











互联网
互联网企业是指以计算机网络技术为基础, 利用网络平台提供服务并因此获得收入的企业。这些企业可以分为广义和狭义两种。









AI大模型训练规模已跃升至数十万卡,400G/ 800G高速组网成为核心支撑,单设备高速端口数值接决定超大规模集群的组网能力

硬件性能瓶颈、传统协议丢包率高及AI流量突发,持续制约高算力连接效率;MoE模型普及带来 All-to-All流量激增,进一步加剧网络压力

复杂组网人工开局低效,AI训练流量突发监控缺失和跨域故障难回溯,导致智算场景算力联接可用率大幅降低
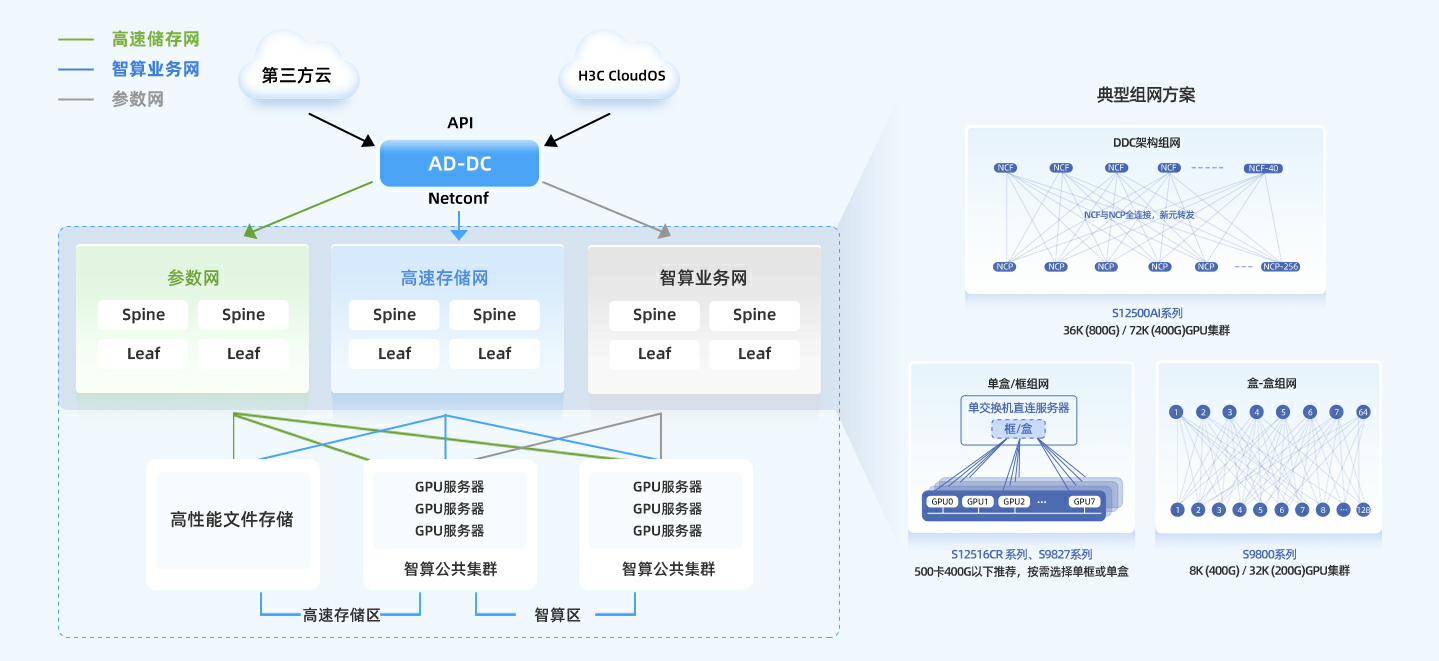
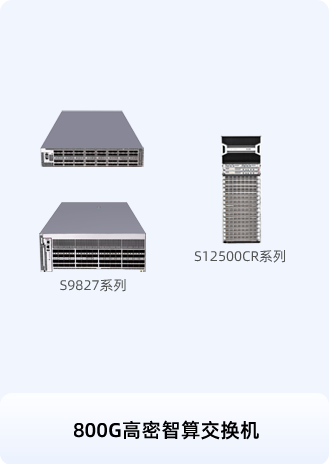
依托业内最完整的盒式/框式组网方案,实现单POD大规模组网能力达到行业主流水平的16倍
支撑万卡级集群建设,有效突破大模型训练中的联接规模瓶颈
独创"多轨架构+路径导航"技术组合,训练效率提升20%
DDC架构实现100%负载均衡,All to All场景下性能表现媲美InfiniBand方案
端网融合部署,开局效率提升10倍
端到端硬件健康状态全息感知,可靠性提升10倍
AI训练全程可跟踪、问题可追溯,提升排障效率

基于DDC架构的新一代无损网络方案

Scale-out &Scale-up谁才是智算中心关键互联技术

智算中心“Pod 从“小房子”到“大house”加速AI训练与推理

探秘智算之SprayLink逐包喷洒技术

探秘智算之LBN端口对称HASH技术

VOQ+Credit 根治网络阻塞

为什么需要更加开放解耦的智算网络中心

探秘智算网络负载均衡技术(一):LBN

探秘智算网络负载均衡技术(二):DLB

如何打造算力持续增长的AI智算中心?(一)
如何打造算力持续增长的AI智算中心?(二)






















