| Title | Size | Downloads |
|---|---|---|
| H3C SeerEngine-Campus Troubleshooting Guide-E32xx-5W200-book.pdf | 450.89 KB |
- Table of Contents
- Related Documents
-
|
|
|
H3C SeerEngine-Campus |
|
Troubleshooting Guide |
|
|
Document version: 5W200-20211126
Copyright © 2021 New H3C Technologies Co., Ltd. All rights reserved.
No part of this manual may be reproduced or transmitted in any form or by any means without prior written consent of New H3C Technologies Co., Ltd.
Except for the trademarks of New H3C Technologies Co., Ltd., any trademarks that may be mentioned in this document are the property of their respective owners.
The information in this document is subject to change without notice.
Contents
Collecting diagnosis log messages
Troubleshooting product licensing
Cannot get licensing data from the license server after a controller team reboot
Inconsistent master controller role on the OpenFlow instance and a controller
Troubleshooting diagnosis logs
Diagnosis log exporting failure
Network device information display failure
Troubleshooting carrier networks
Physical network element activation failure
Automatic region configuration failure
Troubleshooting the DHCP service
User or device failed to obtain IP address from Microsoft DHCP server
User cannot obtain expected IP address
Inconsistent primary/secondary Microsoft DHCP server configuration in HA mode
IP address displayed as BAD_ADDRESS in address lease on Microsoft DHCP server
Controller failed to deploy configuration to vDHCP servers in HA mode
Troubleshooting the collaboration between the EIA server and controllers
Data synchronization status as unsynchronized between the EIA server and controllers
Introduction
This document provides information about troubleshooting common software and hardware issues with H3C SeerEngine-Campus controllers.
General guidelines
To help identify the cause of the issue, collect system and configuration information, including:
· Versions of the SeerEngine-Campus controller, Linux operation system, SNA Center, EIA, and DHCP server.
· Symptom, time of failure, and configuration.
· Network topology information, including the network diagram, port connections, and points of failure.
· Log messages and diagnostic information. For more information, see "Collecting diagnosis log messages."
· Steps you have taken and their effects.
Collecting diagnosis log messages
1. Enter the URL of SNA Center in the address bar of a browser (for example, Chrome) to enter the SNA Center login page.
The URL is in the format of https://snacenter_ip_address:10443/portal/. If HTTPS is not available due to policy limitations, you can enter the URL in the format of http://snacenter_ip_address:10080/portal/ to log in to the controller through HTTP.
2. On the login page, enter the username and password, and click Log in.
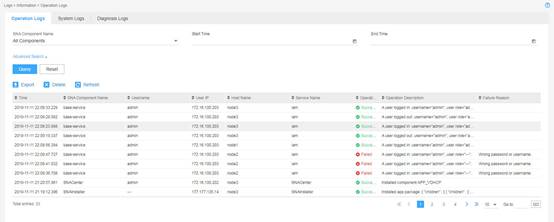
3. Click Settings, click Logs on the top navigation bar, and then select Information from the navigation pane. The page that opens displays operation, system, and diagnosis logs. You can click a tab to view the corresponding log entries.
¡ To filter log entries by component or time, specify the filtering criteria and click Query.
¡ To filter log entries by username, user IP, host name, service name, module name, operation result, operation description, or failure reason, click Advanced Search.
¡ To export the filtered log entries, click Export.
Figure 1 Log information page
Contacting technical support
If you cannot resolve an issue after using the troubleshooting procedures in this document, contact H3C Support.
The following is the contact information for H3C Support:
· Telephone number—400-810-0504.
· E-mail—[email protected].
Troubleshooting product licensing
This section provides troubleshooting information for common product licensing issues.
Cannot get licensing data from the license server after a controller team reboot
Symptom
A controller team restarts and has established a connection with the license server. The license for the controller team has been installed at the license server. However, the controller team cannot get the licensing data from the license server.
Solution
This symptom might occur if the controller team reconnects to the license server before the license server aging timer for the last connection expires. The license server does not reclaim the licensing data from an unexpectedly disconnected license client (the controller team) until the aging timer expires.
To resolve the issue:
1. Log in to the license server, and kick off the license clients that were disconnected from the license server unexpectedly.
2. Log in to SNA Center, click Application Driven Campus Network to log in to the SeerEngine-Campus controller, and then perform the following tasks:
a. Click System on the top navigation bar and then select License from the navigation pane
b. On the page that appears, disconnect the controller from the license server, and reconnect to the license sever.
3. If the issue persists, contact H3C Support.
Troubleshooting teams
This section provides troubleshooting information for common team issues.
Node hardware failure
Symptom
A node in the Matrix cluster cannot operate correctly because of hardware failure and needs to be replaced.
Solution
To resolve the issue:
1. Execute the following command on the master node to release the IP addresses used by the faulty node (node matrix02 in this example):
[root@matrix01 ~]# sh /opt/matrix/k8s/disaster-recovery/recovery.sh matrix02
2. Replace the faulty node with a new server. Make sure new server have the same IP settings, username, and password as the faulty node.
3. Copy folder /opt/matrix/app/install from the master node to the corresponding directory of the new server.
4. Install the Matrix platform on the new server. For more information, see H3C Matrix Containerized Application Deployment Platform Installation Guide.
5. Log in to the Matrix platform. Click DEPLOY on the top navigation bar and then select Cluster from the navigation pane.
6. Disable and then enable the faulty node. To
disable or enable a node, click the ![]() icon for
the node and then select Disable or Enable.
icon for
the node and then select Disable or Enable.
Troubleshooting regions
This section provides troubleshooting information for common region issues.
Inconsistent master controller role on the OpenFlow instance and a controller
Symptom
When an OpenFlow instance is connected to multiple controllers in different regions, the master controller role is inconsistent on the OpenFlow instance and a controller.
Solution
This symptom might occur if an OpenFlow instance is connected to two controllers in different regions or more than two controllers.
When the OpenFlow instance is connected to a controller in a region, the controller issues its configured role (master or subordinate) to the OpenFlow instance. If the OpenFlow instance is then connected to the controllers in another region, the original master controller on the OpenFlow instance will be overwritten.
For example, an OpenFlow instance is connected to controller A (master) and controller B (subordinate) in Region A. Then, the OpenFlow instance is connected controller C (master) and Controller D (subordinate) in Region B. On the OpenFlow instance, controller C is the master and the other three are subordinates. However, controller A still determines that it is the master for the OpenFlow instance.
To resolve the issue:
1. Verify that an OpenFlow instance is connected to only two controllers in a region.
¡ If the instance is connected to multiple controllers, delete unnecessary controllers and make sure the remaining two controllers are in the same region.
¡ If the instance is connected to two controllers in different regions, modify the region configuration to assign the two controllers to the same region.
2. If the issue persists, contact H3C Support.
Troubleshooting diagnosis logs
This section provides troubleshooting information for common diagnosis log issues.
Diagnosis log exporting failure
Symptom
When diagnosis log entries are downloaded from the Web interface, the page displays exporting failure at the end of the progress bar and the downloaded file cannot be opened.
Solution
This symptom might occur if the log mounting directory is deleted on the cluster node.
To resolve the issue:
1. Access the CLI for the node, and execute the ls -al /opt/matrix/app/data/VcfcCampus/log/log-tmp command to identify whether the log mounting directory still exists.
¡ If the directory does not exist, go to step 2.
¡ If the directory exists, go to step 3.
2. Execute the docker ps | grep log | grep VcfcCampus | grep -v "POD" | awk '{cmd="docker stop "$1;system(cmd)}' command to reboot the container. Then, wait for 1 to 2 minutes, and try to export diagnosis logs again.
3. If the issue persists, contact H3C Support.
Troubleshooting OpenFlow
This section provides troubleshooting information for common OpenFlow issues.
OpenFlow connection failure
Symptom
No device information is displayed for a correctly configured OpenFlow device (spine or leaf device) after you access the Assurance > Controller Info page on the controller's GUI and click the region link for the controller.
Solution
To resolve the issue:
1. Log in to the OpenFlow device and verify that the controller IP address specified for the OpenFlow device is correct. If the controller IP address is incorrect, specify the correct controller IP address on the OpenFlow device as shown in Figure 2.
Figure 2 Specifying the controller IP address

2. Verify that the controller IP address is reachable. If the controller IP address is reachable, troubleshoot the network.
3. If the issue persists, contact H3C Support.
Unstable OpenFlow connection
Symptom
The OpenFlow connection established between the controller and the OpenFlow device is unstable.
Solution
To resolve the issue:
1. Verify that the network is connected. If the network is disconnected, troubleshoot the network.
2. Verify that traffic congestion does not occur in the region.
If traffic congestion occurs in the region, OpenFlow echo messages cannot be exchanged correctly. Execute the netstat -anp | grep 6633 command as a root user to identify whether the TCP channel for the OpenFlow connection is occupied. As shown in Figure 3, if the values for the first and the second columns are in the range of 200000 to 250000, the traffic in the region is heavy. You can disconnect OpenFlow connections for some OpenFlow devices and then connect these devices to controllers in other regions.

3. If the issue persists, contact H3C Support.
Network device information display failure
Symptom
When you access the Provision > Inventory > Devices page on the controller's GUI, the Physical Devices tab cannot display device summary and port information.
Solution
To resolve the issue:
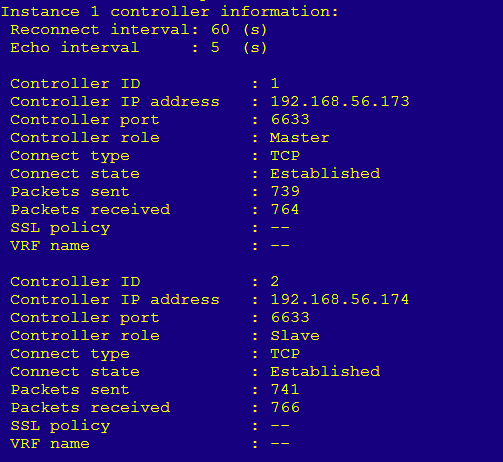
1. Log in to the OpenFlow device, and execute the display openflow instance instance-id controller command to verify that the controller role is correctly assigned to the OpenFlow device.
This example uses OpenFlow instance 1. If the controller role is Equal, create a region on the controller or connect the OpenFlow device to a controller in a region.
Figure 4 Controller role assigned to the OpenFlow device
2. Verify that the region to which the OpenFlow device is connected is configured correctly.
a. Access the PROVISION > Network Design > Fabrics > Fabric [xx] > Switching Device [xx] > Switching Device Details page on the controller's GUI to identify whether region information is displayed for the OpenFlow device.
If the region information is not displayed, export the diagnosis log messages for the controller. For more information, see "Collecting diagnosis log messages."
b. Identify whether the MAC address of the OpenFlow device exists in the Global Master Cache field in the RegionInfo log file exported.
If the MAC address of the OpenFlow device does exist in the Global Master Cache field, disconnect the OpenFlow device from the controller and reconnect the device to the controller.
As a best practice, do not disconnect and reconnect the OpenFlow device if the service traffic can be processed correctly when the symptom appears.
3. If the issue persists, contact H3C Support.
Troubleshooting NETCONF
This section provides troubleshooting information for common NETCONF issues.
NETCONF communication failure
Symptom
The controller fails to use SOAP to issue NETCONF configuration. For example, after a network element is added, its state is inactive and the system displays either of the following error messages:
· OpenFlow connection is down.
· NETCONF connection fails due to network congestion.
Solution
To resolve the issue:
1. Verify that the network device and the controller are physically connected:
a. Log in to the controller, and examine the cable connection status and link status.
b. Log in to the network device, and examine the cable connection status and link status.
2. Verify that the NETCONF settings are consistent on the network device and the controller:
a. Make sure NETCONF over SOAP over HTTPS is enabled on the network device.
b. Make sure the network device and the controller are configured with the same username and password.
If any inconsistency occurs, modify the NETCONF settings on the network device or the controller.
3. Verify that a NETCONF session can be established between the network device and the controller.
There is a limit on the number of NETCONF sessions that can be established on the network device. If the upper limit has been reached, the network device cannot establish a NETCONF session with the controller. In this case, delete the existing NETCONF sessions or increase the NETCONF session limit to ensure that a NETCONF session can be established between network device and the controller.
4. If the issue persists, contact H3C Support.
Troubleshooting SNMP
This section provides troubleshooting information for common SNMP issues.
SNMP communication failure
Symptom
Configuration cannot be issued to a newly added access device. The device is in inactive state and the system prompts configuration deployment uncompleted.
Solution
|
|
IMPORTANT: Perform steps 1 and 2 on both the access device and its leaf device. |
To resolve the issue:
1. Verify that the device and the controller can reach each other. You can log in to the controller and the device to verify the network connection and link state.
2. Verify that the device and the controller are both enabled with SNMP and have consistent SNMP settings, read/write community string for example.
3. If the issue persists, contact H3C Support.
Troubleshooting LLDP
This section provides troubleshooting information for common LLDP issues.
LLDP communication failure
Symptom
Configuration cannot be issued to a newly added access device. The device is in inactive state and the system prompts configuration deployment uncompleted.
Solution
|
|
IMPORTANT: Perform steps 1 and 2 on both the access device and its leaf device. |
To resolve the issue:
1. Verify that the device and the controller can reach each other. You can log in to the controller and the device to verify the network connection and link state.
2. Verify that the device and its directly connected leaf or access device are configured with LLDP correctly. For example, verify that LLDP is enabled on these devices globally and on related interfaces.
3. If the issue persists, contact H3C Support.
Troubleshooting carrier networks
This section provides troubleshooting information for common carrier network issues.
Physical network element activation failure
Symptom
A physical network element remains in inactive state after it is created.
Solution
To resolve the issue:
1. Verify the number of physical network elements managed by the controller. If the number exceeds the limit allowed by the licenses, purchase new licenses.
2. Verify that the physical network element and the controller can ping each other by using the management IP of the physical network element. If the ping operation fails, troubleshoot the network connection issue.
3. If the physical network element type is gateway, verify that the physical network element has joined a gateway group.
4. Verify that NETCONF communication between the physical network element and the controller succeeds. If NETCONF communication fails, troubleshoot NETCONF. For more information, see "Troubleshooting NETCONF."
5. Verify that the controller and the physical network elements can reach each other through SNMP operations. For more information, see "SNMP communication failure."
6. Verify that the physical network elements can reach each other through LLDP. For more information, see "LLDP communication failure."
7. Verify that a region is automatically selected for the physical network element if the controller operates in team mode:
a. Click Provision on the top navigation bar, and then select Network Design > Fabrics from the left navigation pane.
b. Select a fabric and view the Selected Region field. If --- is displayed, troubleshoot automatic region configuration failure. For more information, see "Automatic region configuration failure."
8. If the issue persists, contact H3C Support.
Automatic region configuration failure
Symptom
A network element fails to automatically select a region when the controller operates in team mode.
Solution
To resolve the issue:
1. Verify that a region is configured for the team:
a. Click the gear icon at the upper right corner of the page, and select Controller from the left navigation pane.
b. Click Region to identify whether a region is configured. If no region is configured, configure a region for the team.
2. Verify that the management IP address of the network element belongs to the managed subnets of the configured region:
a. On the Region page, view the Managed Subnets field.
If the management IP address of the network element does not belong to the managed subnets, perform either of the following tasks:
- Create a new region without any managed subnets.
- Click the Edit icon in the Actions field for the region to add the network segment of the management IP address.
3. If the issue persists, contact H3C Support.
Troubleshooting the DHCP service
This section provides troubleshooting information for common DHCP service issues.
User or device failed to obtain IP address from Microsoft DHCP server
Symptom
In the Windows scenario, a user or device newly coming online cannot obtain an address from the DHCP server, so the user or device cannot properly come online.
Solution
Possible reasons are:
· The DHCP server fails, and the DHCP service is not properly started.
· Port 67 for the DHCP server is occupied and cannot provide services.
· The operating system does not meet the requirements. As a result, the scope on the DHCP server is not a superscope, and the policy is not properly deployed.
· The VLAN4094 address pool is not configured on the controller.
To resolve this issue:
1. Log in to the Windows operating system. Identify whether the DHCP service is properly started. If the DHCP service is not started, start the DHCP service.
2. Identify the usage of port 67 on the DHCP server. Execute the netstat -ano | findstr 67 command to identify whether port 67 is occupied. If port 67 is occupied, end the process that occupies the port.
3. Identify whether the operating system version meets the requirements. The operating system version must be Windows Server 2008 R2 with Service Pack 1 or Windows Server 2012 R2. If the operating system version does not meet the requirements, upgrade the operating system to the required version.
4. Log in to the controller, and identify whether the VLAN4094 address pool is configured on the controller. If the VLAN4094 address pool is not configured on the controller, configure the VLAN4094 address pool.
5. If the issue persists, contact H3C Support.
User cannot obtain expected IP address
Symptom
A client failed to obtain an expected IP address from the DHCP server.
Solution
Possible reasons are:
· When the client comes online, the sent DHCP request packet carries the old IP address in Option 50.
· On the DHCP server, the relay agent information (Option 82 policy) is not configured or incorrectly configured.
· A DHCP snooping entry of the device carries the old IP address. The device sends the old IP address to EIA through accounting packets, and EIA binds the IP address to the client MAC address. When the client comes online, the client obtains the old IP address.
· During the process of deleting reserved IP addresses, the address leases are first deleted and then the reserved IP addresses are deleted. When an IP address is bound on the DHCP server, the DHCP server first identifies whether the IP address has a lease. If the IP address has a lease, DNS deregistration is first performed for the lease. During the DNS deregistration process, the client MAC address becomes the virtual dummyhwaddress (for example, 0789010a00000000). In this case, the IP address is bound to the virtual MAC address rather than an actual MAC address. As a result, when the client comes online, the client is assigned a new IP address rather than the expected IP address.
To resolve the issue:
1. Capture packets, and identify whether Option 50 in the Discover packets from the client carries an IP address. If Option 50 carries an IP address, the system requires preferentially assigning the address. As a result, the client cannot be assigned the expected address. In this case, restart the NIC of the client, so that the Discover packet from the client does not carry the specified IP address.
2. Make sure the relay agent information is consistent with the VLAN ID of the security group configured on the controller.
a. Log in to the DHCP server, select the policy for the specified scope, and view the circuit ID in the relay agent information of the policy.
b. Make sure the circuit ID is the same as the VLAN ID in the security group.
3. Clear the MAC address entry corresponding to the DHCP snooping entry on the device, clear the IP-MAC binding on EIA, and manually bind the MAC address to a correct IP address. The client can obtain a correct IP address when coming online again.
4. Clear the reserved IP addresses on the DHCP server, and then bind the IP address to a correct IP address. On EIA, set the endpoint aging time and IP binding aging time (360 days), and try to avoid the IP binding addition and deletion operations.
5. If the issue persists, contact H3C Support.
Inconsistent primary/secondary Microsoft DHCP server configuration in HA mode
Symptom
In the Windows environment, the primary and secondary DHCP server configurations are inconsistent in HA mode.
Solution
1. In the Windows environment where DHCP servers are deployed in HA mode, make sure the computer name of each operating system is unique. If the computer names conflict, perform one of the following tasks:
¡Take the Windows Server 2012 R2 operating system as an example.
- Right-click Computer on the desktop and select Properties.
- Click Change settings in the Computer name, domain, and workgroup settings area.
- On the dialog box that opens, click the Change (C)... button. Enter a new computer name, and click OK.
- The system will restart to change the computer name.
¡Modify the computer name through initializing the operating system as follows:
- Click Start > Run, and enter sysprep.
- Double-click sysprep on the window that opens.
- Select Generalize and then click OK on the dialog box that opens
- The system will automatically restart to automatically modify the computer name.
2. Identify whether the installed DHCP plug-in (iMC DHCP PLUG) has the super user privilege. If the plug-in does not have the super user privilege, you must assign the super user privilege to the DHCP plug-in on the primary and secondary servers.
3. If the issue persists, contact H3C Support.
IP address displayed as BAD_ADDRESS in address lease on Microsoft DHCP server
Symptom
In a scope on the DHCP server, an IP address is displayed as BAD_ADDRESS in the address lease.
Solution
Possible reasons are:
· The specified IP address has been statically assigned, but has not been excluded on the DHCP server. When a client dynamically obtains the IP address, the client will send a Decline packet to the DHCP server due to address conflict.
· The IP addresses in the network have been statically assigned, and address conflict detection is enabled on the DHCP server. As a result, the static IP addresses will be displayed as BAD_ADDRESS.
· Other DHCP servers exist in the network.
To resolve the issue:
1. Delete static addresses in the network, and configure all addresses to be obtained from the DHCP server. Alternatively, configure static addresses as reserved IP addresses or excluded IP addresses on the DHCP server.
2. Remove other DHCP servers from the network.
3. If the issue persists, contact H3C Support.
Controller failed to deploy configuration to vDHCP servers in HA mode
Symptom
The controller failed to deploy configuration to vDHCP servers in HA mode.
Solution
1. Identify whether the NETCONF sessions are normal. Make sure the NETCONF sessions between the controller and the primary and secondary DHCP servers are normal.
2. Log in to the vDHCP server, and verify that the primary/secondary role of the vDHCP server is normal.
3. If the issue persists, contact H3C Support.
Troubleshooting the collaboration between the EIA server and controllers
This section provides troubleshooting information for common EIA-controller collaboration issues.
Data synchronization status as unsynchronized between the EIA server and controllers
Symptom
· When you add a security group, the system prompts that the security group fails to be added for the reason that the authentication server data has not been synchronized.
· On the PROVISION > Basic Services > AAA page, view the data synchronization status between the EIA server and the controller. The status is Unsynchronized.
Solution
Possible reasons are:
· The connectivity between the controller and EIA server is abnormal.
· The controller is wholly restarted.
To resolve this issue:
1. Identify whether the connectivity between the controller and EIA server is normal. If the connectivity is abnormal, troubleshoot the network.
2. Access the PROVISION > Basic Services > AAA page, and click Synchronize Data to manually synchronize data.
3. If the issue persists, contact H3C Support.
