桥模块具体化) |
|
0x1D–0x2A |
OEM的预内存初始化代码 |
|
0x2B |
内存初始化,读取串行存在检测(SPD)数据 |
|
0x2C |
内存初始化,内存存在检测 |
|
0x2D |
内存初始化,内存进程时序信息 |
|
0x2E |
内存初始化,配置内存 |
|
0x2F |
内存初始化(其他) |
|
0x30 |
保留ASL |
|
0x31 |
安装内存 |
|
0x32 |
开启CPU的内存配置后的初始化 |
|
0x33 |
高速缓存初始化 |
|
0x34 |
应用程序初始化 |
|
0x35 |
启动捆绑处理器(BSP)的选择 |
|
0x36 |
系统管理模式初始化(SMM) |
|
0x37 |
开启内存配置后的北桥初始化 |
|
0x38 |
内存配置后北桥配置(具体的北桥模块) |
|
0x39 |
内存配置后北桥配置(具体的北桥模块) |
|
0x3A |
内存配置后北桥配置(具体的北桥模块) |
|
0x3B |
开启内存配置后的南桥初始化 |
|
0x3C |
内存配置后南桥配置(具体的南桥模块) |
|
0x3D |
内存配置后南桥配置(具体的南桥模块) |
|
0x3E |
内存配置后南桥配置(具体的南桥模块) |
|
0x3F–0x4E |
内存配置后OEM初始化代码 |
|
0x4F |
开启DXEPIL |
|
PCI错误的代码 |
描述 |
|
0x50 |
内存初始化错误。Memoryinitializationerror.内存类型无效或不兼容的内存速度 |
|
0x51 |
内存初始化错误。读取SPD故障 |
|
0x52 |
内存初始化错误。Memoryinitializationerror.无效的内存大小活内存模块不匹配 |
|
0x53 |
内存初始化错误,没有检测到可用内存 |
|
0x54 |
未指定内存初始化错误 |
|
0x55 |
未安装内存 |
|
0x56 |
无效的CPU类型或速度 |
|
0x57 |
CPU不匹配 |
|
0x58 |
CPU自测故障或可能的CPU高速缓存错误 |
|
0x59 |
未发现CPU微码或者微码更新故障 |
|
0x5A |
内部CPU错误 |
|
0x5B |
复位PPI不可用 |
|
0x5C–0x5F |
保留未来的AMI错误代码 |
|
S3重启进程代码 |
描述 |
|
0xE0 |
开启S3重启(S3重启PPI由DXEIPL控制) |
|
0xE1 |
执行S3开机脚本 |
|
0xE2 |
视频转贴 |
|
0xE3 |
调用OSS3唤醒向量 |
|
0xE4–0xE7 |
保留未来AMI进程代码 |
|
S3重启错误代码 |
描述 |
|
0xE8 |
S3重启故障 |
|
0xE9 |
未发现S3重启PPI |
|
0xEA |
S3重启开机脚本错误 |
|
0xEB |
S3OS唤醒错误 |
|
0xEC–0xEF |
保留未来的AMI错误代码 |
|
恢复进程代码 |
描述 |
|
0xF0 |
由固件引起的恢复(自动恢复) |
|
0xF1 |
有用户引起的恢复(强制恢复) |
|
0xF2 |
开启恢复进程 |
|
0xF3 |
发现恢复固件映像 |
|
0xF4 |
加载恢复固件映像 |
|
0xF5–0xF7 |
保留未来的AMI进程代码 |
|
恢复错误的代码 |
描述 |
|
0xF8 |
恢复PPI无效 |
|
0xF9 |
未发现恢复保护 |
|
0xFA |
无效的回复保护 |
|
0xFB–0xFF |
保留未来的AMI错误代码 |
表6‑5标准检查点:DXE阶段
|
状态代码 |
描述 |
|
0x60 |
开启DXE内核 |
|
0x61 |
NVRAM初始化 |
|
0x62 |
初始化南桥运行时的服务 |
|
0x63 |
开启CPUDXE初始化 |
|
0x64 |
CPUDXE初始化(具体的CPU模块) |
|
0x65 |
CPUDXE初始化(具体的CPU模块) |
|
0x66 |
CPUDXE初始化(具体的CPU模块) |
|
0x67 |
CPUDXE初始化(具体的CPU模块) |
|
0x68 |
PCI主桥初始化 |
|
0x69 |
开启北桥DXE初始化 |
|
0x6A |
开启北桥DXESMM初始化 |
|
0x6B |
北桥DXE初始化(具体的北桥模块) |
|
0x6C |
北桥DXE初始化(具体的北桥模块) |
|
0x6D |
北桥DXE初始化(具体的北桥模块) |
|
0x6E |
北桥DXE初始化(具体的北桥模块) |
|
0x6F |
北桥DXE初始化(具体的北桥模块) |
|
0x70 |
开启南桥DXE初始化 |
|
0x71 |
开启南桥DXESMM初始化 |
|
0x72 |
南桥设备初始化 |
|
0x73 |
南桥初始化(具体的南桥模块) |
|
0x74 |
南桥初始化(具体的南桥模块) |
|
0x75 |
南桥初始化(具体的南桥模块) |
|
0x76 |
南桥初始化(具体的南桥模块) |
|
0x77 |
南桥初始化(具体的南桥模块) |
|
0x78 |
ACPI模块初始化 |
|
0x79 |
CSM初始化 |
|
0x7A–0x7F |
保留未来的AMIDXE代码 |
|
0x80–0x8F |
OEMDXE初始化代码 |
|
0x90 |
开启启动设备选择阶段(BDS) |
|
0x91 |
开启驱动连接 |
|
0x92 |
开启PCI总线初始化 |
|
0x93 |
PCI总线热插拔控制器初始化 |
|
0x94 |
PCI总线枚举 |
|
0x95 |
PCI总线请求资源 |
|
0x96 |
PCI总线配置资源 |
|
0x97 |
控制台输出设备连接 |
|
0x98 |
控制台输入设备连接 |
|
0x99 |
超IO初始化 |
|
0x9A |
开启USB初始化 |
|
0x9B |
USB复位 |
|
0x9C |
USB检测 |
|
0x9D |
启动USB |
|
0x9E-0x9F |
保留未来的AMI代码 |
|
0xA0 |
开启IDE初始化 |
|
0xA1 |
IDE复位 |
|
0xA2 |
IDE检测 |
|
0xA3 |
启动IDE |
|
0xA4 |
开启SCSI初始化 |
|
0xA5 |
SCSI复位 |
|
0xA6 |
SCSI检测 |
|
0xA7 |
启动SCSI |
|
0xA8 |
设置验证密码 |
|
0xA9 |
开始安装 |
|
0xAA |
保留ASL |
|
0xAB |
设置输入等待 |
|
0xAC |
保留ASL |
|
0xAD |
启动就绪事件 |
|
0xAE |
旧式启动事件 |
|
0xAF |
退出启动服务事件 |
|
0xB0 |
开始运行时设置的虚拟地址映射 |
|
0xB1 |
结束运行时设置的虚拟地址映射 |
|
0xB2 |
旧式选项ROM初始化 |
|
0xB3 |
系统复位 |
|
0xB4 |
USB热插拔 |
|
0xB5 |
PCI总线热插拔 |
|
0xB6 |
清空NVRAM |
|
0xB7 |
配置复位(复位NVRAM设置) |
|
0xB8–0xBF |
保留AMI代码 |
|
0xC0–0xCF |
OEMBDS初始化代码 |
|
DXE错误的代码 |
描述 |
|
0xD0 |
CPU初始化错误 |
|
0xD1 |
北桥初始化错误 |
|
0xD2 |
南桥初始化错误 |
|
0xD3 |
一些构架协议无效 |
|
0xD4 |
PCI资源分配错误,超过资源 |
|
0xD5 |
没有空间提供给就是选项ROM |
|
0xD6 |
未发现控制台输出设备 |
|
0xD7 |
为发现控制台输入设备 |
|
0xD8 |
密码无效 |
|
0xD9 |
错误加载引导选项(载入图像返回错误) |
|
0xDA |
启动选项故障(开始图像传回错误) |
|
0xDB |
闪存更新故障 |
|
0xDC |
协议复位失效 |
表6‑6标准检查点:ACPI/ASL检查点阶段
|
状态代码 |
描述 |
|
0x01 |
系统进入S1睡眠状态 |
|
0x02 |
系统进入S2睡眠状态 |
|
0x03 |
系统进入S3睡眠状态 |
|
0x04 |
系统进入S4睡眠状态 |
|
0x05 |
系统进入S5睡眠状态 |
|
0x10 |
系统从S1睡眠状态中唤醒 |
|
0x20 |
系统从S2睡眠状态中唤醒 |
|
0x30 |
系统从S3睡眠状态中唤醒 |
|
0x40 |
系统从S4睡眠状态中唤醒 |
|
0xAC |
系统已经转变成ACPI模式。中断控制器存在APIC模式 |
|
0xAA |
系统已经转变成为ACPI模式,中断控制器存在于APIC模式 |
在进行指示灯诊断前,需了解不同指示灯不同状态的具体说明。本章主要介绍电源开关指示灯、Health指示灯、UID指示灯以及硬盘指示灯。
其中,电源开关指示灯、Health指示灯、UID指示灯一般位于前置面板上,由BMC控制。常见的前置面板类型及面板上的相关按钮,如图6.11。

图6.11前面板示意图
前置板上右箱耳的详细说明,如图6.12。

图6.12右箱耳示意图
电源开关指示灯的相关说明如表6‑7。
表6‑7电源开关指示灯说明
|
按键 |
符号 |
状态 |
功能说明 |
|
电源按键 |
|
绿色常亮 |
系统处于S0状态 |
|
绿色闪烁 |
系统处于S1状态(最佳) |
||
|
黄色常亮 |
系统处于S4,S5状态 |
||
|
不亮 |
系统处于G3状态 |
Health指示灯的相关说明如表6‑8。
表6‑8 Health电源指示灯说明
|
指示灯 |
符号 |
状态 |
功能说明 |
|
|
Health |
|
红色常亮 |
检测到关键系统故障(处理器、内存、电压调节器、热事件、风扇故障等) |
|
|
红色闪烁(1Hz) |
系统降级;未出现关键故障 |
|||
|
不亮 |
系统正常 |
|||
UID指示灯的相关说明如表6‑9。
表6‑9 UID指示灯说明
|
按键 |
符号 |
功能说明 |
|
ID按键 |
ID |
短按ID按键或HDM下点击UID虚拟按钮:开/关IDLED,用于服务器定位与识别; 长按ID按键:ResetBMC; |
每个硬盘配有两个LED指示灯,分别为Active指示灯和Status指示灯,如图6.13所示。

图6.13硬盘指示灯示意图
Active指示灯为绿色单色LED指示灯,Locate/ERR指示灯为蓝色与黄色双色LED指示灯,通过观察这两个指示灯的状态变化,可以获取硬盘工作的状态。如表6‑10所示。
表6‑10 SAS/SATA硬盘状态指示灯显示说明
|
Active |
Locate/ERR |
功能说明 |
|
灭 |
灭 |
不在位或故障 |
|
绿色常亮 |
灭 |
工作正常无数据读写 |
|
绿色闪烁 |
灭 |
工作正常有数据读写 |
|
绿色常亮 |
蓝色常亮 |
被定位 |
|
绿色闪烁 |
黄色闪烁1Hz |
所在RAID组在进行重构 |
|
绿色常亮 |
黄色闪烁4Hz |
即将故障 |
|
绿色常亮 |
黄色常亮 |
硬盘故障 |
U.2硬盘状态指示灯如表6‑11所示。
表6‑11 U.2硬盘状态指示灯显示说明
|
Active |
Locate/ERR |
功能说明 |
|
灭 |
灭 |
不在位 |
|
绿色常亮 |
灭 |
工作正常无数据读写 |
|
绿色闪烁 |
灭 |
工作正常有数据读写 |
|
灭 |
黄色闪烁 |
可进行热插拔 |
|
绿色常亮 |
黄色常亮 |
硬盘故障 |
(1)服务器搭配LSI SAS HBA卡(卡下连接装有OS的系统盘),反复对服务器上下电操作,小概率出现无法正常进入系统的情况。
产生原因
控制器下未指定系统启动盘,导致重启后BIOS无法在控制器下找到系统盘,从而无法正常引导操作系统。
解决方案
① 进入SAS卡Option ROM界面,在SAS Topology下展开硬盘列表,按Alt+B将OS所在硬盘设置为Boot(键入Alt+B)项,如下图:
② 在Advanced Adapter Properties->Advanced Device Properties目录下,设置可启动设备数量,如下图:

注:若SAS卡连接了系统盘,建议将Maximum INT 13 Devices for this Adapter设置为1;若SAS卡只连接数据盘,无OS启动盘,建议将Maximum INT 13 Devices for this Adapter设置为0。
设置成功后,在POST界面以及BIOS启动列表中,将只显示对应数量的硬盘,不再显示全部硬盘。
(2)硬盘上电状态下,拔出RAID1组列下的两块硬盘,插入另一机器RAID卡下时,在BMC Web页面显示的状态不一致。
产生原因
该现象因硬盘上电状态下拔盘导致。先拔出来的盘,硬盘DDF(disk data format)中RAID组列的状态仍记录为optimal,而后拔出来的盘,因RAID组列降级,DDF中的RAID组列状态将更新为degraded。进而导致两块盘插入新卡下后,storlib读取到的两块盘为两种状态。出现该现象时,BMC的存储系统或RAID卡可以正常地将两块硬盘import为一个RAID组列。
解决方案
此配置若要拔盘,请在下电的情况下拔。
(3)RAID卡在开机自检阶段hang92。
产生原因
出现RAID卡自检时卡住,大概率由于RAID卡的Option ROM在执行中出现了挂死现象。
解决方案
① 如出现问题前升级过RAID卡固件,则检查RAID卡与BIOS版本是否配套,如无法确认,请联系技术支持。若有硬盘扩展板,则重点关注硬盘扩展板与RAID卡固件是否配套。
② 登录BMC Web页面,查看event log中是否有超级电容或硬盘故障等相关告警,如存在告警,则更换相关部件。
③ 在BMC Web页面的资产信息中,查看物理盘信息是否准确。若存在物理盘信息对应不上的情况,需排查线缆、背板及相关硬盘是否存在故障。
④ 确认逻辑盘状态是否正常。若不正常,则先查看是否有RAID成员盘异常,有则更换异常硬盘。若无 RAID 成员盘异常,则查看是否逻辑盘处于 Offline 状态,恢复为 Online 后再重新启动确认故障是否解决。
⑤ 更换RAID卡,查看问题是否解决。
⑥ 若问题仍然存在,请联系技术支持。
(4)更换同型号RAID卡后,发现原RAID卡的硬盘数据无法被识别和使用。
产生原因
更换后的RAID卡的current personality不为 RAID模式,导致用户无法识别和使用含有 RAID数据的硬盘。
解决方案
① 将RAID卡的current personality改为 RAID模式,保存配置并重启服务器。
② 若问题仍然存在,请联系技术支持。
(1)操作系统日志上报硬盘故障,如“I/O error”、“Hardware Error”、“Medium Error”等。
产生原因
硬盘损坏。
RAID卡与硬盘间的链路出现异常,导致硬盘无法正常读写。
解决方案
① storcli工具:storcli call//eall/sall show all确定硬盘SN号与slot号;storcli /cx/ex/sx start locate对故障盘进行点灯、定位。
② 收集raid卡日志、BMC日志、硬盘日志,进一步联系技术支持。
(2)操作系统无法识别硬盘。
产生原因
硬盘背板供电异常。
硬盘安装不到位。
硬盘故障。
硬盘在存储控制卡下未创建 RAID 或配置为直通盘。
存储控制卡驱动未安装或版本过低。
NVMe 硬盘驱动未安装。
解决方案
① 确保硬盘安装到位。
② 查询硬盘Present/Active指示灯,指示灯常亮/闪烁,说明硬盘背板供电正常;否则,请通过交叉验证的方法,查看硬盘背板、硬盘电源线缆是否存在异常。
③ 通过BIOS下的RAID卡控制界面,确认当前硬盘是否可以被RAID卡识别。如果不能识别,执行步骤④。如果可以识别,执行步骤⑤。
④ 确认硬盘是否已创建RAID或配置为JBOD盘,创建RAID或配置为JBOD盘后,操作系统才能识别到该硬盘。
⑤ 确认RAID卡的驱动版本,建议更新到最新驱动版本。
⑥ 若问题仍然存在,请联系技术支持。
(3)硬盘Fault/UID指示灯橙灯常亮或闪烁。
产生原因
硬盘处于热插入过程中。
硬盘完成预知性热拔出流程。
硬盘预告性故障报警。
硬盘故障。
解决方案
① 通过硬盘 Fault/UID 指示灯位置,确认故障硬盘所在槽位号。
② 确认硬盘类型,并按如下处理步骤进行排查,若仍存在异常,执行步骤③。
ü 若为SAS/SATA硬盘,请尝试重新插拔硬盘,确认是否可以恢复正常。
ü 若为NVMe硬盘,请根据硬盘 Fault/UID 指示灯判断处理方式。
s 硬盘 Fault/UID 指示灯橙色闪烁时无需处理。
s 硬盘 Fault/UID 指示灯橙色常亮,请尝试重新插拔硬盘,确认是否可以恢复正常。
③ 做好业务数据备份工作后更换对应槽位硬盘。
④ 若问题仍然存在,请联系技术支持。
(4)更换RAID组列中的硬盘后,虚拟盘重建失败。
产生原因
更换的新硬盘异常。
解决方案
① 检查并确保新成员盘的容量大于等于故障成员盘。若新成员盘容量小于故障成员盘,会导致逻辑盘重建失败。
② 检查并确保RAID卡线缆连接正确、稳固无松动。
③ 确认新成员盘能否被RAID卡正常识别。
(5)BMC提示硬盘Drive Fault或Offline告警。
产生原因
BMC、BIOS版本过低。
硬盘离线。
硬盘本体故障。
硬盘线缆、RAID卡、硬盘背板以及硬盘扩展板未正确安装或已出现故障。
解决方案
① 确认OS或BIOS下硬盘是否可以识别。如果两者任意一个可以识别,请升级BMC、BIOS至最新版本。
② 升级硬盘固件至最新版本;若RAID卡连接了硬盘扩展板,请同步升级硬盘扩展板固件到官网最新版本。
③ 请通过交叉验证方法,依次排查存储控制卡、硬盘、硬盘背板、硬盘扩展板及其配套线缆的链路问题。若故障跟随某一部件出现,则更换该部件。
④ 若问题仍然存在,请联系技术支持。
(6)根据软硬件配置设定好NVMe配置后,NVMe盘位插SATA盘不能识别,SATA盘位插NVMe盘不能识别;如果后期更换主板,并且没有对应刷写命令,会出现原机器识别NVMe的盘位只能识别SATA。
产生原因
该机型NVME功能,除需要硬件线缆适配外,还需要通过更改 FRU中的‘Board Extra’ 字段进行对应实现。
解决方案
通过更改 FRU中的‘Board Extra’ 字段进行对应实现,命令为: ipmitool -I lanplus -H <BMC IP> -U admin -P Password@_ fru edit 0 field b 5 xxxxxxx
命令中的‘xxxxxxx’对应如下列表中的‘Board Extra’列:
|
序号 |
NVME实现数量 |
Board Extra |
备注 |
|
1 |
0 |
0000000 |
/ |
|
2 |
个数≤4 |
1001111 |
/ |
|
3 |
4<个数≤8 |
1401111 |
Retimer卡插在RiserB上 |
|
4 |
4<个数≤8 |
1201111 |
Retimer卡插在RiserA上 |
备注:从 ‘生产/逆向/客户’ 流到 用服 的整机或备件,都是可以直接刷写‘Board Extra’ 字段,所以不需要调用NVME配置软件‘0502A9SB’(PDM已发布);若无法刷写成功,预计需要反查对应主板的来料过程。
(1)新安装的网卡无法正常识别或工作。
产生原因
PCIe连接问题。
网卡不兼容已安装的光模块,或光模块/线缆安装不到位。
网卡、线缆、光模块或其他部件如Riser等发生故障。
服务器硬件配置问题,如槽位不匹配、CPU不在位等。
网卡的固件或驱动版本过低。
网卡与服务器不兼容。
网卡的固件或驱动版本与操作系统不兼容。
解决方案
① 通过兼容性列表查询,该网卡是否符合服务器兼容性要求。
② 在服务器启动过程中,进入BIOS Setup界面,查看网卡能否被正常识别。
(UEFI启动模式与Legacy启动模式有所不同:从UEFI启动,需再Advanced页面,查看是否有网卡配置项;从Legacy启动,需查看POST阶段,是否有对应网卡的打印信息。)
③ 将网卡的固件和驱动版本升级为满足兼容要求的最新版本。
④ 若网卡能被BIOS识别,则继续以下步骤排查故障原因:
ü 确保PCIe连接正常。
ü 检查金手指、插槽及接口的物理形态是否正常。
ü 检查网卡和光模块的兼容性。
ü 使用正常工作的光模块进行交叉验证。
ü 检查网卡的固件和驱动是否为满足要求的最新版本。
⑤ 若网卡不能被BIOS识别,则表明网卡或槽位发生硬件故障。需交叉验证,在定位故障部件后需进行进一步地更换。
⑥ 若问题仍存在,请联系技术支持。
(2)PXE启动打印错误信息,无法进入PXE环境。
产生原因
网卡不支持PXE Boot功能。
BIOS Setup中PXE功能或网口的PXE功能被禁用。
网卡Boot Protocol未设置为PXE方式,导致服务器无法从PXE启动。
解决方案
⑦ 查看官网上的网卡datasheet,确认该网卡是否支持PXE Boot。如果否,请更换一个支持PXE Boot的网卡。
⑧ 进入BIOS Setup检查PXE相关功能是否已启用。
⑨ 服务器启动过程中,网卡自检时,按Ctrl+s进入网卡参数配置界面,确认Boot Protocl是否为PXE。
(3)Mellanox网卡通过PXE启动装Windows 2012 R2系统时,启动失败,报“modnic_device_start_modnic failed to initialize device(Status=-5)”错误。

产生原因
由Mellanox网卡的驱动与Windows 2012 R2系统存在兼容性差异导致。
解决方案
下载ucrtbase.dll补丁文件,将文件放入C:\Windows\SysWOW64下,再重新安装驱动。
(4)网讯网卡在VMware ESXi系统下安装网卡驱动时,会报“Dependency Error”,导致安装失败。
产生原因
目前网迅全系列网卡都未经过VMware认证,且此厂商目前没有VMware认证计划。
解决方案
输入命令:esxcli software acceptance set --level=CommunitySupported,将系统接收软件的级别降低即可安装成功。
(5)搭配有Mellanox网卡的服务器安装完Windows 2012 R2系统后,在系统下安装网卡驱动会报:“error 2707.Target path not created. No path exits for entry System order in Directory table”的错误。
产生原因
由Mellanox网卡的驱动与Windows 2012 R2系统存在兼容性差异导致。
解决方案
下载ucrtbase.dll补丁文件,将文件放入C:\Windows\SysWOW64下,再重新安装驱动即可。
(1)风扇转速过高,噪声过大。
产生原因
当前散热策略选择不当。
风扇损坏。
工作温度过高,通风不畅。
服务器内部通风环境不良,有异物阻塞风道。
固件版本过低。
当前服务器loading过高,功耗过大。
解决方案
① 检查并确保机箱中没有异物、所有风扇接口完好无损,确保所有风扇均正确安装到位。
② 检查并确保服务器通风正常,出风口和入风口没有被异物阻塞。
③ 检查并确保服务器工作环境温度符合要求。
④ 登录BMC WEB检查当前散热策略。

⑤ 检查BMC WEB->系统信息->历史记录,查询当前服务器负载和功耗情况。

⑥ 升级固件(BIOS/BMC/CPLD)至最新版本。
(2)服务器正常运行时:某一个在位风扇以全速转或接近全速转的速率运行,其余风扇转速正常。
产生原因
风扇异常。
主板上对应的风扇接风口异常。
解决方案
① 检查该风扇接口,确保其完好无损坏。
② 使用正常工作的同型号风扇,进行交叉验证。
(3)服务器正常运行时,所有在位风扇接近全转速。
产生原因
风扇调速模式选择不当。
服务器运行功耗过高。
BMC、BIOS、主板CPLD固件版本过低。
风扇当前的安装规则,不符合系统要求的风扇安装准则。
风扇未安装到位。
风扇异常。
外部工作环境温度过高。
服务器通风环境不良。
机箱内存在异物。
解决方案
① 检查并确保机箱中没有异物、所有风扇接口完好无损。
② 重新安装所有风扇,确保所有风扇均正确安装到位。
③ 检查并确保服务器通风正常,出风口和入风口没有被异物阻塞。
④ 检查并确保服务器工作环境温度符合要求,详细信息请参见服务器用户指南。
⑤ 在BMC WEB界面,手动调节风扇的运行模式,将风扇以较低的速率运转。
⑥ 将BMC、BIOS、主板CPLD固件版本,均升级至最新版本。
⑦ 使用正常工作的同型号风扇,与原来所有风扇逐个进行交叉验证。
内存安装准则
安装内存前
做好防静电措施:穿上防静电工作服;正确佩戴防静电腕带并良好接地;去除身体上携带的易导电物体(如首饰、手表)。
检查内存金手指和插槽,确保金手指是否脱落、插槽中没有异物。
取放内存时
务必仅拿住内存两侧的边缘,不要用多根手指紧握内存。
避免触摸内存两侧的颗粒、底部的金手指。
安装内存前
内存不支持热插拔。
确保相应的CPU已安装到位。
不同规格(类型、容量、Rank、数据宽度、频率)的 DRAM 不支持混插,不同规格的DCPMM不支持混插。即一台服务器上配置的所有DRAM产品编码必须相同,所有DCPMM产品编码必须相同。
DRAM和DCPMM尽量分布在不同的通道上,以提升内存访问带宽。
详细的内存安装准则,请参见产品用户指南。
(1)内存安装位置错误告警,服务器卡在POST界面。
产生原因
内存位置安装错误。
解决方案
根据BMC告警信息,确认出现问题的内存槽位。
参考服务器用户指南内存安装准则,重新安装内存。
若问题仍存在,请联系技术支持。
(1)Cambricon MLU100-C3/C4 GPU在安装驱动后,Linux无法启动。
产生原因
该GPU卡中带有PCIe Switch,安装驱动后PCIe资源分配错误造成Linux无法启动。
解决方案
先拔出该卡或移除该卡的供电线缆,正常开机后按如下方法修改Linux内核参数(以CentOS7.x为例):
① Legacy模式请修改/boot/grub2/grub.cfg。
② UEFI模式请修改/boot/efi/EFI/centos/grub.cfg。
③ 在kernel后增加参数pci=realloc=on后保存。
![]()
④ 重启服务器,操作系统可以正常启动。
(1)系统上电后,BIOS POST阶段挂死,无法进入启动项或无法进入BIOS Setup。
产生原因
CPU、内存、PCIe 卡、硬盘、USB 等硬件初始化故障引起的挂死。
BIOS 配置选项引起的挂死。
非稳态升级 BIOS 版本引起的挂死。
解决方案
① 登录BMC界面,查看事件日志,确认传感器是否提示存在设备故障。若有故障提示,请按对应的处理建议排除故障。
② 无传感器故障时,将服务器电源断开,进行AC下电操作。取下主板上纽扣电池,静置3分钟清除CMOS,CMOS清除完后再将纽扣电池装回原位置,重新进行AC上电操作。此时查看故障是否顺利解决。
③ 登录BMC界面,升级BIOS、BMC版本查看问题是否解决。
④ 确认服务器上是否存在 USB 设备,移除 USB 设备后重启确认故障是否解除。
⑤ 确认服务器上是否存在SATA/SAS硬盘,逐步移除硬盘设备后重启确认是否故障解除,通过排查确认故障硬盘后解除故障。
⑥ 若问题仍然存在,请联系技术支持。
(1)BMC WEB界面无法正常访问。
产生原因
BMC管理口的IP地址与笔记本的IP地址不在同一网段。
BMC管理口未连接网线或网络连接处于异常状态。
服务器进入了BIOS Setup界面。
解决方案
① 检查BMC管理口的IP地址与笔记本的IP地址是否在同一网段。
② 检查BMC管理口是否正确连接了网线。
③ 查看服务器是否进入了BIOS Setup界面。若是,则保存配置并退出,正常进入系统即可。
④ 若问题仍然存在,请联系技术支持。
(1)服务器上电后,启动异常,且出现黑屏现象。
产生原因
服务器外部供电不足。
内存安装位置错误。
服务器故障。
显示器故障。
解决方案
① 检查本故障发生时服务器前面板指示灯(包括 Health 指示灯等)是否都不亮。
② 观察服务器 Health 指示灯是否存在异常。若 Health 指示灯显示系统出现问题,请通过BMC查看系统运行状态。
③ 请确保内存安装符合服务器的内存安装准则,安装准则请参见产品用户指南。错误的安装位置 会导致服务器启动异常。
④ 采用交叉验证的方法,确认服务器或显示器是否故障。
(2)服务器在运行过程中,显示器突然黑屏。
产生原因
显示器电源线连接不良或供电不符合要求。
显示器与服务器之间的 VGA 线缆连接不良。
显示器亮度、对比度未正确设置。
显示器故障。
服务器故障。
解决方案
① 检查显示器的外部供电,确保供电正常,若显示器的指示灯亮则表明连接正确。
② 检查显示器和服务器之间的 VGA 线缆,确保连接正确可靠。
③ 调节显示器的亮度和对比度,确认故障是否仍然存在。是,则执行步骤④。
④ 将服务器下电,然后重新上电,确认故障是否存在。是,则执行步骤⑤。
⑤ 采用交叉验证的方法,确认服务器或显示器是否故障。
若故障现象跟随显示器出现,则更换显示器;若故障现象跟随服务器出现,请联系技术支持确认服务器问题。
(1)服务器上前面板指示灯同时不亮, BMC无法连接。涉及指示灯类型如下:
Health 指示灯
系统电源指示灯
UID 指示灯
网口指示灯
硬盘指示灯
电源模块状态指示灯
产生原因
服务器外部供电异常。
电源线缆连接松动。
电源模块未正确安装到位。
服务器电源模块故障。
服务器主板故障。
解决方案
① 检查外部供电,确保外部供电正常;
② 检查所有的电源线缆,重新安装电源线缆,确保线缆稳固无松动;
③ 重新正确安装电源模块。若问题仍然存在,请执行步骤④;
④ 使用正常工作的同型号电源模块,进行交叉验证:
若问题解决,说明原电源模块故障,请更换;若问题仍然存在,则说明主板出现故障,请联系技术支持。
(1)服务器正常运行过程中自动关机。
产生原因
服务器外部供电异常。
• 服务器被执行了关机操作。
• 服务器中部件温度过高。
• 服务器外部环境温度过高。
• 硬件故障。
• 软件异常。
解决方案
① 在BMC Web界面的事件日志中,查阅是否有供电异常的记录;同时,检查服务器的外部供电是否正常。
② 在BMC Web界面的事件日志中,查阅是否有关机键被按下的记录,即查阅是否是人为触发了关机操作。
③ 在BMC Web界面的事件日志中,查阅是否有温度过高的报警信息。
④ 检查并确保机房温度满足服务器的工作环境温度。机房温度过高可能会导致服务器自动关机,服务器的工作环境温度请参见产品用户指南。
⑤ 收集操作系统日志:分析Dmesg、Message 等日志是否有硬件异常告警信息,根据该信息排查对应硬件;分析是否有操作系统层或者业务层相关告警信息,如果存在相关告警信息请联系相关厂家。
(2)安装新部件后,服务器无法正常启动或者部件无法正常工作。
产生原因
服务器不兼容该部件。
该部件未安装到位。
该部件的固件或驱动版本过低。
该部件故障。
解决方案
① 确保服务器兼容该部件,兼容性可通过服务器兼容的部件查询工具查询。
② 确保部件和相关线缆均正确安装到位,线缆稳固无松动。且部件安装过程中,没有遗漏相关组件(比如线缆)。
③ 检查系统能否识别该部件,并确保部件的固件和驱动,均更新为最新版本。
④ 将新部件安装到其他正常的服务器上,通过交叉验证的方法,检查新部件是否故障。
⑤ 若问题仍然存在,请联系技术支持。
(3)USB设备连接至服务器的任意USB接口上,均无法被BIOS或者操作系统识别。
产生原因
USB设备故障。
BIOS下未开启服务器上的任意USB接口的功能,此时任何连接至这些接口上的USB设备将会被禁用。
主板上的USB接口故障。
解决方案
① 在 BIOS 中开启服务器上所有 USB 接口的功能。
② 将接入的该 USB 设备替换为正常工作 USB 设备,进行交叉验证。
若问题解决,说明该USB设备故障,请更换。若问题仍然存在,说明主板上的USB接口故障,请联系技术支持。
服务器固件升级主要包括:BIOS固件升级和BMC固件升级。
(1)EFI Shell 刷写
①将BIOS FW文件夹拷贝到U盘,将U盘插到服务器;
②开机/重启服务器,启动到Shell下;

③FS*即为所插U盘盘符,输入”FS*:”进入到U盘目录;
④进入到FW文件及刷写脚本所在路径(注意FW文件需与刷写脚本在同一路径下),执行efiflash.nsh进行刷写;

⑤关机断AC,再次上电启动才能使新版BIOS生效,进入Setup界面, F3恢复默认值F4保存设置并退出。
(2)BMC Web刷写(推荐使用方法)
①远程登录BMC,用户名admin,密码Password@_;

②打开“系统维护”菜单下的“BIOS固件更新”选项;

③点击“选择文件”选取FW文件,如“ R4930-***.rom ”,点击“开始固件更新”;

④“固件更新提示”弹出,点击“确定”;

⑤上传成功后,点击“开始更新”来更新BIOS,更新过程中禁止断电(点击“取消”则取消更新BIOS);

⑥“BIOS固件更新提示”弹出,点击“确定”;

⑦刷新成功后,弹出如下提示,点击“确定”;

⑧BMC Web刷新支持服务器开机状态下刷写;关机断AC,再次上电启动才能使新版BIOS生效,重启后,进入Setup界面, F3恢复默认值F4保存设置并退出。
(3)操作系统下刷新方法(Linux 64位)
①开机进入操作系统,将BIOS FW文件夹拷贝到系统下;打开命令行界面,进入到FW文件及刷写脚本所在路径(FW文件需与刷写脚本在同一路径下),执行linuxflash.sh进行刷写;


②关机断AC,再次上电启动才能使新版BIOS生效,进入Setup界面, F3恢复默认值F4保存设置并退出;
(4)检验方法如下:
①更新完BIOS后,机器在POST界面显示为H3C Logo:

②进入BIOS Setup界面,查看BIOS版本信息:

③ 登录BMC主界面查看,“仪表盘”页面下的“固件版本信息”:

(1)DOS盘刷新方法:
①将BMCFW刷新文件夹拷贝到USB启动盘;
②服务器开机从U盘启动,进入到FW文件及刷写脚本所在路径,运行upFW.bat文件进行刷写;

③提示刷新成功后,关机/断开AC,再次上电开机检查版本信息。
注意:刷写过程不能断电!
(2)BMC Web界面刷新方法:
①远程登录IPMI,用户:admin,密码:Password@_;

②打开“系统维护”菜单下的“BMC固件更新”选项;

③“保存所有配置”选项不勾选,点击“选择文件”选取FW文件,点击“开始固件更新”;

④“固件更新提示”弹出,点击“确定”;

⑤上传成功后,点击“开始更新“进行BMC更新,更新过程中禁止断电;

⑥刷新成功后,弹出如下提示,点击“确定”,2分钟后可重新登录管理界面,BMC Firmware刷新过程结束。

(3)Linux 64位(CentOS 7.4)下刷新方法:
①开机进入操作系统,将BMC FW文件以及对应刷写工具拷贝到系统下;打开命令行界面,进入到FW文件及刷写脚本所在路径(注意刷写脚本需与FW文件在同一路径下),先执行chmod 777 socflash_x64,修改权限;

②执行sh upFW.sh进行刷写;

③待刷写完毕后,关机/断开AC,再次上电开机检查版本信息;
(4)检验方法如下:
①BIOS查看。开机进入BIOS Setup界面,“Server Mgmt”中BMC Firmware Revision,如下图。

②登录BMC主界面查看。登录界面Logo和BMC主系统左上角logo为Sugon Logo。
③在系统摘要—固件版本信息中查看,进入后如下图:

④通过本地系统ipmitool或远程系统ipmitool查看。显示Firmware Revision版本,如下图:

固件升级可以采用UEFI下刷写和Linux下刷写两部分,下文以9361-8i卡为例,进行详细说明。
(1)UEFI刷新
①进入LSI 9361-8i RAID卡的管理界面,查看FW Package Version,如果为目标固件,则不需要刷新。如果不是,则进入第二步刷新此Firmware;
②进入BIOS,选择从UEFI: Built-in EFI Shell启动项启动,如下图所示:

④ 在EFI Shell下输入命令‘fs0:’,进入Firmware所在U盘,如下图:

⑤ 进入Firmware所在路径,执行升级命令:storcli.efi /c0 download file=0132.rom noverchk,如下图:(图片仅供参考)

⑤等待刷新结束,刷新过程中注意不要掉电或关机,不要移除存放Firmware的U盘;
⑥刷新结束后重启。
(2)Linux下刷写
①进人Linux系统,安装阵列卡管理工具,进入/opt/MegaRAID/storcli/路径,执行升级命令:./storcli64 /c0 download file=0132.rom,,如下图:

②等待刷新结束,刷新过程中注意不要掉电或关机,不要移除存放Firmware的U盘;
③刷新结束后重启。
(3)检验方法
①检查RAID卡的FW Package Version为24.21.0-0132,Revision为4.680.00-8527。刷新后如下图:


(4)注意事项
①刷新过程中注意不要断电或关机;
②刷新过程中注意不要移除存放Firmware的U盘。
集团主流的网卡厂商为Intel与Mellanox。本节分别对两张网卡的固件升级过程作说明。
7.2.2.1 Intel系列网卡
本节以Intel X520双口万兆网卡为例,刷新Boot Agent和Firmware。其他Intel芯片网卡可参考此节。
下载Bootutil+Eeupdate_Linux_x64.tar.gz压缩包,拷贝到Linux系统下:
更新系统pci.ids文件:
(下载链接:http://pciids.sourceforge.net/)
(1)输入:cp /tmp/pci.ids/usr/share/hwdata/:在弹出的提示是否覆盖系统原有pci.ids文件时输入y,回车。
(2)输入:lspci | grep –I X520:使用lspci查看Intel X520网卡硬件是否被识别到。
升级网卡BootAgent:
(1)安装BootAgent刷新工具,步骤如下:
① 指令:tar xvf Bootutil+Eeupdate_Linux_x64.tar.gz
② 指令:cd /tmp/Bootutil+Eeupdate_Linux_x64/DRIVER
③ 指令:./install
④ 指令:./bootuti
⑤ 进入OEM_Mfg文件夹下,执行bootutil命令,查看X520网卡前面的网卡序号X,如下图:

(2)刷新网卡BootAgent,步骤如下:
① 指令:./bootutil -nic=X -up=combo -file=BootIMG.FLB,在弹出询问是否生成restoreimage时,输入y即可;
② 升级完成后如下图所示:

升级网卡Firmware:
(1)安装Firmware刷新工具,步骤如下:
① 指令:tar xvf Bootutil+Eeupdate_Linux_x64.tar.gz
② 指令:cd /tmp/Bootutil+Eeupdate_Linux_x64/DRIVER
③ 指令:./install
④ 指令:./eeupdate64e
⑤ 指令:./eeupdate64e -nic=1-eepromver
⑥ 进入OEM_Mfg文件夹下,执行./eeupdate64e命令,查看X520网卡相关信息,如下图:

(2)刷新网卡Firmware,步骤如下:
① 指令:./eeupdate64e /nic=X /d=X520EEPR
(在升级网卡Firmware时,要先把X520EEPR文件拷贝到与eeupdate64e同一目录下)
② 升级完成后,重启服务器,如下图所示:

7.2.2.2 Mellanox系列网卡
本节以Mellanox CX4双口万兆网卡为例,刷新Boot Agent和Firmware。其他Mellanox芯片网卡可参考此节。
下载MFT工具包
(下载最新连接:https://www.mellanox.com/page/management_tools)
更新系统pci.ids文件:
(下载链接:http://pciids.sourceforge.net/)
(1)输入:cp /tmp/pci.ids/usr/share/hwdata/:在弹出的提示是否覆盖系统原有pci.ids文件时输入y,回车即可。
(2)输入:lspci | grep –I Mellanox:使用lspci查看Mellanox网卡硬件是否被识别到,如下图:

安装工具和驱动:
(1)步骤如下:
⑥ 指令:tar xvf mft-4.8.0-26-x86_64-rpm.tar.gz
⑦ 指令:cd mft-4.8.0-26-x86_64-rpm
⑧ 指令:./install
⑨ 等待5~10分钟驱动安装完成,效果如下图所示。

查看Firmware版本:
(1)步骤如下:
① 指令:mst start

② 指令:mlxfwmanager
③ 查看所有Mellanox网卡的FW和PXE版本。

下载Firmware:
(下载链接:https://www.mellanox.com/page/firmware_download)
在刷新FW以前,先把Mellanox网卡对应的FW文件放到mft-4.8.0-26-x86_64-rpm文件夹下。
刷新Firmware:
指令:mlxfwmanager –update:
在弹出Perform FW update? [y/N]时,输入y,回车即可。
(1)在机箱盖上可直接获取,如下图红框处:

(2)BMC WEB资产信息界面可直击获取,点击“系统信息——fru信息——产品序号”即可查看;
(3)系统下用Ipmitool工具直接查看,指令:ipmitool fru。
①使用网线(交叉网线或交叉线)连接本地PC和服务器的BMC管理网口。连接组网络如下图所示。

②在PC的浏览器中输入BMC管理口IP,如10.8.20.109。
③在跳转后的地址页内,输入BMC账号及密码,如下图。

④成功登入到BMCWEB界面。

①远程登入服务器IP,指令:ssh服务器IP(以10.8.20.111为例);

②输入当前服务器的账户名;

③输入当前服务器的密码;

④登入服务器,成功登入界面如下图所示。

IPMI 是智能型平台管理接口(Intelligent Platform Management Interface)的缩写,是管理基于 Intel 结构的企业系统中所使用的外围设备采用的一种工业标准。用户可以利用 IPMI 监视服务器的物理健康特征,如温度、电压、风扇工作状态、电源状态等。IPMI 针对大量监控、控制和自动回复服务器的作业,提供了智能型的管理方式。
ipmitool工具详情操作指令参见《ipmitool用户手册》,本节对常用指令作简单介绍。若有需要,请联系售后工程师。
(1)ipmitool lan print<channel>
查看服务器指定通道的当前配置信息,尤其是BMC地址信息。若不输入通道数,会显示默认的首通道信息。
(2)ipmitool lan alert print<channel>
打印服务器本通道告警信息。
(1)ipmitool chassis status
查看服务器当前机箱状态。
(2)ipmitool chassis selftest
服务器开始进行机箱自检,并返回检测结果。
(1)ipmitool fru print
服务器返回所有的FRU 信息。
RAID卡(如3108、3316)管理通用工具,最新版本加入了对HBA卡(如3008)的支持,64位系统命令的绝对路径为:/opt/MegaRAID/storcli/storcli64;32位系统命令的绝对路径为:/opt/MegaRAID/storcli/storcli。
storcli工具详情操作指令参见《H3C服务器 存储控制卡用户指南》,本节对常用指令作简单介绍。若有需要,请联系售后工程师。
(1)storcli /c0 show all
查看第一块RAID卡版本、功能、状态、以及raid卡下的物理磁、逻辑盘信息。c0代表第一块raid卡,如果有多块则命令以此类推。
(2)storcli /c0 show freespace
查看第一块RAID卡剩下的磁盘空间。
(3)storcli /c0/cv show all
显示超级电容信息。
(1)storcli /c0 add vd type=raid5 size=all names=tmp1 drives=252:2-4
由第3、4、5块物理磁盘来构建RAID5,分配所有空间的逻辑磁盘命名tmp1。
(2)storcli /c0 add vd each type=raid0 drives=252:0,1,2,3
单独为每一块物理磁盘创建raid0。
(3)storcli /c0/v0 del force
强制删除逻辑磁盘,v0代表第一个逻辑磁盘,如果有多块则命令以此类推。
(4)storcli /c0/v0 set wrcache=wt/wb/awb
设置写策略。
wt:write through;wb:write back;awb:always write back
(5)storcli /c0/v0 set rd cache=ra/nora
设置读策略。
ra:read ahead;nora:no read ahead
(1)storcli /c0/fall show
查看所有的foreign信息。
(2)storcli /c0/fall import
导入所有的foreign。
(1)storcli /c0 show rebuildrate
查看第一块RAID卡rebuildrate速度。
(2)storcli /c0/e252/sall show rebuild
查看磁盘重建进度。
(3)storcli /c0/ex/sx start rebuild
开始重建。
(4)storcli /c0/ex/sx stop rebuild
停止重建。
(5)storcli /c0 set autorebuild=off
关闭自动重建。
(1)storcli /c0/eall/sall show all
查看第一块RAID卡上物理磁盘详细信息。
(2)storcli /c0/eall/s1 show all
查看第一块RAID卡上第二块物理磁盘详细信息。
(1)storcli /c0 set alarm=silence
暂时关闭报警器鸣叫。
(2)storcli /c0 set alarm=off
始终关闭报警器鸣叫。
(1)storcli /c0/e252/sx set good force
如:/opt/MegaRAID/storcli/storcli64 /c0/e252/s3 set good force,表示:改变插入的物理磁盘的状态为good
(2)storcli /c0/e252/sx set jbod
如:/opt/MegaRAID/storcli/storcli64 /c0/e252/s3 set jbod,表示:改变插入的物理磁盘的状态为jbod
(3)storcli /c0/e252/sx set offline/online
如:/opt/MegaRAID/storcli/storcli64 /c0/e252/s3 set offline,表示:改变RAID组成员盘的状态为offline
(1)storcli /c0/e252/s0 start locate
说明:定位第一块RAID上第一块物理磁盘,物理磁盘的绿色的定位灯会闪烁。e代表Enclosure,s代表Slot或PD。
(1)storcli /c0 show termlog,storcli /c0 show alilog,storcli /c0 show events
在线查看日志。
(2)storcli /c0 show termlog | grep"rebuild"
在线查看日志抽取关键字。
(3)storcli /c0 show events/termlog/alilog > storcli.events/storcli.termlog/ storcli.alilog
将日志存储为文件。
注释:用于debug的RAID卡日志主要有以下两个:alilog与fwtermlog。其中:
fw termlog为仅次于串口输出的操作记录,能够记录控制器工作过程中的详细信息,主要用于反馈给官方进行debug;
Alilog也是记录控制器的各项操作,但是详细程度不及fwtermlog,但是内容比较直观,适合现场工程师等受众进行简单查看与分析。
机房环境主要包括机房内部的空调和供电设备等。
对线缆的巡检,建议肉眼查看即可。如果需要重新拔插,必须征得客户的同意。巡检线缆布局前为防止损坏线缆,需注意以下事项:
检查电源线。
保证线缆远离热源,线缆避免紧绷,保持适度松弛。
插拔线缆时,不要用力过大。
尽可能通过连接端口插拔线缆。
任何情况下,禁止扭曲或者拉扯线缆。
合理布线,保证需要拆卸或者更换的部件不会接触线缆,确保所有电源线正确连接。
服务器巡检,需要征得客户同意并且对机器只能做查看操作。未经客户书面授权同意,严禁对服务器做任何修改配置、上下电操作、部件插拔和线缆改动。
服务器巡检前,需要提前获取巡检机器的BMC地址、IP地址、root或Administrator账户密码。巡检完成后,需要通知客户及时更新root或Administrator账户密码。
服务器前后面板分别提供UID按钮/指示灯、健康状态指示灯、网口指示灯、电源指示灯等。通过观察指示灯状态可初步诊断当前服务器状态。具体指示灯状态及处理方法请参见6.6根据指示灯诊断。
用户可通过BMC告警信息,进行详细地诊断与故障定位。其中,告警信息涉及:Chassis告警说明、CPU告警说明、内存告警说明、硬盘告警说明、电源告警说明、风扇告警说明等。
具体参见:《BMC告警说明用户文档》。
综上,具体的巡检内容如表9‑1:
表9‑1 巡检内容
|
现场健康状态检查 |
服务器面板告警灯状态; 主机风扇运转检查,观察并用手感觉进风和出风是否正常 主机运转噪音检查,仔细听系统运转声音 ; 服务器硬盘工作状态,硬盘指示灯指示是否正常,一般绿色为正常; 服务器网卡工作状态,有数据传输,则网卡指示灯呈现规律性闪烁; 服务器电源连接检查,电源连接线是否有松动、接触不良等情况; 检查是否存在其他影响设备状态的相关因素; 发现设备故障后的软硬件维修服务(如无法现场解决故障,则拨打服务热线进行报修) |
|
服务器硬件日志分析 |
通过Mgmt口登录BMC平台查看非直观可视的服务器健康状态和告警日志信息 收集服务器硬件日志信息(主板/黑盒/Raid卡日志/HBA卡/网卡/磁盘SMART信息等),交由厂商分析,检查是否存在未报警的故障隐患 |
|
固件校验 |
校验服务器设备的固件版本 提供最新的版本建议,以及重要问题修复说明 |
|
故障回顾 |
分析本季度维修记录 |
|
本月巡检问题汇总 |
汇总本次巡检中发现的问题 |
(1)巡检信息
表9‑2 巡检信息汇总表(客户)
|
客户信息 |
|||
|
客户名称 |
|
||
|
机房地址 |
|
机房名称 |
|
|
机房主管 |
|
电话 |
|
表9‑3 巡检信息汇总表(巡检人)
|
巡检方信息 |
|||
|
巡检时间 |
|
||
|
巡检人 |
|
电话 |
|
|
产品接口人 |
|
电话 |
|
(2)总结及建议
尊敬的客户:您好!
巡检主要目的是对您所购买的服务器进行全面检查,及早发现潜在问题,提交详细检查报告及问题的针对性建议,提高业务的可用性。本公司的工程师有责任将检查的结果向您汇报。如果您已了解此次巡检服务的内容,请针对本次巡检的结果提出意见和建议并签字确认。
表9‑4 巡检总结及意见(巡检人)
|
工程师巡检总结及意见 |
|||||
|
|
|||||
|
巡检工程师 |
|
电话 |
|
日期 |
|
表9‑5 巡检反馈与意见(客户)
|
客户对巡检结果的反馈与建议 |
|||||
|
|
|||||
|
客户 |
|
电话 |
|
日期 |
|
①服务器产品的特性与规格信息;②服务器硬件的结构、规格、安装和更换等信息;③服务器软件的功能和配置方法等信息。
相关文档主要为:用户手册。
请联系售后工程师。
OS兼容性查询工具:查询服务器兼容的操作系统。
服务器兼容的部件查询工具:查询服务器部件和操作系统的兼容性。
部件兼容的服务器查询工具:查询部件兼容的所有服务器。
请联系售后工程师。
介绍BMC的告警日志信息,包含日志的内容、参数介绍、等级、含义和处理建议等,为用户进行系统诊断和维护提供参考。
请联系售后工程师。
驱动涉及的部件包括:外插网卡、SAS RAID卡/HBA卡、FC HBA卡;
固件涉及到的部件或软件包括:BMC、BIOS、CPLD、网卡、SAS RAID卡/HBA卡、FC HBA卡等。
固件/驱动下载:访问H3C官网,单击:支持![]() 文档与软件
文档与软件![]() 软件下载,在按产品检索处选择“服务器”,在“支持机型”处选择服务器信息,在“版本类别处”选择驱动或固件,在“组件类型”处选择所需的组件类别,在“操作系统”处选择需要的系统(固件不涉及),进行查询与下载。
软件下载,在按产品检索处选择“服务器”,在“支持机型”处选择服务器信息,在“版本类别处”选择驱动或固件,在“组件类型”处选择所需的组件类别,在“操作系统”处选择需要的系统(固件不涉及),进行查询与下载。
请联系售后工程师。













