- 产品与解决方案
- 行业解决方案
- 服务
- 支持
- 合作伙伴
- 关于我们




上一期,我们详细介绍了网络可视化技术的需求根源以及早期的1.0和2.0时代。通过gRPC等网络可视化技术,网络工程师已经可以实现应用层面的网络流量感知和一定程度的主动监控。但伴随网络在业务中的比重越来越高,业务的网络的依赖和要求也水涨船高。由此,我们进入了网络可视化的3.0时代。
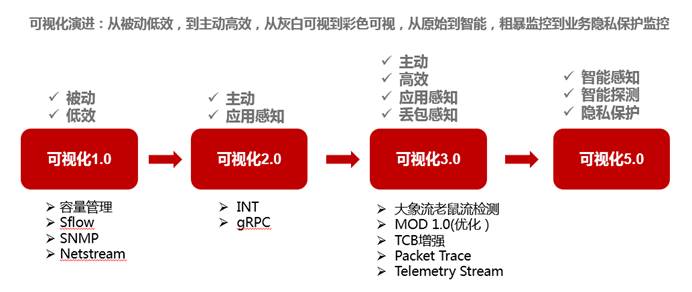
由图中我们看到了可视化3.0的关键技术点有大象流老鼠流检查、MOD、TCP增强、Packet Trace和Telemetry。
通过可视化2.0,设备已经具备了主动告警的能力,依靠gRPC和INT我们也能做到简单的应用感知,端到端数据每节点的延迟,相关接口buffer的监控我们也能开始初步把控。相比可视化1.0,这给网络问题的定位和流量转发的优化带来了长足的帮助。那么此时我们可能会有advance的要求:现网发生问题时能不能直接告诉我们确切原因,我们能不能准确的复现问题,并在修复问题后直接模拟问题是否复现,对流量对buffer我们能不能有更细力度的把控?
还记得我们《我看见,我管理(一)——网络可视化,网络工程师们的福音》开篇那张图吗?
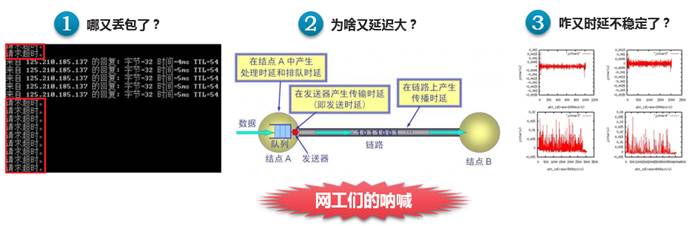
如果把可视化2.0方案比作网工解决问题的引路人的话,那么可视化3.0将是现网运维人员的直通车,他将主动的告诉你问题所在,让我们更高效的解决问题,更高效的优化网络。
那么,接下来就让我们换挡,进入可视化3.0时代。
老鼠流和大象流是网络可视化3.0当中两个逃不开的概念。
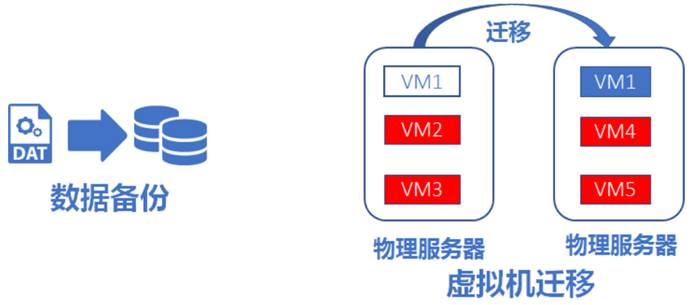
大象流,类似于数据备份流量,在网络中占用带宽很大,但对时延要求较低,如数据中心常见的数据批量备份和虚拟机迁移等业务:
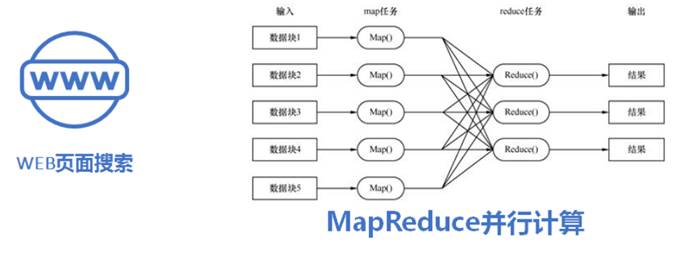
老鼠流,类似于业务查询流量,流量很小,但对要求快速响应,如大家常用的web搜索和MapReduce并行计算等业务:
在传统数据中心Spine-leaf网络架构中,流量一般是按照负载分担(ECMP)的方式进行调度,这里难免出现两个问题:
1. ECMP仅能根据报文中的特征值进行hash,所以难免出现将多条大象流调度至同一线路,将多条老鼠流调度至其他线路的现象,进而出现因负载分担导致的网络拥塞问题
2. 传统的设备不支持区分大象流和老鼠流的能力,当老鼠流和大象流在一条链路上出现拥塞时,无法有效的进行流量优先级调度。
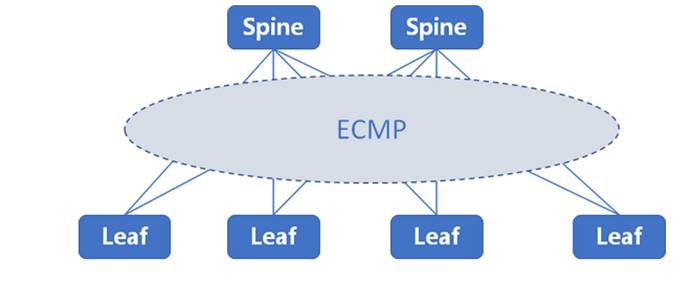
如果不能有效的解决数据中心网络中这两种流量的调度问题,难免会降低数据中心的网络性能。
那么我们应该如何解决呢?这里我们就来谈一下新华三的网络解决方案,也就是mice-elephant功能,如下图:

先让我来详细解释一下上述配置的效果:流量到达设备后,首先进行acl匹配,符合acl3000(上图中第9-10行配置)的流量将进入Flow group1的模板配置,进入该模板的流量会根据目的ip进行再进行细化统计(第11-12行配置),而其中速率为20kbp或流量大小为100kbytes的流量将定义为大象流(第15-16行配置),将其流量优先级(第17-18行配置,丢弃优先级dp设置为2,)降低。
这样就完美的解决了老鼠低延时而大象希望大带宽的诉求,各取所需。
不过基于此,我们引入了一个新的概念telemetry flow group,他又是做什么的呢?Flow Group是一种流表模板,用户可以为Flow Group指定流表的生成规则,设备依据流表生成规则提取流量特征,生成更详细的流表,如下图:
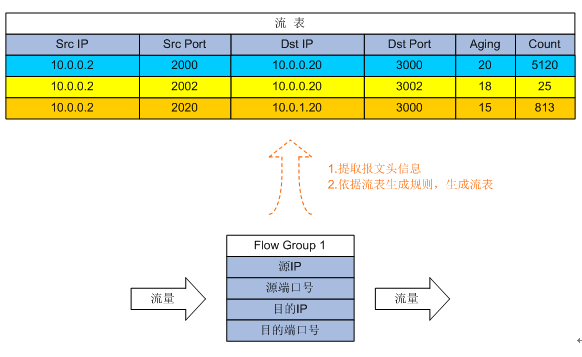
流量进入设备时,将进行telemetry flow group的ACL匹配,符合ACL的流量会根据Flow Group中template的配置进行更进一步的流表生成。如上图将根据五元组中的(源/目的IP和源/目的端口)进行重新表项生成和存储,并记录match该表项的流量详情(如aging time和通过的报文数量等),进而被更精细化的调度,如上文中提到的大象流和老鼠流功能。并且template中不仅能定义5元组,他还支持vxlan的表项匹配,以便更切合数据中心的网络业务。
flow group支持3种模式:MOD模式、简化MOD模式和大小流模式。其中大小流模式就是我们上文所说的大象流和老鼠流模式。
那么,MOD又是什么功能?
可视化3.0——MOD
在讲MOD的之前,我们不得不提运维网工们的另一个头疼问题——微量丢包。

我们可以做到24小时监控业务的流量运行情况,可以不间断收集链路质量的数据,但要解决流量的瞬时丢包问题,我们可能要排查上很长时间。究其原因就是定位难,24小时大量数据同步运行中的几百或几千个报文丢失原因的排查,犹如大海捞针。
在此,我来介绍一下MOD(Mirror On Drop),即丢包镜像功能,他可以检测报文在设备内部转发过程中是否发生丢包。当发生丢包时,设备会将丢包原因及丢弃报文的特征发送给采集器。这难道不是咱们运维人员的福音吗?
那MOD具体是怎么实现的呢?话不多说,上干货:
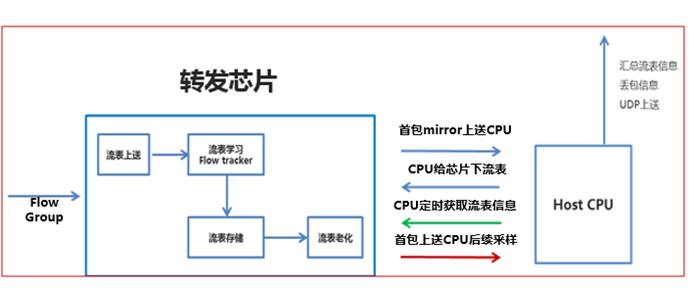
上图中详细的介绍了如何运用MOD解决现网中丢包定位难的问题,根据Flow group的细化表项统计能力,聚焦于问题业务段地址进行详细排查,先根据template中的配置进行流表学习,将新学习到的流表首包上送CPU,CPU生成相应表项下发给转发芯片,然后芯片进行存储。后续CPU即会周期性的获取流表信息,保证同步,芯片上的流表也会根据配置的采样比将报文上送CPU;若流表老化周期到达,且没有新的报文经过,即将相应流表进行删除,有效节约存储空间。
下面我们来一套具体配置(含具体配置解释),这样我们就一目了然了:

在此,新华三为现网问题量身定制了8大原因(上图右侧)聚焦于定位问题,如其中的IPv4 DIP miss就是目的地址不可达的问题描述,IPv4 L3 header error即为报文的IPv4三层头部有问题,相关问题原因直接呈现给运维人员,做到真正的深度问题原因可视。而且新华三的MOD功能还分为MOD和简化MOD两种模式,方便客户部署。MOD 1.0模式节约CPU能力;简化MOD模式节省硬件资源。
现在,我们知道流量优化和问题定位新华三能做到可管可视了,那么如果更深度的buffer问题,新华三有何建树呢?那么请让我来介绍一下可视化3.0的又一重要功能——TCB
上一节,我们提到了buffer的问题,很多同学也许会有困惑:管控buffer有这么重要吗?那我们就当下比较热门的RDMA技术为例,详细的说明一下buffer管控在数据中心组网的重要性吧。
RDMA,远程直接内存访问技术。这里我们要主要提的是RoCE(基于以太网的RDMA技术)特性的如何保障。众所周知,RoCE的关键技术诸如PFC,ECN,ETS和DCBX等均为保障RDMA业务端到端无损而推出,关键诉求就是通过合理的buffer来保障端到端的业务流量不丢包:
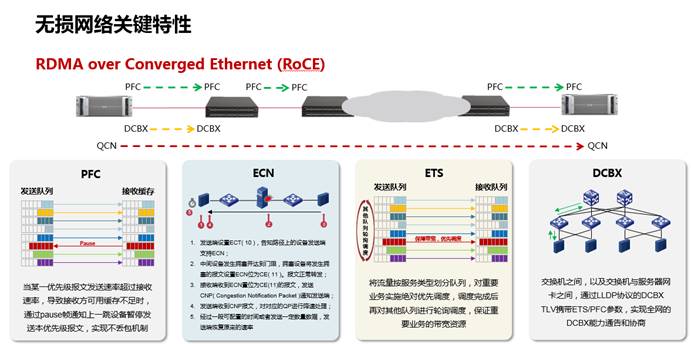
而RDMA虽然能带来良好的业务体验同时,但其对网络设备运维的要求也提高了,因为业务的故障可能不止是设备表项级或业务报文级的问题,还可能是接口或芯片buffer级的问题。
这时传统的定位或可视化手段就满足不了当今数据中心网络运维的需求了。这里就需要一套自动化可视分析管理系统配合使用,也就是新华三的先知系统,这点我们暂且按下不表,先说一下网络设备如何支持吧。而这也正是之前提到的TCB功能。
TCB(Transient Capture Buffer,瞬时抓包缓存)是一种用来监控MMU(Memory Management Unit,缓存管理单元)队列丢包的技术。开启TCB功能后,系统将持续监控队列。当队列发生丢包时,系统将收集丢包时间、丢包原因、丢包特征(源/目的IP地址,源/目的端口号,协议号等),丢包相关接口队列和被丢弃报文的原始数据等信息,并通过gRPC的方式将分析后的数据上报网管,方便网络管理员及时知晓设备上发生的丢包事件。
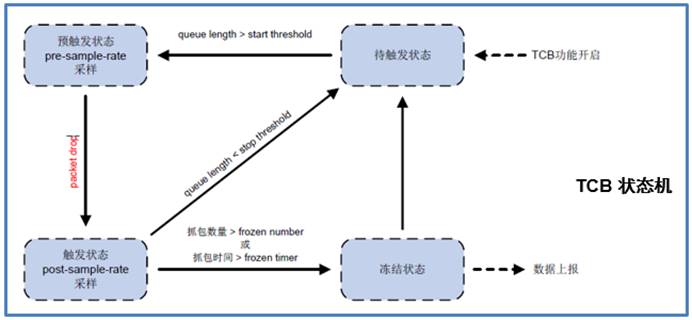
下面我们就来详细介绍一下TCB的状态机,如下图:
详细流程如下:
1. TCB功能被开启,设备相应接口进入待触发状态,开始检测;
2. 当流量队列长度大于start-threshold-value门限时,TCB状态机由待触发状态进入预触发状态,并使用pre-sample-rate对队列进行采样抓包;
3. 当流量队列发生丢包时,TCB状态机由预触发状态进入触发状态,并使用post-sample-rate对队列进行采样抓包;
4. 当流量队列长度小于stop-threshold-value门限时,设备停止抓包,TCB状态机由触发状态进入待触发状态;
5. 当TCB状态机处于待触发状态下,接口流量队列长度再次大于start-threshold-value门限时,重复步骤2;
6. 当抓包数量达到frozen-number或抓包时间达到timer-value时,TCB状态机由触发状态进入冻结状态;
7. TCB进入冻结状态后,相关模块会对丢包原因及丢弃报文特征等信息进行分析,并将分析结果发送给gRPC模块,由gRPC上报网管;
8. 上报后,TCB状态机将由冻结状态进入待触发状态,如此循环
这里总结一下TCB给网络运维带来的好处,如下图:
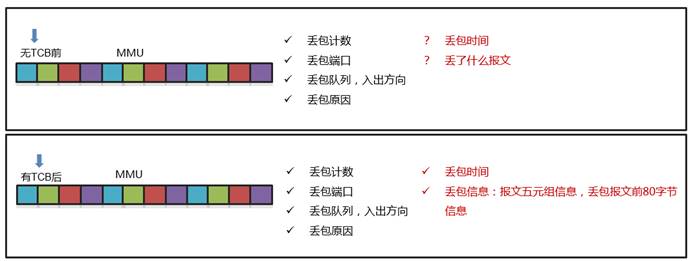
TCB功能补足传统可视化方案中基于buffer监控的能力,使数据中心网络更智能更细化的管理(接口或芯片buffer级),使诸如RDMA等业务更平稳的运行和管控。当问题发生时,详细原因和抓包的收集分析和上报,让问题第一时间可视,并可结合相关分析管理系统的能力(新华三先知系统),做到自动化网络保障。
网络可视化3.0,故事仍将继续
到这里,对于新华三可视化3.0方案的流量深度优化和定位的能力,大家应该get到了。
那么网络问题复现和确认问题是否修复?
对于能够支持未来网络自查自愈的功能,新华三又有哪些独到之处呢?
关于网络可视化的3.0时代,故事远未结束。下周,我们将继续网络可视化3.0的讨论;来看看 Packet trace、硬件Telemetry Stream以及即将到来的网络可视化5.0。
欢迎持续关注!









