- Table of Contents
- Related Documents
-
| Title | Size | Download |
|---|---|---|
| 01-Text | 2.26 MB |
Contents
Configuring Ethernet interfaces
Configuring a management Ethernet interface
Ethernet interface naming conventions
Configuring common Ethernet interface settings
Splitting a 40-GE interface and combining 10-GE breakout interfaces
Configuring basic settings of an Ethernet interface or Layer 3 Ethernet subinterface
Configuring the link mode of an Ethernet interface
Configuring jumbo frame support
Configuring physical state change suppression on an Ethernet interface
Configuring generic flow control on an Ethernet interface
Configuring PFC on an Ethernet interface
Enabling energy saving features on an Ethernet interface
Configuring a Layer 2 Ethernet interface
Configuring storm control on an Ethernet interface
Forcibly bringing up a fiber port
Setting the MDIX mode of an Ethernet interface
Testing the cable connection of an Ethernet interface
Configuring a Layer 3 Ethernet interface or subinterface
Setting the MTU for an Ethernet interface or subinterface
Displaying and maintaining an Ethernet interface
Configuring loopback, null, and inloopback interfaces
Configuring a loopback interface
Configuring an inloopback interface
Displaying and maintaining loopback, null, and inloopback interfaces
Configuration restrictions and guidelines
Displaying and maintaining bulk interface configuration
Configuring the MAC address table
How a MAC address entry is created
MAC address table configuration task list
Configuring MAC address entries
Adding or modifying a static or dynamic MAC address entry globally
Adding or modifying a static or dynamic MAC address entry on an interface
Adding or modifying a blackhole MAC address entry
Adding or modifying a multiport unicast MAC address entry
Disabling MAC address learning
Disabling global MAC address learning
Disabling MAC address learning on interfaces
Configuring the aging timer for dynamic MAC address entries
Enabling MAC address synchronization
Enabling MAC addresses learning at ingress
Displaying and maintaining the MAC address table
MAC address table configuration example
Configuring the MAC Information mode
Configuring the MAC change notification interval
Configuring the MAC Information queue length
MAC Information configuration example
Configuration restrictions and guidelines
Configuring Ethernet link aggregation
Aggregation group, member port, and aggregate interface
Aggregation states of member ports in an aggregation group
Aggregating links in static mode
Setting the aggregation state of each member port
Aggregating links in dynamic mode
How dynamic link aggregation works
Load sharing modes for link aggregation groups
Ethernet link aggregation configuration task list
Configuring an aggregation group
Configuration restrictions and guidelines
Configuring a static aggregation group
Configuring a dynamic aggregation group
Configuring an aggregate interface
Setting the description for an aggregate interface
Specifying ignored VLANs for a Layer 2 aggregate interface
Setting the MTU for a Layer 3 aggregate interface or subinterface
Setting the minimum and maximum numbers of Selected ports for an aggregation group
Setting the expected bandwidth for an aggregate interface
Configuring an edge aggregate interface
Enabling BFD for an aggregation group
Shutting down an aggregate interface
Restoring the default settings for an aggregate interface
Configuring load sharing for link aggregation groups
Setting load sharing modes for link aggregation groups
Enabling local-first load sharing for link aggregation
Enabling link-aggregation traffic redirection
Configuration restrictions and guidelines
Configuring the link aggregation capability for the device
Displaying and maintaining Ethernet link aggregation
Ethernet link aggregation configuration examples
Layer 2 static aggregation configuration example
Layer 2 dynamic aggregation configuration example
Layer 2 aggregation load sharing configuration example
Layer 3 static aggregation configuration example
Layer 3 dynamic aggregation configuration example
Layer 3 edge aggregate interface configuration example
Assigning ports to an isolation group
Displaying and maintaining port isolation
Port isolation configuration example
Configuring spanning tree protocols
Calculation process of the STP algorithm
MSTP implementation on devices
Spanning tree configuration task lists
Configuration restrictions and guidelines
Setting the spanning tree mode
Configuring the root bridge or a secondary root bridge
Configuring the current device as the root bridge of a specific spanning tree
Configuring the current device as a secondary root bridge of a specific spanning tree
Configuring the device priority
Configuring the maximum hops of an MST region
Configuring the network diameter of a switched network
Configuration restrictions and guidelines
Configuring the timeout factor
Configuring the BPDU transmission rate
Configuration restrictions and guidelines
Configuring path costs of ports
Specifying a standard for the device to use when it calculates the default path cost
Configuring path costs of ports
Configuring the port link type
Configuration restrictions and guidelines
Configuring the mode a port uses to recognize and send MSTP packets
Enabling outputting port state transition information
Enabling the spanning tree feature
Performing mCheck in interface view
Configuration restrictions and guidelines
Digest Snooping configuration example
Configuring No Agreement Check
No Agreement Check configuration example
Configuring protection features
Configuring port role restriction
Configuring TC-BPDU transmission restriction
Displaying and maintaining the spanning tree
Spanning tree configuration example
Loop detection configuration task list
Enabling loop detection globally
Enabling loop detection on a port
Setting the loop protection action
Setting the global loop protection action
Setting the loop protection action on a Layer 2 Ethernet interface
Setting the loop protection action on a Layer 2 aggregate interface
Setting the loop detection interval
Displaying and maintaining loop detection
Loop detection configuration example
Configuring basic VLAN settings
Configuring basic settings of a VLAN interface
Reserving VLAN interface resources
Reserving local-type VLAN interface resources
Reserving global-type VLAN interface resources
Configuration restrictions and guidelines
Introduction to port-based VLAN
Assigning an access port to a VLAN
Assigning a trunk port to a VLAN
Assigning a hybrid port to a VLAN
Displaying and maintaining VLANs
Port-based VLAN configuration example
Application scenario of one-to-one VLAN mapping
Application scenario of one-to-two and two-to-two VLAN mapping
Application scenario of zero-to-two VLAN mapping
Application scenario of two-to-three VLAN mapping
Configuration restrictions and guidelines
VLAN mapping configuration task list
Configuring one-to-one VLAN mapping
Configuring one-to-two VLAN mapping
Configuring zero-to-two VLAN mapping
Configuring two-to-two VLAN mapping
Configuring two-to-three VLAN mapping
Displaying and maintaining VLAN mapping
VLAN mapping configuration examples
One-to-one VLAN mapping configuration example
One-to-two and two-to-two VLAN mapping configuration example
Performing basic LLDP configuration
Configuring the LLDP bridge mode
Setting the LLDP operating mode
Setting the LLDP re-initialization delay
Configuring the advertisable TLVs
Configuring the management address and its encoding format
Setting an encapsulation format for LLDP frames
Enabling LLDP and DCBX TLV advertising
Configuring LLDP trapping and LLDP-MED trapping
Configuring Ethernet interfaces
The switch series supports Ethernet interfaces, management Ethernet interfaces, and Console interfaces. For the interface types and the number of interfaces supported by a switch model, see the installation guide.
This document describes how to configure management Ethernet interfaces and Ethernet interfaces.
Configuring a management Ethernet interface
A management interface uses an RJ-45 connector. You can connect the interface to a PC for software loading and system debugging.
To configure a management Ethernet interface:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter management Ethernet interface view. |
interface M-GigabitEthernet interface-number |
N/A |
|
3. (Optional.) Set the interface description. |
description text |
The default setting is M-GigabitEthernet0/0/0 Interface. |
|
4. (Optional.) Shut down the interface. |
shutdown |
By default, the management Ethernet interface is up. |
|
5. (Optional.) Set the duplex mode for the interface. |
duplex { auto | full | half } |
By default, the management Ethernet interface automatically negotiates the duplex mode with its peer. |
|
6. (Optional.) Set the speed for the interface. |
speed { 10 | 100 | 1000 | auto } |
By default, the management Ethernet interface automatically negotiates the speed with its peer. |
|
|
NOTE: Set the same speed and duplex mode for a management Ethernet interface and its peer port. |
Ethernet interface naming conventions
For a switch in an IRF fabric, its Ethernet interfaces are numbered in the format of interface type A/B/C/D. For a switch not in an IRF fabric, its Ethernet interfaces are numbered in the format of interface type B/C/D. The following definitions apply:
· A—Number of the switch in an IRF fabric.
· B—Slot number of the card in the switch.
· C—Sub-slot number on a card.
· D—Number of an interface on a card.
Configuring common Ethernet interface settings
This section describes the settings common to Layer 2 Ethernet interfaces and Layer 3 Ethernet interfaces/subinterfaces. You can set an Ethernet interface as a Layer 3 interface by using the port link-mode route command. For more information, see "Configuring the link mode of an Ethernet interface." For more information about the settings specific to Layer 2 Ethernet interfaces, see "Configuring a Layer 2 Ethernet interface."
Splitting a 40-GE interface and combining 10-GE breakout interfaces
Splitting a 40-GE interface into four 10-GE breakout interfaces
You can use a 40-GE interface as a single interface. To improve port density, reduce costs, and improve network flexibility, you can also split a 40-GE interface into four 10-GE breakout interfaces.
For example, you can split a 40-GE interface FortyGigE 1/0/16 into four 10-GE breakout interfaces Ten-GigabitEthernet 1/0/16:1 through Ten-GigabitEthernet 1/0/16:4.
After you split a 40-GE interface into four 10-GE breakout interfaces, reboot the device. The system deletes the 40-GE interface and creates the four 10-GE breakout interfaces.
Before rebooting a switch configured with this command, save the splitting configuration even if the switch is an IRF member switch.
To split a 40-GE interface into four 10-GE breakout interfaces:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter 40-GE interface view. |
interface interface-type interface-number |
N/A |
|
3. Split the 40-GE interface into four 10-GE breakout interfaces. |
using tengige |
By default, a 40-GE interface is not split and operates as a single interface. The 10-GE breakout interfaces split from a 40-GE interface support the same configuration and attributes as common 10-GE interfaces, except that they are numbered differently. A 40-GE interface split into four 10-GE breakout interfaces must use a dedicated 1-to-4 cable or a 1-to-4 fiber and transceiver modules. |
Combining four 10-GE breakout interfaces into a 40-GE interface
If you need higher bandwidth, you can combine the four 10-GE breakout interfaces into a 40-GE interface.
After you combine four 10-GE breakout interfaces into a 40-GE interface, reboot the device. The system deletes the four 10-GE breakout interfaces and creates the combined 40-GE interface.
Before rebooting a switch configured with this command, save the combining configuration even if the switch is an IRF member switch.
To combine four 10-GE breakout interfaces into a 40-GE interface:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter the view of a 10-GE breakout interface split from a 40-GE interface. |
interface interface-type interface-number |
N/A |
|
3. Combine the four 10-GE breakout interfaces into a 40-GE interface. |
using fortygige |
By default, a 40-GE interface is not split and operates as a single interface. After you combine the four 10-GE breakout interfaces, use a dedicated 1-to-1 cable or a 40-GE transceiver module and fiber. |
Configuring basic settings of an Ethernet interface or Layer 3 Ethernet subinterface
Configuring an Ethernet interface
You can configure an Ethernet interface to operate in one of the following duplex modes:
· Full—Interfaces can send and receive packets simultaneously.
· Half—Interfaces cannot send and receive packets simultaneously.
· Auto—Interfaces negotiate a duplex mode with their peers.
You can set the speed of an Ethernet interface or enable it to automatically negotiate a speed with its peer.
To configure an Ethernet interface:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Ethernet interface view. |
interface interface-type interface-number |
N/A |
|
3. Set the interface description. |
description text |
The default setting is in the format of interface-name Interface. For example, FortyGigE1/0/1 Interface. |
|
4. Set the duplex mode of the Ethernet interface. |
duplex { auto | full | half } |
This command is not applicable to 100-GE CXP interfaces and 100-GE CFP2 interfaces. Copper ports operating at 1000 Mbps or 10 Gbps and fiber ports do not support the half keyword. By default, 100-GE CXP interfaces and 100-GE CFP2 interfaces operate in full duplex mode, and other Ethernet interfaces automatically negotiate a duplex mode with the peer. |
|
5. Set the interface speed. |
speed { 10 | 100 | 1000 | 10000 | 40000 | 100000 | auto } |
By default, 100-GE CXP interfaces and 100-GE CFP2 interfaces operate at 100 Gbps, and other Ethernet interfaces automatically negotiate a speed with the peer. Support for the keywords varies by interface type. For more information, execute the speed ? command in interface view. |
|
6. Configure the expected bandwidth of the interface. |
bandwidth bandwidth-value |
By default, the expected bandwidth (in kbps) is the interface baud rate divided by 1000. |
|
7. Restore the default settings for the Ethernet interface. |
default |
N/A |
|
8. Bring up the Ethernet interface. |
undo shutdown |
By default, Ethernet interfaces are in up state. |
Configuring a Layer 3 Ethernet subinterface
Each of the Layer 3 interfaces and subinterfaces use one VLAN interface resource. To successfully create the Layer 3 interfaces and subinterfaces, use the reserve-vlan-interface command to reserve VLAN interface resources for them before you create them. For example, before creating four Layer 3 subinterfaces on a Layer 3 interface, you must reserve five VLAN interface resources by using the reserve-vlan-interface command.
To reserve global VLAN interface resources, specify the global keyword in the reserve-vlan-interface command. To reserve local VLAN interface resources, do not specify the global keyword. Reserved VLAN interface resources are local in this chapter.
Before creating a Layer 3 Ethernet subinterface, do not reserve a resource for the VLAN interface whose interface number matches the subinterface number. After you reserve a VLAN interface resource, do not create a Layer 3 Ethernet subinterface whose subinterface number is the VLAN interface number. A Layer 3 Ethernet subinterface uses the VLAN interface resource in processing tagged packets whose VLAN ID matches the subinterface number.
For more information about reserving VLAN interface resources, see "Configuring VLANs."
To configure a Layer 3 Ethernet subinterface:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Create an Ethernet subinterface and enter subinterface view. |
interface interface-type interface-number.subnumber |
N/A |
|
3. Set the description for the Ethernet subinterface. |
description text |
The default setting is interface-name Interface. For example, FortyGigE1/0/1.1 Interface. |
|
4. Restore the default settings for the Ethernet subinterface. |
default |
N/A |
|
5. Set the expected bandwidth for the Ethernet subinterface. |
bandwidth bandwidth-value |
By default, the expected bandwidth (in kbps) is the interface baud rate divided by 1000. |
|
6. Bring up the Ethernet subinterface. |
undo shutdown |
By default, Ethernet subinterfaces are in up state. |
Configuring the link mode of an Ethernet interface
|
|
CAUTION: After you change the link mode of an Ethernet interface, all commands (except the shutdown command) on the Ethernet interface are restored to their defaults in the new link mode. |
Each of the Layer 3 interfaces and subinterfaces use one VLAN interface resource. To successfully configure an Ethernet interface to operate in route mode, use the reserve-vlan-interface command to reserve a VLAN interface resource for the interface first. For example, before configuring four Layer 2 interfaces to operate in route mode, you must reserve four VLAN interface resources by using the reserve-vlan-interface command.
To reserve global VLAN interface resources, specify the global keyword in the reserve-vlan-interface command. To reserve local VLAN interface resources, do not specify the global keyword. Reserved VLAN interface resources are local in this chapter.
For more information about reserving VLAN interface resources, see "Configuring VLANs."
On the switch, Ethernet interfaces can operate either as Layer 2 or Layer 3 Ethernet interfaces (you can set the link mode to bridge or route).
To change the link mode of an Ethernet interface:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Ethernet interface view. |
interface interface-type interface-number |
N/A |
|
3. Change the link mode of the Ethernet interface. |
port link-mode { bridge | route } |
By default, an Ethernet interface operates in bridge mode. |
Configuring jumbo frame support
An Ethernet interface might receive some frames larger than the standard Ethernet frame size (called jumbo frames) during high-throughput data exchanges, such as file transfers. When the Ethernet interface is configured to deny jumbo frames, the Ethernet interface discards jumbo frames without further processing. When the Ethernet interface is configured with jumbo frame support, the Ethernet interface processes jumbo frames within the specified length.
To configure jumbo frame support:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Ethernet interface view. |
interface interface-type interface-number |
N/A |
|
3. Configure jumbo frame support. |
jumboframe enable [ value ] |
By default, the switch allows jumbo frames within 12288 bytes to pass through Ethernet interfaces. If you set the value argument multiple times, the most recent configuration takes effect. |
Configuring physical state change suppression on an Ethernet interface
The physical link state of an Ethernet interface is either up or down. Each time the physical link of an interface goes up or comes down, the interface immediately reports the change to the CPU. The CPU then performs the following operations:
· Notifies the upper-layer protocol modules (such as routing and forwarding modules) of the change for guiding packet forwarding.
· Automatically generates traps and logs to inform the user to take corresponding actions.
To prevent frequent physical link flapping from affecting system performance, configure physical state change suppression to suppress the reporting of physical link state changes. You can configure this feature to suppress only link-down events, only link-up events, or both. If an event of the specified type still exists when the suppression interval expires, the system reports the event.
When you configure this feature, follow these guidelines:
· To suppress only link-down events, configure the link-delay [ msec ] delay-time command.
· To suppress only link-up events, configure the link-delay [ msec ] delay-time mode up command.
· To suppress both link-down and link-up events, configure the link-delay [ msec ] delay-time mode updown command.
· Do not configure physical state change suppression on an interface with MSTP enabled.
· When you separately enable state change suppression for link-up and link-down events, both configurations take effect. For example, if you configure the link-delay [ msec ] delay-time mode up command and then configure the link-delay [ msec ] delay-time command, both commands take effect.
· If you configure this command multiple times for link-up or link-down events on an Ethernet interface, the most recent configuration takes effect.
To configure physical state change suppression on an Ethernet interface:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Ethernet interface view. |
interface interface-type interface-number |
N/A |
|
3. Set the link-down event suppression interval. |
link-delay delay-time |
By default, each time the physical link of an interface comes down, the interface immediately reports the change to the CPU. |
|
4. Set the link-up event suppression interval. |
link-delay [ msec ] delay-time mode up |
By default, each time the physical link of an interface goes up, the interface immediately reports the change to the CPU. |
|
5. Set the link-updown event suppression interval. |
link-delay [ msec ] delay-time mode updown |
By default, each time the physical link of an interface goes up or comes down, the interface immediately reports the change to the CPU. |
Configuring generic flow control on an Ethernet interface
To avoid packet drops on a link, you can enable generic flow control at both ends of the link. When traffic congestion occurs at the receiving end, the receiving end sends a flow control (Pause) frame to ask the sending end to suspend sending packets.
· With TxRx mode generic flow control enabled, an interface can both send and receive flow control frames. When congestion occurs, the interface sends a flow control frame to its peer. When the interface receives a flow control frame from the peer, it suspends sending packets.
· With Rx flow mode generic control enabled, an interface can receive flow control frames, but it cannot send flow control frames. When the interface receives a flow control frame from its peer, it suspends sending packets to the peer. When congestion occurs, the interface cannot send flow control frames to the peer.
As shown in Figure 1, when both Port A and Port B forward packets at the rate of 1000 Mbps, Port C will be congested. To avoid packet loss, enable flow control on Port A and Port B.
Figure 1 Flow control on ports

When TxRx mode generic flow control is enabled on Port B and Rx mode generic flow control is enabled on Port A:
· When Port C is congested, Switch B buffers the packet. When the buffered packets reach a size, Switch B learns that the traffic forwarded from Port B to Port C exceeds the forwarding capability of Port C. In this case, Port B sends generic pause frames to Port A and tells Port A to suspend sending packets.
· When Port A receives the generic pause frames, Port A suspends sending packets to Port B for a certain period, which is carried in the generic pause frames. Port B sends generic pause frames to Port A until congestion is removed.
To handle unidirectional traffic congestion on a link, configure the flow-control receive enable command at one end and the flow-control command at the other end. To enable both ends of a link to handle traffic congestion, configure the flow-control command at both ends.
To enable generic flow control on an Ethernet interface:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Ethernet interface view. |
interface interface-type interface-number |
N/A |
|
3. Enable generic flow control. |
·
Enable TxRx mode
generic flow control: ·
Enable Rx mode
generic flow control: |
By default, generic flow control is disabled on an Ethernet interface. |
Configuring PFC on an Ethernet interface
|
|
IMPORTANT: This feature is available only when the system operates in advanced mode. For more information about system operating modes, see Fundamentals Configuration Guide. |
PFC performs flow control based on 802.1p priorities. With PFC enabled, an interface requires its peer to suspend sending packets with the specified 802.1p priorities when congestion occurs. By decreasing the transmission rate, PFC helps avoid packet loss.
You can enable PFC for the specified 802.1p priorities at the two ends of a link. When network congestion occurs, the local device checks the PFC status for the 802.1p priority carried in each arriving packet. The device processes the packet depending on the PFC status as follows:
· If PFC is enabled for the 802.1p priority, the local device accepts the packet and sends a PFC pause frame to the peer. The peer stops sending packets carrying this 802.1p priority for an interval as specified in the PFC pause frame. This process is repeated until the congestion is removed.
· If PFC is disabled for the 802.1p priority, the local interface drops the packet.
To configure PFC on an Ethernet interface:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Ethernet interface view. |
interface interface-type interface-number |
N/A |
|
3. Enable PFC on the interface through automatic negotiation or forcibly. |
priority-flow-control { auto | enable } |
By default, PFC is disabled. |
|
4. Enable PFC for specific 802.1p priorities. |
priority-flow-control no-drop dot1p dot1p-list |
By default, PFC is disabled for all 802.1p priorities. |
When you configure PFC, follow these guidelines:
· To perform PFC on a network interface of an IRF member device, configure PFC on both the network interface and the IRF physical interfaces. For information about IRF, see IRF configuration Guide.
· As a best practice to ensure correct operations of IRF and other protocols, do not enable PFC for 802.1p priorities 0, 6, and 7.
· Make the same PFC configuration on all interfaces that traffic travels through.
· An interface can receive PFC pause frames whether or not PFC is enabled on the interface. However, only an interface with PFC enabled can process PFC pause frames. To make PFC take effect, make sure PFC is enabled on both the local end and the peer end.
The relationship between the PFC function and the generic flow control function is shown in Table 1.
Table 1 The relationship between the PFC function and the generic flow control function
|
flow-control |
priority-flow-control enable |
priority-flow-control no-drop dot1p |
Remarks |
|
Unconfigurable |
Configured |
Configured |
You cannot enable flow control by using the flow-control command on an interface where PFC is enabled and PFC is enabled for the specified 802.1p priority values. |
|
Configured |
Configurable |
Unconfigurable |
· On an interface configured with the flow-control command, you can enable PFC, but you cannot enable PFC for specific 802.1p priorities. · Enabling both generic flow control and PFC on an interface disables the interface from sending common or PFC pause frames to inform the peer of congestion conditions. However, the interface can still handle common and PFC pause frames from the peer. |
Enabling energy saving features on an Ethernet interface
Enabling auto power-down on an Ethernet interface
|
|
IMPORTANT: Fiber ports do not support this feature. |
When an Ethernet interface with auto power-down enabled has been down for a certain period of time, both of the following events occur:
· The device automatically stops supplying power to the Ethernet interface.
· The Ethernet interface enters the power save mode.
The time period depends on the chip specifications and is not configurable.
When the Ethernet interface comes up, both of the following events occur:
· The device automatically restores power supply to the Ethernet interface.
· The Ethernet interface restores to its normal state.
To enable auto power-down on an Ethernet interface:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Ethernet interface view. |
interface interface-type interface-number |
N/A |
|
3. Enable auto power-down on the Ethernet interface. |
port auto-power-down |
By default, auto power-down is disabled on an Ethernet interface. |
Enabling EEE on an Ethernet interface
|
|
IMPORTANT: · Fiber ports do not support this feature. · Ports on an LSXM1GT48FX1 card do not support this feature when they operate at 100 Mbps. |
With Energy Efficient Ethernet (EEE) enabled, a link-up interface enters low power state if it has not received any packets for a period of time. The time period depends on the chip specifications and is not configurable. When a packet arrives later, the device automatically restores power supply to the interface and the interface restores to the normal state.
To enable EEE on an Ethernet interface:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Ethernet interface view. |
interface interface-type interface-number |
N/A |
|
3. Enable EEE on the Ethernet interface. |
eee enable |
By default, EEE is disabled on an Ethernet interface. |
Configuring a Layer 2 Ethernet interface
Configuring storm suppression
You can use the storm suppression feature to limit the size of a particular type of traffic (broadcast, multicast, or unknown unicast traffic) on an interface. When the broadcast, multicast, or unknown unicast traffic on the interface exceeds this threshold, the system discards packets until the traffic drops below this threshold.
Any of the storm-constrain, broadcast-suppression, multicast-suppression, and unicast-suppression commands can suppress storm on an interface. The broadcast-suppression, multicast-suppression, and unicast-suppression commands suppress traffic in hardware, and have less impact on device performance than the storm-constrain command, which performs suppression in software.
Configuration guidelines
For the same type of traffic, do not configure the storm constrain command together with any of the broadcast-suppression, multicast-suppression, and unicast-suppression commands. Otherwise, the traffic suppression result is not determined. For more information about the storm-constrain command, see "Configuring storm control on an Ethernet interface."
Configuration procedure
To set storm suppression thresholds on one or multiple Ethernet interfaces:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Ethernet interface view. |
interface interface-type interface-number |
N/A |
|
3. Enable broadcast suppression and set the broadcast suppression threshold. |
broadcast-suppression { ratio | pps max-pps | kbps max-kbps } |
By default, broadcast traffic is allowed to pass through an interface. |
|
4. Enable multicast suppression and set the multicast suppression threshold. |
multicast-suppression { ratio | pps max-pps | kbps max-kbps } |
By default, multicast traffic is allowed to pass through an interface. |
|
5. Enable unknown unicast suppression and set the unknown unicast suppression threshold. |
unicast-suppression { ratio | pps max-pps | kbps max-kbps } |
By default, unknown unicast traffic is allowed to pass through an interface. |
Configuring storm control on an Ethernet interface
About storm control
Storm control compares broadcast, multicast, and unknown unicast traffic regularly with their respective traffic thresholds on an Ethernet interface. For each type of traffic, storm control provides a lower threshold and a higher threshold.
For management purposes, you can configure the interface to output threshold event traps and log messages when monitored traffic meets either of the following conditions:
· Exceeds the upper threshold.
· Falls below the lower threshold from the upper threshold.
Depending on your configuration, when a particular type of traffic exceeds its upper threshold, the interface performs either of the following operations:
· Blocks this type of traffic and forwards other types of traffic—Even though the interface does not forward the blocked traffic, it still counts the traffic. When the blocked traffic drops below the lower threshold, the interface begins to forward the traffic.
· Goes down automatically—The interface goes down automatically and stops forwarding traffic. When the blocked traffic is detected dropping below the lower threshold, the interface does not forward the traffic. To bring up the interface, use the undo shutdown command or disable the storm control function.
Any of the storm-constrain, broadcast-suppression, multicast-suppression, and unicast-suppression commands can suppress storm on an interface. The broadcast-suppression, multicast-suppression, and unicast-suppression commands suppress traffic in hardware, and have less impact on device performance than the storm-constrain command, which performs suppression in software.
Storm control uses a complete polling cycle to collect traffic data, and analyzes the data in the next cycle. An interface takes one to two polling intervals to take a storm control action.
Configuration guidelines
For the same type of traffic, do not configure the storm constrain command together with any of the broadcast-suppression, multicast-suppression, and unicast-suppression commands. Otherwise, the traffic suppression result is not determined. For more information about the broadcast-suppression, multicast-suppression, and unicast-suppression commands, see "Configuring storm suppression."
Configuration procedure
To configure storm control on an Ethernet interface:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. (Optional.) Set the traffic polling interval of the storm control module. |
storm-constrain interval seconds |
The default setting is 10 seconds. For network stability, use the default or set a higher traffic polling interval (10 seconds). |
|
3. Enter Ethernet interface view. |
interface interface-type interface-number |
N/A |
|
4. (Optional.) Enable storm control, and set the lower and upper thresholds for broadcast, multicast, or unknown unicast traffic. |
storm-constrain { broadcast | multicast | unicast } { pps | kbps | ratio } max-pps-values min-pps-values |
By default, storm control is disabled. |
|
5. Set the control action to take when monitored traffic exceeds the upper threshold. |
storm-constrain control { block | shutdown } |
By default, storm control is disabled. |
|
6. (Optional.) Enable the interface to log storm control threshold events. |
storm-constrain enable log |
By default, the interface outputs log messages when monitored traffic exceeds the upper threshold or falls below the lower threshold from the upper threshold. |
|
7. (Optional.) Enable the interface to send storm control threshold event traps. |
storm-constrain enable trap |
By default, the interface sends traps when monitored traffic exceeds the upper threshold or drops below the lower threshold from the upper threshold. |
Forcibly bringing up a fiber port
|
|
CAUTION: The following operations on a fiber port will cause link updown events before the port finally stays up: · Configure both the port up-mode command and the speed or duplex command. · Install or remove fiber links or transceiver modules after you forcibly bring up the fiber port. |
|
|
IMPORTANT: Copper ports do not support this feature. |
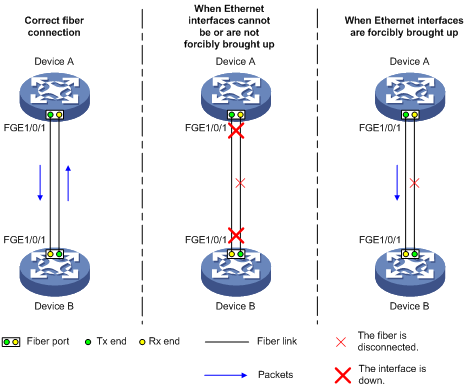
As shown in Figure 2, a fiber port uses separate fibers for transmitting and receiving packets. The physical state of the fiber port is up only when both transmit and receive fibers are physically connected. If one of the fibers is disconnected, the fiber port does not work.
To enable a fiber port to forward traffic over a single link, use the port up-mode command. This command forcibly brings up a fiber port, even when no fiber links or transceiver modules are present for the fiber port. When one fiber link is present and up, the fiber port can forward packets over the link unidirectionally.
Figure 2 Forcibly bring up a fiber port
Configuration restrictions and guidelines
When you forcibly bring up a fiber port, follow these restrictions and guidelines:
· To enable this feature on a fiber port, make sure the port is operating in bridge mode.
· The port up-mode, shutdown, and loopback commands are exclusive with each other.
· A GE fiber port forcibly brought up cannot correctly forward traffic if it is installed with a fiber-to-copper converter, 100/1000-Mbps transceiver module, or 100-Mbps transceiver module. To solve the problem, use the undo port up-mode command on the fiber port.
To forcibly bring up a fiber port:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Ethernet interface view. |
interface interface-type interface-number |
N/A |
|
3. Forcibly bring up the fiber port. |
port up-mode |
By default, a fiber port is not forcibly brought up, and the physical state of a fiber port depends on the physical state of the fibers. |
Setting the MDIX mode of an Ethernet interface
|
|
IMPORTANT: Fiber ports do not support this feature. |
A physical Ethernet interface has eight pins. Each pin plays a dedicated role by default. For example, pins 1 and 2 receive signals, and pins 3 and 6 transmit signals. You can use both crossover and straight-through Ethernet cables to connect copper Ethernet interfaces. To accommodate these types of cables, a copper Ethernet interface can operate in one of the following Medium Dependent Interface-Crossover (MDIX) modes:
· MDIX mode—Pins 1 and 2 are receive pins and pins 3 and 6 are transmit pins.
· MDI mode—Pins 1 and 2 are transmit pins and pins 3 and 6 are receive pins.
· AutoMDIX mode—The interface negotiates pin roles with its peer.
For a copper Ethernet interface to communicate with its peer, set the MDIX mode of the interface by following these guidelines:
· Typically, set the MDIX mode of the interface to AutoMDIX. Set the MDIX mode of the interface to MDI or MDIX only when the device cannot determine the cable type.
· When a straight-through cable is used, configure the interface to operate in an MDIX mode different than its peer.
· When a crossover cable is used, perform one of the following tasks:
? Configure the interface to operate in the same MDIX mode as its peer.
? Configure either end to operate in AutoMDIX mode.
To set the MDIX mode of an Ethernet interface:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Ethernet interface view. |
interface interface-type interface-number |
N/A |
|
3. Set the MDIX mode of the Ethernet interface. |
mdix-mode { automdix | mdi | mdix } |
By default, a copper Ethernet interface operates in auto mode to negotiate pin roles with its peer. |
Testing the cable connection of an Ethernet interface
|
|
IMPORTANT: · Fiber ports do not support this feature. · If the link of an Ethernet interface is up, testing its cable connection will cause the link to go down and then come up. |
This feature tests the cable connection of an Ethernet interface and displays cable test result within 5 seconds. The test result includes the cable's status and some physical parameters. If a fault is detected, the test result shows the length from the local interface to the faulty point.
To test the cable connection of an Ethernet interface:
|
Step |
Command |
|
1. Enter system view. |
system-view |
|
2. Enter Ethernet interface view. |
interface interface-type interface-number |
|
3. Perform a test for the cable connected to the Ethernet interface. |
virtual-cable-test |
Configuring a Layer 3 Ethernet interface or subinterface
Setting the MTU for an Ethernet interface or subinterface
The maximum transmission unit (MTU) of an Ethernet interface affects the fragmentation and reassembly of IP packets on the interface. Typically, you do not need to modify the MTU of an interface.
To set the MTU for an Ethernet interface or subinterface:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Ethernet interface or subinterface view. |
interface interface-type { interface-number | interface-number.subnumber } |
N/A |
|
3. Set the MTU for the Ethernet interface or subinterface. |
mtu size |
By default, the MTU of an Ethernet interface or subinterface is 1500 bytes. |
Displaying and maintaining an Ethernet interface
Execute display commands in any view and reset commands in user view.
|
Task |
Command |
|
Display interface traffic statistics. |
display counters { inbound | outbound } interface [ interface-type [ interface-number ] ] |
|
Display traffic rate statistics of interfaces in up state over the last sampling interval. |
display counters rate { inbound | outbound } interface [ interface-type [ interface-number ] ] |
|
Display the operational and status information of the specified interface or all interfaces. |
display interface [ interface-type [ interface-number | interface-number.subnumber ] ] |
|
Display summary information about the specified interface or all interfaces. |
display interface [ interface-type [ interface-number | interface-number.subnumber ] ] brief [ description ] |
|
Display information about dropped packets on the specified interface or all interfaces. |
display packet-drop { interface [ interface-type [ interface-number ] ] | summary } |
|
Display information about storm control on the specified interface or all interfaces. |
display storm-constrain [ broadcast | multicast | unicast ] [ interface interface-type interface-number ] |
|
Display the Ethernet module statistics. |
display ethernet statistics |
|
Clear the interface statistics. |
reset counters interface [ interface-type [ interface-number ] ] |
|
Clear the statistics of dropped packets on the specified interfaces. |
reset packet-drop interface [ interface-type [ interface-number ] ] |
|
Clear the Ethernet module statistics. |
reset ethernet statistics |
Configuring loopback, null, and inloopback interfaces
This chapter describes how to configure a loopback interface, a null interface, and an inloopback interface.
Configuring a loopback interface
A loopback interface is a virtual interface. The physical layer state of a loopback interface is always up unless the loopback interface is manually shut down. Because of this benefit, loopback interfaces are widely used in the following scenarios:
· Configuring a loopback interface address as the source address of the IP packets that the device generates—Because loopback interface addresses are stable unicast addresses, they are usually used as device identifications.
? When you configure a rule on an authentication or security server to permit or deny packets that a device generates, you can simplify the rule by configuring it to permit or deny packets carrying the loopback interface address that identifies the device.
? When you use a loopback interface address as the source address of IP packets, make sure the route from the loopback interface to the peer is reachable by performing routing configuration. All data packets sent to the loopback interface are considered packets sent to the device itself, so the device does not forward these packets.
· Using a loopback interface in dynamic routing protocols—With no router ID configured for a dynamic routing protocol, the system selects the highest loopback interface IP address as the router ID. In BGP, to avoid interruption of BGP sessions due to physical port failure, you can use a loopback interface as the source interface of BGP packets.
To configure a loopback interface:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Create a loopback interface and enter loopback interface view. |
interface loopback interface-number |
N/A |
|
3. Set the interface description. |
description text |
The default setting is interface name Interface (for example, LoopBack1 Interface). |
|
4. Configure the expected bandwidth of the loopback interface. |
bandwidth bandwidth-value |
By default, the expected bandwidth of a loopback interface is 0 kbps. |
|
5. Restore the default settings for the loopback interface. |
default |
N/A |
|
6. Bring up the loopback interface. |
undo shutdown |
By default, a loopback interface is up. |
Configuring a null interface
A null interface is a virtual interface and is always up, but you can neither use it to forward data packets nor can you configure it with an IP address or link layer protocol. The null interface provides a simpler way to filter packets than ACL. You can filter undesired traffic by transmitting it to a null interface instead of applying an ACL. For example, if you specify a null interface as the next hop of a static route to a specific network segment, any packets routed to the network segment are dropped.
To configure a null interface:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter null interface view. |
interface null 0 |
Interface Null 0 is the default null interface on the device and cannot be manually created or removed. Only one null interface, Null 0, is supported on the device. The null interface number is always 0. |
|
3. Set the interface description. |
description text |
The default setting is NULL0 Interface. |
|
4. Restore the default settings for the null interface. |
default |
N/A |
Configuring an inloopback interface
An inloopback interface is a virtual interface created by the system, which cannot be configured or deleted. The physical layer and link layer protocol states of an inloopback interface are always up. All IP packets sent to an inloopback interface are considered packets sent to the device itself and are not further forwarded.
Displaying and maintaining loopback, null, and inloopback interfaces
Execute display commands in any view and reset commands in user view.
|
Task |
Command |
|
Display information about the specified or all loopback interfaces. |
display interface [ loopback ] [ brief [ down ] ] display interface [ loopback [ interface-number ] ] [ brief [ description ] ] |
|
Display information about the null interface. |
display interface [ null [ 0 ] ] [ brief [ description ] ] |
|
Display information about the inloopback interface. |
display interface [ inloopback [ 0 ] ] [ brief [ description ] ] |
|
Clear the statistics on the specified or all loopback interfaces. |
reset counters interface loopback [ interface-number ] |
|
Clear the statistics on the null interface. |
reset counters interface [ null [ 0 ] ] |
|
Clear the statistics on the inloopback interface. |
reset counters interface |
Bulk configuring interfaces
Configuration restrictions and guidelines
When you bulk configure interfaces in interface range view, follow these restrictions and guidelines:
· In interface range view, only the commands supported by the first interface are available. The first interface is specified with the interface range command.
· If you cannot enter the view of an interface by using the interface interface-type interface-number command, do not configure the interface as the first interface in the interface range.
· Do not assign an aggregate interface and any of its member interfaces to an interface range at the same time. Some commands, after being executed on both an aggregate interface and its member interfaces, can break up the aggregation.
· No limit is set on the maximum number of interfaces in an interface range. The more interfaces in an interface range, the longer the command execution time.
· The maximum number of interface range names is only limited by the system resources. As a best practice to guarantee bulk interface configuration performance, configure fewer than 1000 interface range names.
· After a command is executed in interface range view, one of the following situations might occur:
? The system stays in interface range view and displays no error messages. It means that the execution succeeded on all member interfaces in the interface range.
? The system displays an error message and stays in interface range view. It means that the execution failed on member interfaces in the interface range.
- If the execution failed on the first member interface in the interface range, the command is not executed on any member interfaces.
- If the execution failed on non-first member interfaces, the command takes effect on the other member interfaces.
? The system returns to system view. It means that:
- The command is supported in both system view and interface view.
- The execution failed on a member interface in interface range view and succeeded in system view.
- The command is not executed on the subsequent member interfaces.
You can use the display this command to verify the configuration in interface view of each member interface. In addition, if the configuration in system view is not needed, use the undo form of the command to remove the configuration.
Configuration procedure
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter interface range view. |
· interface range { interface-type interface-number [ to interface-type interface-number ] } &<1-24> · interface range name name [ interface { interface-type interface-number [ to interface-type interface-number ] } &<1-24> ] |
Use either command. By using the interface range name command, you assign a name to an interface range and can specify this name rather than the interface range to enter the interface range view. |
|
3. (Optional.) Display commands available for the first interface in the interface range. |
Enter a question mark (?) at the interface range prompt. |
N/A |
|
4. Use available commands to configure the interfaces. |
Available commands vary by interface. |
N/A |
|
5. (Optional.) Verify the configuration. |
display this |
N/A |
Displaying and maintaining bulk interface configuration
Execute display commands in any view.
|
Task |
Command |
|
Display information about interface ranges configured through the interface range name command. |
display interface range [ name name ] |
Configuring the MAC address table
Overview
An Ethernet device uses a MAC address table to forward frames. A MAC address entry includes a destination MAC address, an outgoing interface, and a VLAN ID. When the device receives a frame, it uses the destination MAC address of the frame to look for a match in the MAC address table.
· The device forwards the frame out of the outgoing interface in the matching entry if a match is found.
· The device floods the frame in the VLAN of the frame if no match is found.
How a MAC address entry is created
The entries in the MAC address table include entries automatically learned by the device and entries manually added.
MAC address learning
The device can automatically populate its MAC address table by learning the source MAC addresses of incoming frames on each interface.
The device performs the following operations to learn the source MAC maddress of incoming packets:
1. Checks the source MAC address (for example, MAC-SOURCE) of the frame.
2. Looks up the source MAC address in the MAC address table.
? The device updates the entry if an entry is found.
? The device adds an entry for MAC-SOURCE and the incoming port if no entry is found.
When the device receives a frame destined for MAC-SOURCE after learning this source MAC address, the device performs the following operations:
3. Finds the MAC-SOURCE entry in the MAC address table.
4. Forwards the frame out of the port in the entry.
The device performs the learning process for each incoming frame with an unknown source MAC address until the MAC address table is fully populated.
Manually configuring MAC address entries
Dynamic MAC address learning does not distinguish between illegitimate and legitimate frames, which can invite security hazards. When Host A is connected to port A, a MAC address entry will be learned for the MAC address of Host A (for example, MAC A). When an illegal user sends frames with MAC A as the source MAC address to port B, the device performs the following tasks:
1. Learns a new MAC address entry with port B as the outgoing interface and overwrites the old entry for MAC A.
2. Forwards frames destined for MAC A out of port B to the illegal user.
As a result, the illegal user obtains the data of Host A. To improve the security for Host A, manually configure a static entry to bind Host A to port A. Then, the frames destined for Host A are always sent out of port A. Other hosts using the forged MAC address of Host A cannot obtain the frames destined for Host A.
Types of MAC address entries
A MAC address table can contain the following types of entries:
· Static entries—A static entry is manually added to forward frames with a specific destination MAC address out of the associated interface, and it never ages out. A static entry has higher priority than a dynamically learned one.
· Dynamic entries—A dynamic entry can be manually configured or dynamically learned to forward frames with a specific destination MAC address out of the associated interface. A dynamic entry might age out. A manually configured dynamic entry has the same priority as a dynamically learned one.
· Blackhole entries—A blackhole entry is manually configured and never ages out. A blackhole entry is configured for filtering out frames with a specific destination MAC address. For example, to block all frames destined for a specific user for security concerns, you can configure the MAC address of this user as a blackhole MAC address entry.
· Multiport unicast entries—A multiport unicast entry is manually added to send frames with a specific unicast destination MAC address out of multiple ports, and it never ages out. A multiport unicast entry has higher priority than a dynamically learned one.
A static, blackhole, or multiport unicast MAC address entry can overwrite a dynamic MAC address entry, but not vice versa.
MAC address table configuration task list
The configuration tasks discussed in the following sections can be performed in any order.
This document covers only the configuration of unicast MAC address entries, including static, dynamic, blackhole, and multiport unicast MAC address entries. For information about configuring static multicast MAC address entries, see IP Multicast Configuration Guide.
To configure the MAC address table, perform the following tasks:
|
Tasks at a glance |
|
(Optional.) Configuring MAC address entries: · Adding or modifying a static or dynamic MAC address entry globally · Adding or modifying a static or dynamic MAC address entry on an interface |
|
(Optional.) Disabling MAC address learning |
|
(Optional.) Configuring the aging timer for dynamic MAC address entries |
|
(Optional.) Enabling MAC address synchronization |
|
(Optional.) Enabling MAC addresses learning at ingress |
Configuring MAC address entries
Configuration guidelines
· You cannot add a dynamic MAC address entry if a learned entry already exists with a different outgoing interface for the MAC address.
· The manually configured static, blackhole, and multiport unicast MAC address entries cannot survive a reboot if you do not save the configuration. The manually configured dynamic MAC address entries, however, are lost upon reboot whether or not you save the configuration.
A frame whose source MAC address matches different types of MAC address entries is differently processed.
|
Type |
Description |
|
Static MAC address entry |
· Discards the frame received on a different interface from that in the entry. · Forwards the frame received on the same interface as that in the entry. |
|
Multiport unicast MAC address entry |
· Learns the MAC address (for example, MAC A) of the frame, adds a dynamic MAC address entry for MAC A, and forwards the frame. · Forwards the frames destined for MAC A based on the multiport unicast MAC address entry. |
|
Dynamic MAC address entry |
· Learns the MAC address of the frame received on a different interface from that in the entry and overwrites the original entry. · Forwards the frame received on the same interface as that in the entry and updates the aging timer for the entry. |
Adding or modifying a static or dynamic MAC address entry globally
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Add or modify a static or dynamic MAC address entry. |
mac-address { dynamic | static } mac-address interface interface-type interface-number vlan vlan-id |
By default, no MAC address entry is configured globally. Make sure you have created the VLAN and assigned the interface to the VLAN. |
Adding or modifying a static or dynamic MAC address entry on an interface
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter interface view. |
·
Enter Layer 2 Ethernet interface view: ·
Enter Layer 2 aggregate interface view: |
N/A |
|
3. Add or modify a static or dynamic MAC address entry. |
mac-address { dynamic | static } mac-address vlan vlan-id |
By default, no MAC address entry is configured on an interface. Make sure you have created the VLAN and assigned the interface to the VLAN. |
Adding or modifying a blackhole MAC address entry
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Add or modify a blackhole MAC address entry. |
mac-address blackhole mac-address vlan vlan-id |
By default, no blackhole MAC address entry is configured. Make sure you have created the VLAN. |
Adding or modifying a multiport unicast MAC address entry
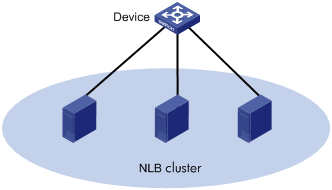
You can configure a multiport unicast MAC address entry to associate a unicast destination MAC address with multiple ports, so that the frame with a destination MAC address matching the entry is forwarded out of multiple ports.
For example, in NLB unicast mode, all servers within the cluster uses the cluster's MAC address as their own address, and frames destined for the cluster are forwarded to every server. In this case, you can configure a multiport unicast MAC address entry on the device connected to the server group. Then, the device forwards the frame destined for the server group through all ports connected to the servers within the cluster.
Figure 3 NLB cluster
You can configure a multiport unicast MAC address entry globally or on an interface.
Configuring a multiport unicast MAC address entry globally
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Add or modify a multiport unicast MAC address entry. |
mac-address multiport mac-address interface interface-list vlan vlan-id |
By default, no multiport unicast MAC address entry is configured globally. Make sure you have created the VLAN and assigned the interface to the VLAN. |
Configuring a multiport unicast MAC address entry on an interface
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter interface view. |
·
Enter Layer 2 Ethernet interface view: ·
Enter Layer 2 aggregate interface view: |
N/A |
|
3. Add the interface to a multiport unicast MAC address entry. |
mac-address multiport mac-address vlan vlan-id |
By default, no multiport unicast MAC address entry is configured on an interface. Make sure you have created the VLAN and assigned the interface to the VLAN. Do not configure an interface as the output interface of a multiport unicast MAC address entry if the interface receives frames destined for the multiport unicast MAC address. Otherwise, the frames are flooded in the VLAN to which they belong. |
Disabling MAC address learning
MAC address learning is enabled by default. To prevent the MAC address table from being saturated when the device is experiencing attacks, disable MAC address learning. For example, you can disable MAC address learning to prevent the device from being attacked by a large amount of frames with different source MAC addresses.
When MAC address learning is disabled, the learned dynamic MAC addresses remain valid until they age out.
Disabling global MAC address learning
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Disable global MAC address learning. |
undo mac-address mac-learning enable |
By default, global MAC address learning is enabled. |
Disabling global MAC address learning disables MAC address learning on all interfaces.
Disabling MAC address learning on interfaces
When global MAC address learning is enabled, you can disable MAC address learning on a single interface.
To disable MAC address learning on an interface:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter interface view. |
·
Enter Layer 2 Ethernet interface view: ·
Enter Layer 2 aggregate interface view: |
N/A |
|
3. Disable MAC address learning on the interface. |
undo mac-address mac-learning enable |
By default, MAC address learning on the interface is enabled. |
Configuring the aging timer for dynamic MAC address entries
For security and efficient use of table space, the MAC address table uses an aging timer for each dynamic MAC address entry. If a dynamic MAC address entry is not updated before the aging timer expires, the device deletes the entry. This aging mechanism ensures that the MAC address table can promptly update to accommodate latest network topology changes.
A stable network requires a longer aging interval, and an unstable network requires a shorter aging interval.
An aging interval that is too long might cause the MAC address table to retain outdated entries. As a result, the MAC address table resources might be exhausted, and the MAC address table might fail to update to accommodate the latest network changes.
An interval that is too short might result in removal of valid entries, which would cause unnecessary floods and possibly affect the device performance.
To reduce floods on a stable network, set a long aging timer or disable the timer to prevent dynamic entries from unnecessarily aging out. Reducing floods improves the network performance. Reducing flooding also improves the security because it reduces the chances for a data frame to reach unintended destinations.
To configure the aging timer for dynamic MAC address entries:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Configure the aging timer for dynamic MAC address entries. |
mac-address timer { aging seconds | no-aging } |
By default, the aging timer for dynamic MAC address entries is 300 seconds. The no-aging keyword disables the aging timer. |
Enabling MAC address synchronization
To avoid unnecessary floods and improve forwarding speed, make sure all cards have the same MAC address table. After you enable MAC address synchronization, each card advertises learned MAC address entries to other cards. (In standalone mode.)
To avoid unnecessary floods and improve forwarding speed, make sure all cards have the same MAC address table. After you enable MAC address synchronization, each card advertises learned MAC address entries to other cards of all member devices. (In IRF mode.)
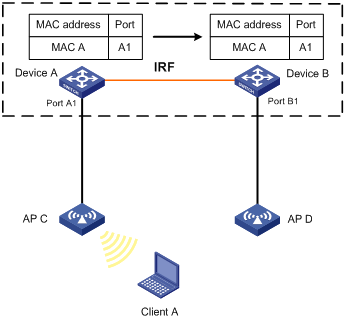
As shown in Figure 4:
· Device A and Device B form an IRF fabric enabled with MAC address synchronization.
· Device A and Device B connect to AP C and AP D, respectively.
When Client A associates with AP C, Device A learns a MAC address entry for Client A and advertises it to Device B.
Figure 4 MAC address tables of devices when Client A accesses AP C
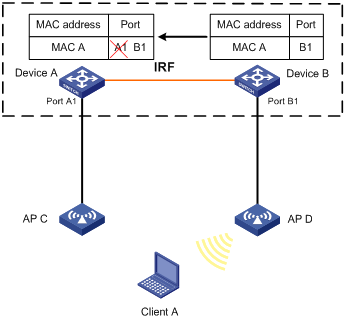
When Client A roams to AP D, Device B learns a MAC address entry for Client A. Device B advertises it to Device A to ensure service continuity for Client A, as shown in Figure 5.
Figure 5 MAC address tables of devices when Client A roams to AP D
To enable MAC address synchronization:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enable MAC address synchronization. |
mac-address mac-roaming enable |
By default, MAC address synchronization is disabled. |
Enabling MAC addresses learning at ingress
|
|
IMPORTANT: This feature is available in Release 11xx. |
The device can learn the source MAC address of a packet when it receives the packet or when it sends out the packet.
For the device to correctly learn the source MAC address of Layer 3 forwarded packets, you must enable MAC address learning at ingress.
At egress, the source MAC address of Layer 3 forwarded packets is replaced by the outgoing interface's MAC address. The device cannot learn the original source MAC address.
To enable MAC address learning at ingress:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enable MAC address learning at ingress. |
mac-address mac-learning ingress |
By default, the device learns MAC addresses at egress. |
Displaying and maintaining the MAC address table
Execute display commands in any view.
|
Task |
Command |
|
Display MAC address table information. |
display mac-address [ mac-address [ vlan vlan-id ] | [ [ dynamic | static ] [ interface interface-type interface-number ] | blackhole | multiport ] [ vlan vlan-id ] [ count ] ] |
|
Display the aging timer for dynamic MAC address entries. |
display mac-address aging-time |
|
Display the system or interface MAC address learning state. |
display mac-address mac-learning [ interface interface-type interface-number ] |
|
Display MAC address statistics. |
display mac-address statistics |
MAC address table configuration example
Network requirements
On a network:
· Host A at 000f-e235-dc71 is connected to interface FortyGigE 1/0/1 of Device and belongs to VLAN 1.
· Host B at 000f-e235-abcd, which behaved suspiciously on the network, also belongs to VLAN 1.
Configure the MAC address table as follows:
· To prevent MAC address spoofing, add a static entry for Host A in the MAC address table of Device.
· To drop all frames destined for Host B, add a blackhole MAC address entry for the host.
· Set the aging timer to 500 seconds for dynamic MAC address entries.
Configuration procedure
# Add a static MAC address entry for MAC address 000f-e235-dc71 on FortyGigE 1/0/1 that belongs to VLAN 1.
<Device> system-view
[Device] mac-address static 000f-e235-dc71 interface fortygige 1/0/1 vlan 1
# Add a blackhole MAC address entry for MAC address 000f-e235-abcd that belongs to VLAN 1.
[Device] mac-address blackhole 000f-e235-abcd vlan 1
# Set the aging timer to 500 seconds for dynamic MAC address entries.
[Device] mac-address timer aging 500
Verifying the configuration
# Display the static MAC address entries for interface FortyGigE 1/0/1.
[Device] display mac-address static interface fortygige 1/0/1
MAC Address VLAN ID State Port/NickName Aging
000f-e235-dc71 1 Static FGE1/0/1 N
# Display the blackhole MAC address entries.
[Device] display mac-address blackhole
MAC Address VLAN ID State Port/NickName Aging
000f-e235-abcd 1 Blackhole N/A N
# Display the aging time of dynamic MAC address entries.
[Device] display mac-address aging-time
MAC address aging time: 500s.
Configuring MAC Information
The MAC Information feature can generate syslog messages or SNMP notifications when MAC address entries are learned or deleted. You can use these messages to monitor users leaving or joining the network and analyze network traffic.
The MAC Information feature buffers the MAC change syslog messages or SNMP notifications in a queue. The device overwrites the oldest MAC address change written into the queue with the most recent MAC address change when the following conditions exist:
· The MAC change notification interval does not expire.
· The queue has been exhausted.
To send a syslog message or SNMP notification immediately after it is created, set the queue length to zero.
The device does not write MAC address change information or send MAC address change messages for blackhole MAC addresses, static MAC addresses, multiport unicast MAC addresses, multicast MAC addresses, and local MAC addresses except for dynamic MAC addresses.
Enabling MAC Information
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enable MAC Information globally. |
mac-address information enable |
By default, MAC Information is globally disabled. |
|
3. Enter Layer 2 Ethernet interface view. |
interface interface-type interface-number |
N/A |
|
4. Enable MAC Information on the interface. |
mac-address information enable { added | deleted } |
By default, MAC Information is disabled on an interface. Make sure you have enabled MAC Information globally before you enable it on the interface. |
Configuring the MAC Information mode
The following MAC Information modes are available for sending MAC address changes:
· Syslog—The device sends syslog messages to notify MAC address changes. In this mode, the device sends syslog messages to the information center, which then outputs them to the monitoring terminal. For more information about information center, see Network Management and Monitoring Configuration Guide.
· Trap—The device sends SNMP notifications to notify MAC address changes. In this mode, the device sends SNMP notifications to the NMS. For more information about SNMP, see Network Management and Monitoring Configuration Guide.
To configure the MAC Information mode:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Configure the MAC Information mode. |
mac-address information mode { syslog | trap } |
The default setting is trap. |
Configuring the MAC change notification interval
To prevent syslog messages or SNMP notifications from being sent too frequently, you can set the MAC change notification interval to a larger value.
To set the MAC change notification interval:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Set the MAC change notification interval. |
mac-address information interval interval-time |
The default setting is 1 second. |
Configuring the MAC Information queue length
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Configure the MAC Information queue length. |
mac-address information queue-length value |
The default setting is 50. |
MAC Information configuration example
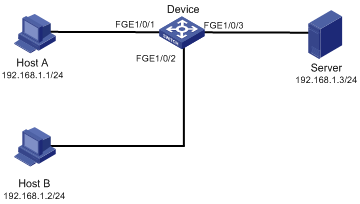
Network requirements
Enable MAC Information on interface FortyGigE 1/0/1 on Device in Figure 6 to send MAC address changes in syslog messages to the log host, Host B, through interface FortyGigE 1/0/2.
Configuration restrictions and guidelines
When you edit the file /etc/syslog.conf, follow these restrictions and guidelines:
· Comments must be on a separate line and must begin with a pound sign (#).
· No redundant spaces are allowed after the file name.
· The logging facility name and the severity level specified in the /etc/syslog.conf file must be the same as those configured on the device. Otherwise, the log information might not be output correctly to the log host. The logging facility name and the severity level are configured by using the info-center loghost and info-center source commands.
Configuration procedure
1. Configure Device to send syslog messages to Host B:
# Enable the information center.
<Device> system-view
[Device] info-center enable
# Specify the log host 192.168.1.2/24 and specify local4 as the logging facility.
[Device] info-center loghost 192.168.1.2 facility local4
# Disable log output to the log host.
[Device] info-center source default loghost deny
To avoid output of unnecessary information, disable all modules from outputting logs to the specified destination (loghost, in this example) before you configure an output rule.
# Configure an output rule to output to the log host MAC address logs that have a severity level of at least informational.
[Device] info-center source mac loghost level informational
2. Configure the log host, Host B:
Configure Solaris as follows. Configure other UNIX operating systems in the same way Solaris is configured.
a. Log in to the log host as a root user.
b. Create a subdirectory named Device in directory /var/log/, and then create file info.log in the Device directory to save logs from Device.
# mkdir /var/log/Device
# touch /var/log/Device/info.log
c. Edit the file syslog.conf in directory /etc/ and add the following contents:
# Device configuration messages
local4.info /var/log/Device/info.log
In this configuration, local4 is the name of the logging facility that the log host uses to receive logs, and info is the informational level. The UNIX system records the log information that has a severity level of at least informational to the file /var/log/Device/info.log.
d. Display the process ID of syslogd, kill the syslogd process, and then restart syslogd using the –r option to make the new configuration take effect.
# ps -ae | grep syslogd
147
# kill -HUP 147
# syslogd -r &
Now, the device can output MAC address logs to the log host, which stores the logs to the specified file.
3. Enable MAC Information on Device:
# Enable MAC Information globally.
[Device] mac-address information enable
# Configure the MAC Information mode as syslog.
[Device] mac-address information mode syslog
# Enable MAC Information on interface FortyGigE 1/0/1 to enable the interface to record MAC address change information when the interface performs either of the following tasks:
? Learns a new MAC address.
? Deletes an existing MAC address.
[Device] interface fortygige 1/0/1
[Device-FortyGigE1/0/1] mac-address information enable added
[Device-FortyGigE1/0/1] mac-address information enable deleted
[Device-FortyGigE1/0/1] quit
# Set the MAC Information queue length to 100.
[Device] mac-address information queue-length 100
# Set the MAC change notification interval to 20 seconds.
[Device] mac-address information interval 20
Configuring Ethernet link aggregation
Ethernet link aggregation bundles multiple physical Ethernet links into one logical link, called an aggregate link. Link aggregation has the following benefits:
· Increased bandwidth beyond the limits of any single link. In an aggregate link, traffic is distributed across the member ports.
· Improved link reliability. The member ports dynamically back up one another. When a member port fails, its traffic is automatically switched to other member ports.
As shown in Figure 7, Device A and Device B are connected by three physical Ethernet links. These physical Ethernet links are combined into an aggregate link called link aggregation 1. The bandwidth of this aggregate link can reach up to the total bandwidth of the three physical Ethernet links. At the same time, the three Ethernet links back up one another. When a physical Ethernet link fails, the traffic previously carried on the failed link is switched to the other two links.
Figure 7 Ethernet link aggregation diagram

Basic concepts
Aggregation group, member port, and aggregate interface
Link bundling is implemented through interface bundling. An aggregation group is a group of Ethernet interfaces bundled together, which are called member ports of the aggregation group. For each aggregation group, a logical interface (called an aggregate interface), is created.
Aggregate interfaces include Layer 2 aggregate interfaces and Layer 3 aggregate interfaces. On a Layer 3 aggregate interface, you can create subinterfaces.
When you create an aggregate interface, the device automatically creates an aggregation group of the same type and number as the aggregate interface. For example, when you create aggregate interface 1, aggregation group 1 is created.
You can assign Layer 2 Ethernet interfaces only to a Layer 2 aggregation group, and Layer 3 Ethernet interfaces only to a Layer 3 aggregation group.
The port rate of an aggregate interface equals the total rate of its Selected member ports. Its duplex mode is the same as that of the selected member ports. For more information about the states of member ports in an aggregation group, see "Aggregation states of member ports in an aggregation group."
Aggregation states of member ports in an aggregation group
A member port in an aggregation group can be in any of the following aggregation states:
· Selected—A Selected port can forward traffic.
· Unselected—An Unselected port cannot forward traffic.
· Individual—An Individual port can forward traffic as a normal physical port. A port is placed in the Individual state when the following conditions exist:
? The corresponding aggregate interface is configured as an edge aggregate interface.
? The port has not received LACPDUs from its peer port.
Operational key
When aggregating ports, the system automatically assigns each port an operational key based on port information, such as port rate and duplex mode. Any change to this information triggers a recalculation of the operational key.
In an aggregation group, all Selected ports are assigned the same operational key.
Configuration types
Every configuration setting on a port might affect its aggregation state. Port configurations include the following types:
· Attribute configurations—To become a Selected port, a member port must have the same attribute configurations as the aggregate interface. Table 2 describes the attribute configurations.
Attribute configurations made on an aggregate interface are automatically synchronized to all member ports. These configurations are retained on the member ports even after the aggregate interface is removed.
Any attribute configuration change might affect the aggregation state of link aggregation member ports and running services. To make sure that you are aware of the risk, the system displays a warning message every time you attempt to change an attribute configuration setting on a member port.
Table 2 Attribute configurations
|
Feature |
Considerations |
|
Port isolation |
Indicates whether the port has joined an isolation group and which isolation group the port belongs to. |
|
VLAN |
VLAN attribute configurations include: · Permitted VLAN IDs. · PVID. · Link type (trunk, hybrid, or access). · Operating mode (promiscuous, trunk promiscuous, or host). · VLAN tagging mode. For information about VLAN, see "Configuring VLANs." |
· Protocol configurations—Protocol configurations of a member port do not affect the aggregation state of the member port. MAC address learning and spanning tree settings are examples of protocol configurations.
|
|
NOTE: The protocol configurations for a member port take effect only when the member port leaves the aggregation group. |
Link aggregation modes
An aggregation group operates in one of the following modes:
· Static—Static aggregation is stable. An aggregation group in static mode is called a static aggregation group. The aggregation states of the member ports in a static aggregation group are not affected by the peer ports.
· Dynamic—An aggregation group in dynamic mode is called a dynamic aggregation group. The local system and the peer system automatically maintain the aggregation states of the member ports, which reduces the administrators' workload.
Aggregating links in static mode
Choosing a reference port
When setting the aggregation state of the ports in an aggregation group, the system automatically picks a member port as the reference port. A Selected port must have the same operational key and attribute configurations as the reference port.
The system chooses a reference port from the member ports that are in up state.
The candidate reference ports are organized into different priority levels following these rules:
1. In descending order of port priority.
2. Full duplex.
3. In descending order of speed.
4. Half duplex.
5. In descending order of speed.
From the candidate ports with the same attribute configurations as the aggregate interface, the one with the highest priority level is chosen as the reference port.
· If multiple ports have the same priority level, the port that has been Selected (if any) is chosen. If multiple ports with the same priority level have been Selected, the one with the smallest port number is chosen.
· If multiple ports have the same priority level and none of them has been Selected, the port with the smallest port number is chosen.
Setting the aggregation state of each member port
After a static aggregation group has reached the limit on Selected ports, any port that joins the group is placed in Unselected state to avoid traffic interruption on the existing Selected ports.
Figure 8 Setting the aggregation state of a member port in a static aggregation group
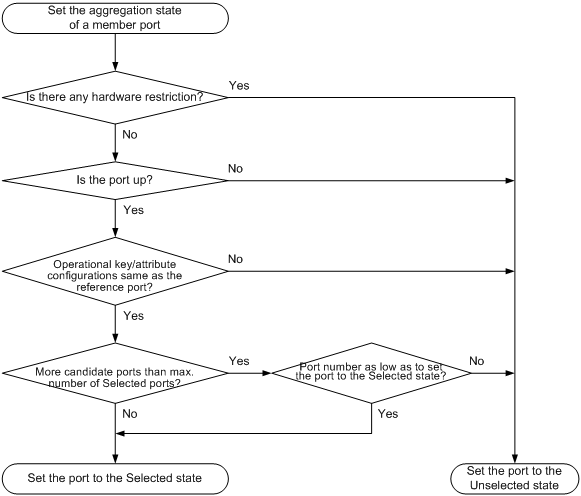
To configure the maximum number of Selected ports in a static aggregation group, see "Setting the minimum and maximum numbers of Selected ports for an aggregation group."
Any operational key or attribute configuration change might affect the aggregation states of link aggregation member ports.
Aggregating links in dynamic mode
Dynamic aggregation mode is implemented through IEEE 802.3ad Link Aggregation Control Protocol (LACP).
LACP
LACP uses LACPDUs to exchange aggregation information between LACP-enabled devices.
Each member port in an LACP-enabled aggregation group exchanges information with its peer. When a member port receives an LACPDU, it compares the received information with information received on the other member ports. In this way, the two systems reach an agreement on which ports are placed in Selected state.
LACP functions
LACP offers basic LACP functions and extended LACP functions, as described in Table 3.
Table 3 Basic and extended LACP functions
|
Category |
Description |
|
Basic LACP functions |
Implemented through the basic LACPDU fields, including the system LACP priority, system MAC address, port priority, port number, and operational key. |
|
Extended LACP functions |
Implemented by extending the LACPDU with new TLV fields. This is how the LACP MAD mechanism of the IRF feature is implemented. it can participate in LACP MAD as either an IRF member device or an intermediate device. For more information about IRF and the LACP MAD mechanism, see IRF Configuration Guide. |
LACP priorities
LACP priorities include system LACP priority and port priority, as described in Table 4. The smaller the priority value, the higher the priority.
|
Type |
Description |
|
System LACP priority |
Used by two peer devices (or systems) to determine which one is superior in link aggregation. In dynamic link aggregation, the system that has higher system LACP priority sets the Selected state of member ports on its side, after which the system that has lower priority sets port state accordingly. |
|
Port priority |
Determines the likelihood of a member port to be selected on a system. The higher port priority, the higher the likelihood of selection. |
LACP timeout interval
The LACP timeout interval specifies how long a member port waits to receive LACPDUs from the peer port. If a local member port fails to receive LACPDUs from the peer within the LACP timeout interval, the member port considers the peer as failed.
The LACP timeout interval also determines the LACPDU sending rate of the peer. LACP timeout intervals include the following types:
· Short timeout interval—3 seconds. If you configure the short timeout interval, the peer sends one LACPDU per second.
· Long timeout interval—90 seconds. If you configure the long timeout interval, the peer sends one LACPDU every 30 seconds.
How dynamic link aggregation works
Choosing a reference port
The system chooses a reference port from the member ports that are in up state and have the same attribute configurations as the aggregate interface. A Selected port must have the same operational key and attribute configurations as the reference port.
The local system (the actor) and the remote system (the partner) negotiate a reference port by using the following workflow:
1. The systems compare their system IDs. (A system ID contains the system LACP priority and the system MAC address.) The lower the LACP priority, the smaller the system ID. If LACP priority values are the same, the two systems compare their MAC addresses. The lower the MAC address, the smaller the system ID.
2. The system with the smaller system ID chooses the port with the smallest port ID as the reference port. (A port ID contains a port priority and a port number.) The port with the lower priority value is chosen. If two ports have the same aggregation priority, the system compares their port numbers. The port with the smaller port number and the same attribute configurations as the aggregate interface becomes the reference port.
Setting the aggregation state of each member port
After the reference port is chosen, the system with the lower system ID sets the state of each member port in the dynamic aggregation group on its side as shown in Figure 9.
Figure 9 Setting the state of a member port in a dynamic aggregation group
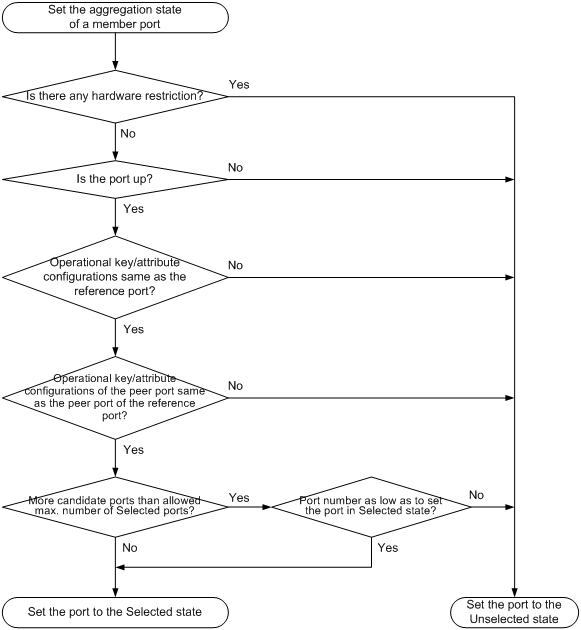
Meanwhile, the system with the higher system ID, being aware of the aggregation state changes on the remote system, sets the aggregation state of local member ports the same as their peer ports.
When you aggregate interfaces in dynamic mode, follow these guidelines:
· To configure the maximum number of Selected ports in a dynamic aggregation group, see "Setting the minimum and maximum numbers of Selected ports for an aggregation group."
· A dynamic link aggregation group preferably chooses full-duplex ports as the Selected ports. The group will choose only one half-duplex port as a Selected port when either of the following conditions exist:
? None of the full-duplex ports can be chosen as Selected ports.
? Only half-duplex ports exist in the group.
· To ensure stable aggregation and service continuity, do not change the operational key or attribute configurations on any member port.
· In a dynamic aggregation group, when the aggregation state of a local port changes, the aggregation state of the peer port also changes.
· After the Selected port limit has been reached, a port joining the aggregation group is placed in the Selected state if it is more eligible than a current Selected port.
Edge aggregate interface
Dynamic link aggregation fails on a server-facing aggregate interface if dynamic link aggregation is configured only on the device. The device forwards traffic by using only one of the physical ports that are connected to the server.
To improve link reliability, configure the aggregate interface as an edge aggregate interface. This feature enables all member ports of the aggregation group to forward traffic. When a member port fails, its traffic is automatically switched to other member ports.
After dynamic link aggregation is configured on the server, the device can receive LACPDUs from the server. Then, link aggregation between the device and the server operates correctly.
An edge aggregate interface takes effect only when it is configured on an aggregate interface corresponding to a dynamic aggregation group.
Load sharing modes for link aggregation groups
In a link aggregation group, traffic can be load shared across the Selected ports based on any of the following modes:
· Per-flow load sharing—Load shares traffic on a per-flow basis. The load sharing mode classifies packets into flows and forwards packets of the same flow on the same link. This mode can be one or any combination of the following criteria that classify traffic:
? Source or destination MAC address.
? Source or destination port number.
? Ingress port.
? Source or destination IP address.
? Protocol number.
· Per-packet load sharing—Load shares traffic on a per-packet basis.
Ethernet link aggregation configuration task list
|
Tasks at a glance |
|
(Required.) Configuring an aggregation group: |
|
(Optional.) Configuring an aggregate interface: · Setting the description for an aggregate interface · Specifying ignored VLANs for a Layer 2 aggregate interface · Setting the MTU for a Layer 3 aggregate interface or subinterface · Setting the minimum and maximum numbers of Selected ports for an aggregation group · Setting the expected bandwidth for an aggregate interface · Configuring an edge aggregate interface · Enabling BFD for an aggregation group |
|
(Optional.) Configuring load sharing for link aggregation group: |
|
(Optional.) Enabling link-aggregation traffic redirection |
|
(Optional.) Configuring the link aggregation capability for the device |
Configuring an aggregation group
This section explains how to configure an aggregation group.
Configuration restrictions and guidelines
When you configure an aggregation group, follow these restrictions and guidelines:
· Deleting an aggregate interface also deletes its aggregation group and causes all member ports to leave the aggregation group.
· You must configure the same aggregation mode on the two ends of an aggregate link.
· Before creating a Layer 3 aggregate interface or subinterface, use the reserve-vlan-interface command to reserve enough VLAN interface resources. If not enough VLAN interface resources are reserved, the system fails to create the Layer 3 aggregate interface or subinterface.
Before creating a Layer 3 aggregate interface, reserve a VLAN interface resource for each of the following interfaces:
? Layer 3 aggregate interface.
? Member ports in the corresponding Layer 3 aggregation group.
For example, before creating a Layer 3 aggregation group containing three member ports, reserve four VLAN interface resources. The Layer 3 aggregate interface uses one VLAN interface resource and each of the member ports uses one VLAN interface resource.
Before creating Layer 3 aggregate subinterfaces on a Layer 3 aggregate interface, reserve a VLAN interface resource for each of the following interface:
? Layer 3 aggregate interface.
? Member ports in the corresponding Layer 3 aggregation group.
? Layer 3 aggregate subinterfaces.
For example, before creating four Layer 3 aggregate subinterfaces on a Layer 3 aggregate interface whose corresponding aggregation group has two member ports, reserve seven VLAN interface resources. The aggregate interface uses one VLAN interface resource. Each of the member ports and aggregate subinterfaces uses one VLAN interface resource.
Before creating a Layer 3 aggregate subinterface, do not reserve a resource for the VLAN interface whose interface number matches the subinterface number. After you reserve a VLAN interface resource, do not create a Layer 3 aggregate subinterface whose subinterface number is the VLAN interface number. A Layer 3 aggregate subinterface uses the VLAN interface resource to process tagged packets whose VLAN ID matches the subinterface number.
To reserve global-type VLAN interface resources, specify the global keyword in the reserve-vlan-interface command. To reserve local-type VLAN interface resources, do not specify the global keyword. Reserved VLAN interface resources are of the local type in this chapter.
For more information about reserving VLAN interface resources, see "Configuring VLANs."
Configuring a static aggregation group
For a successful static aggregation, make sure the ports at both ends of each link are in the same aggregation state.
Avoid assigning ports to a static aggregation group where the limit on Selected ports has been reached. New member ports in the static aggregation group will be placed in the Unselected state to avoid traffic interruption on the current Selected ports. However, a device reboot can cause the aggregation state of member ports to change.
Configuring a Layer 2 static aggregation group
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Create a Layer 2 aggregate interface and enter Layer 2 aggregate interface view. |
interface bridge-aggregation interface-number |
When you create a Layer 2 aggregate interface, the system automatically creates a Layer 2 static aggregation group numbered the same. |
|
3. Exit to system view. |
quit |
N/A |
|
4. Assign an interface to the specified Layer 2 aggregation group. |
a
Enter Layer 2 Ethernet interface view: b
Assign the interface to the specified
Layer 2 aggregation group: |
Repeat these two sub-steps to assign more Layer 2 Ethernet interfaces to the aggregation group. |
Configuring a Layer 3 static aggregation group
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Create a Layer 3 aggregate interface and enter Layer 3 aggregate interface view. |
interface route-aggregation interface-number |
When you create a Layer 3 aggregate interface, the system automatically creates a Layer 3 static aggregation group numbered the same. |
|
3. Exit to system view. |
quit |
N/A |
|
4. Assign an interface to the specified Layer 3 aggregation group. |
a
Enter Layer 3 Ethernet interface view: b
Assign the interface to the specified
Layer 3 aggregation group: |
Repeat these two substeps to assign more Layer 3 Ethernet interfaces to the aggregation group. |
Configuring a dynamic aggregation group
For a successful dynamic aggregation, make sure the peer ports of the ports aggregated at one end are also aggregated. The two ends can automatically negotiate the aggregation state of each member port.
Configuring a Layer 2 dynamic aggregation group
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Set the system LACP priority. |
lacp system-priority system-priority |
By default, the system LACP priority is 32768. Changing the system LACP priority might affect the aggregation state of the ports in a dynamic aggregation group. |
|
3. Create a Layer 2 aggregate interface and enter Layer 2 aggregate interface view. |
interface bridge-aggregation interface-number |
When you create a Layer 2 aggregate interface, the system automatically creates a Layer 2 static aggregation group numbered the same. |
|
4. Configure the aggregation group to operate in dynamic aggregation mode. |
link-aggregation mode dynamic |
By default, an aggregation group operates in static aggregation mode. |
|
5. Exit to system view. |
quit |
N/A |
|
6. Assign an interface to the specified Layer 2 aggregation group. |
a
Enter Layer 2 Ethernet interface view: b
Assign the interface to the specified
Layer 2 aggregation group: |
Repeat these two sub-steps to assign more Layer 2 Ethernet interfaces to the aggregation group. |
|
7. Set the port priority for the interface. |
link-aggregation port-priority port-priority |
The default setting is 32768. |
|
8. Set the short LACP timeout interval (3 seconds) on the interface. |
lacp period short |
By default, the long LACP timeout interval (90 seconds) is adopted by the interface. The peer sends LACPDUs slowly. |
Configuring a Layer 3 dynamic aggregation group
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Set the system LACP priority. |
lacp system-priority system-priority |
By default, the system LACP priority is 32768. Changing the system LACP priority might affect the aggregation states of the ports in the dynamic aggregation group. |
|
3. Create a Layer 3 aggregate interface and enter Layer 3 aggregate interface view. |
interface route-aggregation interface-number |
When you create a Layer 3 aggregate interface, the system automatically creates a Layer 3 static aggregation group numbered the same. |
|
4. Configure the aggregation group to operate in dynamic mode. |
link-aggregation mode dynamic |
By default, an aggregation group operates in static mode. |
|
5. Exit to system view. |
quit |
N/A |
|
6. Assign an interface to the specified Layer 3 aggregation group. |
a
Enter Layer 3 Ethernet interface view: b
Assign the interface to the specified
Layer 3 aggregation group: |
Repeat these two substeps to assign more Layer 3 Ethernet interfaces to the aggregation group. |
|
7. Set the port priority for the interface. |
link-aggregation port-priority port-priority |
The default setting is 32768. |
|
8. Set the short LACP timeout interval (3 seconds) on the interface. |
lacp period short |
By default, the long LACP timeout interval (90 seconds) is adopted by the interface. |
Configuring an aggregate interface
In addition to the configurations in this section, most of the configurations that can be performed on Layer 2 or Layer 3 Ethernet interfaces can also be performed on Layer 2 or Layer 3 aggregate interfaces.
Setting the description for an aggregate interface
You can set the description for an aggregate interface for administration purposes such as describing the purpose of the interface.
To set the description for an aggregate interface:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter aggregate interface or subinterface view. |
·
Enter Layer 2
aggregate interface view: ·
Enter Layer 3 aggregate interface or subinterface view: |
N/A |
|
3. Set the description for the aggregate interface or subinterface. |
description text |
By default, the description of an interface is in the format of interface-name Interface. |
Specifying ignored VLANs for a Layer 2 aggregate interface
By default, the member ports cannot become Selected ports when the permit state and tagging mode of each VLAN are not same for the member ports and the Layer 2 aggregate interface.
You can set a VLAN as an ignored VLAN if you want to allow member ports to be set in Selected state even if the permit state and tagging mode of the VLAN are different between the member ports and the Layer 2 aggregate interface.
To specify ignored VLANs for a Layer 2 aggregate interface:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Layer 2 aggregate interface view. |
interface bridge-aggregation interface-number |
N/A |
|
3. Specify ignored VLANs. |
link-aggregation ignore vlan vlan-id-list |
By default, a Layer 2 aggregate interface does not ignore any VLANs. |
Setting the MTU for a Layer 3 aggregate interface or subinterface
The MTU of an interface affects IP packet fragmentation and reassembly on the interface.
To set the MTU for a Layer 3 aggregate interface or subinterface:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Layer 3 aggregate interface or subinterface view. |
interface route-aggregation { interface-number | interface-number.subnumber } |
N/A |
|
3. Set the MTU for the Layer 3 aggregate interface or subinterface. |
mtu size |
The default setting is 1500 bytes. |
Setting the minimum and maximum numbers of Selected ports for an aggregation group
|
IMPORTANT: The minimum and maximum number of Selected ports must be the same for the local and peer aggregation groups. |
The bandwidth of an aggregate link increases as the number of selected member ports increases. To avoid congestion caused by insufficient Selected ports on an aggregate link, you can set the minimum number of Selected ports required for bringing up the specific aggregate interface.
This minimum threshold setting affects the aggregation state of both aggregation member ports and the aggregate interface:
· When the number of member ports eligible to be selected is smaller than the minimum threshold, all member ports change to the Unselected state and the link of the aggregate interface goes down.
· When the minimum threshold is reached, the eligible member ports change to the Selected state, and the link of the aggregate interface goes up.
The maximum number of Selected ports allowed in an aggregation group is limited by either the configured maximum number or hardware capability, whichever value is smaller.
You can configure backup between two ports by assigning two ports to an aggregation group and configuring the maximum number of Selected ports allowed in the aggregation group as 1. In this way, only one Selected port is allowed in the aggregation group at any point in time, while the Unselected port serves as a backup port.
To set the minimum and maximum numbers of Selected ports for an aggregation group:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter aggregate interface view. |
·
Enter Layer 2
aggregate interface view: ·
Enter Layer 3 aggregate interface view: |
N/A |
|
3. Set the minimum number of Selected ports for the aggregation group. |
link-aggregation selected-port minimum number |
By default, the minimum number of Selected ports for the aggregation group is not specified. |
|
4. Set the maximum number of Selected ports for the aggregation group. |
link-aggregation selected-port maximum number |
By default, the maximum number of Selected ports for an aggregation group is 16. |
Setting the expected bandwidth for an aggregate interface
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter aggregate interface or subinterface view. |
·
Enter Layer 2
aggregate interface view: ·
Enter Layer 3 aggregate interface /subinterface view: |
N/A |
|
3. Set the expected bandwidth for the interface. |
bandwidth bandwidth-value |
By default, the expected bandwidth (in kbps) is the interface baud rate divided by 1000. |
Configuring an edge aggregate interface
This configuration takes effect on only the aggregate interface corresponding to a dynamic aggregation group.
To configure an edge aggregate interface:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter aggregate interface view. |
·
Enter Layer 2
aggregate interface view: ·
Enter Layer 3 aggregate interface view: |
N/A |
|
3. Configure the aggregate interface as an edge aggregate interface. |
lacp edge-port |
By default, an aggregate interface does not operate as an edge aggregate interface. |
Enabling BFD for an aggregation group
BFD for Ethernet link aggregation can monitor member link status in an aggregation group. After you enable BFD on an aggregate interface, each Selected port in the aggregation group establishes a BFD session with its peer port. All the BFD sessions use UDP port 6784 and destination MAC address 01-00-5E-90-00-01. BFD operates differently depending on the aggregation mode.
· BFD for static aggregation—When BFD detects a link failure, BFD notifies the Ethernet link aggregation module that the peer port is unreachable. The local port is placed in the Unselected state. The BFD session between the local and peer ports remains, and the local port keeps sending BFD packets. When the link is recovered, the local port receives BFD packets from the peer port, and BFD notifies the Ethernet link aggregation module that the peer port is reachable. The local port is placed in the Selected state again. This mechanism ensures that the local and peer ports of a static aggregate link have the same aggregation state.
· BFD for dynamic aggregation—When BFD detects a link failure, BFD notifies the Ethernet link aggregation module that the peer port is unreachable. BFD clears the session and stops sending BFD packets. When the link is recovered and the local port is placed in the Selected state again, the local port establishes a new session with the peer port. BFD notifies the Ethernet link aggregation module that the peer port is reachable. Because BFD provides fast failure detection, the local and peer systems of a dynamic aggregate link can negotiate the aggregation state of their member ports faster.
To enable BFD for an aggregation group:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter aggregate interface view. |
·
Enter Layer 2
aggregate interface view: ·
Enter Layer 3 aggregate interface view: |
N/A |
|
3. Enable BFD for the aggregation group. |
link-aggregation bfd ipv4 source ip-address destination ip-address |
By default, BFD is disabled for an aggregation group. |
Shutting down an aggregate interface
Make sure no member port in an aggregation group is configured with the loopback command when you shut down the aggregate interface. Similarly, a port configured with the loopback command cannot be assigned to an aggregate interface already shut down. For more information about the loopback command, see Layer 2—LAN Switching Command Reference.
Shutting down or bringing up an aggregate interface affects the aggregation state and link state of ports in the corresponding aggregation group in the following ways:
· When an aggregate interface is shut down, all Selected ports in the corresponding aggregation group become unselected and their link state becomes down.
· When an aggregate interface is brought up, the aggregation state of ports in the corresponding aggregation group is recalculated.
To shut down an aggregate interface:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter aggregate interface or subinterface view. |
·
Enter Layer 2
aggregate interface view: ·
Enter Layer 3 aggregate interface or subinterface view: |
N/A |
|
3. Shut down the aggregate interface. |
shutdown |
By default, aggregate interfaces are up. |
Restoring the default settings for an aggregate interface
You can return all configurations on an aggregate interface to default settings.
To restore the default settings for an aggregate interface:
|
Step |
Command |
|
1. Enter system view. |
system-view |
|
2. Enter aggregate interface or subinterface view. |
·
Enter Layer 2
aggregate interface view: ·
Enter Layer 3 aggregate interface or subinterface view: |
|
3. Restore the default settings for the aggregate interface. |
default |
Configuring load sharing for link aggregation groups
This section explains how to set load sharing modes for link aggregation groups and how to enable local-first load sharing for link aggregation.
Setting load sharing modes for link aggregation groups
You can set the global or group-specific load sharing mode. The global load sharing mode takes effect on all link aggregation groups. A link aggregation group preferentially uses the group-specific load sharing mode. If the group-specific load sharing mode is not available, the group uses the global load sharing mode.
If you configure both link aggregation load sharing and per-flow load sharing over equal-cost routes, the latest configuration takes effect. Per-flow load sharing over equal-cost routes identifies a flow based on five tuples (source IP address, destination IP address, source port number, destination port number, and IP protocol number). For information about configuring per-flow load sharing over equal-cost routes, see Layer 3—IP Services Configuration Guide.
Setting the global link-aggregation load sharing mode
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Set the global link-aggregation load sharing mode. |
link-aggregation global load-sharing mode { destination-ip | destination-mac | destination-port | ingress-port | ip-protocol | source-ip | source-mac | source-port } * |
The default settings are as follows: · Layer 2 traffic is distributed based on the Ethernet type, source and destination MAC address, and source port. · IPv4 or IPv6 traffic is distributed based on the source and destination IP addresses, source and destination ports, and protocol number. · MPLS traffic with three or fewer layers of labels is distributed based on the source and destination IP addresses, source and destination ports, and protocol number. MPLS traffic with more than three layers of labels is distributed based on the source and destination IP addresses. |
|
|
NOTE: · If you set the global load-sharing mode to source MAC address, the setting takes effect only on Layer 2 aggregation groups. A Layer 3 aggregation group forwards traffic by using one of its Selected ports rather than load shares traffic. When the Selected port fails, traffic is switched to another Selected port in the aggregation group. · If an unsupported load sharing mode is set, an error prompt appears. |
Setting the group-specific load sharing mode
The switch can perform link-aggregation load sharing on a per-packet basis.
To set the group-specific load sharing mode:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Layer 2 aggregate interface view. |
interface bridge-aggregation interface-number |
N/A |
|
3. Configure the aggregation group to load share traffic on a per-packet basis. |
link-aggregation load-sharing mode flexible |
By default, the load sharing mode of a group is the same as the global load sharing mode. |
Enabling local-first load sharing for link aggregation
Use the local-first load sharing mechanism in a multi-device link aggregation scenario to distribute traffic preferentially across member ports on the ingress card or device rather than all member ports.
When you aggregate ports on different member devices in an IRF fabric, you can use local-first load sharing to reduce traffic on IRF links, as shown in Figure 10. For more information about IRF, see IRF Configuration Guide.
Figure 10 Load sharing for multi-switch link aggregation in an IRF fabric
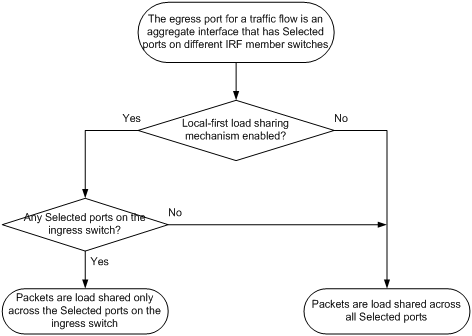
To enable local-first load sharing for link aggregation:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enable local-first load sharing for link aggregation. |
link-aggregation load-sharing mode local-first |
By default, local-first load sharing for link aggregation is enabled. |
|
|
NOTE: Local-first load sharing for link aggregation takes effect on only known unicast packets. |
Enabling link-aggregation traffic redirection
|
|
IMPORTANT: This feature is available in Release 1138P01 and later versions. |
Link-aggregation traffic redirection prevents traffic interruption.
When you restart a card that contains Selected ports, this feature redirects traffic of the card to other cards. (In standalone mode.)
When you restart an IRF member device that contains Selected ports, this feature redirects traffic of the IRF member device to other IRF member devices. When you restart a card that contains Selected ports, this feature redirects traffic of the card to other cards. (In IRF mode.)
You can enable link-aggregation traffic redirection globally or for an aggregation group. Global link-aggregation traffic redirection settings take effect on all aggregation groups. A link aggregation group preferentially uses the group-specific link-aggregation traffic redirection settings. If group-specific link-aggregation traffic redirection is not configured, the group uses the global link-aggregation traffic redirection settings.
Configuration restrictions and guidelines
When you enable link-aggregation traffic redirection, follow these restrictions and guidelines:
· Link-aggregation traffic redirection applies only to dynamic link aggregation groups.
· To prevent traffic interruption, enable link-aggregation traffic redirection on devices at both ends of the aggregate link.
· To prevent packet loss that might occur at a reboot, do not enable spanning tree together with link-aggregation traffic redirection.
· Link-aggregation traffic redirection does not operate correctly on an edge aggregate interface.
· As a best practice, enable link-aggregation traffic redirection on aggregate interfaces. If you enable this feature globally, communication with a third-party peer device might be affected if the peer is not compatible with this feature.
Configuration procedure
To enable link-aggregation traffic redirection globally:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enable link-aggregation traffic redirection globally. |
link-aggregation lacp traffic-redirect-notification enable |
By default, link-aggregation traffic redirection is disabled globally. |
To enable link-aggregation traffic redirection for an aggregation group:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter aggregate interface view. |
·
Enter Layer 2
aggregate interface view: ·
Enter Layer 3 aggregate interface view: |
N/A |
|
3. Enable link-aggregation traffic redirection for the aggregation group. |
link-aggregation lacp traffic-redirect-notification enable |
By default, link-aggregation traffic redirection is disabled for an aggregation group. |
Configuring the link aggregation capability for the device
|
|
IMPORTANT: This feature is available in Release 1138P01 and later versions. |
By default, the device supports a maximum of 1024 aggregation groups, and an aggregation group can have a maximum of 16 Selected ports. You can perform this task to modify the maximum number of aggregation groups and the maximum number of Selected ports per aggregation group.
After you configure the link aggregation capability for the device, save the configuration and reboot the device for the configuration to take effect. Before rebooting the device, make sure you know the possible impact on the network.
The maximum number of Selected ports allowed in an aggregation group is limited by one of the following values, whichever value is smaller:
· Maximum number set by using the link-aggregation selected-port maximum command.
· Maximum number of Selected ports allowed by the link aggregation capability.
To configure the link aggregation capability for the device:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Configure the link aggregation capability for the device. |
link-aggregation capability max-group max-group-number max-selected-port max-selected-port-number |
By default, the device supports a maximum of 1024 aggregation groups, and an aggregation group can have a maximum of 16 Selected ports. |
Displaying and maintaining Ethernet link aggregation
|
|
IMPORTANT: The display link-aggregation capability command is available in Release 1138P01 and later versions. |
Execute display commands in any view and reset commands in user view.
|
Task |
Command |
|
Display information for an aggregate interface or multiple aggregate interfaces. |
display interface [ bridge-aggregation| route-aggregation ] [ brief [ down | description ] ] display interface { bridge-aggregation | route-aggregation } interface-number [ brief [ description ] ] |
|
Display the local system ID. |
display lacp system-id |
|
Display the link aggregation capability for the device. |
display link-aggregation capability |
|
Display the global or group-specific link-aggregation load sharing modes. |
display link-aggregation load-sharing mode [ interface [ { bridge-aggregation | route-aggregation } interface-number ] ] |
|
Display forwarding information for the specified traffic flow. |
display link-aggregation load-sharing path interface { bridge-aggregation | route-aggregation } interface-number ingress-port interface-type interface-number [ route ] { { destination-ip ip-address | destination-ipv6 ipv6-address } | { source-ip ip-address | source-ipv6 ipv6-address } | destination-mac mac-address | destination-port port-id | ethernet-type type-number | ip-protocol protocol-id | source-mac mac-address | source-port port-id | vlan vlan-id }* |
|
Display detailed link aggregation information for link aggregation member ports. |
display link-aggregation member-port [ interface-list ] |
|
Display summary information about all aggregation groups. |
display link-aggregation summary |
|
Display detailed information about the specified aggregation groups. |
display link-aggregation verbose [ { bridge-aggregation | route-aggregation } [ interface-number ] ] |
|
Clear LACP statistics for the specified link aggregation member ports. |
reset lacp statistics [ interface interface-list ] |
|
Clear statistics for the specified aggregate interfaces. |
reset counters interface [ { bridge-aggregation | route-aggregation } [ interface-number ] ] |
Ethernet link aggregation configuration examples
Layer 2 static aggregation configuration example
Network requirements
As shown in Figure 11, configure a Layer 2 static aggregation group on both Device A and Device B, and enable VLAN 10 at one end of the aggregate link to communicate with VLAN 10 at the other end, and VLAN 20 at one end to communicate with VLAN 20 at the other end.
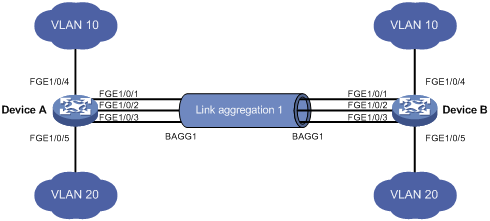
Configuration procedure
1. Configure Device A:
# Create VLAN 10, and assign port FortyGigE 1/0/4 to VLAN 10.
<DeviceA> system-view
[DeviceA] vlan 10
[DeviceA-vlan10] port fortygige 1/0/4
[DeviceA-vlan10] quit
# Create VLAN 20, and assign port FortyGigE 1/0/5 to VLAN 20.
[DeviceA] vlan 20
[DeviceA-vlan20] port fortygige 1/0/5
[DeviceA-vlan20] quit
# Create Layer 2 aggregate interface Bridge-Aggregation 1.
[DeviceA] interface bridge-aggregation 1
[DeviceA-Bridge-Aggregation1] quit
# Assign ports FortyGigE 1/0/1 through FortyGigE 1/0/3 to link aggregation group 1.
[DeviceA] interface fortygige 1/0/1
[DeviceA-FortyGigE1/0/1] port link-aggregation group 1
[DeviceA-FortyGigE1/0/1] quit
[DeviceA] interface fortygige 1/0/2
[DeviceA-FortyGigE1/0/2] port link-aggregation group 1
[DeviceA-FortyGigE1/0/2] quit
[DeviceA] interface fortygige 1/0/3
[DeviceA-FortyGigE1/0/3] port link-aggregation group 1
[DeviceA-FortyGigE1/0/3] quit
# Configure Layer 2 aggregate interface Bridge-Aggregation 1 as a trunk port and assign it to VLANs 10 and 20.
[DeviceA] interface bridge-aggregation 1
[DeviceA-Bridge-Aggregation1] port link-type trunk
[DeviceA-Bridge-Aggregation1] port trunk permit vlan 10 20
[DeviceA-Bridge-Aggregation1] quit
2. Configure Device B in the same way Device A is configured. (Details not shown.)
Verifying the configuration
# Display detailed information about all aggregation groups on Device A.
[DeviceA] display link-aggregation verbose
Loadsharing Type: Shar -- Loadsharing, NonS -- Non-Loadsharing
Port Status: S -- Selected, U -- Unselected, I -- Individual
Flags: A -- LACP_Activity, B -- LACP_Timeout, C -- Aggregation,
D -- Synchronization, E -- Collecting, F -- Distributing,
G -- Defaulted, H -- Expired
Aggregate Interface: Bridge-Aggregation1
Aggregation Mode: Static
Loadsharing Type: Shar
Port Status Priority Oper-Key
--------------------------------------------------------------------------------
FGE1/0/1 S 32768 1
FGE1/0/2 S 32768 1
FGE1/0/3 S 32768 1
The output shows that link aggregation group 1 is a Layer 2 static aggregation group and it contains three Selected ports.
Layer 2 dynamic aggregation configuration example
Network requirements
As shown in Figure 12, configure a Layer 2 dynamic aggregation group on both Device A and Device B, enable VLAN 10 at one end of the aggregate link to communicate with VLAN 10 at the other end, and VLAN 20 at one end to communicate with VLAN 20 at the other end.
Configuration procedure
1. Configure Device A:
# Create VLAN 10, and assign the port FortyGigE 1/0/4 to VLAN 10.
<DeviceA> system-view
[DeviceA] vlan 10
[DeviceA-vlan10] port fortygige 1/0/4
[DeviceA-vlan10] quit
# Create VLAN 20, and assign the port FortyGigE 1/0/5 to VLAN 20.
[DeviceA] vlan 20
[DeviceA-vlan20] port fortygige 1/0/5
[DeviceA-vlan20] quit
# Create Layer 2 aggregate interface Bridge-Aggregation 1, and set the link aggregation mode to dynamic.
[DeviceA] interface bridge-aggregation 1
[DeviceA-Bridge-Aggregation1] link-aggregation mode dynamic
[DeviceA-Bridge-Aggregation1] quit
# Assign ports FortyGigE 1/0/1 through FortyGigE 1/0/3 to link aggregation group 1.
[DeviceA] interface fortygige 1/0/1
[DeviceA-FortyGigE1/0/1] port link-aggregation group 1
[DeviceA-FortyGigE1/0/1] quit
[DeviceA] interface fortygige 1/0/2
[DeviceA-FortyGigE1/0/2] port link-aggregation group 1
[DeviceA-FortyGigE1/0/2] quit
[DeviceA] interface fortygige 1/0/3
[DeviceA-FortyGigE1/0/3] port link-aggregation group 1
[DeviceA-FortyGigE1/0/3] quit
# Configure Layer 2 aggregate interface Bridge-Aggregation 1 as a trunk port and assign it to VLANs 10 and 20.
[DeviceA] interface bridge-aggregation 1
[DeviceA-Bridge-Aggregation1] port link-type trunk
[DeviceA-Bridge-Aggregation1] port trunk permit vlan 10 20
[DeviceA-Bridge-Aggregation1] quit
2. Configure Device B in the same way Device A is configured. (Details not shown.)
Verifying the configuration
# Display detailed information about all aggregation groups on Device A.
[DeviceA] display link-aggregation verbose
Loadsharing Type: Shar -- Loadsharing, NonS -- Non-Loadsharing
Port Status: S -- Selected, U -- Unselected, I -- Individual
Flags: A -- LACP_Activity, B -- LACP_Timeout, C -- Aggregation,
D -- Synchronization, E -- Collecting, F -- Distributing,
G -- Defaulted, H -- Expired
Aggregate Interface: Bridge-Aggregation1
Aggregation Mode: Dynamic
Loadsharing Type: Shar
System ID: 0x8000, 000f-e267-6c6a
Local:
Port Status Priority Oper-Key Flag
--------------------------------------------------------------------------------
FGE1/0/1 S 32768 1 {ACDEF}
FGE1/0/2 S 32768 1 {ACDEF}
FGE1/0/3 S 32768 1 {ACDEF}
Remote:
Actor Partner Priority Oper-Key SystemID Flag
--------------------------------------------------------------------------------
FGE1/0/1 1 32768 1 0x8000, 000f-e267-57ad {ACDEF}
FGE1/0/2 2 32768 1 0x8000, 000f-e267-57ad {ACDEF}
FGE1/0/3 3 32768 1 0x8000, 000f-e267-57ad {ACDEF}
The output shows that link aggregation group 1 is a Layer 2 dynamic aggregation group and it contains three Selected ports.
Layer 2 aggregation load sharing configuration example
Network requirements
As shown in Figure 13:
· Configure two Layer 2 static aggregation groups (1 and 2) on Device A and Device B, respectively.
· Enable VLAN 10 at one end of the aggregate link to communicate with VLAN 10 at the other end.
· Enable VLAN 20 at one end of the aggregate link to communicate with VLAN 20 at the other end.
· Configure the global load sharing mode to load share traffic across aggregation group member ports based on source MAC addresses.
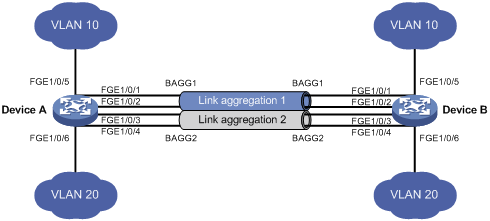
Configuration procedure
1. Configure Device A:
# Create VLAN 10, and assign the port FortyGigE 1/0/5 to VLAN 10.
<DeviceA> system-view
[DeviceA] vlan 10
[DeviceA-vlan10] port fortygige 1/0/5
[DeviceA-vlan10] quit
# Create VLAN 20, and assign the port FortyGigE 1/0/6 to VLAN 20.
[DeviceA] vlan 20
[DeviceA-vlan20] port fortygige 1/0/6
[DeviceA-vlan20] quit
# Create Layer 2 aggregate interface Bridge-Aggregation 1.
[DeviceA] interface bridge-aggregation 1
[DeviceA-Bridge-Aggregation1] quit
# Assign ports FortyGigE 1/0/1 and FortyGigE 1/0/2 to link aggregation group 1.
[DeviceA] interface fortygige 1/0/1
[DeviceA-FortyGigE1/0/1] port link-aggregation group 1
[DeviceA-FortyGigE1/0/1] quit
[DeviceA] interface fortygige 1/0/2
[DeviceA-FortyGigE1/0/2] port link-aggregation group 1
[DeviceA-FortyGigE1/0/2] quit
# Configure Layer 2 aggregate interface Bridge-Aggregation 1 as a trunk port and assign it to VLAN 10.
[DeviceA] interface bridge-aggregation 1
[DeviceA-Bridge-Aggregation1] port link-type trunk
[DeviceA-Bridge-Aggregation1] port trunk permit vlan 10
[DeviceA-Bridge-Aggregation1] quit
# Create Layer 2 aggregate interface Bridge-Aggregation 2.
[DeviceA] interface bridge-aggregation 2
[DeviceA-Bridge-Aggregation2] quit
# Assign ports FortyGigE 1/0/3 and FortyGigE 1/0/4 to link aggregation group 2.
[DeviceA] interface fortygige 1/0/3
[DeviceA-FortyGigE1/0/3] port link-aggregation group 2
[DeviceA-FortyGigE1/0/3] quit
[DeviceA] interface fortygige 1/0/4
[DeviceA-FortyGigE1/0/4] port link-aggregation group 2
[DeviceA-FortyGigE1/0/4] quit
# Configure Layer 2 aggregate interface Bridge-Aggregation 2 as a trunk port and assign it to VLAN 20.
[DeviceA] interface bridge-aggregation 2
[DeviceA-Bridge-Aggregation2] port link-type trunk
[DeviceA-Bridge-Aggregation2] port trunk permit vlan 20
[DeviceA-Bridge-Aggregation2] quit
# Configure the global link-aggregation load sharing mode to load share packets based on source MAC addresses.
[DeviceA] link-aggregation global load-sharing mode source-mac
2. Configure Device B in the same way Device A is configured. (Details not shown.)
Verifying the configuration
# Display detailed information about all aggregation groups on Device A.
[DeviceA] display link-aggregation verbose
Loadsharing Type: Shar -- Loadsharing, NonS -- Non-Loadsharing
Port Status: S -- Selected, U -- Unselected, I -- Individual
Flags: A -- LACP_Activity, B -- LACP_Timeout, C -- Aggregation,
D -- Synchronization, E -- Collecting, F -- Distributing,
G -- Defaulted, H -- Expired
Aggregate Interface: Bridge-Aggregation1
Aggregation Mode: Static
Loadsharing Type: Shar
Port Status Priority Oper-Key
--------------------------------------------------------------------------------
FGE1/0/1 S 32768 1
FGE1/0/2 S 32768 1
Aggregate Interface: Bridge-Aggregation2
Aggregation Mode: Static
Loadsharing Type: Shar
Port Status Priority Oper-Key
--------------------------------------------------------------------------------
FGE1/0/3 S 32768 2
FGE1/0/4 S 32768 2
The output shows that link aggregation groups 1 and 2 are both load-shared Layer 2 static aggregation groups and each contains two Selected ports.
# Display all the group-specific load sharing modes on Device A.
[DeviceA] display link-aggregation load-sharing mode interface
Bridge-Aggregation1 Load-Sharing Mode:
source-mac address
Bridge-Aggregation2 Load-Sharing Mode:
source-mac address
The output shows that both link aggregation group 1 and link aggregation group 2 load share packets based on source MAC addresses.
Layer 3 static aggregation configuration example
Network requirements
As shown in Figure 14:
· Reserve four VLAN interface resources before creating a Layer 3 aggregate interface.
· Configure a Layer 3 static aggregation group on both Device A and Device B.
· Configure IP addresses and subnet masks for the corresponding Layer 3 aggregate interfaces.

Configuration procedure
1. Configure Device A:
# Reserve VLAN interface resources of VLANs 3000 to 3500. For more information about reserving VLAN interface resources, see "Configuring VLANs."
<DeviceA> system-view
[DeviceA] reserve-vlan-interface 3000 to 3500
# Create Layer 3 aggregate interface Route-Aggregation 1, and configure an IP address and subnet mask for the aggregate interface.
<DeviceA> system-view
[DeviceA] interface route-aggregation 1
[DeviceA-Route-Aggregation1] ip address 192.168.1.1 24
[DeviceA-Route-Aggregation1] quit
# Assign Layer 3 Ethernet interfaces FortyGigE 1/0/1 through FortyGigE 1/0/3 to aggregation group 1.
[DeviceA] interface fortygige 1/0/1
[DeviceA-FortyGigE1/0/1] port link-aggregation group 1
[DeviceA-FortyGigE1/0/1] quit
[DeviceA] interface fortygige 1/0/2
[DeviceA-FortyGigE1/0/2] port link-aggregation group 1
[DeviceA-FortyGigE1/0/2] quit
[DeviceA] interface fortygige 1/0/3
[DeviceA-FortyGigE1/0/3] port link-aggregation group 1
[DeviceA-FortyGigE1/0/3] quit
2. Configure Device B in the same way Device A is configured. (Details not shown.)
Verifying the configuration
# Display detailed information about all aggregation groups on Device A.
[DeviceA] display link-aggregation verbose
Loadsharing Type: Shar -- Loadsharing, NonS -- Non-Loadsharing
Port Status: S -- Selected, U -- Unselected, I -- Individual
Flags: A -- LACP_Activity, B -- LACP_Timeout, C -- Aggregation,
D -- Synchronization, E -- Collecting, F -- Distributing,
G -- Defaulted, H -- Expired
Aggregate Interface: Route-Aggregation1
Aggregation Mode: Static
Loadsharing Type: Shar
Port Status Priority Oper-Key
--------------------------------------------------------------------------------
FGE1/0/1 S 32768 1
FGE1/0/2 S 32768 1
FGE1/0/3 S 32768 1
The output shows that link aggregation group 1 is a non-load-shared Layer 3 static aggregation group that contains three Selected ports.
Layer 3 dynamic aggregation configuration example
Network requirements
As shown in Figure 15:
· Reserve four VLAN interface resources before creating a Layer 3 aggregate interface.
· Configure a Layer 3 dynamic aggregation group on both Device A and Device B.
· Configure IP addresses and subnet masks for the corresponding Layer 3 aggregate interfaces.

Configuration procedure
1. Configure Device A:
# Reserve VLAN interface resources of VLANs 3000 to 3500. For more information about reserving VLAN interface resources, see "Configuring VLANs."
<DeviceA> system-view
[DeviceA] reserve-vlan-interface 3000 to 3500
# Create Layer 3 aggregate interface Route-Aggregation 1.
<DeviceA> system-view
[DeviceA] interface route-aggregation 1
# Configure the link aggregation mode as dynamic.
[DeviceA-Route-Aggregation1] link-aggregation mode dynamic
# Configure an IP address and subnet mask for Route-Aggregation 1.
[DeviceA-Route-Aggregation1] ip address 192.168.1.1 24
[DeviceA-Route-Aggregation1] quit
# Assign Layer 3 Ethernet interfaces FortyGigE 1/0/1 through FortyGigE 1/0/3 to aggregation group 1.
[DeviceA] interface fortygige 1/0/1
[DeviceA-FortyGigE1/0/1] port link-aggregation group 1
[DeviceA-FortyGigE1/0/1] quit
[DeviceA] interface fortygige 1/0/2
[DeviceA-FortyGigE1/0/2] port link-aggregation group 1
[DeviceA-FortyGigE1/0/2] quit
[DeviceA] interface fortygige 1/0/3
[DeviceA-FortyGigE1/0/3] port link-aggregation group 1
[DeviceA-FortyGigE1/0/3] quit
2. Configure Device B in the same way Device A is configured. (Details not shown.)
Verifying the configuration
# Display detailed information about all aggregation groups on Device A.
[DeviceA] display link-aggregation verbose
Loadsharing Type: Shar -- Loadsharing, NonS -- Non-Loadsharing
Port Status: S -- Selected, U -- Unselected, I -- Individual
Flags: A -- LACP_Activity, B -- LACP_Timeout, C -- Aggregation,
D -- Synchronization, E -- Collecting, F -- Distributing,
G -- Defaulted, H -- Expired
Aggregate Interface: Route-Aggregation1
Aggregation Mode: Dynamic
Loadsharing Type: Shar
System ID: 0x8000, 000f-e267-6c6a
Local:
Port Status Priority Oper-Key Flag
--------------------------------------------------------------------------------
FGE1/0/1 S 32768 1 {ACDEF}
FGE1/0/2 S 32768 1 {ACDEF}
FGE1/0/3 S 32768 1 {ACDEF}
Remote:
Actor Partner Priority Oper-Key SystemID Flag
--------------------------------------------------------------------------------
FGE1/0/1 1 32768 1 0x8000, 000f-e267-57ad {ACDEF}
FGE1/0/2 2 32768 1 0x8000, 000f-e267-57ad {ACDEF}
FGE1/0/3 3 32768 1 0x8000, 000f-e267-57ad {ACDEF}
The output shows that:
· Link aggregation group 1 is a non-load-shared Layer 3 dynamic aggregation group.
· The aggregation group contains three Selected ports.
Layer 3 edge aggregate interface configuration example
Network requirements
As shown in Figure 16, a Layer 3 dynamic aggregation group is configured on the device. The server is not configured with dynamic link aggregation.
Configure an edge aggregate interface so that both FortyGigE 1/0/1 and FortyGigE 1/0/2 can forward traffic to improve link reliability.
Reserve three VLAN interface resources before creating the Layer 3 aggregate interface.

Configuration procedure
# Reserve VLAN interface resources of VLANs 3000 to 3500. For more information about reserving VLAN interface resources, see "Configuring VLANs."
<DeviceA> system-view
[DeviceA] reserve-vlan-interface 3000 to 3500
# Create Layer 3 aggregate interface Route-Aggregation 1, and set the link aggregation mode to dynamic.
<Device> system-view
[Device] interface route-aggregation 1
[Device-Route-Aggregation1] link-aggregation mode dynamic
# Configure an IP address and subnet mask for Layer 3 aggregate interface Route-Aggregation 1.
[Device-Route-Aggregation1] ip address 192.168.1.1 24
# Configure Layer 3 aggregate interface Route-Aggregation 1 as an edge aggregate interface.
[Device-Route-Aggregation1] lacp edge-port
[Device-Route-Aggregation1] quit
# Assign Layer 3 Ethernet interfaces FortyGigE 1/0/1 and FortyGigE 1/0/2 to aggregation group 1.
[Device] interface fortygige 1/0/1
[Device-FortyGigE1/0/1] port link-aggregation group 1
[Device-FortyGigE1/0/1] quit
[Device] interface fortygige 1/0/2
[Device-FortyGigE1/0/2] port link-aggregation group 1
[Device-FortyGigE1/0/2] quit
Verifying the configuration
# Display detailed information about all aggregation groups on the device when the server is not configured with dynamic link aggregation.
[Device] display link-aggregation verbose
Loadsharing Type: Shar -- Loadsharing, NonS -- Non-Loadsharing
Port Status: S -- Selected, U -- Unselected, I -- Individual
Flags: A -- LACP_Activity, B -- LACP_Timeout, C -- Aggregation,
D -- Synchronization, E -- Collecting, F -- Distributing,
G -- Defaulted, H -- Expired
Aggregate Interface: Route-Aggregation1
Aggregation Mode: Dynamic
Loadsharing Type: NonS
System ID: 0x8000, 000f-e267-6c6a
Local:
Port Status Priority Oper-Key Flag
--------------------------------------------------------------------------------
FGE1/0/1 I 32768 1 {AG}
FGE1/0/2 I 32768 1 {AG}
Remote:
Actor Partner Priority Oper-Key SystemID Flag
--------------------------------------------------------------------------------
FGE1/0/1 0 32768 0 0x8000, 0000-0000-0000 {DEF}
FGE1/0/2 0 32768 0 0x8000, 0000-0000-0000 {DEF}
The output shows that FortyGigE 1/0/1 and FortyGigE 1/0/2 are in Individual state when they do not receive LACPDUs from the server. Both FortyGigE 1/0/1 and FortyGigE 1/0/2 can forward traffic. When one port fails, its traffic is automatically switched to the other port.
Configuring port isolation
The port isolation feature isolates Layer 2 traffic for data privacy and security without using VLANs. You can also use this feature to isolate the hosts in a VLAN from one another.
You can manually create isolation groups on the switch, but only the isolation group numbered 1 is valid. The number of ports assigned to an isolation group is not limited.
Within the same VLAN, ports in an isolation group can communicate with those outside the isolation group at Layer 2.
Assigning ports to an isolation group
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Create an isolation group. |
port-isolate group group-number |
For this switch series, only the isolation group numbered 1 is valid. |
|
3. Enter interface view. |
·
Enter Layer 2 Ethernet interface view: ·
Enter Layer 2 aggregate interface view: |
· The configuration in Layer 2 Ethernet interface view applies only to the interface. · The configuration in Layer 2 aggregate interface view applies to the Layer 2 aggregate interface and its aggregation member ports. If the device fails to apply the configuration to the aggregate interface, it does not assign any aggregation member port to the isolation group. If the failure occurs on an aggregation member port, the device skips the port and continues to assign other aggregation member ports to the isolation group. |
|
4. Assign ports to the specified isolation group. |
port-isolate enable group group-number |
No ports are assigned to an isolation group by default. For this switch series, you can assign ports to only isolation group 1. |
Displaying and maintaining port isolation
Execute display commands in any view.
|
Task |
Command |
|
Display isolation group information |
display port-isolate group [ group-number ] [ | { begin | exclude | include } regular-expression ] |
Port isolation configuration example
Network requirements
As shown in Figure 17, LAN users Host A, Host B, and Host C are connected to FortyGigE 1/0/1, FortyGigE 1/0/2, and FortyGigE 1/0/3 on the device, respectively. The device connects to the Internet through FortyGigE 1/0/4.
Configure the device to provide Internet access for the hosts, and isolate them from one another at Layer 2.
Configuration procedure
# Create isolation group 1.
<Device> system-view
[Device] port-isolate group 1
# Assign FortyGigE 1/0/1, FortyGigE 1/0/2, and FortyGigE 1/0/3 to isolation group 1.
[Device] interface fortygige 1/0/1
[Device-FortyGigE1/0/1] port-isolate enable group 1
[Device-FortyGigE1/0/1] quit
[Device] interface fortygige 1/0/2
[Device-FortyGigE1/0/2] port-isolate enable group 1
[Device-FortyGigE1/0/2] quit
[Device] interface fortygige 1/0/3
[Device-FortyGigE1/0/3] port-isolate enable group 1
Verifying the configuration
# Display information about isolation group 1.
[Device-FortyGigE1/0/3] display port-isolate group 1
Port isolation group information:
Group ID: 1
Group members:
FortyGigE1/0/1
FortyGigE1/0/2
FortyGigE1/0/3
Configuring spanning tree protocols
Spanning tree protocols eliminate loops in a physical link-redundant network by selectively blocking redundant links and putting them in a standby state.
The recent versions of STP include the Rapid Spanning Tree Protocol (RSTP) and the Multiple Spanning Tree Protocol (MSTP).
STP
STP was developed based on the 802.1d standard of IEEE to eliminate loops at the data link layer in a LAN. Networks often have redundant links as backups in case of failures, but loops are a very serious problem. Devices running STP detect loops in the network by exchanging information with one another, and eliminate loops by selectively blocking certain ports to prune the loop structure into a loop-free tree structure. This avoids proliferation and infinite cycling of packets that would occur in a loop network.
In the narrow sense, STP refers to IEEE 802.1d STP. In the broad sense, STP refers to the IEEE 802.1d STP and various enhanced spanning tree protocols derived from that protocol.
STP protocol packets
STP uses bridge protocol data units (BPDUs), also known as configuration messages, as its protocol packets. This chapter uses BPDUs to represent all types of spanning tree protocol packets.
STP-enabled network devices exchange BPDUs to establish a spanning tree. BPDUs contain sufficient information for the network devices to complete spanning tree calculation.
STP uses the following types of BPDUs:
· Configuration BPDUs—Used by the network devices to calculate a spanning tree and maintain the spanning tree topology.
· Topology change notification (TCN) BPDUs—Notify network devices of network topology changes.
Configuration BPDUs contain sufficient information for the network devices to complete spanning tree calculation. Important fields in a configuration BPDU include the following:
· Root bridge ID—Consisting of the priority and MAC address of the root bridge.
· Root path cost—Cost of the path to the root bridge denoted by the root identifier from the transmitting bridge.
· Designated bridge ID—Consisting of the priority and MAC address of the designated bridge.
· Designated port ID—Consisting of the priority and global port number of the designated port.
· Message age—Age of the configuration BPDU while it propagates in the network.
· Max age—Maximum age of the configuration BPDU stored on the switch.
· Hello time—Configuration BPDU transmission interval.
· Forward delay—Delay that STP bridges use to transit port state.
Basic concepts in STP
Root bridge
A tree network must have a root bridge. The entire network contains only one root bridge, and all the other bridges in the network are called "leaf nodes". The root bridge is not permanent, but can change with changes of the network topology.
Upon initialization of a network, each device generates and periodically sends configuration BPDUs, with itself as the root bridge. After network convergence, only the root bridge generates and periodically sends configuration BPDUs. The other devices only forward the BPDUs.
Root port
Designated bridge and designated port
|
Classification |
Designated bridge |
Designated port |
|
For a device |
Device directly connected to the local device and responsible for forwarding BPDUs to the local device |
Port through which the designated bridge forwards BPDUs to this device |
|
For a LAN |
Device responsible for forwarding BPDUs to this LAN segment |
Port through which the designated bridge forwards BPDUs to this LAN segment |
As shown in Figure 18, Device B and Device C are directly connected to a LAN. If Device A forwards BPDUs to Device B through port A1, the designated bridge for Device B is Device A, and the designated port of Device B is port A1 on Device A. If Device B forwards BPDUs to the LAN, the designated bridge for the LAN is Device B, and the designated port for the LAN is port B2 on Device B.
Figure 18 Designated bridges and designated ports
Path cost
Path cost is a reference value used for link selection in STP. STP calculates path costs to select the most robust links and block redundant links that are less robust, to prune the network into a loop-free tree.
Calculation process of the STP algorithm
The spanning tree calculation process described in the following sections is a simplified process for example only.
Calculation process
The STP algorithm uses the following calculation process:
1. Network initialization.
Upon initialization of a device, each port generates a BPDU with the port as the designated port, the device as the root bridge, 0 as the root path cost, and the device ID as the designated bridge ID.
2. Root bridge selection.
Initially, each STP-enabled device on the network assumes itself to be the root bridge, with its own device ID as the root bridge ID. By exchanging configuration BPDUs, the devices compare their root bridge IDs to elect the device with the smallest root bridge ID as the root bridge.
3. Root port and designated ports selection on the non-root bridges.
|
Step |
Description |
|
1 |
A non-root–bridge device regards the port on which it received the optimum configuration BPDU as the root port. Table 5 describes how the optimum configuration BPDU is selected. |
|
2 |
Based on the configuration BPDU and the path cost of the root port, the device calculates a designated port configuration BPDU for each of the other ports. · The root bridge ID is replaced with that of the configuration BPDU of the root port. · The root path cost is replaced with that of the configuration BPDU of the root port plus the path cost of the root port. · The designated bridge ID is replaced with the ID of this device. · The designated port ID is replaced with the ID of this port. |
|
3 |
The device compares the calculated configuration BPDU with the configuration BPDU on the port whose port role will be determined, and acts depending on the result of the comparison: · If the calculated configuration BPDU is superior, the device considers this port as the designated port, replaces the configuration BPDU on the port with the calculated configuration BPDU, and periodically sends the calculated configuration BPDU. · If the configuration BPDU on the port is superior, the device blocks this port without updating its configuration BPDU. The blocked port can receive BPDUs, but cannot send BPDUs or forward data traffic. |
When the network topology is stable, only the root port and designated ports forward user traffic. Other ports are all in the blocked state to receive BPDUs but not to forward BPDUs or user traffic.
Table 5 Selecting the optimum configuration BPDU
|
Step |
Actions |
|
1 |
Upon receiving a configuration BPDU on a port, the device compares the priority of the received configuration BPDU with that of the configuration BPDU generated by the port, and: · If the former priority is lower, the device discards the received configuration BPDU and keeps the configuration BPDU the port generated. · If the former priority is higher, the device replaces the content of the configuration BPDU generated by the port with the content of the received configuration BPDU. |
|
2 |
The device compares the configuration BPDUs of all the ports and chooses the optimum configuration BPDU. |
The following are the principles of configuration BPDU comparison:
a. The configuration BPDU with the lowest root bridge ID has the highest priority.
b. If configuration BPDUs have the same root bridge ID, their root path costs are compared. For example, the root path cost in a configuration BPDU plus the path cost of a receiving port is S. The configuration BPDU with the smallest S value has the highest priority.
c. If all configuration BPDUs have the same root bridge ID and S value, their designated bridge IDs, designated port IDs, and the IDs of the receiving ports are compared in sequence. The configuration BPDU that contains a smaller designated bridge ID, designated port ID, or receiving port ID is selected.
A tree-shape topology forms when the root bridge, root ports, and designated ports are selected.
Example of STP calculation
Figure 19 provides an example showing how the STP algorithm works.
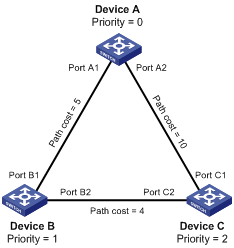
As shown in Figure 19, the priority values of Device A, Device B, and Device C are 0, 1, and 2, and the path costs of links among the three devices are 5, 10, and 4, respectively.
1. Device state initialization.
In Table 6, each configuration BPDU contains the following fields: root bridge ID, root path cost, designated bridge ID, and designated port ID.
Table 6 Initial state of each device
|
Device |
Port name |
Configuration BPDU on the port |
|
Device A |
Port A1 |
{0, 0, 0, Port A1} |
|
Port A2 |
{0, 0, 0, Port A2} |
|
|
Device B |
Port B1 |
{1, 0, 1, Port B1} |
|
Port B2 |
{1, 0, 1, Port B2} |
|
|
Device C |
Port C1 |
{2, 0, 2, Port C1} |
|
Port C2 |
{2, 0, 2, Port C2} |
2. Configuration BPDUs comparison on each device.
In Table 7, each configuration BPDU contains the following fields: root bridge ID, root path cost, designated bridge ID, and designated port ID.
Table 7 Comparison process and result on each device
|
Device |
Comparison process |
Configuration BPDU on ports after comparison |
|
Device A |
· Port A1 receives the configuration BPDU of Port B1 {1, 0, 1, Port B1}, finds that its existing configuration BPDU {0, 0, 0, Port A1} is superior to the received configuration BPDU, and discards the received one. · Port A2 receives the configuration BPDU of Port C1 {2, 0, 2, Port C1}, finds that its existing configuration BPDU {0, 0, 0, Port A2} is superior to the received configuration BPDU, and discards the received one. · Device A finds that it is both the root bridge and designated bridge in the configuration BPDUs of all its ports, and considers itself as the root bridge. It does not change the configuration BPDU of any port and starts to periodically send configuration BPDUs. |
· Port A1: {0, 0, 0, Port A1} · Port A2: {0, 0, 0, Port A2} |
|
Device B |
· Port B1 receives the configuration BPDU of Port A1 {0, 0, 0, Port A1}, finds that the received configuration BPDU is superior to its existing configuration BPDU {1, 0, 1, Port B1}, and updates its configuration BPDU. · Port B2 receives the configuration BPDU of Port C2 {2, 0, 2, Port C2}, finds that its existing configuration BPDU {1, 0, 1, Port B2} is superior to the received configuration BPDU, and discards the received one. |
· Port B1: {0, 0, 0, Port A1} · Port B2: {1, 0, 1, Port B2} |
|
· Device B compares the configuration BPDUs of all its ports, decides that the configuration BPDU of Port B1 is the optimum, and selects Port B1 as the root port with the configuration BPDU unchanged. · Based on the configuration BPDU and path cost of the root port, Device B calculates a designated port configuration BPDU for Port B2 {0, 5, 1, Port B2}, and compares it with the existing configuration BPDU of Port B2 {1, 0, 1, Port B2}. Device B finds that the calculated one is superior, decides that Port B2 is the designated port, replaces the configuration BPDU on Port B2 with the calculated one, and periodically sends the calculated configuration BPDU. |
· Root port (Port B1): {0, 0, 0, Port A1} · Designated port (Port B2): {0, 5, 1, Port B2} |
|
|
Device C |
· Port C1 receives the configuration BPDU of Port A2 {0, 0, 0, Port A2}, finds that the received configuration BPDU is superior to its existing configuration BPDU {2, 0, 2, Port C1}, and updates its configuration BPDU. · Port C2 receives the original configuration BPDU of Port B2 {1, 0, 1, Port B2}, finds that the received configuration BPDU is superior to the existing configuration BPDU {2, 0, 2, Port C2}, and updates its configuration BPDU. |
· Port C1: {0, 0, 0, Port A2} · Port C2: {1, 0, 1, Port B2} |
|
· Device C compares the configuration BPDUs of all its ports, decides that the configuration BPDU of Port C1 is the optimum, and selects Port C1 as the root port with the configuration BPDU unchanged. · Based on the configuration BPDU and path cost of the root port, Device C calculates the configuration BPDU of Port C2 {0, 10, 2, Port C2}, and compares it with the existing configuration BPDU of Port C2 {1, 0, 1, Port B2}. Device C finds that the calculated configuration BPDU is superior to the existing one, selects Port C2 as the designated port, and replaces the configuration BPDU of Port C2 with the calculated one. |
· Root port (Port C1): {0, 0, 0, Port A2} · Designated port (Port C2): {0, 10, 2, Port C2} |
|
|
· Port C2 receives the updated configuration BPDU of Port B2 {0, 5, 1, Port B2}, finds that the received configuration BPDU is superior to its existing configuration BPDU {0, 10, 2, Port C2}, and updates its configuration BPDU. · Port C1 receives a periodic configuration BPDU {0, 0, 0, Port A2} from Port A2, finds that it is the same as the existing configuration BPDU, and discards the received one. |
· Port C1: {0, 0, 0, Port A2} · Port C2: {0, 5, 1, Port B2} |
|
|
· Device C finds that the root path cost of Port C1 (10) (root path cost of the received configuration BPDU (0) plus path cost of Port C1 (10)) is larger than that of Port C2 (9) (root path cost of the received configuration BPDU (5) plus path cost of Port C2 (4)), decides that the configuration BPDU of Port C2 is the optimum, and selects Port C2 as the root port with the configuration BPDU unchanged. · Based on the configuration BPDU and path cost of the root port, Device C calculates a designated port configuration BPDU for Port C1 {0, 9, 2, Port C1} and compares it with the existing configuration BPDU of Port C1 {0, 0, 0, Port A2}. Device C finds that the existing configuration BPDU is superior to the calculated one and blocks Port C1 with the configuration BPDU unchanged. Then Port C1 does not forward data until a new event triggers a spanning tree calculation process, for example, the link between Device B and Device C is down. |
· Blocked port (Port C1): {0, 0, 0, Port A2} · Root port (Port C2): {0, 5, 1, Port B2} |
After the comparison processes described in Table 7, a spanning tree with Device A as the root bridge is established, and the topology is shown in Figure 20.
Figure 20 The final calculated spanning tree
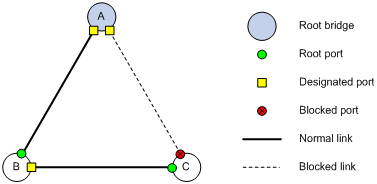
The configuration BPDU forwarding mechanism of STP
The configuration BPDUs of STP are forwarded according to these guidelines:
· Upon network initiation, every device regards itself as the root bridge, generates configuration BPDUs with itself as the root, and sends the configuration BPDUs at a regular hello interval.
· If the root port received a configuration BPDU and the received configuration BPDU is superior to the configuration BPDU of the port, the device increases the message age carried in the configuration BPDU following a certain rule and starts a timer to time the configuration BPDU while sending this configuration BPDU through the designated port.
· If the configuration BPDU received on a designated port has a lower priority than the configuration BPDU of the local port, the port immediately sends its own configuration BPDU in response.
· If a path becomes faulty, the root port on this path no longer receives new configuration BPDUs and the old configuration BPDUs will be discarded due to timeout. The device generates a configuration BPDU with itself as the root and sends the BPDUs and TCN BPDUs. This triggers a new spanning tree calculation process to establish a new path to restore the network connectivity.
However, the newly calculated configuration BPDU cannot be propagated throughout the network immediately, so the old root ports and designated ports that have not detected the topology change continue forwarding data along the old path. If the new root ports and designated ports begin to forward data as soon as they are elected, a temporary loop might occur.
STP timers
The most important timing parameters in STP calculation are forward delay, hello time, and max age.
· Forward delay—Forward delay is the delay time for port state transition.
A path failure can cause spanning tree re-calculation to adapt the spanning tree structure to the change. However, the resulting new configuration BPDU cannot propagate throughout the network immediately. If the newly elected root ports and designated ports start to forward data immediately, a temporary loop will likely occur.
For this reason, as a mechanism for state transition in STP, the newly elected root ports or designated ports require twice the forward delay time before they transit to the forwarding state to make sure the new configuration BPDU has propagated throughout the network.
· Hello time—The device sends hello packets at the hello time interval to the neighboring devices to make sure the paths are fault-free.
· Max age—The device uses the max age to determine whether a stored configuration BPDU has expired and discards it if the max age is exceeded.
RSTP
RSTP achieves rapid network convergence by allowing a newly elected root port or designated port to enter the forwarding state much faster than STP.
If the old root port on the device has stopped forwarding data and the upstream designated port has started forwarding data, a newly elected RSTP root port rapidly enters the forwarding state.
A newly elected RSTP designated port rapidly enters the forwarding state if it is an edge port (a port that directly connects to a user terminal rather than to another network device or a shared LAN segment) or it connects to a point-to-point link. Edge ports directly enter the forwarding state. Connecting to a point-to-point link, a designated port enters the forwarding state immediately after the device receives a handshake response from the directly connected device.
MSTP
MSTP overcomes the following STP and RSTP limitations:
· STP limitations—STP does not support rapid state transition of ports. A newly elected port must wait twice the forward delay time before it transits to the forwarding state, even if it connects to a point-to-point link or is an edge port.
· RSTP limitations—Although RSTP enables faster network convergence than STP, RSTP fails to provide load balancing among VLANs. As with STP, all RSTP bridges in a LAN share one spanning tree and forward packets from all VLANs along this spanning tree.
MSTP features
Developed based on IEEE 802.1s, MSTP overcomes the limitations of STP and RSTP. In addition to supporting rapid network convergence, it provides a better load sharing mechanism for redundant links by allowing data flows of different VLANs to be forwarded along separate paths.
MSTP provides the following features:
· MSTP divides a switched network into multiple regions, each of which contains multiple spanning trees that are independent of one another.
· MSTP supports mapping VLANs to spanning tree instances by means of a VLAN-to-instance mapping table. MSTP can reduce communication overheads and resource usage by mapping multiple VLANs to one instance.
· MSTP prunes a loop network into a loop-free tree, which avoids proliferation and endless cycling of packets in a loop network. In addition, it supports load balancing of VLAN data by providing multiple redundant paths for data forwarding.
· MSTP is compatible with STP and RSTP.
MSTP basic concepts
Figure 21 shows a switched network that contains four MST regions, each MST region containing four MSTP devices. Figure 22 shows the networking topology of MST region 3.
Figure 21 Basic concepts in MSTP
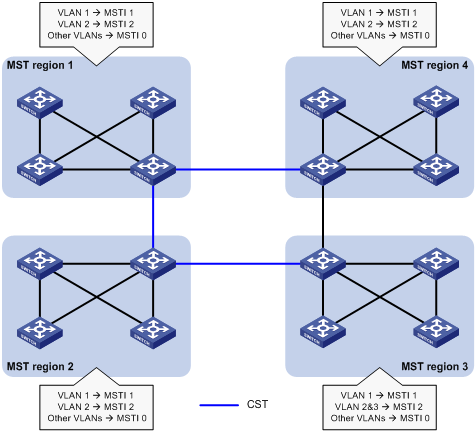
Figure 22 Network diagram and topology of MST region 3
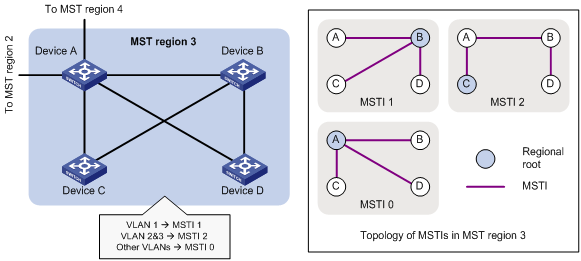
MST region
A multiple spanning tree region (MST region) consists of multiple devices in a switched network and the network segments among them. All these devices have the following characteristics:
· A spanning tree protocol enabled
· Same region name
· Same VLAN-to-instance mapping configuration
· Same MSTP revision level
· Physically linked together
Multiple MST regions can exist in a switched network. You can assign multiple devices to the same MST region. In Figure 21, the switched network contains four MST regions, MST region 1 through MST region 4, and all devices in each MST region have the same MST region configuration.
MSTI
MSTP can generate multiple independent spanning trees in an MST region, and each spanning tree is mapped to the specific VLANs. Each spanning tree is referred to as a "multiple spanning tree instance (MSTI)".
In Figure 22, MST region 3 contains three MSTIs, MSTI 1, MSTI 2, and MSTI 0.
VLAN-to-instance mapping table
As an attribute of an MST region, the VLAN-to-instance mapping table describes the mapping relationships between VLANs and MSTIs.
In Figure 22, the VLAN-to-instance mapping table of MST region 3 is: VLAN 1 to MSTI 1, VLAN 2 and VLAN 3 to MSTI 2, and other VLANs to MSTI 0. MSTP achieves load balancing by means of the VLAN-to-instance mapping table.
CST
The common spanning tree (CST) is a single spanning tree that connects all MST regions in a switched network. If you regard each MST region as a device, the CST is a spanning tree calculated by these devices through STP or RSTP.
The blue lines in Figure 21 represent the CST.
IST
An internal spanning tree (IST) is a spanning tree that runs in an MST region. It is also called MSTI 0, a special MSTI to which all VLANs are mapped by default.
In Figure 21, MSTI 0 is the IST in MST region 3.
CIST
The common and internal spanning tree (CIST) is a single spanning tree that connects all devices in a switched network. It consists of the ISTs in all MST regions and the CST.
In Figure 21, the ISTs (MSTI 0) in all MST regions plus the inter-region CST constitute the CIST of the entire network.
Regional root
The root bridge of the IST or an MSTI within an MST region is the regional root of the IST or MSTI. Based on the topology, different spanning trees in an MST region might have different regional roots.
In MST region 3 in Figure 22, the regional root of MSTI 1 is Device B, the regional root of MSTI 2 is Device C, and the regional root of MSTI 0 (also known as the IST) is Device A.
Common root bridge
The common root bridge is the root bridge of the CIST.
In Figure 21, the common root bridge is a device in MST region 1.
Port roles
A port can play different roles in different MSTIs. As shown in Figure 23, an MST region contains Device A, Device B, Device C, and Device D. Port A1 and port A2 of Device A connect to the common root bridge. Port B2 and Port B3 of Device B form a loop. Port C3 and Port C4 of Device C connect to other MST regions. Port D3 of Device D directly connects to a host.
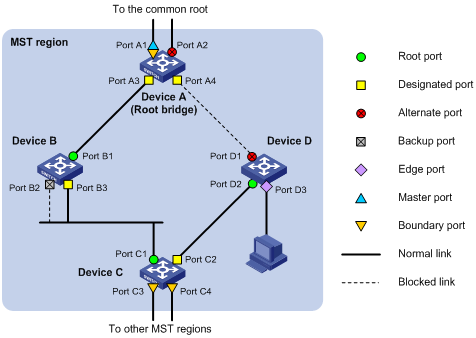
MSTP calculation involves the following port roles:
· Root port—Forwards data for a non-root bridge to the root bridge. The root bridge does not have any root port.
· Designated port—Forwards data to the downstream network segment or device.
· Alternate port—Serves as the backup port for a root port or master port. When the root port or master port is blocked, the alternate port takes over.
· Backup port—Serves as the backup port of a designated port. When the designated port is invalid, the backup port becomes the new designated port. A loop occurs when two ports of the same spanning tree device are connected, so the device blocks one of the ports. The blocked port acts as the backup.
· Edge port—Does not connect to any network device or network segment, but directly connects to a user host.
· Master port—Serves as a port on the shortest path from the local MST region to the common root bridge. The master port is not always located on the regional root. It is a root port on the IST or CIST and still a master port on the other MSTIs.
· Boundary port—Connects an MST region to another MST region or to an STP/RSTP-running device. In MSTP calculation, a boundary port's role on an MSTI is consistent with its role on the CIST. But that is not true with master ports. A master port on MSTIs is a root port on the CIST.
Port states
In MSTP, a port can be in one of the following states:
· Forwarding—The port receives and sends BPDUs, learns MAC addresses, and forwards user traffic.
· Learning—The port receives and sends BPDUs, learns MAC addresses, but does not forward user traffic. Learning is an intermediate port state.
· Discarding—The port receives and sends BPDUs, but does not learn MAC addresses or forward user traffic.
|
|
NOTE: When in different MSTIs, a port can be in different states. |
A port state is not exclusively associated with a port role. Table 8 lists the port states that each port role supports. (A check mark [√] indicates that the port supports this state, while a dash [—] indicates that the port does not support this state.)
Table 8 Port states that different port roles support
|
Port role (right) Port state (below) |
Root port/master port |
Designated port |
Alternate port |
Backup port |
|
Forwarding |
√ |
√ |
— |
— |
|
Learning |
√ |
√ |
— |
— |
|
Discarding |
√ |
√ |
√ |
√ |
How MSTP works
MSTP divides an entire Layer 2 network into multiple MST regions, which are connected by a calculated CST. Inside an MST region, multiple spanning trees, called MSTIs, are calculated. Among these MSTIs, MSTI 0 is the IST.
Like STP, MSTP uses configuration BPDUs to calculate spanning trees. An important difference is that an MSTP BPDU carries the MSTP configuration of the bridge from which the BPDU is sent.
CIST calculation
The calculation of a CIST tree is also the process of configuration BPDU comparison. During this process, the device with the highest priority is elected as the root bridge of the CIST. MSTP generates an IST within each MST region through calculation. At the same time, MSTP regards each MST region as a single device and generates a CST among these MST regions through calculation. The CST and ISTs constitute the CIST of the entire network.
MSTI calculation
Within an MST region, MSTP generates different MSTIs for different VLANs based on the VLAN-to-instance mappings. For each spanning tree, MSTP performs a separate calculation process similar to spanning tree calculation in STP. For more information, see "Calculation process of the STP algorithm."
In MSTP, a VLAN packet is forwarded along the following paths:
· Within an MST region, the packet is forwarded along the corresponding MSTI.
· Between two MST regions, the packet is forwarded along the CST.
MSTP implementation on devices
MSTP is compatible with STP and RSTP. Devices that are running MSTP and that are used for spanning tree calculation can identify STP and RSTP protocol packets.
In addition to basic MSTP features, the following features are provided for ease of management:
· Root bridge hold
· Root bridge backup
· Root guard
· BPDU guard
· TC-BPDU guard
· Port role restriction
· TC-BPDU transmission restriction
· Support for hot swapping of interface cards
Protocols and standards
MSTP is documented in the following protocols and standards:
· IEEE 802.1d, Media Access Control (MAC) Bridges
· IEEE 802.1w, Part 3: Media Access Control (MAC) Bridges—Amendment 2: Rapid Reconfiguration
· IEEE 802.1s, Virtual Bridged Local Area Networks—Amendment 3: Multiple Spanning Trees
· IEEE 802.1Q-REV/D1.3, Media Access Control (MAC) Bridges and Virtual Bridged Local Area Networks —Clause 13: Spanning tree Protocols
Spanning tree configuration task lists
Before configuring a spanning tree, you must determine the spanning tree protocol to be used (STP, RSTP, or MSTP) and plan the device roles (the root bridge or leaf node).
Configuration restrictions and guidelines
When you configure the spanning tree feature, follow these restrictions and guidelines:
· Configurations made in system view take effect globally. Configurations made in Ethernet interface view or WLAN mesh interface view take effect on the interface only. Configurations made in Layer 2 aggregate interface view take effect only on the aggregate interface. Configurations made on an aggregation member port can take effect only after the port is removed from the aggregation group.
· After you enable a spanning tree protocol on a Layer 2 aggregate interface, the system performs spanning tree calculation on the Layer 2 aggregate interface, but not on the aggregation member ports. The spanning tree protocol enable state and forwarding state of each selected member port is consistent with those of the corresponding Layer 2 aggregate interface.
· Though the member ports of an aggregation group do not participate in spanning tree calculation, the ports still reserve their spanning tree configurations for participating in spanning tree calculation after leaving the aggregation group.
STP configuration task list
RSTP configuration task list
MSTP configuration task list
Setting the spanning tree mode
The spanning tree modes include:
· STP mode—All ports of the device send STP BPDUs. Select this mode when the peer device of a port supports only STP.
· RSTP mode—All ports of the device send RSTP BPDUs. A port in this mode automatically transits to the STP mode when it receives STP BPDUs from the peer device, and a port in this mode does not transit to the MSTP mode when it receives MSTP BPDUs from the peer device.
· MSTP mode—All ports of the device send MSTP BPDUs. A port in this mode automatically transits to the STP mode when receiving STP BPDUs from the peer device, and a port in this mode does not transit to the RSTP mode when receiving RSTP BPDUs from the peer device.
MSTP mode is compatible with RSTP mode, and RSTP mode is compatible with STP mode.
To set the spanning tree mode:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Set the spanning tree mode. |
stp mode { mstp | rstp | stp } |
The default setting is the MSTP mode. |
|
|
NOTE: · In STP or RSTP mode, do not specify an MSTI. Otherwise, the spanning tree configuration does not take effect. · In MSTP mode, if you specify an MSTI, the spanning tree configuration takes effect on the specified MSTI. If you do not specify an MSTI, the spanning tree configuration takes effect on the CIST. |
Configuring an MST region
Two or more spanning tree devices belong to the same MST region only if they are configured to have the same format selector (0 by default, not configurable), MST region name, MST region revision level, and the same VLAN-to-instance mapping entries in the MST region, and they are connected through a physical link.
The configuration of MST region-related parameters (especially the VLAN-to-instance mapping table) might cause MSTP to begin a new spanning tree calculation. To reduce the possibility of topology instability, the MST region configuration takes effect only after you activate it by using the active region-configuration command, or enable a spanning tree protocol by using the stp global enable command if the spanning tree protocol is disabled.
To configure an MST region:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter MST region view. |
stp region-configuration |
N/A |
|
3. Configure the MST region name. |
region-name name |
The default setting is the MAC address. |
|
4. Configure the VLAN-to-instance mapping table. |
· instance instance-id vlan vlan-id-list · vlan-mapping modulo modulo |
Use one of the commands. By default, all VLANs in an MST region are mapped to the CIST (or MSTI 0). |
|
5. Configure the MSTP revision level of the MST region. |
revision-level level |
The default setting is 0. |
|
6. (Optional.) Display the MST region configurations that are not activated yet. |
check region-configuration |
N/A |
|
7. Manually activate MST region configuration. |
active region-configuration |
N/A |
|
8. (Optional.) Display the activated configuration information of the MST region. |
display stp region-configuration |
Available in any view. |
Configuring the root bridge or a secondary root bridge
You can have the spanning tree protocol determine the root bridge of a spanning tree through MSTP calculation, or you can specify the current device as the root bridge or as a secondary root bridge.
A device has independent roles in different spanning trees. It can act as the root bridge in one spanning tree and as a secondary root bridge in another. However, one device cannot be the root bridge and a secondary root bridge in the same spanning tree.
A spanning tree can have only one root bridge. If two or more devices are selected as the root bridge in a spanning tree at the same time, the device with the lowest MAC address is chosen.
When the root bridge of an instance fails or is shut down, the secondary root bridge (if you have specified one) becomes the root bridge if you have not specified a new root bridge. If you specify multiple secondary root bridges for an instance, the secondary root bridge with the lowest MAC address is given priority.
You can specify one root bridge for each spanning tree, regardless of the device priority settings. Once you specify a device as the root bridge or a secondary root bridge, you cannot change its priority.
You can configure the current device as the root bridge by setting the device priority to 0. For the device priority configuration, see "Configuring the device priority."
Configuring the current device as the root bridge of a specific spanning tree
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Configure the current device as the root bridge. |
·
In STP/RSTP mode: ·
In MSTP mode: |
By default, a device does not function as the root bridge. |
Configuring the current device as a secondary root bridge of a specific spanning tree
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Configure the current device as a secondary root bridge. |
·
In STP/RSTP mode: ·
In MSTP mode: |
By default, a device does not function as a secondary root bridge. |
Configuring the device priority
Device priority is a factor in calculating the spanning tree. The priority of a device determines whether the device can be elected as the root bridge of a spanning tree. A lower value indicates a higher priority. You can set the priority of a device to a low value to specify the device as the root bridge of the spanning tree. A spanning tree device can have different priorities in different MSTIs.
During root bridge selection, if all devices in a spanning tree have the same priority, the one with the lowest MAC address is selected as the root bridge of the spanning tree. You cannot change the priority of a device after it is configured as the root bridge or as a secondary root bridge.
To configure the priority of a device in a specified MSTI:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Configure the priority of the current device. |
·
In STP/RSTP mode: ·
In MSTP mode: |
The default setting is 32768. |
Configuring the maximum hops of an MST region
Restrict the region size by setting the maximum hops of an MST region. The hop limit configured on the regional root bridge is used as the hop limit for the MST region.
Configuration BPDUs sent by the regional root bridge always have a hop count set to the maximum value. When a device receives this configuration BPDU, it decrements the hop count by one, and uses the new hop count in the BPDUs that it propagates. When the hop count of a BPDU reaches zero, it is discarded by the device that received it. Devices beyond the reach of the maximum hop can no longer participate in spanning tree calculations, so the size of the MST region is limited.
Make this configuration only on the root bridge. All other devices in the MST region use the maximum hop value set for the root bridge.
To configure the maximum number of hops of an MST region:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Configure the maximum hops of the MST region. |
stp max-hops hops |
The default setting is 20. |
Configuring the network diameter of a switched network
Any two terminal devices in a switched network are connected through a specific path composed of a series of devices. The network diameter is the number of devices on the path composed of the most devices. The network diameter is a parameter that indicates the network size. A bigger network diameter indicates a larger network size.
Based on the network diameter you configured, the system automatically sets an optimal hello time, forward delay, and max age for the device. Each MST region is considered a device and the configured network diameter is effective only on the CIST (or the common root bridge) but not on other MSTIs.
To configure the network diameter of a switched network:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Configure the network diameter of the switched network. |
stp bridge-diameter diameter |
The default setting is 7. |
Setting spanning tree timers
The following timers are used for spanning tree calculation:
· Forward delay—Delay time for port state transition. To prevent temporary loops on a network, the spanning tree feature sets an intermediate port state (the learning state) before it transits from the discarding state to the forwarding state. The feature also requires that the port transit its state after a forward delay timer to make sure the state transition of the local port stays synchronized with the peer.
· Hello time—Interval at which the device sends configuration BPDUs to detect link failures. If the device receives no configuration BPDUs within the timeout time, it recalculates the spanning tree. (Timeout time = timeout factor × 3 × hello time.)
· Max age—In the CIST of an MSTP network, the device uses the max age timer to determine if a configuration BPDU received by a port has expired. If it has, a new spanning tree calculation process starts. The max age timer does not take effect on other MSTIs except the CIST.
To avoid frequent network changes, make sure the timer settings meet the following formulas:
· 2 × (forward delay – 1 second) ≥ max age
· Max age ≥ 2 × (hello time + 1 second)
As a best practice, specify the network diameter instead of manually setting the spanning tree timers. The spanning tree protocols will automatically calculate the timers based on the network diameter. If the network diameter uses the default value, the timers also use their default values.
Set the timers only on the root bridge. The timer settings on the root bridge apply to all devices on the entire switched network.
Configuration restrictions and guidelines
When you configure spanning tree timers, follow these restrictions and guidelines:
· The length of the forward delay timer is related to the network diameter of the switched network. The larger the network diameter is, the longer the forward delay time should be. As a best practice, use the automatically calculated value because inappropriate forward delay setting might cause temporary redundant paths or increase the network convergence time.
· An appropriate hello time setting enables the device to promptly detect link failures on the network without using excessive network resources. If the hello time is too long, the device mistakes packet loss for a link failure and triggers a new spanning tree calculation process. If the hello time is too short, the device frequently sends the same configuration BPDUs, which waste device and network resources. As a best practice, use the default setting.
· If the max age timer is too short, the device frequently begins spanning tree calculations and might mistake network congestion as a link failure. If the max age timer is too long, the device might fail to promptly detect link failures and quickly launch spanning tree calculations, reducing the auto-sensing capability of the network. As a best practice, use the default setting.
Configuration procedure
To configure the spanning tree timers:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Configure the forward delay timer. |
stp timer forward-delay time |
The default setting is 15 seconds. |
|
3. Configure the hello timer. |
stp timer hello time |
The default setting is 2 seconds. |
|
4. Configure the max age timer. |
stp timer max-age time |
The default setting is 20 seconds. |
Configuring the timeout factor
The timeout factor is a parameter used to decide the timeout time, in the following formula: Timeout time = timeout factor × 3 × hello time.
After the network topology is stabilized, each non-root-bridge device forwards configuration BPDUs to the downstream devices at the hello interval to detect link failures. If a device does not receive a BPDU from the upstream device within nine times the hello time, it assumes that the upstream device has failed and starts a new spanning tree calculation process.
An upstream device might be too busy to forward configuration BPDUs in time, for example, many Layer 2 interfaces are configured on the upstream device. As a result, the downstream device fails to receive a BPDU within the timeout period and then starts an undesired spanning tree calculation. The calculation might fail, and it also wastes network resources. To prevent undesired spanning tree calculation and save network resources on a stable network, you can set the timeout factor to 5, 6, or 7.
To configure the timeout factor:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Configure the timeout factor of the device. |
stp timer-factor factor |
The default setting is 3. |
Configuring the BPDU transmission rate
The maximum number of BPDUs a port can send within each hello time equals the BPDU transmission rate plus the hello timer value. Configure an appropriate BPDU transmission rate based on the physical status of the port and the network structure.
The higher the BPDU transmission rate, the more BPDUs are sent within each hello time, and the more system resources are used. By setting an appropriate BPDU transmission rate, you can limit the rate at which the port sends BPDUs and prevent spanning tree protocols from using excessive network resources when the network topology changes. As a best practice, use the default setting.
To configure the BPDU transmission rate:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Layer 2 Ethernet or aggregate interface view. |
interface interface-type interface-number |
N/A |
|
3. Configure the BPDU transmission rate of the ports. |
stp transmit-limit limit |
The default setting is 10. |
Configuring edge ports
If a port directly connects to a user terminal rather than another device or a shared LAN segment, this port is regarded as an edge port. When network topology change occurs, an edge port will not cause a temporary loop. Because a device does not determine whether a port is directly connected to a terminal, you must manually configure the port as an edge port. After that, the port can rapidly transit from the blocked state to the forwarding state.
Configuration restrictions and guidelines
When you configure edge ports, follow these restrictions and guidelines:
· If BPDU guard is disabled, a port set as an edge port becomes a non-edge port again if it receives a BPDU from another port. To restore the edge port, re-enable it.
· If a port directly connects to a user terminal, configure it as an edge port and enable BPDU guard for it. This enables the port to quickly transit to the forwarding state when ensuring network security.
· On a port, the loop guard feature and the edge port setting are mutually exclusive.
Configuration procedure
To specify a port as an edge port:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Layer 2 Ethernet or aggregate interface view. |
interface interface-type interface-number |
N/A |
|
3. Configure the current ports as edge ports. |
stp edged-port |
By default, all ports are non-edge ports. |
Configuring path costs of ports
Path cost is a parameter related to the rate of a port. On a spanning tree device, a port can have different path costs in different MSTIs. Setting appropriate path costs allows VLAN traffic flows to be forwarded along different physical links, achieving VLAN-based load balancing.
You can have the device automatically calculate the default path cost, or you can configure the path cost for ports.
Specifying a standard for the device to use when it calculates the default path cost
|
|
CAUTION: If you change the standard that the device uses to calculate the default path costs, you restore the path costs to the default. |
You can specify a standard for the device to use in automatic calculation for the default path cost. The device supports the following standards:
· dot1d-1998—The device calculates the default path cost for ports based on IEEE 802.1d-1998.
· dot1t—The device calculates the default path cost for ports based on IEEE 802.1t.
· legacy—The device calculates the default path cost for ports based on a private standard.
Table 9 shows the mapping between the link speed and the path cost.
Table 9 Mappings between the link speed and the path cost
|
Link speed |
Port type |
Path cost |
||
|
IEEE 802.1d-1998 |
IEEE 802.1t |
Private standard |
||
|
0 |
N/A |
65535 |
200000000 |
200000 |
|
10 Mbps |
Single port |
100 |
2000000 |
2000 |
|
Aggregate interface containing 2 Selected ports |
1000000 |
1800 |
||
|
Aggregate interface containing 3 Selected ports |
666666 |
1600 |
||
|
Aggregate interface containing 4 Selected ports |
500000 |
1400 |
||
|
100 Mbps |
Single port |
19 |
200000 |
200 |
|
Aggregate interface containing 2 Selected ports |
100000 |
180 |
||
|
Aggregate interface containing 3 Selected ports |
66666 |
160 |
||
|
Aggregate interface containing 4 Selected ports |
50000 |
140 |
||
|
1000 Mbps |
Single port |
4 |
20000 |
20 |
|
Aggregate interface containing 2 Selected ports |
10000 |
18 |
||
|
Aggregate interface containing 3 Selected ports |
6666 |
16 |
||
|
Aggregate interface containing 4 Selected ports |
5000 |
14 |
||
|
10 Gbps |
Single port |
2 |
2000 |
2 |
|
Aggregate interface containing 2 Selected ports |
1000 |
1 |
||
|
Aggregate interface containing 3 Selected ports |
666 |
1 |
||
|
Aggregate interface containing 4 Selected ports |
500 |
1 |
||
Configuration restrictions and guidelines
When you specify a standard for the device to use when it calculates the default path cost, follow these restrictions and guidelines:
· When it calculates the path cost for an aggregate interface, IEEE 802.1t takes into account the number of Selected ports in its aggregation group, but IEEE 802.1d-1998 does not. The calculation formula of IEEE 802.1t is: Path cost = 200,000,000/link speed (in 100 kbps), where link speed is the sum of the link speed values of the Selected ports in the aggregation group.
· IEEE 802.1d-1998 or the private standard always assigns the smallest possible value to a single port or an aggregate interface when the link speed of the port or interface exceeds 10 Gbps. The forwarding path selected based on this criterion might not be the best one. To solve this problem, use dot1t as the standard for default path cost calculation, or manually set the path cost for the port (see "Configuring path costs of ports").
Configuration procedure
To specify a standard for the device to use when it calculates the default path cost:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Specify a standard for the device to use when it calculates the default path costs of its ports. |
stp pathcost-standard { dot1d-1998 | dot1t | legacy } |
The default setting is legacy. |
Configuring path costs of ports
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Layer 2 Ethernet or aggregate interface view. |
interface interface-type interface-number |
N/A |
|
3. Configure the path cost of the ports. |
·
In STP/RSTP mode: ·
In MSTP mode: |
By default, the system automatically calculates the path cost of each port. |
|
|
NOTE: When the path cost of a port changes, the system re-calculates the role of the port and initiates a state transition. |
Configuration example
# In MSTP mode, configure the device to calculate the default path costs of its ports by using IEEE 802.1d-1998, and set the path cost of FortyGigE 1/0/3 to 200 on MSTI 2.
<Sysname> system-view
[Sysname] stp pathcost-standard dot1d-1998
Cost of every port will be reset and automatically re-calculated after you change the current pathcost standard. Continue?[Y/N]:y
Cost of every port has been re-calculated.
[Sysname] interface fortygige 1/0/3
[Sysname-FortyGigE1/0/3] stp instance 2 cost 200
Configuring the port priority
The priority of a port is a factor that determines whether the port can be elected as the root port of a device. If all other conditions are the same, the port with the highest priority is elected as the root port.
On a spanning tree device, a port can have different priorities and play different roles in different spanning trees, so that data of different VLANs can be propagated along different physical paths, implementing per-VLAN load balancing. You can set port priority values based on the actual networking requirements.
To configure the priority of a port:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Layer 2 Ethernet or aggregate interface view. |
interface interface-type interface-number |
N/A |
|
3. Configure the port priority. |
·
In STP/RSTP mode: ·
In MSTP mode: |
The default setting is 128 for all ports. |
|
|
NOTE: When the priority of a port changes, the system re-calculates the port role and initiates a state transition. |
Configuring the port link type
A point-to-point link directly connects two devices. If two root ports or designated ports are connected over a point-to-point link, they can rapidly transit to the forwarding state after a proposal-agreement handshake process.
Configuration restrictions and guidelines
When you configure the port link type, follow these restrictions and guidelines:
· You can configure the link type as point-to-point for a Layer 2 aggregate interface or a port that operates in full duplex mode. As a best practice, use the default setting for the device to automatically detect the port link type.
· The stp point-to-point force-false or stp point-to-point force-true command configured on a port in MSTP mode is effective on all MSTIs.
· If you configure a non-point-to-point link as a point-to-point link, the configuration might cause a temporary loop.
Configuration procedure
To configure the link type of a port:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Layer 2 Ethernet or aggregate interface view. |
interface interface-type interface-number |
N/A |
|
3. Configure the port link type. |
stp point-to-point { auto | force-false | force-true } |
By default, the link type is auto where the port automatically detects the link type. |
Configuring the mode a port uses to recognize and send MSTP packets
A port can receive and send MSTP packets in the following formats:
· dot1s—802.1s-compliant standard format
· legacy—Compatible format
When the number of existing MSTIs exceeds 48, the port can send only 802.1s MSTP packets.
By default, the packet format recognition mode of a port is auto. The port automatically distinguishes the two MSTP packet formats, and determines the format of packets that it will send based on the recognized format.
You can configure the MSTP packet format on a port. When operating in MSTP mode after the configuration, the port sends only MSTP packets of the format that you have configured to communicate with devices that send packets of the same format.
A port in auto mode sends 802.1s MSTP packets by default. When the port receives an MSTP packet of a legacy format, the port starts to send packets only of the legacy format. This prevents the port from frequently changing the format of sent packets. To configure the port to send 802.1s MSTP packets, shut down and then bring up the port.
To configure the MSTP packet format to be supported on a port:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Layer 2 Ethernet or aggregate interface view. |
interface interface-type interface-number |
N/A |
|
3. Configure the mode that the port uses to recognize/send MSTP packets. |
stp compliance { auto | dot1s | legacy } |
The default setting is auto. |
Enabling outputting port state transition information
In a large-scale spanning tree network, you can enable devices to output the port state transition information of all MSTIs or the specified MSTI in order to monitor the port states in real time.
To enable outputting port state transition information:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enable outputting port state transition information. |
·
In STP/RSTP mode: ·
In MSTP mode: |
By default, this feature is enabled. |
Enabling the spanning tree feature
You must enable the spanning tree feature for the device before any other spanning tree related configurations can take effect. Make sure the spanning tree feature is enabled globally and on the desired ports.
You can disable the spanning tree feature for certain ports with the undo stp enable command to exclude them from spanning tree calculation and save CPU resources of the device.
To enable the spanning tree feature:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enable the spanning tree feature globally. |
stp global enable |
By default, the spanning tree feature is disabled globally. |
|
3. Enter Layer 2 Ethernet or aggregate interface view. |
interface interface-type interface-number |
N/A |
|
4. (Optional.) Enable the spanning tree feature for the port. |
stp enable |
By default, the spanning tree feature is enabled on all ports. |
Performing mCheck
The mCheck feature enables user intervention in the port status transition process.
If a port on a device that is running MSTP or RSTP connects to an STP device, this port automatically transits to STP mode when the port receives STP BPDUs. However, if the peer STP device is shut down or removed and the local device cannot detect the change, the local device cannot automatically transit back to the original mode. To forcibly transit the port to operate in the original mode, you can perform an mCheck operation.
Suppose a scenario where Device A, Device B, and Device C are connected in sequence. Device A runs STP, Device B does not run any spanning tree protocol, and Device C runs RSTP or MSTP. In this case, when Device C receives an STP BPDU transparently transmitted by Device B, the receiving port transits to the STP mode. If you configure Device B to run RSTP or MSTP with Device C, you must perform mCheck operations on the ports interconnecting Device B and Device C.
The following methods for performing mCheck produce the same result.
Performing mCheck globally
|
Step |
Command |
|
1. Enter system view. |
system-view |
|
2. Perform mCheck. |
stp global mcheck |
Performing mCheck in interface view
|
Step |
Command |
|
1. Enter system view. |
system-view |
|
2. Enter Layer 2 Ethernet or aggregate interface view. |
interface interface-type interface-number |
|
3. Perform mCheck. |
stp mcheck |
|
|
NOTE: An mCheck operation takes effect on a device that operates in MSTP or RSTP mode. |
Configuring Digest Snooping
As defined in IEEE 802.1s, connected devices are in the same region only when their MST region-related configurations (region name, revision level, and VLAN-to-instance mappings) are identical. A spanning tree device identifies devices in the same MST region by determining the configuration ID in BPDU packets. The configuration ID includes the region name, revision level, and configuration digest, which is 16-byte long and is the result calculated through the HMAC-MD5 algorithm based on VLAN-to-instance mappings.
Because spanning tree implementations vary by vendor, the configuration digests calculated through private keys are different. The devices of different vendors in the same MST region cannot communicate with each other.
To enable communication between an H3C device and a third-party device, enable the Digest Snooping feature on the port that connects the H3C device to the third-party device in the same MST region.
Configuration restrictions and guidelines
When you configure Digest Snooping, follow these restrictions and guidelines:
· Before you enable Digest Snooping, make sure associated devices of different vendors are connected and run spanning tree protocols.
· With Digest Snooping enabled, in-the-same-region verification does not require comparison of configuration digest, so the VLAN-to-instance mappings must be the same on associated ports.
· With Digest Snooping enabled globally, modify the VLAN-to-instance mappings or execute the undo stp region-configuration command to restore the default MST region configuration with caution. If the local device has different VLAN-to-instance mappings than its neighboring devices, loops or traffic interruption occurs.
· To make Digest Snooping take effect, you must enable Digest Snooping both globally and on associated ports. As a best practice, enable Digest Snooping on all associated ports first and then enable it globally. This will make the configuration take effect on all configured ports and reduce impact on the network.
· To prevent loops, do not enable Digest Snooping on MST region edge ports.
· As a best practice, enable Digest Snooping first and then the spanning tree feature. To avoid traffic interruption, do not configure Digest Snooping when the network is already working well.
Configuration procedure
You can enable Digest Snooping only on the H3C device that is connected to a third-party device that uses its private key to calculate the configuration digest.
To configure Digest Snooping:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Layer 2 Ethernet or aggregate interface view. |
interface interface-type interface-number |
N/A |
|
3. Enable Digest Snooping on the interface. |
stp config-digest-snooping |
By default, Digest Snooping is disabled on ports. |
|
4. Return to system view. |
quit |
N/A |
|
5. Enable Digest Snooping globally. |
stp global config-digest-snooping |
By default, Digest Snooping is disabled globally. |
Digest Snooping configuration example
Network requirements
As shown in Figure 24, Device A and Device B connect to Device C, which is a third-party device. All these devices are in the same region.
Enable Digest Snooping on the ports of Device A and Device B that connect to Device C, so that the three devices can communicate with one another.
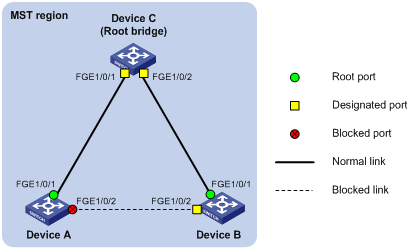
Configuration procedure
# Enable Digest Snooping on FortyGigE 1/0/1 of Device A and enable global Digest Snooping on Device A.
<DeviceA> system-view
[DeviceA] interface fortygige 1/0/1
[DeviceA-FortyGigE1/0/1] stp config-digest-snooping
[DeviceA-FortyGigE1/0/1] quit
[DeviceA] stp global config-digest-snooping
# Enable Digest Snooping on FortyGigE 1/0/1 of Device B and enable global Digest Snooping on Device B.
<DeviceB> system-view
[DeviceB] interface fortygige 1/0/1
[DeviceB-FortyGigE1/0/1] stp config-digest-snooping
[DeviceB-FortyGigE1/0/1] quit
[DeviceB] stp global config-digest-snooping
Configuring No Agreement Check
In RSTP and MSTP, the following types of messages are used for rapid state transition on designated ports:
· Proposal—Sent by designated ports to request rapid transition
· Agreement—Used to acknowledge rapid transition requests
Both RSTP and MSTP devices can perform rapid transition on a designated port only when the port receives an agreement packet from the downstream device. RSTP and MSTP devices have the following differences:
· For MSTP, the root port of the downstream device sends an agreement packet only after it receives an agreement packet from the upstream device.
· For RSTP, the downstream device sends an agreement packet regardless of whether an agreement packet from the upstream device is received.
Figure 25 Rapid state transition of an MSTP designated port
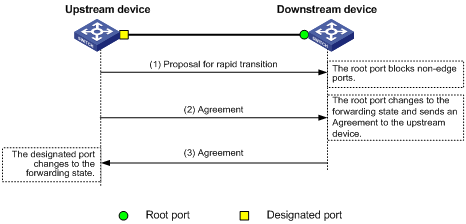
Figure 26 Rapid state transition of an RSTP designated port
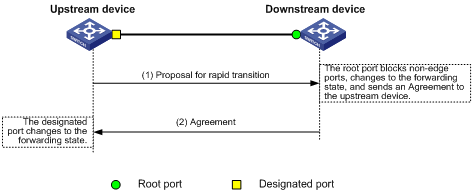
If the upstream device is a third-party device, the rapid state transition implementation might be limited. For example, when the upstream device uses a rapid transition mechanism similar to that of RSTP, and the downstream device adopts MSTP and does not operate in RSTP mode, the root port on the downstream device receives no agreement packet from the upstream device and sends no agreement packets to the upstream device. As a result, the designated port of the upstream device fails to transit rapidly, and can only change to the forwarding state after a period twice the Forward Delay.
You can enable the No Agreement Check feature on the downstream device's port to enable the designated port of the upstream device to transit its state rapidly.
Configuration prerequisites
Before you configure the No Agreement Check feature, complete the following tasks:
· Connect a device to a third-party upstream device that supports spanning tree protocols through a point-to-point link.
· Configure the same region name, revision level and VLAN-to-instance mappings on the two devices, assigning them to the same region.
Configuration procedure
Enable the No Agreement Check feature on the root port.
To configure No Agreement Check:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Layer 2 Ethernet or aggregate interface view. |
interface interface-type interface-number |
N/A |
|
3. Enable No Agreement Check. |
stp no-agreement-check |
By default, No Agreement Check is disabled. |
No Agreement Check configuration example
Network requirements
As shown in Figure 27:
· Device A connects to a third-party device that has a different spanning tree implementation. Both devices are in the same region.
· The third-party device (Device B) is the regional root bridge, and Device A is the downstream device.
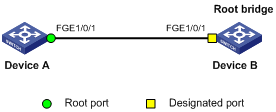
Configuration procedure
# Enable No Agreement Check on FortyGigE 1/0/1 of Device A.
<DeviceA> system-view
[DeviceA] interface fortygige 1/0/1
[DeviceA-FortyGigE1/0/1] stp no-agreement-check
Configuring protection features
A spanning tree device supports the following protection features:
· BPDU guard
· Root guard
· Loop guard
· Port role restriction
· TC-BPDU transmission restriction
· TC-BPDU guard
Enabling BPDU guard
For access layer devices, the access ports can directly connect to the user terminals (such as PCs) or file servers. The access ports are configured as edge ports to allow rapid transition. When these ports receive configuration BPDUs, the system automatically sets the ports as non-edge ports and starts a new spanning tree calculation process. This causes a change of network topology. Under normal conditions, these ports should not receive configuration BPDUs. However, if someone forges configuration BPDUs maliciously to attack the devices, the network will become unstable.
The spanning tree protocol provides the BPDU guard feature to protect the system against such attacks. With the BPDU guard feature enabled on the devices, when edge ports receive configuration BPDUs, the system closes these ports and notifies the NMS that these ports have been closed by the spanning tree protocol. The device reactivates the closed ports after a detection interval. For more information about this detection interval, see Fundamentals Configuration Guide.
BPDU guard does not take effect on loopback-testing-enabled ports. For more information about loopback testing, see "Configuring Ethernet interfaces."
Configure BPDU guard on a device with edge ports configured.
To enable BPDU guard:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enable the BPDU guard feature for the device. |
stp bpdu-protection |
By default, BPDU guard is disabled. |
Enabling root guard
The root bridge and secondary root bridge of a spanning tree should be located in the same MST region. Especially for the CIST, the root bridge and secondary root bridge are put in a high-bandwidth core region during network design. However, due to possible configuration errors or malicious attacks in the network, the legal root bridge might receive a configuration BPDU with a higher priority. Another device supersedes the current legal root bridge, causing an undesired change of the network topology. The traffic that should go over high-speed links is switched to low-speed links, resulting in network congestion.
To prevent this situation, MSTP provides the root guard feature. If the root guard feature is enabled on a port of a root bridge, this port plays the role of designated port on all MSTIs. After this port receives a configuration BPDU with a higher priority from an MSTI, it immediately sets that port to the listening state in the MSTI, without forwarding the packet. This is equivalent to disconnecting the link connected to this port in the MSTI. If the port receives no BPDUs with a higher priority within twice the forwarding delay, it reverts to its original state.
On a port, the loop guard feature and the root guard feature are mutually exclusive.
Configure root guard on a designated port.
To enable root guard:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Layer 2 Ethernet or aggregate interface view. |
interface interface-type interface-number |
N/A |
|
3. Enable the root guard feature. |
stp root-protection |
By default, root guard is disabled. |
Enabling loop guard
By continuing to receive BPDUs from the upstream device, a device can maintain the state of the root port and blocked ports. However, link congestion or unidirectional link failures might cause these ports to fail to receive BPDUs from the upstream devices. The device reselects the port roles: Those ports in forwarding state that failed to receive upstream BPDUs become designated ports, and the blocked ports transit to the forwarding state, resulting in loops in the switched network. The loop guard feature can suppress the occurrence of such loops.
The initial state of a loop guard-enabled port is discarding in every MSTI. When the port receives BPDUs, it transits its state. Otherwise, it stays in the discarding state to prevent temporary loops.
Do not enable loop guard on a port that connects user terminals. Otherwise, the port stays in the discarding state in all MSTIs because it cannot receive BPDUs.
On a port, the loop guard feature is mutually exclusive with the root guard feature or the edge port setting.
Configure loop guard on the root port and alternate ports of a device.
To enable loop guard:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Layer 2 Ethernet or aggregate interface view. |
interface interface-type interface-number |
N/A |
|
3. Enable the loop guard feature for the ports. |
stp loop-protection |
By default, loop guard is disabled. |
Configuring port role restriction
|
|
CAUTION: Use this feature with caution, because enabling port role restriction on a port might affect the connectivity of the spanning tree topology. |
The change to the bridge ID of a device in the user access network might cause a change to the spanning tree topology in the core network. To avoid this problem, you can enable port role restriction on a port. With this feature enabled, when the port receives a superior BPDU, it becomes an alternate port rather than a root port.
Make this configuration on the port that connects to the user access network.
To configure port role restriction:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Layer 2 Ethernet or aggregate interface view. |
interface interface-type interface-number |
N/A |
|
3. Enable port role restriction. |
stp role-restriction |
By default, port role restriction is disabled. |
Configuring TC-BPDU transmission restriction
|
|
CAUTION: Enabling TC-BPDU transmission restriction on a port might cause the previous forwarding address table to fail to be updated when the topology changes. |
The topology change to the user access network might cause the forwarding address changes to the core network. When the user access network topology is unstable, the user access network might affect the core network. To avoid this problem, you can enable TC-BPDU transmission restriction on a port. With this feature enabled, when the port receives a TC-BPDU, it does not forward the TC-BPDU to other ports.
Make this configuration on the port that connects to the user access network.
To configure TC-BPDU transmission restriction:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Layer 2 Ethernet or aggregate interface view. |
interface interface-type interface-number |
N/A |
|
3. Enable TC-BPDU transmission restriction. |
stp tc-restriction |
By default, TC-BPDU transmission restriction is disabled. |
Enabling TC-BPDU guard
When a device receives topology change (TC) BPDUs (the BPDUs that notify devices of topology changes), it flushes its forwarding address entries. If someone forges TC-BPDUs to attack the device, the device will receive a large number of TC-BPDUs within a short time and be busy with forwarding address entry flushing. This affects network stability.
With the TC-BPDU guard feature, you can set the maximum number of immediate forwarding address entry flushes that the device can perform within a specified period of time (10 seconds) after it receives the first TC-BPDU. For TC-BPDUs received in excess of the limit, the device performs a forwarding address entry flush when the time period expires. This prevents frequent flushing of forwarding address entries.
To enable TC-BPDU guard:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enable the TC-BPDU guard feature. |
stp tc-protection |
By default, TC-BPDU guard is enabled. As a best practice, do not disable this feature. |
|
3. (Optional.) Configure the maximum number of forwarding address entry flushes that the device can perform every 10 seconds. |
stp tc-protection threshold number |
The default setting is 6. |
Displaying and maintaining the spanning tree
Execute display commands in any view and reset command in user view.
|
Task |
Command |
|
Display information about ports blocked by spanning tree protection features. |
display stp abnormal-port |
|
Display BPDU statistics on ports. |
display stp bpdu-statistics [ interface interface-type interface-number [ instance instance-list ] ] |
|
Display information about ports shut down by spanning tree protection features. |
display stp down-port |
|
Display the historical information of port role calculation for the specified MSTI or all MSTIs (in standalone mode). |
display stp [ instance instance-list ] history [ slot slot-number ] |
|
Display the historical information of port role calculation for the specified MSTI or all MSTIs (in IRF mode). |
display stp [ instance instance-list ] history [ chassis chassis-number slot slot-number ] |
|
Display the statistics of TC/TCN BPDUs sent and received by all ports in the specified MSTI or all MSTIs (in standalone mode). |
display stp [ instance instance-list ] tc [ slot slot-number ] |
|
Display the statistics of TC/TCN BPDUs sent and received by all ports in the specified MSTI or all MSTIs (in IRF mode). |
display stp [ instance instance-list ] tc [ chassis chassis-number slot slot-number ] |
|
Display the spanning tree status and statistics (in standalone mode). |
display stp [ instance instance-list ] [ interface interface-list | slot slot-number ] [ brief ] |
|
Display the spanning tree status and statistics (in IRF mode). |
display stp [ instance instance-list ] [ interface interface-list | chassis chassis-number slot slot-number ] [ brief ] |
|
Display the MST region configuration information that has taken effect. |
display stp region-configuration |
|
Display the root bridge information of all MSTIs. |
display stp root |
|
Clear the spanning tree statistics. |
reset stp [ interface interface-list ] |
Spanning tree configuration example
Network requirements
As shown in Figure 28, all devices on the network are in the same MST region. Device A and Device B work at the distribution layer. Device C and Device D work at the access layer.
Configure MSTP so that packets of different VLANs are forwarded along different spanning trees: Packets of VLAN 10 are forwarded along MSTI 1, those of VLAN 30 are forwarded along MSTI 3, those of VLAN 40 are forwarded along MSTI 4, and those of VLAN 20 are forwarded along MSTI 0.
VLAN 10 and VLAN 30 are terminated on the distribution layer devices, and VLAN 40 is terminated on the access layer devices. The root bridges of MSTI 1 and MSTI 3 are Device A and Device B, respectively, and the root bridge of MSTI 4 is Device C.
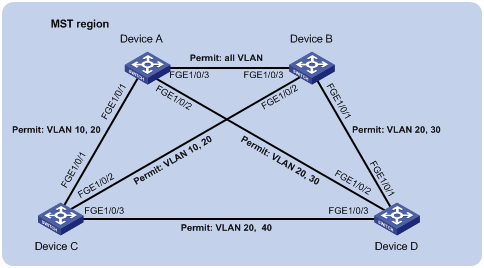
Configuration procedure
1. Configure VLANs and VLAN member ports: (Details not shown.)
? Create VLAN 10, VLAN 20, and VLAN 30 on both Device A and Device B.
? Create VLAN 10, VLAN 20, and VLAN 40 on Device C.
? Create VLAN 20, VLAN 30, and VLAN 40 on Device D.
? Configure the ports on these devices as trunk ports and assign them to related VLANs.
2. Configure Device A:
# Enter MST region view, and configure the MST region name as example.
<DeviceA> system-view
[DeviceA] stp region-configuration
[DeviceA-mst-region] region-name example
# Map VLAN 10, VLAN 30, and VLAN 40 to MSTI 1, MSTI 3, and MSTI 4, respectively.
[DeviceA-mst-region] instance 1 vlan 10
[DeviceA-mst-region] instance 3 vlan 30
[DeviceA-mst-region] instance 4 vlan 40
# Configure the revision level of the MST region as 0.
[DeviceA-mst-region] revision-level 0
# Activate MST region configuration.
[DeviceA-mst-region] active region-configuration
[DeviceA-mst-region] quit
# Specify the current device as the root bridge of MSTI 1.
[DeviceA] stp instance 1 root primary
# Enable the spanning tree feature globally.
[DeviceA] stp global enable
3. Configure Device B:
# Enter MST region view, and configure the MST region name as example.
<DeviceB> system-view
[DeviceB] stp region-configuration
[DeviceB-mst-region] region-name example
# Map VLAN 10, VLAN 30, and VLAN 40 to MSTI 1, MSTI 3, and MSTI 4, respectively.
[DeviceB-mst-region] instance 1 vlan 10
[DeviceB-mst-region] instance 3 vlan 30
[DeviceB-mst-region] instance 4 vlan 40
# Configure the revision level of the MST region as 0.
[DeviceB-mst-region] revision-level 0
# Activate MST region configuration.
[DeviceB-mst-region] active region-configuration
[DeviceB-mst-region] quit
# Specify the current device as the root bridge of MSTI 3.
[DeviceB] stp instance 3 root primary
# Enable the spanning tree feature globally.
[DeviceB] stp global enable
4. Configure Device C:
# Enter MST region view, and configure the MST region name as example.
<DeviceC> system-view
[DeviceC] stp region-configuration
[DeviceC-mst-region] region-name example
# Map VLAN 10, VLAN 30, and VLAN 40 to MSTI 1, MSTI 3, and MSTI 4, respectively.
[DeviceC-mst-region] instance 1 vlan 10
[DeviceC-mst-region] instance 3 vlan 30
[DeviceC-mst-region] instance 4 vlan 40
# Configure the revision level of the MST region as 0.
[DeviceC-mst-region] revision-level 0
# Activate MST region configuration.
[DeviceC-mst-region] active region-configuration
[DeviceC-mst-region] quit
# Specify the current device as the root bridge of MSTI 4.
[DeviceC] stp instance 4 root primary
# Enable the spanning tree feature globally.
[DeviceC] stp global enable
5. Configure Device D:
# Enter MST region view, and configure the MST region name as example.
<DeviceD> system-view
[DeviceD] stp region-configuration
[DeviceD-mst-region] region-name example
# Map VLAN 10, VLAN 30, and VLAN 40 to MSTI 1, MSTI 3, and MSTI 4, respectively.
[DeviceD-mst-region] instance 1 vlan 10
[DeviceD-mst-region] instance 3 vlan 30
[DeviceD-mst-region] instance 4 vlan 40
# Configure the revision level of the MST region as 0.
[DeviceD-mst-region] revision-level 0
# Activate MST region configuration.
[DeviceD-mst-region] active region-configuration
[DeviceD-mst-region] quit
# Enable the spanning tree feature globally.
[DeviceD] stp global enable
Verifying the configuration
In this example, suppose that Device B has the lowest root bridge ID. As a result, Device B is elected as the root bridge in MSTI 0.
You can use the display stp brief command to display brief spanning tree information on each device after the network is stable.
# Display brief spanning tree information on Device A.
[DeviceA] display stp brief
[DeviceA] display stp brief
MSTID Port Role STP State Protection
0 FortyGigE1/0/1 ALTE DISCARDING NONE
0 FortyGigE1/0/2 DESI FORWARDING NONE
0 FortyGigE1/0/3 ROOT FORWARDING NONE
1 FortyGigE1/0/1 DESI FORWARDING NONE
1 FortyGigE1/0/3 DESI FORWARDING NONE
3 FortyGigE1/0/2 DESI FORWARDING NONE
3 FortyGigE1/0/3 ROOT FORWARDING NONE
# Display brief spanning tree information on Device B.
[DeviceB] display stp brief
MSTID Port Role STP State Protection
0 FortyGigE1/0/1 DESI FORWARDING NONE
0 FortyGigE1/0/2 DESI FORWARDING NONE
0 FortyGigE1/0/3 DESI FORWARDING NONE
1 FortyGigE1/0/2 DESI FORWARDING NONE
1 FortyGigE1/0/3 ROOT FORWARDING NONE
3 FortyGigE1/0/1 DESI FORWARDING NONE
3 FortyGigE1/0/3 DESI FORWARDING NONE
# Display brief spanning tree information on Device C.
[DeviceC] display stp brief
MSTID Port Role STP State Protection
0 FortyGigE1/0/1 DESI FORWARDING NONE
0 FortyGigE1/0/2 ROOT FORWARDING NONE
0 FortyGigE1/0/3 DESI FORWARDING NONE
1 FortyGigE1/0/1 ROOT FORWARDING NONE
1 FortyGigE1/0/2 ALTE DISCARDING NONE
4 FortyGigE1/0/3 DESI FORWARDING NONE
# Display brief spanning tree information on Device D.
[DeviceD] display stp brief
MSTID Port Role STP State Protection
0 FortyGigE1/0/1 ROOT FORWARDING NONE
0 FortyGigE1/0/2 ALTE DISCARDING NONE
0 FortyGigE1/0/3 ALTE DISCARDING NONE
3 FortyGigE1/0/1 ROOT FORWARDING NONE
3 FortyGigE1/0/2 ALTE DISCARDING NONE
4 FortyGigE1/0/3 ROOT FORWARDING NONE
Based on the output, you can draw each MSTI mapped to each VLAN, as shown in Figure 29.
Figure 29 MSTIs mapped to different VLANs
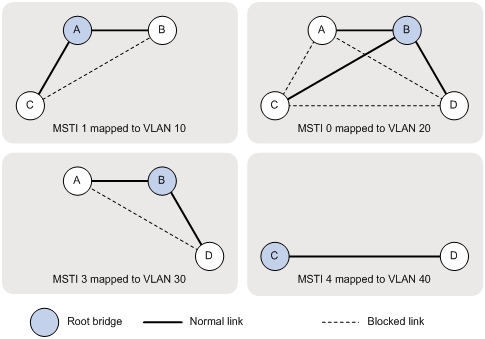
Configuring loop detection
Overview
Incorrect network connections or configurations can create Layer 2 loops, which results in repeated transmission of broadcasts, multicasts, or unknown unicasts, waste network resources, and sometimes even paralyze networks. The loop detection mechanism immediately generates a log when a loop occurs so that you are promptly notified to adjust network connections and configurations. You can even configure loop detection to shut down the looped port. Logs are maintained in the information center. For more information, see Network Management and Monitoring Configuration Guide.
Loop detection mechanism
The device detects loops by sending detection frames and then checking whether these frames return to any port on the device. If they do, the device considers that the port is on a looped link.
Figure 30 Ethernet frame header for loop detection
The Ethernet frame header for loop detection contains the following fields:
· DMAC—Destination MAC address of the frame, which is the multicast MAC address 010F-E200-0007. When a loop detection-enabled device receives a frame with this destination MAC address, it sends the frame to the CPU and floods the frame in the VLAN from which the frame was originally received.
· SMAC—Source MAC address of the frame, which is the bridge MAC address of the sending device.
· TPID—Type of the VLAN tag, with the value of 0x8100.
· TCI—Information of the VLAN tag, including the priority and VLAN ID.
· Type—Protocol type, with the value of 0x8918.
Figure 31 Inner frame header for loop detection

The inner frame header for loop detection contains the following fields:
· Code—Protocol sub-type, which is 0x0001, indicating the loop detection protocol.
· Version—Protocol version, which is always 0x0000.
· Length—Length of the frame. The value includes the inner header, but excludes the Ethernet header.
· Reserved—This field is reserved.
Frames for loop detection are encapsulated as TLV triplets.
Table 10 TLVs supported by loop detection
|
TLV |
Description |
Remarks |
|
End of PDU |
End of a PDU. |
Optional. |
|
Device ID |
Bridge MAC address of the sending device. |
Required. |
|
Port ID |
ID of the PDU sending port. |
Optional. |
|
Port Name |
Name of the PDU sending port. |
Optional. |
|
System Name |
Device name. |
Optional. |
|
Chassis ID |
Chassis ID of the sending port. |
Optional. |
|
Slot ID |
Slot ID of the sending port. |
Optional. |
|
Sub Slot ID |
Sub-slot ID of the sending port. |
Optional. |
Loop detection uses the following important concepts.
Loop detection interval
Loop protection actions
When the device detects a loop on a port, it generates a log but performs no action on the port by default. You can configure the device to take one of the following actions:
· Block—Disables the port from learning MAC addresses and blocks inbound traffic to the port.
· No-learning—Disables the port from learning MAC addresses.
· Shutdown—Shuts down the port to disable it from receiving and sending any frames.
Port status auto recovery
When the device configured with the block or no-learning loop action detects a loop on a port, it performs the action and waits three loop detection intervals. If the device does not receive a loop detection frame within three loop detection intervals, it performs the following tasks:
· Automatically sets the port to the forwarding state.
· Notifies the user of the event.
When the device configured with the shutdown action detects a loop on a port, the following events occur:
1. The device automatically shuts down the port.
2. The device automatically sets the port to the forwarding state after the detection timer configured by using the shutdown-interval command expires. For more information about the shutdown-interval command, see Fundamentals Command Reference.
3. The device shuts down the port again if a loop is still detected on the port when the detection timer expires.
This process is repeated until the loop is removed.
|
|
NOTE: Incorrect recovery can occur when loop detection frames are discarded to reduce the load. To avoid this, use the shutdown action, or manually remove the loop. |
Loop detection configuration task list
|
Tasks at a glance |
|
(Required.) Enabling loop detection |
|
(Optional.) Setting the loop protection action |
|
(Optional.) Setting the loop detection interval |
Enabling loop detection
You can enable loop detection globally or on specific ports. The global configuration applies to all ports in the specified VLAN. The per-port configuration applies to the individual port only when the port belongs to the specified VLAN. Per-port configurations take precedence over global configurations.
Enabling loop detection globally
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Globally enable loop detection. |
loopback-detection global enable vlan { vlan-list | all } |
Disabled by default. |
Enabling loop detection on a port
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Layer 2 Ethernet interface view or Layer 2 aggregate interface view. |
interface interface-type interface-number |
N/A |
|
3. Enable loop detection on the port. |
loopback-detection enable vlan { vlan-list | all } |
Disabled by default. |
Setting the loop protection action
You can configure the loop protection action globally or on specific ports. The global setting applies to all ports. The per-port setting applies to the individual ports. The per-port setting takes precedence over the global setting.
Setting the global loop protection action
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Configure the global loop protection action. |
loopback-detection global action shutdown |
By default, the device generates a log but performs no action on the port on which a loop is detected. |
Setting the loop protection action on a Layer 2 Ethernet interface
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Layer 2 Ethernet interface view. |
interface interface-type interface-number |
N/A |
|
3. Configure the loop protection action on the interface. |
loopback-detection action { block | no-learning | shutdown } |
By default, the device generates a log but performs no action on the port on which a loop is detected. |
Setting the loop protection action on a Layer 2 aggregate interface
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Layer 2 aggregate interface view. |
interface bridge-aggregation interface-number |
N/A |
|
3. Configure the loop protection action on the interface. |
loopback-detection action shutdown |
By default, the device generates a log but performs no action on the port on which a loop is detected. |
Setting the loop detection interval
With loop detection enabled, the device sends loop detection frames at a specified interval. A shorter interval offers more sensitive detection but consumes more resources. Consider the system performance and loop detection speed when you set the loop detection interval.
To set the loop detection interval:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Set the loop detection interval. |
loopback-detection interval-time interval |
The default setting is 30 seconds. |
Displaying and maintaining loop detection
Execute display commands in any view.
|
Task |
Command |
|
Display the loop detection configuration and status. |
display loopback-detection |
Loop detection configuration example
Network requirements
As shown in Figure 32, configure loop detection on Device A, so that Device A generates a log as a notification and automatically shuts down the port on which a loop is detected.
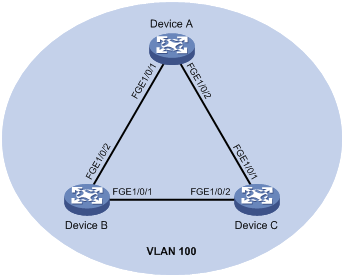
Configuration procedure
1. Configure Device A:
# Create VLAN 100, and globally enable loop detection for the VLAN.
<DeviceA> system-view
[DeviceA] vlan 100
[DeviceA-vlan100] quit
[DeviceA] loopback-detection global enable vlan 100
# Configure FortyGigE 1/0/1 and FortyGigE 1/0/2 as trunk ports, and assign them to VLAN 100.
[DeviceA] interface fortygige 1/0/1
[DeviceA-FortyGigE1/0/1] port link-type trunk
[DeviceA-FortyGigE1/0/1] port trunk permit vlan 100
[DeviceA-FortyGigE1/0/1] quit
[DeviceA] interface fortygige 1/0/2
[DeviceA-FortyGigE1/0/2] port link-type trunk
[DeviceA-FortyGigE1/0/2] port trunk permit vlan 100
[DeviceA-FortyGigE1/0/2] quit
# Configure the global loop protection action as shutdown.
[DeviceA] loopback-detection global action shutdown
# Set the loop detection interval to 35 seconds.
[DeviceA] loopback-detection interval-time 35
2. Configure Device B:
# Create VLAN 100.
<DeviceB> system-view
[DeviceB] vlan 100
[DeviceB–vlan100] quit
# Configure FortyGigE 1/0/1 and FortyGigE 1/0/2 as trunk ports, and assign them to VLAN 100.
[DeviceB] interface fortygige 1/0/1
[DeviceB-FortyGigE1/0/1] port link-type trunk
[DeviceB-FortyGigE1/0/1] port trunk permit vlan 100
[DeviceB-FortyGigE1/0/1] quit
[DeviceB] interface fortygige 1/0/2
[DeviceB-FortyGigE1/0/2] port link-type trunk
[DeviceB-FortyGigE1/0/2] port trunk permit vlan 100
[DeviceB-FortyGigE1/0/2] quit
3. Configure Device C:
# Create VLAN 100.
<DeviceC> system-view
[DeviceC] vlan 100
[DeviceC–vlan100] quit
# Configure FortyGigE 1/0/1 and FortyGigE 1/0/2 as trunk ports, and assign them to VLAN 100.
[DeviceC] interface fortygige 1/0/1
[DeviceC-FortyGigE1/0/1] port link-type trunk
[DeviceC-FortyGigE1/0/1] port trunk permit vlan 100
[DeviceC-FortyGigE1/0/1] quit
[DeviceC] interface fortygige 1/0/2
[DeviceC-FortyGigE1/0/2] port link-type trunk
[DeviceC-FortyGigE1/0/2] port trunk permit vlan 100
[DeviceC-FortyGigE1/0/2] quit
Verifying the configuration
After the configurations are complete, Device A detects loops on ports FortyGigE 1/0/1 and FortyGigE 1/0/2 within a loop detection interval. Consequently, Device A automatically shuts down the ports and generates the following log messages:
[DeviceA]
%Feb 24 15:04:29:663 2011 DeviceA LPDT/4/LOOPED:Slot=1;
Loopback exists on FortyGigE 1/0/1.
%Feb 24 15:04:29:667 2011 DeviceA LPDT/4/LOOPED:Slot=1;
Loopback exists on FortyGigE 1/0/2.
%Feb 24 15:04:44:243 2011 DeviceA LPDT/4/RECOVERED:Slot=1;
Loopback on FortyGigE 1/0/1 recovered.
%Feb 24 15:04:44:248 2011 DeviceA LPDT/4/RECOVERED:Slot=1;
Loopback on FortyGigE 1/0/2 recovered.
Use the display loopback-detection command to display the loop detection configuration and status on Device A.
# Display the loop detection configuration and status on Device A.
[DeviceA] display loopback-detection
Loop detection is enabled.
Loop detection interval is 35 second(s).
No loopback is detected.
The output shows that the device has removed the loops from FortyGigE 1/0/1 and FortyGigE 1/0/2 according to the shutdown action. Use the display interface command to display the status of FortyGigE 1/0/1 and FortyGigE 1/0/2 on Device A.
# Display the status of FortyGigE 1/0/1 on Device A.
[DeviceA] display interface fortygige 1/0/1
FortyGigE 1/0/1 current state: DOWN (Loop detection down)
...
# Display the status of FortyGigE 1/0/2 on Device A.
[DeviceA] display interface fortygige 1/0/2
FortyGigE 1/0/2 current state: DOWN (Loop detection down)
...
The output shows that FortyGigE 1/0/1 and FortyGigE 1/0/2 are already shut down by the loop detection module.
Configuring VLANs
Overview
Ethernet is a family of shared-media LAN technologies based on the CSMA/CD mechanism. An Ethernet LAN is both a collision domain and a broadcast domain. Because the medium is shared, collisions and broadcasts are common in an Ethernet LAN. Typically, bridges and Layer 2 switches can reduce collisions in an Ethernet LAN. To confine broadcasts, a Layer 2 switch must use the Virtual Local Area Network (VLAN) technology.
VLANs enable a Layer 2 switch to break a LAN down into smaller broadcast domains, as shown in Figure 33.
A VLAN is logically divided on an organizational basis rather than on a physical basis. For example, you can assign all workstations and servers used by a particular workgroup to the same VLAN, regardless of their physical locations. Hosts in the same VLAN can directly communicate with one another. You need a router or a Layer 3 switch for hosts in different VLANs to communicate with one another.
All these VLAN features reduce bandwidth waste, improve LAN security, and enable flexible virtual group creation.
VLAN frame encapsulation
To identify Ethernet frames from different VLANs, IEEE 802.1Q inserts a four-byte VLAN tag between the destination and source MAC address (DA&SA) field and the upper layer protocol type (Type) field, as shown in Figure 34.
Figure 34 VLAN tag placement and format

A VLAN tag includes the following fields:
· TPID—16-bit tag protocol identifier that indicates whether a frame is VLAN-tagged. By default, the TPID value is 0x8100, indicating that the frame is VLAN-tagged. However, device vendors can set TPID to different values. For compatibility with neighbor devices, configure the TPID value on the device to be the same as the neighbor device.
· Priority—3-bit long, identifies the 802.1p priority of the frame. For more information, see ACL and QoS Configuration Guide.
· CFI—1-bit long canonical format indicator that indicates whether the MAC addresses are encapsulated in the standard format when packets are transmitted across different media. The possible values are:
? 0 (default)—The MAC addresses are encapsulated in the standard format.
? 1—The MAC addresses are encapsulated in a non-standard format.
This field is always set to 0 for Ethernet.
· VLAN ID—12-bit long, identifies the VLAN that the frame belongs to. The VLAN ID range is 0 to 4095. VLAN IDs 0 and 4095 are reserved, and VLAN IDs 1 to 4094 are user configurable.
The way a network device handles an incoming frame depends on whether the frame is VLAN-tagged and the value of the VLAN tag (if any). For more information, see "Introduction to port-based VLAN."
Ethernet supports encapsulation formats Ethernet II, 802.3/802.2 LLC, 802.3/802.2 SNAP, and 802.3 raw. The Ethernet II encapsulation format is used here. For how the VLAN tag fields are added to frames encapsulated in the other formats for VLAN identification, see related protocols and standards.
For a frame with multiple VLAN tags, the device handles it according to its outer-most VLAN tag and transmits its inner VLAN tags as the payload.
Protocols and standards
IEEE 802.1Q, IEEE Standard for Local and Metropolitan Area Networks: Virtual Bridged Local Area Networks
Configuring basic VLAN settings
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. (Optional.) Create a VLAN and enter its view, or create a list of VLANs. |
vlan { vlan-id1 [ to vlan-id2 ] | all } |
By default, only the system default VLAN (VLAN 1) exists. |
|
3. Enter VLAN view. |
vlan vlan-id |
To configure a specific VLAN after you create a list of VLANs, you must perform this step. |
|
4. Configure a name for the VLAN. |
name text |
By default, the name of a VLAN is VLAN vlan-id. The vlan-id argument specifies the VLAN ID in a four-digit format. If the VLAN ID has fewer than four digits, leading zeros are added. For example, the name of VLAN 100 is VLAN 0100. |
|
5. Configure the description of the VLAN. |
description text |
By default, the description of a VLAN is VLAN vlan-id. The vlan-id argument specifies the VLAN ID in a four-digit format. If the VLAN ID has fewer than four digits, leading zeros are added. For example, the default description of VLAN 100 is VLAN 0100. |
|
|
NOTE: · As the system default VLAN, VLAN 1 cannot be created or deleted. · Before you delete a dynamic VLAN, a VLAN configured with a QoS policy, or a VLAN locked by an application, you must first remove the configuration from the VLAN. |
Configuring basic settings of a VLAN interface
For hosts of different VLANs to communicate at Layer 3, you can use VLAN interfaces. VLAN interfaces are virtual interfaces used for Layer 3 communication between different VLANs. They do not exist as physical entities on devices. For each VLAN, you can create one VLAN interface. You can assign an IP address to it. The VLAN interface acts as the gateway of the VLAN to forward packets destined for another IP subnet.
Before you create a VLAN interface for a VLAN, create the VLAN first.
To configure basic settings of a VLAN interface:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Create a VLAN interface and enter VLAN interface view. |
interface vlan-interface vlan-interface-id |
If the VLAN interface already exists, you enter its view directly. By default, no VLAN interface is created. |
|
3. Assign an IP address to the VLAN interface. |
ip address ip-address { mask | mask-length } [ sub ] |
By default, no IP address is assigned to any VLAN interface. |
|
4. Configure the description of the VLAN interface. |
description text |
The default setting is the VLAN interface name. For example, Vlan-interface1 Interface. |
|
5. (Optional.) Specify a line processing unit (LPU) for forwarding the traffic on the current VLAN interface (in standalone mode). |
·
In standalone mode: ·
In IRF mode: |
By default, no LPU is specified. |
|
6. Set the MTU for the VLAN interface. |
By default, the MTU for a VLAN interface is 1500 bytes. |
|
|
7. Configure the expected bandwidth of the interface. |
bandwidth bandwidth-value |
By default, the expected bandwidth (in kbps) is the interface baud rate divided by 1000. |
|
8. (Optional.) Restore the default settings for the VLAN interface. |
default |
N/A |
|
9. (Optional.) Bring up the VLAN interface. |
undo shutdown |
By default, a VLAN interface is not manually shut down. The VLAN interface is up if one or more ports in the VLAN is up, and goes down if all ports in the VLAN go down. |
Reserving VLAN interface resources
The system provides 4094 Layer 3 interface hardware resources for Layer 3 interfaces and subinterfaces. By default, these Layer 3 interface resources are assigned to 4094 VLAN interfaces.
Reserve VLAN interface resources before you perform the following tasks:
· Create Layer 3 interfaces and subinterfaces, except VLAN interfaces.
· Configure features that require Layer 3 interface hardware resources.
A reserved VLAN interface resource can be of the local or global type, depending on for which feature the VLAN interface resource is reserved. For example, if the VLAN interface resource is reserved for a Layer 3 interface or subinterface, it is of the local type. If the resource is reserved for a VSI interface, it is of the global type.
Reserving local-type VLAN interface resources
Reserve local-type VLAN interface resources before you perform the following operations:
· Switch Layer 2 Ethernet interfaces to Layer 3 Ethernet interfaces.
· Create Layer 3 Ethernet subinterfaces, Layer 3 aggregate interfaces, and Layer 3 aggregate subinterfaces.
· Create VPN instances on a PE device on the MPLS L3VPN network. For more information about MPLS L3VPN, see MPLS Configuration Guide.
Each of the Layer 3 interfaces and subinterfaces uses one local-type VLAN interface resource. When you reserve local-type VLAN interface resources for interfaces that have subinterfaces, take the number of the subinterfaces into account. For example:
· Reserve two local-type VLAN interface resources when you create a Layer 3 Ethernet subinterface. The main interface and subinterface each use one local-type VLAN interface resource.
· Reserve seven local-type VLAN interface resources when you create four Layer 3 aggregate subinterfaces on an aggregate interface whose corresponding aggregation group has two member ports. The aggregate interface uses one local-type VLAN interface. Each of the member ports and aggregate subinterfaces uses one local-type VLAN interface resource.
Each MPLS L3VPN instance uses one local-type VLAN interface resource. Reserve a local-type VLAN interface resource before you create an MPLS L3VPN instance.
Reserving global-type VLAN interface resources
If you set the VXLAN forwarding mode to Layer 3, you must reserve one global-type VLAN interface resource for each VSI interface before it is created. For more information about VSI interfaces, see VXLAN Configuration Guide.
Configuration restrictions and guidelines
When you reserve VLAN interface resources, follow these restrictions and guidelines:
· As a best practice to simplify management and configuration, reserve VLAN interface resources as follows:
? Bulk reserve resources of VLAN interfaces that are numbered in consecutive order.
? Preferentially reserve resources of VLAN interfaces whose VLAN IDs are in the range of 3000 to 3500.
· Select the VLAN interfaces of unused VLANs rather than used VLANs for resource reservation. As a best practice, do not create or use a VLAN if the VLAN interface resource of the VLAN is reserved.
· The VLAN interface resource reservation of a VLAN conflicts with the VLAN interface creation of this VLAN.
· Before creating a Layer 3 Ethernet subinterface or aggregate subinterface, do not reserve a resource for the VLAN interface whose interface number matches the subinterface number. After you reserve a VLAN interface resource, do not create a Layer 3 Ethernet subinterface or aggregate subinterface whose subinterface number is the VLAN interface number. A Layer 3 Ethernet subinterface or aggregate subinterface uses the VLAN interface resource in processing tagged packets whose VLAN ID matches the subinterface number.
· A reserved VLAN interface resource can be of the local or global type. To change the type of a reserved VLAN interface resource, first remove the reservation.
· You cannot remove the reservation of a VLAN interface resource if this resource has been used.
· This feature is available in Feature 1108 and later versions. After the software upgrades to support this feature, first reserve VLAN interface resources for existing configurations that require the reservation.
Configuration procedure
To reserve VLAN interface resources:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Reserve VLAN interface resources. |
reserve-vlan-interface { vlan-interface-id1 [ to vlan-interface-id2 ] [ global ] } |
By default, no VLAN interface resources are reserved. To reserve global-type VLAN interface resources, specify the global keyword. To reserve local-type VLAN interface resources, do not specify the global keyword. |
|
3. (Optional.) Display VLANs whose VLAN interface resources have been reserved. |
display reserve-vlan-interface |
N/A |
Configuring port-based VLANs
Introduction to port-based VLAN
Port-based VLANs group VLAN members by port. A port forwards packets from a VLAN only after it is assigned to the VLAN.
Port link type
You can configure the link type of a port as access, trunk, or hybrid. The link types use the following VLAN tag handling methods:
· Access—An access port can forward packets from only one specific VLAN and send these packets untagged. An access port can connect a terminal device that does not support VLAN packets or is used in scenarios that do not distinguish VLANs.
· Trunk—A trunk port can forward packets from multiple VLANs. Except packets from the port VLAN ID (PVID), packets sent out of a trunk port are VLAN-tagged. Ports connecting network devices are typically configured as trunk ports.
· Hybrid—A hybrid port can forward packets from multiple VLANs. A hybrid port allows traffic from some VLANs to pass through untagged and traffic from other VLANs to pass through tagged. A hybrid port can connect a network device or terminal device.
PVID
The PVID identifies the port VLAN of a port.
When you configure the PVID on a port, follow these restrictions and guidelines:
· An access port can join only one VLAN. The VLAN to which the access port belongs is the PVID of the port.
· A trunk or hybrid port supports multiple VLANs and the PVID configuration.
· When you use the undo vlan command to delete the PVID of a port, either of the following events occurs depending on the port link type:
? For an access port, the PVID of the port changes to VLAN 1.
? For a hybrid or trunk port, the PVID setting of the port does not change.
You can use a nonexistent VLAN as the PVID for a hybrid or trunk port, but not for an access port.
· To correctly transmit packets, configure the same PVID for local and remote ports.
· To prevent a port from dropping untagged packets or PVID-tagged packets, assign the port to its PVID.
How ports of different link types handle frames
|
Actions |
Access |
Trunk |
Hybrid |
|
|
In the inbound direction for an untagged frame |
Tags the frame with the PVID tag. |
· If the PVID is permitted on the port, tags the frame with the PVID tag. · If not, drops the frame. |
||
|
In the inbound direction for a tagged frame |
· Receives the frame if its VLAN ID is the same as the PVID. · Drops the frame if its VLAN ID is different from the PVID. |
· Receives the frame if its VLAN is permitted on the port. · Drops the frame if its VLAN is not permitted on the port. |
||
|
In the outbound direction |
Removes the VLAN tag and sends the frame. |
· Removes the tag and sends the frame if the frame carries the PVID tag and the port belongs to the PVID. · Sends the frame without removing the tag if its VLAN is carried on the port but is different from the PVID. |
Sends the frame if its VLAN is permitted on the port. The tagging status of the frame depends on the port hybrid vlan command configuration. |
|
Assigning an access port to a VLAN
You can assign an access port to a VLAN in VLAN view or interface view.
Make sure the VLAN has been created.
Assigning one or multiple access ports to a VLAN in VLAN view
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter VLAN view. |
vlan vlan-id |
N/A |
|
3. Assign one or a group of access ports to the VLAN. |
port interface-list |
By default, all ports belong to VLAN 1. |
Assigning an access port to a VLAN in interface view
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter interface view. |
·
Enter Layer 2 Ethernet interface view: ·
Enter Layer 2 aggregate interface view: |
· The configuration made in Layer 2 Ethernet interface view applies only to the port. · The configuration made in Layer 2 aggregate interface view applies to the aggregate interface and its aggregation member ports. If the system fails to apply the configuration to an aggregation member port, it skips the port and moves to the next member port. If the system fails to apply the configuration to the aggregate interface, it stops applying the configuration to aggregation member ports. |
|
3. Configure the link type of the port as access. |
port link-type access |
By default, all ports are access ports. |
|
4. (Optional.) Assign the access port to a VLAN. |
port access vlan vlan-id |
By default, all access ports belong to VLAN 1. |
Assigning a trunk port to a VLAN
A trunk port supports multiple VLANs. You can assign it to a VLAN in interface view.
When you assign a trunk port to a VLAN, follow these guidelines:
· To change the link type of a port from trunk to hybrid or vice versa, set the link type to access first.
· To enable a trunk port to transmit packets from its PVID, you must assign the trunk port to the PVID by using the port trunk permit vlan command.
To assign a trunk port to one or multiple VLANs:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter interface view. |
·
Enter Layer 2 Ethernet interface view: ·
Enter Layer 2 aggregate interface view: |
· The configuration made in Layer 2 Ethernet interface view applies only to the port. · The configuration made in Layer 2 aggregate interface view applies to the aggregate interface and its aggregation member ports. If the system fails to apply the configuration to an aggregation member port, it skips the port and moves to the next member port. If the system fails to apply the configuration to the aggregate interface, it stops applying the configuration to aggregation member ports. |
|
3. Configure the link type of the port as trunk. |
port link-type trunk |
By default, all ports are access ports. |
|
4. Assign the trunk port to the specified VLANs. |
port trunk permit vlan { vlan-id-list | all } |
By default, a trunk port only permits VLAN 1. |
|
5. (Optional.) Configure the PVID of the trunk port. |
port trunk pvid vlan vlan-id |
The default setting is VLAN 1. |
Assigning a hybrid port to a VLAN
A hybrid port supports multiple VLANs. You can assign it to the specified VLANs in interface view. Make sure the VLANs have been created.
When you assign a hybrid port to a VLAN, follow these guidelines:
· To change the link type of a port from trunk to hybrid or vice versa, set the link type to access first.
· To enable a hybrid port to transmit packets from its PVID, you must assign the hybrid port to the PVID by using the port hybrid vlan command.
To assign a hybrid port to one or multiple VLANs:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter interface view. |
·
Enter Layer 2 Ethernet interface view: ·
Enter Layer 2 aggregate interface view: |
· The configuration made in Layer 2 Ethernet interface view applies only to the port. · The configuration made in Layer 2 aggregate interface view applies to the aggregate interface and its aggregation member ports. If the system fails to apply the configuration to an aggregation member port, it skips the port and moves to the next member port. If the system fails to apply the configuration to the aggregate interface, it stops applying the configuration to aggregation member ports. |
|
3. Configure the link type of the port as hybrid. |
port link-type hybrid |
By default, all ports are access ports. |
|
4. Assign the hybrid port to the specified VLANs. |
port hybrid vlan vlan-id-list { tagged | untagged } |
By default, a hybrid port is an untagged member of the VLAN to which the port belongs when its link type is access. |
|
5. (Optional.) Configure the PVID of the hybrid port. |
port hybrid pvid vlan vlan-id |
By default, the PVID of a hybrid port is the ID of the VLAN to which the port belongs when its link type is access. |
Displaying and maintaining VLANs
Execute display commands in any view.
|
Task |
Command |
|
Display VLAN information. |
display vlan [ vlan-id1 [ to vlan-id2 ] | all | dynamic | reserved | static ] |
|
Display brief VLAN information. |
|
|
Display VLAN interface information. |
display interface vlan-interface [ vlan-interface-id ] [ brief [ description ] ] |
|
Display hybrid ports or trunk ports. |
display port { hybrid | trunk } |
|
Display VLANs whose VLAN interface resources have been reserved. |
display reserve-vlan-interface [ global ] |
Port-based VLAN configuration example
Network requirements
As shown in Figure 35:
· Host A and Host C belong to Department A. VLAN 100 is assigned to Department A.
· Host B and Host D belong to Department B. VLAN 200 is assigned to Department B.
Configure port-based VLANs so that hosts only in the same department can communicate with each other.
Configuration procedure
1. Configure Device A:
# Create VLAN 100, and assign FortyGigE 1/0/1 to VLAN 100.
<DeviceA> system-view
[DeviceA] vlan 100
[DeviceA-vlan100] port fortygige 1/0/1
[DeviceA-vlan100] quit
# Create VLAN 200, and assign FortyGigE 1/0/2 to VLAN 200.
[DeviceA] vlan 200
[DeviceA-vlan200] port fortygige 1/0/2
[DeviceA-vlan200] quit
# Configure FortyGigE 1/0/3 as a trunk port, and assign it to VLANs 100 and 200.
[DeviceA] interface fortygige 1/0/3
[DeviceA-FortyGigE1/0/3] port link-type trunk
[DeviceA-FortyGigE1/0/3] port trunk permit vlan 100 200
Please wait... Done.
2. Configure Device B in the same way Device A is configured. (Details not shown.)
3. Configure hosts:
? Configure Host A and Host C to be on the same IP subnet. For example, 192.168.100.0/24.
? Configure Host B and Host D to be on the same IP subnet. For example, 192.168.200.0/24.
Verifying the configuration
# Verify that Host A and Host C can ping each other, but they both fail to ping Host B. (Details not shown.)
# Verify that Host B and Host D can ping each other, but they both fail to ping Host A. (Details not shown.)
# Verify that VLANs 100 and 200 are correctly configured on devices, for example, on Device A.
[DeviceA-FortyGigE1/0/3] display vlan 100
VLAN ID: 100
VLAN type: Static
Route interface: Not configured
Description: VLAN 0100
Name: VLAN 0100
Tagged ports:
FortyGigE1/0/3
Untagged ports:
FortyGigE1/0/1
[DeviceA-FortyGigE1/0/3] display vlan 200
VLAN ID: 200
VLAN type: Static
Route interface: Not configured
Description: VLAN 0200
Name: VLAN 0200
Tagged ports:
FortyGigE1/0/3
Untagged ports:
FortyGigE1/0/2
Configuring VLAN mapping
Overview
VLAN mapping re-marks VLAN tagged traffic with new VLAN IDs. H3C provides the following types of VLAN mapping:
· One-to-one VLAN mapping—Replaces one VLAN tag with another.
· One-to-two VLAN mapping—Adds single-tagged packets with an outer VLAN tag.
· Zero-to-two VLAN mapping—Adds untagged packets with two VLAN tags.
· Two-to-two VLAN mapping—Replaces the outer and inner VLAN IDs of double tagged traffic with a new pair of VLAN IDs.
· Two-to-three VLAN mapping—Adds double-tagged packets with an outermost VLAN tag.
Application scenario of one-to-one VLAN mapping
Figure 36 shows a typical application scenario of one-to-one VLAN mapping. The scenario implements broadband Internet access for a community.
Figure 36 Application scenario of one-to-one VLAN mapping
As shown in Figure 36, the network is implemented as follows:
· Each home gateway uses different VLANs to transmit the PC, VoD, and VoIP services.
· To further subclassify each type of traffic by customer, configure one-to-one VLAN mapping on the wiring-closet switches. This feature assigns a separate VLAN for each type of traffic from each customer. The required total number of VLANs in the network can be very large.
Application scenario of one-to-two and two-to-two VLAN mapping
Figure 37 shows a typical application scenario of one-to-two and two-to-two VLAN mapping. In this scenario, the two remote sites of the same VPN must communicate across two SP networks.
Figure 37 Application scenario of one-to-two and two-to-two VLAN mapping
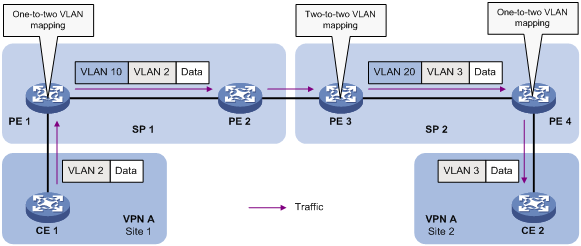
Site 1 and Site 2 are in VLAN 2 and VLAN 3, respectively. The SP 1 network assigns SVLAN 10 to Site 1. The SP 2 network assigns SVLAN 20 to Site 2. When the packet from Site 1 arrives at PE 1, PE 1 tags the packet with SVLAN 10 by using one-to-two VLAN mapping.
When the double-tagged packet from the SP 1 network arrives at the SP 2 network interface, PE 3 processes the packet as follows:
· Replaces SVLAN tag 10 with SVLAN 20.
· Replaces CVLAN tag 2 with CVLAN tag 3.
One-to-two VLAN mapping provides the following benefits:
· Enables a customer network to plan its CVLAN assignment without conflicting with SVLANs.
· Adds a VLAN tag to a tagged packet and expands the number of available VLANs to 4094 × 4094.
· Reduces the stress on the SVLAN resources, which were 4094 VLANs in the SP network before the mapping process was initiated.
Application scenario of zero-to-two VLAN mapping
Zero-to-two VLAN mapping is used on the customer-side port of a PE to add double tags to untagged packets.
Application scenario of two-to-three VLAN mapping
Two-to-three VLAN mapping is used on the customer-side port of a PE to add an outermost VLAN tag to double-tagged packets.
VLAN mapping implementations
Figure 38 shows a simplified network that illustrates basic VLAN mapping terms.
Basic VLAN mapping terms include the following:
· Uplink traffic—Traffic transmitted from the customer network to the service provider network.
· Downlink traffic—Traffic transmitted from the service provider network to the customer network.
· Network-side port—A port connected to or closer to the service provider network.
· Customer-side port—A port connected to or closer to the customer network.
Figure 38 Basic VLAN mapping terms
One-to-one VLAN mapping
As shown in Figure 39, one-to-one VLAN mapping is implemented on the customer-side port and replaces VLAN tags as follows:
· Replaces the CVLAN with the SVLAN for the uplink traffic.
· Replaces the SVLAN with the CVLAN for the downlink traffic.
Figure 39 One-to-one VLAN mapping implementation
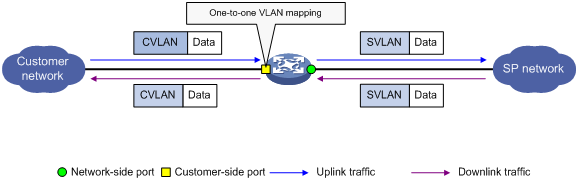
One-to-two VLAN mapping
As shown in Figure 40, one-to-two VLAN mapping is implemented on the customer-side port to add the SVLAN tag for the uplink traffic.
For the downlink traffic to be correctly sent to the customer network, use one of the following methods to remove the SVLAN tag from the traffic:
· Configure the customer-side port as a hybrid port and assign the port to the SVLAN as an untagged member.
· Configure the customer-side port as a trunk port, configure the SVLAN as the PVID, and assign the port to the PVID.
Figure 40 One-to-two VLAN mapping implementation
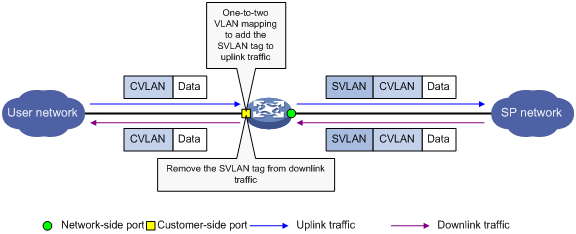
Zero-to-two VLAN mapping
As shown in Figure 41, zero-to-two VLAN mapping is implemented on the customer-side port to add double tags to untagged uplink traffic. For the zero-to-two VLAN mapping to take effect, the PVID of the customer-side port must be VLAN 1.
For correct downlink traffic transmission, the downlink traffic must be untagged or tagged with VLAN 1 when it is sent out of the customer-side port.
To tag the downlink traffic with VLAN 1, perform the following tasks:
1. Configure the network-side port to allow the traffic from the SVLAN to pass through.
2. If the CVLAN of the traffic is not VLAN 1, configure a two-to-two VLAN mapping on the network-side port to replace the CVLAN ID with VLAN 1.
3. Assign the customer-side port to the SVLAN as an untagged member.
Figure 41 Zero-to-two VLAN mapping implementation
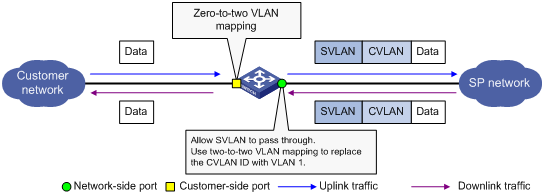
Two-to-two VLAN mapping
As shown in Figure 42, two-to-two VLAN mapping is implemented on the customer-side port and replaces VLAN tags as follows:
· Replaces the CVLAN and the SVLAN with the CVLAN' and the SVLAN' for the uplink traffic.
· Replaces the SVLAN' and CVLAN' with the SVLAN and the CVLAN for the downlink traffic.
Figure 42 Two-to-two VLAN mapping implementation
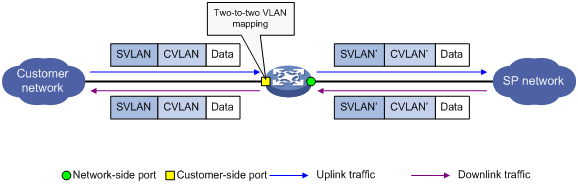
Two-to-three VLAN mapping
As shown in Figure 43, two-to-three VLAN mapping is implemented on the customer-side port to add an outermost VLAN tag to double-tagged uplink traffic.
For the downlink traffic to be correctly sent to the customer network, use one of the following methods to remove the outermost tag from the traffic:
· Configure the customer-side port as a trunk port, configure the outermost VLAN as the PVID, and assign the port to the PVID.
· Configure the customer-side port as a hybrid port and assign the port to the outermost VLAN as an untagged member.
Figure 43 Two-to-three VLAN mapping implementation
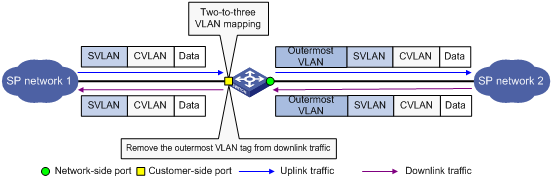
Configuration restrictions and guidelines
When you configure VLAN mapping, follow these restrictions and guidelines:
· Create original VLANs and translated VLANs before you configure VLAN mapping.
· Configure VLAN mapping on the customer-side port.
VLAN mapping configuration task list
|
|
IMPORTANT: Use the appropriate VLAN mapping methods for the devices in the network. |
To configure VLAN mapping:
|
Task |
Remarks |
|
Configure one-to-one VLAN mapping on the wiring-closet switch, as shown in Figure 36. |
|
|
Configure one-to-two VLAN mapping on PE 1 and PE 4, as shown in Figure 37, through which traffic from customer networks enter the service provider networks. |
|
|
N/A |
|
|
Configure two-to-two VLAN mapping on PE 3, as shown in Figure 37, which is an edge device of the SP 2 network. |
|
|
N/A |
Configuring one-to-one VLAN mapping
Configure one-to-one VLAN mapping on the customer-side ports of wiring-closet switches (see Figure 36) to isolate traffic of the same service type from different homes.
To configure one-to-one VLAN mapping:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Layer 2 Ethernet interface view or Layer 2 aggregate interface view. |
·
Enter Layer 2 Ethernet interface view: ·
Enter Layer 2 aggregate interface view: |
N/A |
|
3. Set the link type of the port. |
·
Configure the port as a trunk port: ·
Configure the port as a hybrid port: |
By default, the link type of a port is access. |
|
4. Assign the port to the original VLANs and the translated VLANs. |
· port trunk permit vlan vlan-id-list · port hybrid vlan vlan-id-list tagged |
By default, a trunk port is assigned only to VLAN 1, and a hybrid port is an untagged member of VLAN 1. |
|
5. Configure a one-to-one VLAN mapping. |
vlan mapping vlan-id translated-vlan vlan-id |
By default, VLAN mapping is not configured on an interface. |
Configuring one-to-two VLAN mapping
Configure one-to-two VLAN mapping on the customer-side ports of edge devices from which customer traffic enters SP networks, for example, on PE 1 and PE 4 in Figure 37. One-to-two VLAN mapping enables the edge devices to add an SVLAN tag to each incoming packet.
The MTU of an interface is 1500 bytes by default. After a VLAN tag is added to a packet through one-to-two VLAN mapping, the packet length is added by 4 bytes. As a best practice, set the MTU to a minimum of 1504 bytes for ports on the forwarding path of the packet in the service provider network.
To configure one-to-two VLAN mapping:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Layer 2 Ethernet interface view or Layer 2 aggregate interface view. |
·
Enter Layer 2 Ethernet interface view: ·
Enter Layer 2 aggregate interface view: |
N/A |
|
3. Set the link type of the port. |
·
Configure the port as a trunk port: ·
Configure the port as a hybrid port: |
By default, the link type of a port is access. |
|
4. Assign the port to the CVLAN. |
·
For a trunk port: ·
For a hybrid port: |
By default, a trunk port is assigned only to VLAN 1, and a hybrid port is an untagged member of VLAN 1. |
|
5. Configure the port to allow the packets from SVLAN to pass through untagged. |
· For a trunk port: a. Configure the SVLAN
as the PVID of the trunk port: b. Assign the port to the PVID: ·
For a hybrid port: |
N/A |
|
6. Configure a one-to-two VLAN mapping. |
vlan mapping nest { range vlan-range-list | single vlan-id-list } nested-vlan vlan-id |
By default, VLAN mapping is not configured on an interface. |
Configuring zero-to-two VLAN mapping
When you configure zero-to-two VLAN mapping, follow these restrictions and guidelines:
· For zero-to-two VLAN mapping to take effect, set the PVID of the customer-side port to 1.
· If the CVLAN ID of the downlink traffic is not VLAN 1, configure two-to-two VLAN mapping on the network-side port to change the CVLAN ID to 1.
· As a best practice, set the MTU to a minimum of 1504 bytes for ports on the forwarding path of the double-tagged packet in the service provider network.
To configure zero-to-two VLAN mapping:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Layer 2 Ethernet interface view or Layer 2 aggregate interface view. |
·
Enter Layer 2 Ethernet interface view: ·
Enter Layer 2 aggregate interface view: |
N/A |
|
3. Set the port link type to hybrid. |
port link-type hybrid |
By default, the link type of a port is access. |
|
4. Set the port PVID to VLAN 1. |
port hybrid pvid vlan vlan-id |
By default, the PVID of a port is VLAN 1. |
|
5. Assign the port to VLAN 1. |
port hybrid vlan vlan-id-list { tagged | untagged } |
By default, a hybrid port is an untagged member of VLAN 1. |
|
6. Assign the port to the SVLAN as an untagged member. |
port hybrid vlan vlan-id-list untagged |
By default, a hybrid port is an untagged member of VLAN 1. |
|
7. Configure a zero-to-two VLAN mapping. |
vlan mapping untagged nested-outer-vlan outer-vlan-id nested-inner-vlan inner-vlan-id |
By default, VLAN mapping is not configured on an interface. |
Configuring two-to-two VLAN mapping
Configure two-to-two VLAN mapping on the customer-side port of an edge device that connects two SP networks, for example, on PE 3 in Figure 37. Two-to-two VLAN mapping enables two remote sites in different VLANs to communicate at Layer 2 across two service provider networks that use different VLAN assignment schemes.
To configure two-to-two VLAN mapping:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Layer 2 Ethernet interface view or Layer 2 aggregate interface view. |
·
Enter Layer 2 Ethernet interface view: ·
Enter Layer 2 aggregate interface view: |
N/A |
|
3. Set the link type of the port. |
·
Configure the port as a trunk port: ·
Configure the port as a hybrid port: |
By default, the link type of a port is access. |
|
4. Assign the port to the original VLANs and the translated VLANs. |
· port trunk permit vlan vlan-id-list · port hybrid vlan vlan-id-list tagged |
By default, a trunk port is assigned only to VLAN 1, and a hybrid port is an untagged member of VLAN 1. |
|
5. Configure a two-to-two VLAN mapping. |
vlan mapping tunnel outer-vlan-id inner-vlan-id translated-vlan outer-vlan-id inner-vlan-id |
By default, VLAN mapping is not configured on an interface. |
Configuring two-to-three VLAN mapping
As a best practice, set the MTU to a minimum of 1508 bytes for ports on the forwarding path of the triple-tagged packet in the service provider network.
To configure two-to-three VLAN mapping:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Layer 2 Ethernet interface view or Layer 2 aggregate interface view. |
·
Enter Layer 2 Ethernet interface view: ·
Enter Layer 2 aggregate interface view: |
N/A |
|
3. Set the link type of the port. |
·
Configure the port as a trunk port: ·
Configure the port as a hybrid port: |
By default, the link type of a port is access. |
|
4. Assign the port to the original SVLAN. |
·
For a trunk port: ·
For a hybrid port: |
By default, a trunk port is assigned only to VLAN 1, and a hybrid port is an untagged member of VLAN 1. |
|
5. Configure the port to allow the packets from the outermost VLAN to pass through untagged. |
· For a trunk port: a. Configure the outermost
VLAN as the PVID of the trunk port: b. Assign the port to the PVID: ·
For a hybrid port: |
N/A |
|
6. Configure a two-to-three VLAN mapping. |
vlan mapping double-tagged { outer-vlan outer-vlan-id inner-vlan inner-vlan-id | outer-vlan-range vlan-id-list inner-vlan inner-vlan-id | outer-vlan outer-vlan-id inner-vlan-range vlan-id-list } nested-vlan nested-vlan |
By default, VLAN mapping is not configured on an interface. |
Displaying and maintaining VLAN mapping
Execute display commands in user view.
|
Task |
Command |
|
Display VLAN mapping information. |
display vlan mapping [ interface interface-type interface-number ] |
VLAN mapping configuration examples
One-to-one VLAN mapping configuration example
Network requirements
As shown in Figure 44:
· Each household subscribes to PC, VoD, and VoIP services, and obtains the IP address through DHCP.
· On the home gateways, VLANs 1, 2, and 3 are assigned to PC, VoD, and VoIP traffic, respectively.
To isolate traffic of the same service type from different households, configure one-to-one VLAN mappings on the wiring-closet switches to assign one VLAN to each type of traffic from each household.
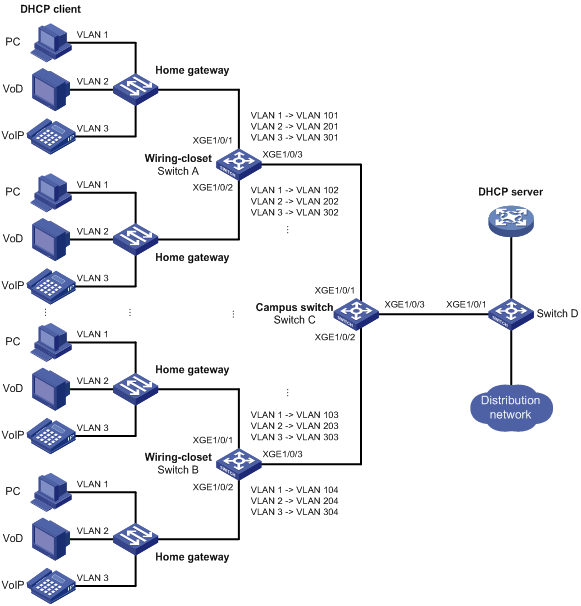
Configuration procedure
1. Configure Switch A:
# Configure the customer-side port Ten-GigabitEthernet 1/0/1 as a trunk port, and assign it to all original VLANs and translated VLANs.
<SwitchA> system-view
[SwitchA] interface ten-gigabitethernet 1/0/1
[SwitchA-Ten-GigabitEthernet1/0/1] port link-type trunk
[SwitchA-Ten-GigabitEthernet1/0/1] port trunk permit vlan 1 2 3 101 201 301
# Configure one-to-one VLAN mappings on Ten-GigabitEthernet 1/0/1 to map VLANs 1, 2, and 3 to VLANs 101, 201, and 301, respectively.
[SwitchA-Ten-GigabitEthernet1/0/1] vlan mapping 1 translated-vlan 101
[SwitchA-Ten-GigabitEthernet1/0/1] vlan mapping 2 translated-vlan 201
[SwitchA-Ten-GigabitEthernet1/0/1] vlan mapping 3 translated-vlan 301
[SwitchA-Ten-GigabitEthernet1/0/1] quit
# Configure the customer-side port Ten-GigabitEthernet 1/0/2 as a trunk port, and assign it to all original VLANs and translated VLANs.
[SwitchA] interface ten-gigabitethernet 1/0/2
[SwitchA-Ten-GigabitEthernet1/0/2] port link-type trunk
[SwitchA-Ten-GigabitEthernet1/0/2] port trunk permit vlan 1 2 3 102 202 302
# Configure one-to-one VLAN mappings on Ten-GigabitEthernet 1/0/2 to map VLANs 1, 2, and 3 to VLANs 102, 202, and 302, respectively.
[SwitchA-Ten-GigabitEthernet1/0/2] vlan mapping 1 translated-vlan 102
[SwitchA-Ten-GigabitEthernet1/0/2] vlan mapping 2 translated-vlan 202
[SwitchA-Ten-GigabitEthernet1/0/2] vlan mapping 3 translated-vlan 302
[SwitchA-Ten-GigabitEthernet1/0/2] quit
# Configure the network-side port Ten-GigabitEthernet 1/0/3 as a trunk port, and assign it to the translated VLANs.
[SwitchA] interface ten-gigabitethernet 1/0/3
[SwitchA-Ten-GigabitEthernet1/0/3] port link-type trunk
[SwitchA-Ten-GigabitEthernet1/0/3] port trunk permit vlan 101 201 301 102 202 302
[SwitchA-Ten-GigabitEthernet1/0/3] quit
2. Configure Switch B in the same way Switch A is configured. (Details not shown.)
Verifying the configuration
# Verify VLAN mapping information on the wiring-closet switches, for example, on Switch A.
[SwitchA] display vlan mapping
Interface Ten-GigabitEthernet1/0/1:
Outer VLAN Inner VLAN Translated Outer VLAN Translated Inner VLAN
1 N/A 101 N/A
2 N/A 201 N/A
3 N/A 301 N/A
Interface Ten-GigabitEthernet1/0/2:
Outer VLAN Inner VLAN Translated Outer VLAN Translated Inner VLAN
1 N/A 102 N/A
2 N/A 202 N/A
3 N/A 302 N/A
One-to-two and two-to-two VLAN mapping configuration example
Network requirements
As shown in Figure 45:
· Two VPN A branches, Site 1 and Site 2, are in VLAN 5 and VLAN 6, respectively.
· The two sites use different VPN access services from different service providers, SP 1 and SP 2.
· SP 1 assigns VLAN 100 to Site 1 and Site 2. SP 2 assigns VLAN 200 to Site 1 and Site 2.
Configure one-to-two and two-to-two VLAN mappings to enable the two branches to communicate across networks SP 1 and SP 2.
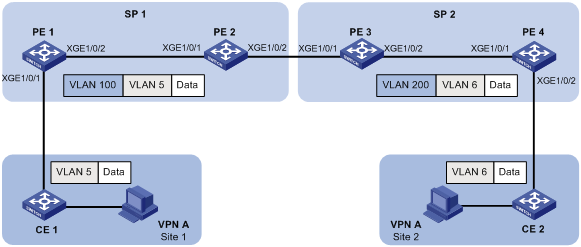
Configuration procedure
1. Configure PE 1:
# Configure a one-to-two VLAN mapping on the customer-side port Ten-GigabitEthernet 1/0/1 to add SVLAN tag 100 to packets from VLAN 5.
<PE1> system-view
[PE1] interface ten-gigabitethernet 1/0/1
[PE1-Ten-GigabitEthernet1/0/1] vlan mapping nest single 5 nested-vlan 100
# Configure Ten-GigabitEthernet 1/0/1 as a hybrid port.
[PE1-Ten-GigabitEthernet1/0/1] port link-type hybrid
# Assign Ten-GigabitEthernet 1/0/1 to VLAN 5 as a tagged member.
[PE1-Ten-GigabitEthernet1/0/1] port hybrid vlan 5 tagged
# Assign Ten-GigabitEthernet 1/0/1 to VLAN 100 as an untagged member.
[PE1-Ten-GigabitEthernet1/0/1] port hybrid vlan 100 untagged
[PE1-Ten-GigabitEthernet1/0/1] quit
# Configure the network-side port Ten-GigabitEthernet 1/0/2 as a trunk port, and assign it to VLAN 100.
[PE1] interface ten-gigabitethernet 1/0/2
[PE1-Ten-GigabitEthernet1/0/2] port link-type trunk
[PE1-Ten-GigabitEthernet1/0/2] port trunk permit vlan 100
[PE1-Ten-GigabitEthernet1/0/2] quit
2. Configure PE 2:
# Configure Ten-GigabitEthernet 1/0/1 as a trunk port, and assign it to VLAN 100.
<PE2> system-view
[PE2] interface ten-gigabitethernet 1/0/1
[PE2-Ten-GigabitEthernet1/0/1] port link-type trunk
[PE2-Ten-GigabitEthernet1/0/1] port trunk permit vlan 100
[PE2-Ten-GigabitEthernet1/0/1] quit
# Configure Ten-GigabitEthernet 1/0/2 as a trunk port, and assign it to VLAN 100.
[PE2] interface ten-gigabitethernet 1/0/2
[PE2-Ten-GigabitEthernet1/0/2] port link-type trunk
[PE2-Ten-GigabitEthernet1/0/2] port trunk permit vlan 100
[PE2-Ten-GigabitEthernet1/0/2] quit
3. Configure PE 3:
# Configure Ten-GigabitEthernet 1/0/1 as a trunk port, and assign it to VLANs 100 and 200.
<PE3> system-view
[PE3] interface ten-gigabitethernet 1/0/1
[PE3-Ten-GigabitEthernet1/0/1] port link-type trunk
[PE3-Ten-GigabitEthernet1/0/1] port trunk permit vlan 100 200
# Configure a two-to-two VLAN mapping on Ten-GigabitEthernet 1/0/1 to map SVLAN 100 and CVLAN 5 to SVLAN 200 and CVLAN 6.
[PE3-Ten-GigabitEthernet1/0/1] vlan mapping tunnel 100 5 translated-vlan 200 6
[PE3-Ten-GigabitEthernet1/0/1] quit
# Configure Ten-GigabitEthernet 1/0/2 as a trunk port, and assign it to VLAN 200.
[PE3] interface ten-gigabitethernet 1/0/2
[PE3-Ten-GigabitEthernet1/0/2] port link-type trunk
[PE3-Ten-GigabitEthernet1/0/2] port trunk permit vlan 200
[PE3-Ten-GigabitEthernet1/0/2] quit
4. Configure PE 4:
# Configure the network-side port Ten-GigabitEthernet 1/0/1 as a trunk port, and assign it to VLAN 200.
<PE4> system-view
[PE4] interface ten-gigabitethernet 1/0/1
[PE4-Ten-GigabitEthernet1/0/1] port link-type trunk
[PE4-Ten-GigabitEthernet1/0/1] port trunk permit vlan 200
[PE4-Ten-GigabitEthernet1/0/1] quit
# Configure the customer-side port Ten-GigabitEthernet 1/0/2 as a hybrid port.
[PE4] interface ten-gigabitethernet 1/0/2
[PE4-Ten-GigabitEthernet1/0/2] port link-type hybrid
# Assign Ten-GigabitEthernet 1/0/2 to VLAN 6 as a tagged member.
[PE4-Ten-GigabitEthernet1/0/2] port hybrid vlan 6 tagged
# Assign Ten-GigabitEthernet 1/0/2 to VLAN 200 as an untagged member.
[PE4-Ten-GigabitEthernet1/0/2] port hybrid vlan 200 untagged
# Configure a one-to-two VLAN mapping on the customer-side port Ten-GigabitEthernet 1/0/2 to add SVLAN tag 200 to packets from VLAN 6.
[PE4-Ten-GigabitEthernet1/0/2] vlan mapping nest single 6 nested-vlan 200
[PE4-Ten-GigabitEthernet1/0/2] quit
Verifying the configuration
# Verify VLAN mapping information on PE 1.
[PE1] display vlan mapping
Interface Ten-GigabitEthernet1/0/1:
Outer VLAN Inner VLAN Translated Outer VLAN Translated Inner VLAN
5 N/A 100 5
# Verify VLAN mapping information on PE 3.
[PE3] display vlan mapping
Interface Ten-GigabitEthernet1/0/1:
Outer VLAN Inner VLAN Translated Outer VLAN Translated Inner VLAN
100 5 200 6
# Verify VLAN mapping information on PE 4.
[PE4] display vlan mapping
Interface Ten-GigabitEthernet1/0/2:
Outer VLAN Inner VLAN Translated Outer VLAN Translated Inner VLAN
6 N/A 200 6
Configuring LLDP
You can set an Ethernet port as a Layer 3 interface by using the port link-mode route command (see "Configuring Ethernet interfaces").
Overview
In a heterogeneous network, a standard configuration exchange platform ensures that different types of network devices from different vendors can discover one another and exchange configuration.
The Link Layer Discovery Protocol (LLDP) is specified in IEEE 802.1AB. The protocol operates on the data link layer to exchange device information between directly connected devices. With LLDP, a device sends local device information as TLV (type, length, and value) triplets in LLDP Data Units (LLDPDUs) to the directly connected devices. Local device information includes its system capabilities, management IP address, device ID, port ID, and so on. The device stores the device information in LLDPDUs from the LLDP neighbors in a standard MIB. For more information about MIBs, see Network Management and Monitoring Configuration Guide. LLDP enables a network management system to quickly detect and identify Layer 2 network topology changes.
Basic concepts
LLDP agent
An LLDP agent is a mapping of an entity where LLDP runs. Multiple LLDP agents can run on the same interface.
LLDP agents include the following types:
· Nearest bridge agent.
· Nearest customer bridge agent.
· Nearest non-TPMR bridge agent.
A Two-port MAC Relay (TPMR) is a type of bridge that has only two externally-accessible bridge ports. It supports a subset of the functions of a MAC bridge. A TPMR is transparent to all frame-based media-independent protocols except for the following:
· Protocols destined to it.
· Protocols destined to reserved MAC addresses that the relay function of the TPMR is configured not to forward.
LLDP exchanges packets between neighbor agents and creates and maintains neighbor information for them. Figure 46 shows the neighbor relationships for these LLDP agents. LLDP has two bridge modes: customer bridge (CB) and service bridge (SB).
Figure 46 LLDP neighbor relationships
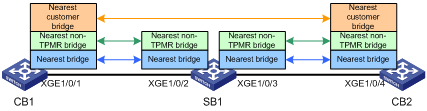
LLDP frame formats
LLDP sends device information in LLDP frames. LLDP frames are encapsulated in Ethernet II or SNAP frames.
· LLDP frame encapsulated in Ethernet II
Figure 47 Ethernet II-encapsulated LLDP frame
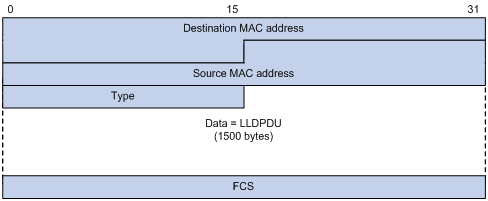
Table 11 Fields in an Ethernet II-encapsulated LLDP frame
|
Field |
Description |
|
Destination MAC address |
MAC address to which the LLDP frame is advertised. LLDP specifies different multicast MAC addresses as destination MAC addresses for LLDP frames destined for agents of different types. This helps distinguish between LLDP frames sent and received by different agent types on the same interface. The destination MAC address is fixed to one of the following multicast MAC addresses: · 0x0180-C200-000E for LLDP frames destined for nearest bridge agents. · 0x0180-C200-0000 for LLDP frames destined for nearest customer bridge agents. · 0x0180-C200-0003 for LLDP frames destined for nearest non-TPMR bridge agents. |
|
Source MAC address |
MAC address of the sending port. |
|
Type |
Ethernet type for the upper-layer protocol. This field is 0x88CC for LLDP. |
|
Data |
LLDPDU. |
|
FCS |
Frame check sequence, a 32-bit CRC value used to determine the validity of the received Ethernet frame. |
· LLDP frame encapsulated in SNAP
Figure 48 SNAP-encapsulated LLDP frame
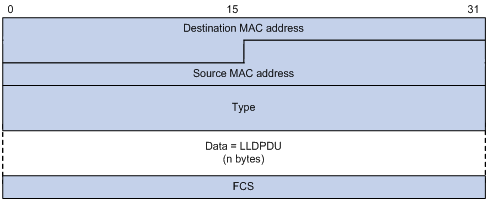
Table 12 Fields in a SNAP-encapsulated LLDP frame
|
Field |
Description |
|
Destination MAC address |
MAC address to which the LLDP frame is advertised. It is the same as that for Ethernet II-encapsulated LLDP frames. |
|
Source MAC address |
MAC address of the sending port. |
|
Type |
SNAP type for the upper-layer protocol. This field is 0xAAAA-0300-0000-88CC for LLDP. |
|
Data |
LLDPDU. |
|
FCS |
Frame check sequence, a 32-bit CRC value used to determine the validity of the received Ethernet frame. |
LLDPDUs
LLDP uses LLDPDUs to exchange information. An LLDPDU comprises multiple TLV. Each TLV carries a type of device information, as shown in Figure 49.
Figure 49 LLDPDU encapsulation format
![]()
An LLDPDU can carry up to 32 types of TLVs. Mandatory TLVs include Chassis ID TLV, Port ID TLV, Time to Live TLV, and End of LLDPDU TLV. Other TLVs are optional.
TLVs
A TLV is an information element that contains the type, length, and value fields.
LLDPDU TLVs include the following categories:
· Basic management TLVs
· Organizationally (IEEE 802.1 and IEEE 802.3) specific TLVs
· LLDP-MED (media endpoint discovery) TLVs
Basic management TLVs are essential to device management.
Organizationally specific TLVs and LLDP-MED TLVs are used for enhanced device management. They are defined by standardization or other organizations and are optional to LLDPDUs.
· Basic management TLVs
Table 13 lists the basic management TLV types. Some of them are mandatory to LLDPDUs.
Table 13 Basic management TLVs
|
Type |
Description |
Remarks |
|
Chassis ID |
Specifies the bridge MAC address of the sending device. |
Mandatory. |
|
Port ID |
Specifies the ID of the sending port. · If the LLDPDU carries LLDP-MED TLVs, the port ID TLV carries the MAC address of the sending port. · Otherwise, the port ID TLV carries the port name. |
|
|
Time to Live |
Specifies the life of the transmitted information on the receiving device. |
|
|
End of LLDPDU |
Marks the end of the TLV sequence in the LLDPDU. |
|
|
Port Description |
Specifies the description of the sending port. |
Optional. |
|
System Name |
Specifies the assigned name of the sending device. |
|
|
System Description |
Specifies the description of the sending device. |
|
|
System Capabilities |
Identifies the primary functions of the sending device and the enabled primary functions. |
|
|
Management Address |
Specifies the following elements: · The management address of the local device. · The interface number and object identifier (OID) associated with the address. |
· IEEE 802.1 organizationally specific TLVs
Table 14 IEEE 802.1 organizationally specific TLVs
|
Type |
Description |
|
Port VLAN ID |
Specifies the port's VLAN identifier (PVID). |
|
Port And Protocol VLAN ID |
Indicates whether the device supports protocol VLANs and, if so, what VLAN IDs these protocols will be associated with. |
|
VLAN Name |
Specifies the textual name of any VLAN to which the port belongs. |
|
Protocol Identity |
Indicates protocols supported on the port. |
|
DCBX |
Data center bridging exchange protocol. |
|
EVB module |
Edge Virtual Bridging module, comprising EVB TLV and CDCP TLV. NOTE: The switch does not support EVB TLV and CDCP TLV in the current software version. |
|
Link Aggregation |
Indicates whether the port supports link aggregation, and if yes, whether link aggregation is enabled. |
|
Management VID |
Management VLAN ID. |
|
VID Usage Digest |
VLAN ID usage digest. |
|
ETS Configuration |
Enhanced Transmission Selection configuration. |
|
ETS Recommendation |
ETS recommendation. |
|
PFC |
Priority-based Flow Control. |
|
APP |
Application protocol. |
|
|
NOTE: · H3C devices support only receiving protocol identity TLVs and VID usage digest TLVs. · Layer 3 Ethernet ports support only link aggregation TLVs. |
· IEEE 802.3 organizationally specific TLVs
Table 15 IEEE 802.3 organizationally specific TLVs
|
Type |
Description |
|
MAC/PHY Configuration/Status |
Contains the bit-rate and duplex capabilities of the port, support for autonegotiation, enabling status of autonegotiation, and the current rate and duplex mode. |
|
Power Via MDI |
Contains the power supply capability of the port: · Port class (PSE or PD). · Power supply mode. · Whether PSE power supply is supported. · Whether PSE power supply is enabled. · Whether pair selection can be controllable. |
|
Maximum Frame Size |
Indicates the supported maximum frame size. It is now the MTU of the port. |
|
Power Stateful Control |
Indicates the power state control configured on the sending port, including the following: · Power supply mode of the PSE/PD. · PSE/PD priority. · PSE/PD power. |
|
|
NOTE: The Power Stateful Control TLV is defined in IEEE P802.3at D1.0 and is not supported in later versions. H3C devices send this type of TLVs only after receiving them. |
· LLDP-MED TLVs
LLDP-MED TLVs provide multiple advanced applications for voice over IP (VoIP), such as basic configuration, network policy configuration, and address and directory management. LLDP-MED TLVs provide a cost-effective and easy-to-use solution for deploying voice devices in Ethernet. LLDP-MED TLVs are shown in Table 16.
|
Type |
Description |
|
LLDP-MED Capabilities |
Allows a network device to advertise the LLDP-MED TLVs that it supports. |
|
Network Policy |
Allows a network device or terminal device to advertise the VLAN ID of a port, the VLAN type, and the Layer 2 and Layer 3 priorities for specific applications. |
|
Extended Power-via-MDI |
Allows a network device or terminal device to advertise power supply capability. This TLV is an extension of the Power Via MDI TLV. |
|
Hardware Revision |
Allows a terminal device to advertise its hardware version. |
|
Firmware Revision |
Allows a terminal device to advertise its firmware version. |
|
Software Revision |
Allows a terminal device to advertise its software version. |
|
Serial Number |
Allows a terminal device to advertise its serial number. |
|
Manufacturer Name |
Allows a terminal device to advertise its vendor name. |
|
Model Name |
Allows a terminal device to advertise its model name. |
|
Asset ID |
Allows a terminal device to advertise its asset ID. The typical case is that the user specifies the asset ID for the endpoint to facilitate directory management and asset tracking. |
|
Location Identification |
Allows a network device to advertise the appropriate location identifier information for a terminal device to use in the context of location-based applications. |
|
|
NOTE: · If the MAC/PHY configuration/status TLV is not advertisable, none of the LLDP-MED TLVs will be advertised even if they are advertisable. · If the LLDP-MED capabilities TLV is not advertisable, the other LLDP-MED TLVs will not be advertised even if they are advertisable. |
Management address
The network management system uses the management address of a device to identify and manage the device for topology maintenance and network management. The management address is encapsulated in the management address TLV.
Work mechanism
LLDP operating modes
An LLDP agent can operate in one of the following modes:
· TxRx mode—An LLDP agent in this mode can send and receive LLDP frames.
· Tx mode—An LLDP agent in this mode can only send LLDP frames.
· Rx mode—An LLDP agent in this mode can only receive LLDP frames.
· Disable mode—An LLDP agent in this mode cannot send or receive LLDP frames.
Each time the LLDP operating mode of an LLDP agent changes, its LLDP protocol state machine re-initializes. A configurable re-initialization delay prevents frequent initializations because of frequent changes to the operating mode. If you configure the reinitialization delay, an LLDP agent must wait the specified amount of time to initialize LLDP after the LLDP operating mode changes.
Transmitting LLDP frames
An LLDP agent operating in TxRx mode or Tx mode sends LLDP frames to its directly connected devices both periodically and when the local configuration changes. To prevent LLDP frames from overwhelming the network during times of frequent changes to local device information, LLDP uses the token bucket mechanism to rate limit LLDP frames. For more information about the token bucket mechanism, see ACL and QoS Configuration Guide.
LLDP automatically enables the fast LLDP frame transmission mechanism in either of the following cases:
· A new LLDP frame is received and carries device information new to the local device.
· The LLDP operating mode of the LLDP agent changes from Disable or Rx to TxRx or Tx.
The fast LLDP frame transmission mechanism successively sends the specified number of LLDP frames at a configurable fast LLDP frame transmission interval. The mechanism helps LLDP neighbors discover the local device as soon as possible. Then, the normal LLDP frame transmission interval resumes.
Receiving LLDP frames
An LLDP agent operating in TxRx mode or Rx mode confirms the validity of TLVs carried in every received LLDP frame. If the TLVs are valid, the LLDP agent saves the information and starts an aging timer. When the TTL value in the Time To Live TLV carried in the LLDP frame becomes zero, the information ages out immediately.
Protocols and standards
· IEEE 802.1AB-2005, Station and Media Access Control Connectivity Discovery
· IEEE 802.1AB-2009, Station and Media Access Control Connectivity Discovery
· ANSI/TIA-1057, Link Layer Discovery Protocol for Media Endpoint Devices
· DCB Capability Exchange Protocol Specification Rev 1.0
· DCB Capability Exchange Protocol Base Specification Rev 1.01
· IEEE Std 802.1Qaz-2011: Media Access Control (MAC) Bridges and Virtual Bridged Local Area Networks-Amendment 18: Enhanced Transmission Selection for Bandwidth Sharing Between Traffic Classes
LLDP configuration task list
|
Tasks at a glance |
|
Performing basic LLDP configuration: (Required.) Enabling LLDP (Optional.) Configuring the LLDP bridge mode (Optional.) Setting the LLDP operating mode (Optional.) Setting the LLDP re-initialization delay (Optional.) Enabling LLDP polling (Optional.) Configuring the advertisable TLVs (Optional.) Configuring the management address and its encoding format (Optional.) Setting other LLDP parameters (Optional.) Setting an encapsulation format for LLDP frames |
|
(Optional.) Configuring CDP compatibility |
|
(Optional.) Configuring DCBX |
|
(Optional.) Configuring LLDP trapping and LLDP-MED trapping |
Performing basic LLDP configuration
Enabling LLDP
To make LLDP take effect on specific ports, you must enable LLDP both globally and on these ports.
To enable LLDP:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enable LLDP globally. |
lldp global enable |
By default, LLDP is disabled globally. |
|
3. Enter Layer 2/Layer 3 Ethernet interface view, Layer 2/Layer 3 aggregate interface view, or IRF physical interface view. |
interface interface-type interface-number |
N/A |
|
4. (Optional.) Enable LLDP. |
lldp enable |
By default, LLDP is enabled on a port. |
|
|
NOTE: The switch supports configuring LLDP on IRF physical interfaces for you to check connections and view link status on IRF physical interfaces. |
Configuring the LLDP bridge mode
The following LLDP bridge modes are available:
· Service bridge mode—In service bridge mode, LLDP supports nearest bridge agents and nearest non-TPMR bridge agents. LLDP processes the LLDP frames with destination MAC addresses for these agents and transparently transmits the LLDP frames with other destination MAC addresses in the VLAN.
· Customer bridge mode—In customer bridge mode, LLDP supports nearest bridge agents, nearest non-TPMR bridge agents, and nearest customer bridge agents. LLDP processes the LLDP frames with destination MAC addresses for these agents and transparently transmits the LLDP frames with other destination MAC addresses in the VLAN.
To configure the LLDP bridge mode:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Configure LLDP to operate in service bridge mode. |
lldp mode service-bridge |
By default, LLDP operates in customer bridge mode. |
Setting the LLDP operating mode
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Layer 2/Layer 3 Ethernet interface view, Layer 2/Layer 3 aggregate interface view, or IRF physical interface view. |
interface interface-type interface-number |
N/A |
|
3. Set the LLDP operating mode. |
·
In Layer 2/Layer 3 Ethernet interface view: ·
In Layer 2/Layer 3 aggregate interface view: ·
In IRF physical interface view: |
By default: · The nearest bridge agent operates in txrx mode. · The nearest customer bridge agent and nearest non-TPMR bridge agent operate in disable mode. In Ethernet interface view, if no agent type is specified, the command configures the operating mode for nearest bridge agents. In aggregate interface view, you can configure the operating mode for only nearest customer bridge agents and nearest non-TPMR bridge agents. In IRF physical interface view, you can configure the operating mode for only nearest bridge agents. |
Setting the LLDP re-initialization delay
When the LLDP operating mode changes on a port, the port initializes the protocol state machines after an LLDP reinitialization delay. By adjusting the delay, you can avoid frequent initializations caused by frequent changes to the LLDP operating mode on a port.
To set the LLDP re-initialization delay for ports:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Set the LLDP re-initialization delay. |
lldp timer reinit-delay delay |
The default setting is 2 seconds. |
Enabling LLDP polling
With LLDP polling enabled, a device periodically searches for local configuration changes. When the device detects a configuration change, it sends LLDPDUs to inform neighboring devices of the change.
To enable LLDP polling:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Layer 2/Layer 3 Ethernet interface view, Layer 2/Layer 3 aggregate interface view, or IRF physical interface view. |
interface interface-type interface-number |
N/A |
|
3. Enable LLDP polling and set the polling interval. |
·
In Layer 2/Layer 3 Ethernet interface view: ·
In Layer 2/Layer 3 aggregate interface view: ·
In IRF physical interface view: |
By default, LLDP polling is disabled. |
Configuring the advertisable TLVs
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Layer 2/Layer 3 Ethernet interface view, Layer 2/Layer 3 aggregate interface view, or IRF physical interface view. |
interface interface-type interface-number |
N/A |
|
3. Configure the advertisable TLVs (in Layer 2 Ethernet interface view). |
· lldp tlv-enable { basic-tlv { all | port-description | system-capability | system-description | system-name | management-address-tlv [ ip-address ] } | dot1-tlv { all | port-vlan-id | link-aggregation | dcbx | protocol-vlan-id [ vlan-id ] | vlan-name [ vlan-id ] | management-vid [ mvlan-id ] } | dot3-tlv { all | mac-physic | max-frame-size | power } | med-tlv { all | capability | inventory | network-policy | power-over-ethernet | location-id { civic-address device-type country-code { ca-type ca-value }&<1-10> | elin-address tel-number } } } · lldp agent nearest-nontpmr tlv-enable { basic-tlv { all | port-description | system-capability | system-description | system-name | management-address-tlv [ ip-address ] } | dot1-tlv { all | port-vlan-id | link-aggregation } } · lldp agent nearest-customer tlv-enable { basic-tlv { all | port-description | system-capability | system-description | system-name | management-address-tlv [ ip-address ] } | dot1-tlv { all | port-vlan-id | link-aggregation } } |
By default: · Nearest bridge agents can advertise all LLDP TLVs except the DCBX, location identification, port and protocol VLAN ID, VLAN name, and management VLAN ID TLVs. · Nearest non-TPMR bridge agents advertise no TLVs. · Nearest customer bridge agents can advertise basic TLVs and IEEE 802.1 organizationally specific TLVs. |
|
4. Configure the advertisable TLVs (in Layer 3 Ethernet interface view). |
· lldp tlv-enable { basic-tlv { all | port-description | system-capability | system-description | system-name | management-address-tlv [ ip-address ] } | dot1-tlv { all | link-aggregation } | dot3-tlv { all | mac-physic | max-frame-size | power } | med-tlv { all | capability | inventory | power-over-ethernet | location-id { civic-address device-type country-code { ca-type ca-value }&<1-10> | elin-address tel-number } } } · lldp agent { nearest-nontpmr | nearest-customer } tlv-enable { basic-tlv { all | port-description | system-capability | system-description | system-name | management-address-tlv [ ip-address ] } | dot1-tlv { all | link-aggregation } } |
By default: · Nearest bridge agents can advertise all LLDP TLVs (only link aggregation TLV in 802.1 organizationally specific TLVs) except network policy TLVs. · Nearest non-TPMR bridge agents advertise no TLVs. · Nearest customer bridge agents can advertise basic TLVs and IEEE 802.1 organizationally specific TLVs (only link aggregation TLV). |
|
5. Configure the advertisable TLVs (in Layer 2 aggregate interface view). |
· lldp agent nearest-nontpmr tlv-enable { basic-tlv { all | management-address-tlv [ ip-address ] | port-description | system-capability | system-description | system-name } | dot1-tlv { all | port-vlan-id } } · lldp agent nearest-customer tlv-enable { basic-tlv { all | management-address-tlv [ ip-address ] | port-description | system-capability | system-description | system-name } | dot1-tlv { all | port-vlan-id } } · lldp tlv-enable dot1-tlv { protocol-vlan-id [ vlan-id ] | vlan-name [ vlan-id ] | management-vid [ mvlan-id ] } |
By default: · Nearest non-TPMR bridge agents advertise no TLVs. · Nearest customer bridge agents can advertise basic TLVs and IEEE 802.1 organizationally specific TLVs (only port and protocol VLAN ID TLV, VLAN name TLV, and management VLAN ID TLV). · Nearest bridge agents are not supported on Layer 2 aggregate interfaces. |
|
6. Configure the advertisable TLVs (in Layer 3 aggregate interface view). |
lldp agent { nearest-customer | nearest-nontpmr } tlv-enable basic-tlv { all | management-address-tlv [ ip-address ] | port-description | system-capability | system-description | system-name } |
By default: · Nearest non-TPMR bridge agents advertise no TLVs. · Nearest customer bridge agents can advertise only basic TLVs. · Nearest bridge agents are not supported on Layer 3 aggregate interfaces. |
|
7. Configure the advertisable TLVs (in IRF physical interface view). |
lldp tlv-enable basic-tlv { port-description | system-capability | system-description | system-name } |
By default, an agent can advertise all supported TLVs. |
Configuring the management address and its encoding format
LLDP encodes management addresses in numeric or string format in management address TLVs.
By default, management addresses are encoded in numeric format. If a neighbor encodes its management address in string format, configure the encoding format of the management address as string on the connecting port. This guarantees normal communication with the neighbor.
To configure a management address to be advertised and its encoding format on a port:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Layer 2/Layer 3 Ethernet interface view, or Layer 2/Layer 3 aggregate interface view. |
interface interface-type interface-number |
N/A |
|
3. Allow LLDP to advertise the management address in LLDP frames and configure the advertised management address. |
·
In Layer 2/Layer 3 Ethernet interface view: ·
In Layer 2/Layer 3 aggregate interface view: |
By default: · Nearest bridge agents and nearest customer bridge agents can advertise the management address in LLDP frames. · Nearest non-TPMR bridge agents cannot advertise the management address in LLDP frames. |
|
4. Configure the encoding format of the management address as string. |
·
In Layer 2/Layer 3 Ethernet interface view: ·
In Layer 2/Layer 3 aggregate interface view: |
By default, the encoding format of the management address is numeric. |
Setting other LLDP parameters
The Time to Live TLV carried in an LLDPDU determines how long the device information carried in the LLDPDU can be saved on a recipient device.
By setting the TTL multiplier, you can configure the TTL of locally sent LLDPDUs, which determines how long information about the local device can be saved on a neighboring device. The TTL is expressed by using the following formula:
TTL = Min (65535, (TTL multiplier × LLDP frame transmission interval))
As the expression shows, the TTL can be up to 65535 seconds. TTLs greater than 65535 will be rounded down to 65535 seconds.
To change LLDP parameters:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Set the TTL multiplier. |
lldp hold-multiplier value |
The default setting is 4. |
|
3. Set the LLDP frame transmission interval. |
lldp timer tx-interval interval |
The default setting is 30 seconds. |
|
4. Set the token bucket size for sending LLDP frames. |
lldp max-credit credit-value |
The default setting is 5. |
|
5. Set the LLDP frame transmission delay. |
lldp timer tx-delay delay |
The default setting is 2 seconds. |
|
6. Set the number of LLDP frames sent each time fast LLDP frame transmission is triggered. |
lldp fast-count count |
The default setting is 4. |
|
7. Set an interval for fast LLDP frame transmission. |
lldp timer fast-interval interval |
The default setting is 1 second. |
Setting an encapsulation format for LLDP frames
LLDP frames can be encapsulated in the following formats:
· Ethernet II—With Ethernet II encapsulation configured, an LLDP port sends LLDP frames in Ethernet II frames.
· SNAP—With SNAP encapsulation configured, an LLDP port sends LLDP frames in SNAP frames.
To set the encapsulation format for LLDP frames to SNAP:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Layer 2/Layer 3 Ethernet interface view, Layer 2/Layer 3 aggregate interface view, or IRF physical interface view. |
interface interface-type interface-number |
N/A |
|
3. Set the encapsulation format for LLDP frames to SNAP. |
·
In Layer 2/Layer 3 Ethernet interface view: ·
In Layer 2/Layer 3 aggregate interface view: ·
In IRF physical interface view: |
By default, Ethernet II encapsulation format applies. |
|
|
NOTE: LLDP of earlier versions requires the same encapsulation format on both ends to process LLDP frames. For this reason, to communicate stably with a neighboring device running LLDP of earlier versions, the local device should be configured with the same encapsulation format. |
Configuring CDP compatibility
When the switch is directly connected to a Cisco device that supports only CDP rather than LLDP, you can enable CDP compatibility to enable the switch to exchange information with the directly-connected device.
With CDP compatibility enabled on the switch, the switch can use LLDP to perform the following tasks:
· Receive and recognize the CDP packets received from the directly-connected device.
· Send CDP packets to the directly-connected device.
The packets that the switch sends to the neighboring CDP device carry the device ID, the ID of the port connecting to the neighboring device, the port IP address, the PVID, and the TTL. The port IP address is the main IP address of the VLAN interface in up state. The VLAN interface must have the lowest VLAN ID among all VLANs permitted on the port. If none of the VLAN interfaces of the permitted VLANs is assigned an IP address or all VLAN interfaces are down, no port IP address will be advertised.
The CDP neighbor-information-related fields in the output of the display lldp neighbor-information command show the CDP neighboring device information that can be recognized by the switch. For more information about the display lldp neighbor-information command, see Layer 2—LAN Switching Command Reference.
Configuration prerequisites
Before you configure CDP compatibility, complete the following tasks:
· Globally enable LLDP.
· Enable LLDP on the port connecting to a device supporting CDP.
· Configure the port to operate in TxRx mode.
Configuration procedure
CDP-compatible LLDP operates in one of the following modes:
· TxRx—CDP packets can be transmitted and received.
· Disable—CDP packets cannot be transmitted or received.
To make CDP-compatible LLDP take effect on specific ports, follow these steps:
1. Enable CDP-compatible LLDP globally.
2. Configure CDP-compatible LLDP to operate in TxRx mode on the port.
The maximum TTL value that CDP allows is 255 seconds. To make CDP-compatible LLDP work correctly with Cisco IP phones, configure the LLDP frame transmission interval to be no more than 1/3 of the TTL value.
To enable LLDP to be compatible with CDP:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enable CDP compatibility globally. |
lldp compliance cdp |
By default, CDP compatibility is disabled globally. |
|
3. Enter Layer 2 or Layer 3 Ethernet interface view. |
interface interface-type interface-number |
N/A |
|
4. Configure CDP-compatible LLDP to operate in TxRx mode. |
lldp compliance admin-status cdp txrx |
By default, CDP-compatible LLDP operates in disable mode. |
Configuring DCBX
Data Center Ethernet (DCE), also known as Converged Enhanced Ethernet (CEE), is enhancement and expansion of traditional Ethernet local area networks for use in data centers. DCE uses the Data Center Bridging Exchange Protocol (DCBX) to negotiate and remotely configure the bridge capability of network elements.
DCBX has the following self-adaptable versions:
· DCB Capability Exchange Protocol Specification Rev 1.00.
· DCB Capability Exchange Protocol Base Specification Rev 1.01.
· IEEE Std 802.1Qaz-2011 (Media Access Control (MAC) Bridges and Virtual Bridged Local Area Networks-Amendment 18: Enhanced Transmission Selection for Bandwidth Sharing Between Traffic Classes).
DCBX offers the following functions:
· Discovers the peer devices' capabilities and determines whether devices at both ends support these capabilities.
· Detects configuration errors on peer devices.
· Remotely configures the peer device if the peer device accepts the configuration.
|
|
NOTE: H3C devices support only the remote configuration function. |
Figure 50 DCBX application scenario
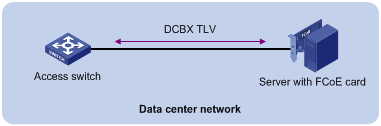
DCBX enables lossless packet transmission on DCE networks.
As shown in Figure 50, DCBX applies to an FCoE-based data center network, and operates on an access switch. DCBX enables the switch to control the server adapter, and simplifies the configuration and guarantees configuration consistency. DCBX extends LLDP by using the IEEE 802.1 organizationally specific TLVs (DCBX TLVs) to transmit DCBX data, including:
· In DCBX Rev 1.00 and DCBX Rev 1.01:
? Application Protocol (APP).
? Enhanced Transmission Selection (ETS).
? Priority-based Flow Control (PFC).
· In IEEE Std 802.1Qaz-2011:
? ETS Configuration.
? ETS Recommendation.
? PFC.
? APP.
DCBX configuration task list
|
Tasks at a glance |
|
|
(Required.) Enabling LLDP and DCBX TLV advertising |
|
|
(Required.) Configuring the DCBX version |
|
|
(Required.) Configuring APP parameters |
|
|
(Optional.) Configuring ETS parameters: |
|
|
(Required.) Configuring PFC parameters |
|
Enabling LLDP and DCBX TLV advertising
To enable the device to advertise APP, ETS, and PFC data through an interface, perform the following tasks:
· Enable LLDP globally.
· Enable LLDP and DCBX TLV advertising on the interface.
To enable LLDP and DCBX TLV advertising:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enable LLDP globally. |
lldp global enable |
By default, LLDP is disabled globally. |
|
3. Enter Layer 2 Ethernet interface view. |
interface interface-type interface-number |
N/A |
|
4. Enable LLDP. |
lldp enable |
By default, LLDP is enabled on an interface. |
|
5. Enable the interface to advertise DCBX TLVs. |
lldp tlv-enable dot1-tlv dcbx |
By default, DCBX TLV advertising is disabled on an interface. |
Configuring the DCBX version
When you configure the DCBX version, follow these restrictions and guidelines:
· For DCBX to work correctly, configure the same DCBX version on the local port and peer port. As a best practice, configure the highest version supported on both ends. IEEE Std 802.1Qaz-2011, DCBX Rev 1.01, and DCBX Rev 1.00 are in descending order.
· After the configuration, LLDP frames sent by the local port carry information about the configured DCBX version. The local port and peer port do not negotiate the DCBX version.
· If the DCBX version is autonegotiated, the version IEEE Std 802.1Qaz-2011 is preferably negotiated.
To configure the DCBX version:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Layer 2 Ethernet interface view. |
interface interface-type interface-number |
N/A |
|
3. Configure the DCBX version. |
dcbx version { rev100 | rev101 | standard } |
By default, the DCBX version is not configured. It is autonegotiated by the local port and peer port. |
Configuring APP parameters
The device negotiates with the server adapter by using the APP parameters to achieve the following purposes:
· Control the 802.1p priority values of the protocol packets that the server adapter sends.
· Identify traffic based on the 802.1p priority values.
For example, the device can use the APP parameters to negotiate with the server adapter to set 802.1p priority 3 for all FCoE and FIP frames. When the negotiation succeeds, all FCoE and FIP frames that the server adapter sends to the device carry the 802.1p priority 3.
Configuration restrictions and guidelines
When you configure APP parameters, follow these restrictions and guidelines:
· An Ethernet frame header ACL identifies application protocol packets by protocol number.
· An IPv4 advanced ACL identifies application protocol packets by IP port number.
· DCBX Rev 1.00 identifies application protocol packets only by protocol number and advertises TLVs with protocol number 0x8906 (FCoE) only.
· DCBX Rev 1.01 has the following attributes:
? Supports identifying application protocol packets by both protocol number and IP port number.
? Does not restrict the protocol number or IP port number for advertising TLVs.
? Can advertise up to 77 TLVs according to the remaining length of the current packet.
Configuration procedure
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Create an Ethernet frame header ACL or an IPv4 advanced ACL and enter ACL view. |
acl number acl-number [ name acl-name ] [ match-order { auto | config } ] |
An Ethernet frame header ACL number is in the range of 4000 to 4999. An IPv4 advanced ACL number is in the range of 3000 to 3999. DCBX Rev 1.00 supports only Ethernet frame header ACLs. DCBX Rev 1.01 and IEEE Std 802.1Qaz-2011 support both Ethernet frame header ACLs and IPv4 advanced ACLs. |
|
3. Create a rule for the ACL. |
·
For the Ethernet frame
header ACL: ·
For the IPv4 advanced ACL: |
Create rules according to the type of the ACL previously created. |
|
4. Return to system view. |
quit |
N/A |
|
5. Create a class, specify the operator of the class as OR, and enter class view. |
traffic classifier classifier-name operator or |
N/A |
|
6. Use the specified ACL as the match criterion of the class. |
if-match acl acl-number |
N/A |
|
7. Return to system view. |
quit |
N/A |
|
8. Create a traffic behavior and enter traffic behavior view. |
traffic behavior behavior-name |
N/A |
|
9. Configure the behavior to mark packets with an 802.1p priority. |
remark dot1p 8021p |
N/A |
|
10. Return to system view. |
quit |
N/A |
|
11. Create a QoS policy and enter QoS policy view. |
qos policy policy-name |
N/A |
|
12. Associate the class with the traffic behavior in the QoS policy, and apply the association to DCBX. |
classifier classifier-name behavior behavior-name mode dcbx |
In a QoS policy, you can configure multiple class-behavior associations. A packet might be configured with multiple 802.1p priority marking or mapping actions, and the one configured first takes effect. |
|
13. Return to system view. |
quit |
N/A |
|
14. Apply the QoS policy. |
·
(Method 1) To the
outgoing traffic of all ports: · (Method 2) To the outgoing traffic of a Layer 2 Ethernet interface: a. Enter Layer 2 Ethernet interface view: b. Apply the QoS policy to the outgoing traffic: |
· Configurations made in system view take effect on all ports. · Configurations made in Layer 2 Ethernet interface view take effect on the interface. |
For more information about the acl, rule, traffic classifier, if-match, traffic behavior, remark dot1p, qos policy, classifier behavior, qos apply policy global, and qos apply policy commands, see ACL and QoS Command Reference.
Configuring ETS parameters
ETS provides committed bandwidth. To avoid packet loss caused by congestion, the device performs the following tasks:
· Uses ETS parameters to negotiate with the server adapter.
· Controls the server adapter's transmission speed of the specified type of traffic.
· Guarantees that the transmission speed is within the committed bandwidth of the interface.
To configure ETS parameters, you must configure the 802.1p-to-local priority mapping and group-based WRR queuing.
Configuring the 802.1p-to-local priority mapping
You can configure the 802.1p-to-local priority mapping either by using the MQC method or the priority mapping table method. If you configure the 802.1p-to-local priority mapping by using both methods, the configuration made in the former method applies.
To configure the 802.1p-to-local priority mapping by using the MQC method:
|
Step |
Command |
|
1. Enter system view. |
system-view |
|
2. Create a class, specify the operator of the class as OR, and enter class view. |
traffic classifier classifier-name operator or |
|
3. Configure the class to match packets with the specified service provider network 802.1p priority values. |
if-match service-dot1p 8021p-list |
|
4. Return to system view. |
quit |
|
5. Create a traffic behavior and enter traffic behavior view. |
traffic behavior behavior-name |
|
6. Configure the behavior to mark packets with the specified local precedence value. |
remark local-precedence local-precedence |
|
7. Return to system view. |
quit |
|
8. Create a QoS policy and enter QoS policy view. |
qos policy policy-name |
|
9. Associate the class with the traffic behavior in the QoS policy, and apply the association to DCBX. |
classifier classifier-name behavior behavior-name mode dcbx |
For more information about the traffic classifier, if-match, traffic behavior, remark local-precedence, qos policy, and classifier behavior commands, see ACL and QoS Command Reference.
To configure the 802.1p priority mapping by using the priority mapping table method:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter 802.1p-to-local priority mapping table view. |
qos map-table dot1p-lp |
N/A |
|
3. Configure the priority mapping table to map the specified 802.1p priority values to a local precedence value. |
import import-value-list export export-value |
For information about the default priority mapping tables, see ACL and QoS Configuration Guide. |
|
4. Return to system view. |
quit |
N/A |
|
5. Enter Ethernet interface view. |
interface interface-type interface-number |
N/A |
|
6. Configure the interface to trust the 802.1p priority carried in packets. |
qos trust dot1p |
By default, an interface trusts the 802.1p priority carried in packets. |
For more information about the qos map-table, qos map-table color, and import commands, see ACL and QoS Command Reference.
Configuring group-based WRR queuing
You can configure group-based WRR queuing to allocate bandwidth.
To configure group-based WRR queuing:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Layer 2 Ethernet interface view. |
interface interface-type interface-number |
N/A |
|
3. Enable WRR queuing. |
qos wrr byte-count |
By default, WRR queuing is disabled. |
|
4. Configure a queue. |
·
Add a queue to WRR priority group 1 and configure the scheduling weight
for the queue: ·
Configure a queue to use strict priority queuing: |
Use one or both commands. |
For more information about the qos wrr, qos wrr byte-count, and qos wrr group sp commands, see ACL and QoS Command Reference.
Configuring PFC parameters
To prevent packets with an 802.1p priority value from being dropped, enable PFC for the 802.1p priority value. This feature reduces the sending rate of packets carrying this priority when network congestion occurs.
The device uses PFC parameters to negotiate with the server adapter and to enable PFC for the specified 802.1p priorities on the server adapter.
To configure PFC parameters:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Layer 2 Ethernet interface view. |
interface interface-type interface-number |
N/A |
|
3. Enable the Ethernet interface to automatically negotiate with its peer to decide whether to enable PFC. |
priority-flow-control auto |
By default, PFC is disabled. To advertise the PFC data, you must enable PFC in autonegotiation mode. |
|
4. Enable PFC for the specified 802.1p priorities. |
priority-flow-control no-drop dot1p dot1p-list |
By default, PFC is disabled for all 802.1p priorities. As a best practice, enable PFC for the 802.1p priority of FCoE traffic. If you enable PFC for multiple 802.1p priorities, packet loss might occur during periods of congestion. |
|
5. Configure the interface to trust the 802.1p priority carried in packets. |
qos trust dot1p |
By default, an interface trusts the 802.1p priority carried in packets. |
For more information about the priority-flow-control and priority-flow-control no-drop dot1p commands, see Interface Command Reference.
Configuring LLDP trapping and LLDP-MED trapping
LLDP trapping or LLDP-MED trapping notifies the network management system of events such as newly detected neighboring devices and link failures.
To prevent excessive LLDP traps from being sent when the topology is unstable, set a trap transmission interval for LLDP.
To configure LLDP trapping and LLDP-MED trapping:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter Layer 2/Layer 3 Ethernet interface view, Layer 2/Layer 3 aggregate interface view, or IRF physical interface view. |
interface interface-type interface-number |
N/A |
|
3. Enable LLDP trapping. |
·
In Layer 2/Layer 3 Ethernet interface view: ·
In Layer 2/Layer 3 aggregate interface view: ·
In IRF physical interface view: |
By default, LLDP trapping is disabled. |
|
4. Enable LLDP-MED trapping (in Layer 2 or Layer 3 Ethernet interface view). |
lldp notification med-topology-change enable |
By default, LLDP-MED trapping is disabled. |
|
5. Return to system view. |
quit |
N/A |
|
6. (Optional.) Set the LLDP trap transmission interval. |
lldp timer notification-interval interval |
The default setting is 30 seconds. |
Displaying and maintaining LLDP
Execute display commands in any view.
|
Command |
|
|
Display local LLDP information. |
display lldp local-information [ global | interface interface-type interface-number ] |
|
Display the information contained in the LLDP TLVs sent from neighboring devices. |
display lldp neighbor-information [ [ [ interface interface-type interface-number ] [ agent { nearest-bridge | nearest-customer | nearest-nontpmr } ] [ verbose ] ] | list [ system-name system-name ] ] |
|
Display LLDP statistics. |
display lldp statistics [ global | [ interface interface-type interface-number ] [ agent { nearest-bridge | nearest-customer | nearest-nontpmr } ] ] |
|
Display LLDP status of a port. |
display lldp status [ interface interface-type interface-number ] [ agent { nearest-bridge | nearest-customer | nearest-nontpmr } ] |
|
Display types of advertisable optional LLDP TLVs. |
display lldp tlv-config [ interface interface-type interface-number ] [ agent { nearest-bridge | nearest-customer | nearest-nontpmr } ] |
LLDP configuration example
Network requirements
As shown in Figure 51, the NMS and Switch A are located in the same Ethernet network. An MED device and Switch B are connected to FortyGigE 1/0/1 and FortyGigE 1/0/2 of Switch A.
Enable LLDP globally on Switch A and Switch B to perform the following tasks:
· Monitor the link between Switch A and Switch B on the NMS.
· Monitor the link between Switch A and the MED device on the NMS.
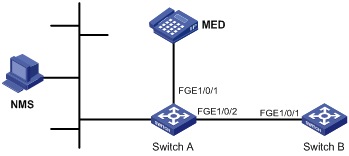
Configuration procedure
1. Configure Switch A:
# Enable LLDP globally.
<SwitchA> system-view
[SwitchA] lldp global enable
# Enable LLDP on FortyGigE 1/0/1. By default, LLDP is enabled on ports.
[SwitchA] interface fortygige 1/0/1
[SwitchA-FortyGigE1/0/1] lldp enable
# Set the LLDP operating mode to Rx on FortyGigE 1/0/1.
[SwitchA-FortyGigE1/0/1] lldp admin-status rx
[SwitchA-FortyGigE1/0/1] quit
# Enable LLDP on FortyGigE 1/0/2. By default, LLDP is enabled on ports.
[SwitchA] interface fortygige 1/0/2
[SwitchA-FortyGigE1/0/2] lldp enable
# Set the LLDP operating mode to Rx on FortyGigE 1/0/2.
[SwitchA-FortyGigE1/0/2] lldp admin-status rx
[SwitchA-FortyGigE1/0/2] quit
2. Configure Switch B:
# Enable LLDP globally.
<SwitchB> system-view
[SwitchB] lldp global enable
# Enable LLDP on FortyGigE 1/0/1. By default, LLDP is enabled on ports.
[SwitchB] interface fortygige 1/0/1
[SwitchB-FortyGigE1/0/1] lldp enable
# Set the LLDP operating mode to Tx on FortyGigE 1/0/1.
[SwitchB-FortyGigE1/0/1] lldp admin-status tx
[SwitchB-FortyGigE1/0/1] quit
Verifying the configuration
# Verify that:
· FortyGigE 1/0/1 of Switch A connects to an MED device.
· FortyGigE 1/0/2 of Switch A connects to a non-MED device.
· Both ports operate in Rx mode, and they can receive LLDP frames but cannot send LLDP frames.
[SwitchA] display lldp status
Global status of LLDP: Enable
Bridge mode of LLDP: customer-bridge
The current number of LLDP neighbors: 2
The current number of CDP neighbors: 0
LLDP neighbor information last changed time: 0 days, 0 hours, 4 minutes, 40 seconds
Transmit interval : 30s
Fast transmit interval : 1s
Transmit credit max : 5
Hold multiplier : 4
Reinit delay : 2s
Trap interval : 30s
Fast start times : 4
LLDP status information of port 1 [FortyGigE1/0/1]:
LLDP agent nearest-bridge:
Port status of LLDP : Enable
Admin status : RX_Only
Trap flag : No
MED trap flag : No
Polling interval : 0s
Number of LLDP neighbors : 1
Number of MED neighbors : 1
Number of CDP neighbors : 0
Number of sent optional TLV : 21
Number of received unknown TLV : 0
LLDP agent nearest-customer:
Port status of LLDP : Enable
Admin status : Disable
Trap flag : No
MED trap flag : No
Polling interval : 0s
Number of LLDP neighbors : 0
Number of MED neighbors : 0
Number of CDP neighbors : 0
Number of sent optional TLV : 16
Number of received unknown TLV : 0
LLDP status information of port 2 [FortyGigE1/0/2]:
LLDP agent nearest-bridge:
Port status of LLDP : Enable
Admin status : RX_Only
Trap flag : No
MED trap flag : No
Polling interval : 0s
Number of LLDP neighbors : 1
Number of MED neighbors : 0
Number of CDP neighbors : 0
Number of sent optional TLV : 21
Number of received unknown TLV : 3
LLDP agent nearest-nontpmr:
Port status of LLDP : Enable
Admin status : Disable
Trap flag : No
MED trap flag : No
Polling interval : 0s
Number of LLDP neighbors : 0
Number of MED neighbors : 0
Number of CDP neighbors : 0
Number of sent optional TLV : 1
Number of received unknown TLV : 0
LLDP agent nearest-customer:
Port status of LLDP : Enable
Admin status : Disable
Trap flag : No
MED trap flag : No
Polling interval : 0s
Number of LLDP neighbors : 0
Number of MED neighbors : 0
Number of CDP neighbors : 0
Number of sent optional TLV : 16
Number of received unknown TLV : 0
# Remove the link between Switch A and Switch B.
# Verify that FortyGigE 1/0/2 of Switch A does not connect to any neighboring devices.
[SwitchA] display lldp status
Global status of LLDP: Enable
The current number of LLDP neighbors: 1
The current number of CDP neighbors: 0
LLDP neighbor information last changed time: 0 days, 0 hours, 5 minutes, 20 seconds
Transmit interval : 30s
Fast transmit interval : 1s
Transmit credit max : 5
Hold multiplier : 4
Reinit delay : 2s
Trap interval : 30s
Fast start times : 4
LLDP status information of port 1 [FortyGigE1/0/1]:
LLDP agent nearest-bridge:
Port status of LLDP : Enable
Admin status : RX_Only
Trap flag : No
MED trap flag : No
Polling interval : 0s
Number of LLDP neighbors : 1
Number of MED neighbors : 1
Number of CDP neighbors : 0
Number of sent optional TLV : 0
Number of received unknown TLV : 5
LLDP agent nearest-nontpmr:
Port status of LLDP : Enable
Admin status : Disable
Trap flag : No
MED trap flag : No
Polling interval : 0s
Number of LLDP neighbors : 0
Number of MED neighbors : 0
Number of CDP neighbors : 0
Number of sent optional TLV : 1
Number of received unknown TLV : 0
LLDP status information of port 2 [FortyGigE1/0/2]:
LLDP agent nearest-bridge:
Port status of LLDP : Enable
Admin status : RX_Only
Trap flag : No
MED trap flag : No
Polling interval : 0s
Number of LLDP neighbors : 0
Number of MED neighbors : 0
Number of CDP neighbors : 0
Number of sent optional TLV : 0
Number of received unknown TLV : 0
LLDP agent nearest-nontpmr:
Port status of LLDP : Enable
Admin status : Disable
Trap flag : No
MED trap flag : No
Polling interval : 0s
Number of LLDP neighbors : 0
Number of MED neighbors : 0
Number of CDP neighbors : 0
Number of sent optional TLV : 1
Number of received unknown TLV : 0
LLDP agent nearest-customer:
Port status of LLDP : Enable
Admin status : Disable
Trap flag : No
MED trap flag : No
Polling interval : 0s
Number of LLDP neighbors : 0
Number of MED neighbors : 0
Number of CDP neighbors : 0
Number of sent optional TLV : 16
Number of received unknown TLV : 0
DCBX configuration example
Network requirements
As shown in Figure 52, in a data center network, interface Ten-GigabitEthernet 1/0/1 of the access switch (Switch A) connects to the FCoE adapter of the data center server (DC server).
Configure Switch A to implement lossless FCoE and FIP frame transmission to DC server.
|
|
NOTE: In this example, both Switch A and the DC server support DCBX Rev 1.01. |

Configuration procedure
1. Enable LLDP and DCBX TLV advertising:
# Enable LLDP globally.
<SwitchA> system-view
[SwitchA] lldp global enable
# Enable LLDP and DCBX TLV advertising on interface Ten-GigabitEthernet 1/0/1.
[SwitchA] interface ten-gigabitethernet 1/0/1
[SwitchA-Ten-GigabitEthernet1/0/1] lldp enable
[SwitchA-Ten-GigabitEthernet1/0/1] lldp tlv-enable dot1-tlv dcbx
2. Configure the DCBX version as Rev. 1.01 on interface Ten-GigabitEthernet 1/0/1.
[SwitchA-Ten-GigabitEthernet1/0/1] dcbx version rev101
[SwitchA-Ten-GigabitEthernet1/0/1] quit
3. Configure APP parameters:
# Create Ethernet frame header ACL 4000.
[SwitchA] acl number 4000
# Configure ACL 4000 to permit FCoE frames (protocol number is 0x8906) and FIP frames (protocol number is 0x8914) to pass through.
[SwitchA-acl-ethernetframe-4000] rule permit type 8906 ffff
[SwitchA-acl-ethernetframe-4000] rule permit type 8914 ffff
[SwitchA-acl-ethernetframe-4000] quit
# Create a class named app_c, specify the operator of the class as OR, and use ACL 4000 as the match criterion of the class.
[SwitchA] traffic classifier app_c operator or
[SwitchA-classifier-app_c] if-match acl 4000
[SwitchA-classifier-app_c] quit
# Create a traffic behavior named app_b, and configure the traffic behavior to mark packets with 802.1p priority value 3.
[SwitchA] traffic behavior app_b
[SwitchA-behavior-app_b] remark dot1p 3
[SwitchA-behavior-app_b] quit
# Create a QoS policy named plcy, associate class app_c with traffic behavior app_b in the QoS policy, and apply the association to DCBX.
[SwitchA] qos policy plcy
[SwitchA-qospolicy-plcy] classifier app_c behavior app_b mode dcbx
[SwitchA-qospolicy-plcy] quit
# Apply the policy named plcy to the outgoing traffic of interface Ten-GigabitEthernet 1/0/1.
[SwitchA] interface ten-gigabitethernet 1/0/1
[SwitchA-Ten-GigabitEthernet1/0/1] qos apply policy plcy outbound
[SwitchA-Ten-GigabitEthernet1/0/1] quit
4. Configure ETS parameters:
# Configure the 802.1p-to-local priority mapping table to map 802.1p priority value 3 to local precedence 3. (This is the default mapping table. You can modify this configuration as needed.)
[SwitchA] qos map-table dot1p-lp
[SwitchA-maptbl-dot1p-lp] import 3 export 3
[SwitchA-maptbl-dot1p-lp] quit
# Configure interface Ten-GigabitEthernet 1/0/1 to trust the 802.1p priority carried in packets.
[SwitchA] interface ten-gigabitethernet 1/0/1
[SwitchA-Ten-GigabitEthernet1/0/1] qos trust dot1p
# Enable byte-count WRR queuing on interface Ten-GigabitEthernet 1/0/1, and configure queue 3 on the interface to use strict priority queuing.
[SwitchA-Ten-GigabitEthernet1/0/1] qos wrr byte-count
[SwitchA-Ten-GigabitEthernet1/0/1] qos wrr 3 group sp
5. Configure PFC:
# Enable PFC in auto mode on interface Ten-GigabitEthernet 1/0/1.
[SwitchA-Ten-GigabitEthernet1/0/1] priority-flow-control auto
# Enable PFC for 802.1 priority 3.
[SwitchA-Ten-GigabitEthernet1/0/1] priority-flow-control no-drop dot1p 3
Verifying the configuration
# Display the data exchange result on the DC server through the software interface. This example uses the data exchange result for a QLogic adapter on the DC server.
------------------------------------------------------
DCBX Parameters Details for CNA Instance 0 - QLE8142
------------------------------------------------------
Mon May 17 10:00:50 2010
DCBX TLV (Type-Length-Value) Data
=================================
DCBX Parameter Type and Length
DCBX Parameter Length: 13
DCBX Parameter Type: 2
DCBX Parameter Information
Parameter Type: Current
Pad Byte Present: Yes
DCBX Parameter Valid: Yes
Reserved: 0
DCBX Parameter Data
Priority Group ID of Priority 1: 0
Priority Group ID of Priority 0: 2
Priority Group ID of Priority 3: 15
Priority Group ID of Priority 2: 1
Priority Group ID of Priority 5: 5
Priority Group ID of Priority 4: 4
Priority Group ID of Priority 7: 7
Priority Group ID of Priority 6: 6
Priority Group 0 Percentage: 2
Priority Group 1 Percentage: 4
Priority Group 2 Percentage: 6
Priority Group 3 Percentage: 0
Priority Group 4 Percentage: 10
Priority Group 5 Percentage: 18
Priority Group 6 Percentage: 27
Priority Group 7 Percentage: 31
Number of Traffic Classes Supported: 8
DCBX Parameter Information
Parameter Type: Remote
Pad Byte Present: Yes
DCBX Parameter Valid: Yes
Reserved: 0
DCBX Parameter Data
Priority Group ID of Priority 1: 0
Priority Group ID of Priority 0: 2
Priority Group ID of Priority 3: 15
Priority Group ID of Priority 2: 1
Priority Group ID of Priority 5: 5
Priority Group ID of Priority 4: 4
Priority Group ID of Priority 7: 7
Priority Group ID of Priority 6: 6
Priority Group 0 Percentage: 2
Priority Group 1 Percentage: 4
Priority Group 2 Percentage: 6
Priority Group 3 Percentage: 0
Priority Group 4 Percentage: 10
Priority Group 5 Percentage: 18
Priority Group 6 Percentage: 27
Priority Group 7 Percentage: 31
Number of Traffic Classes Supported: 8
DCBX Parameter Information
Parameter Type: Local
Pad Byte Present: Yes
DCBX Parameter Valid: Yes
Reserved: 0
DCBX Parameter Data
Priority Group ID of Priority 1: 0
Priority Group ID of Priority 0: 0
Priority Group ID of Priority 3: 1
Priority Group ID of Priority 2: 0
Priority Group ID of Priority 5: 0
Priority Group ID of Priority 4: 0
Priority Group ID of Priority 7: 0
Priority Group ID of Priority 6: 0
Priority Group 0 Percentage: 50
Priority Group 1 Percentage: 50
Priority Group 2 Percentage: 0
Priority Group 3 Percentage: 0
Priority Group 4 Percentage: 0
Priority Group 5 Percentage: 0
Priority Group 6 Percentage: 0
Priority Group 7 Percentage: 0
Number of Traffic Classes Supported: 2
The output shows that the DC server will use SP queuing (priority group ID 15) for 802.1p priority 3.
DCBX Parameter Type and Length
DCBX Parameter Length: 2
DCBX Parameter Type: 3
DCBX Parameter Information
Parameter Type: Current
Pad Byte Present: No
DCBX Parameter Valid: Yes
Reserved: 0
DCBX Parameter Data
PFC Enabled on Priority 0: No
PFC Enabled on Priority 1: No
PFC Enabled on Priority 2: No
PFC Enabled on Priority 3: Yes
PFC Enabled on Priority 4: No
PFC Enabled on Priority 5: No
PFC Enabled on Priority 6: No
PFC Enabled on Priority 7: No
Number of Traffic Classes Supported: 6
DCBX Parameter Information
Parameter Type: Remote
Pad Byte Present: No
DCBX Parameter Valid: Yes
Reserved: 0
DCBX Parameter Data
PFC Enabled on Priority 0: No
PFC Enabled on Priority 1: No
PFC Enabled on Priority 2: No
PFC Enabled on Priority 3: Yes
PFC Enabled on Priority 4: No
PFC Enabled on Priority 5: No
PFC Enabled on Priority 6: No
PFC Enabled on Priority 7: No
Number of Traffic Classes Supported: 6
DCBX Parameter Information
Parameter Type: Local
Pad Byte Present: No
DCBX Parameter Valid: Yes
Reserved: 0
DCBX Parameter Data
PFC Enabled on Priority 0: No
PFC Enabled on Priority 1: No
PFC Enabled on Priority 2: No
PFC Enabled on Priority 3: Yes
PFC Enabled on Priority 4: No
PFC Enabled on Priority 5: No
PFC Enabled on Priority 6: No
PFC Enabled on Priority 7: No
Number of Traffic Classes Supported: 1
The output shows that the DC server will use PFC for 802.1p priority 3.
Numerics
0\
2 VLAN mappingapplication scenario, 126
2 VLAN mappingconfiguration, 131
2 VLAN mappingimplementation, 128
1\
1 VLAN mappingapplication scenario, 124
1 VLAN mappingconfiguration, 130, 134
1 VLAN mappingimplementation, 126, 127
2 VLAN mappingapplication scenario, 125
2 VLAN mappingconfiguration, 130, 136
2 VLAN mappingimplementation, 126, 127
2\
2 VLAN mappingapplication scenario, 125
2 VLAN mappingconfiguration, 132, 136
2 VLAN mappingimplementation, 126, 128
3 VLAN mappingapplication scenario, 126
3 VLAN mappingconfiguration, 133
3 VLAN mappingimplementation, 129
802.x
802.1 LLDPDU TLV types, 142
802.1p-to-local priority mapping, 158
802.3 LLDPDU TLV types, 142
LAN switching LLDP PFC 802.1p priority, 159
A
accessing
port-based VLAN access port, 118
port-based VLAN access port (in interface view), 119
port-based VLAN access port (in VLAN view), 119
ACL
LAN switching LLDP APP parameter, 156
LLDP DCBX version, 155
action
loop detection block, 107
loop detection no-learning protection, 107
loop detection protection action setting, 108
loop detection shutdown protection, 107
adding
MAC address table blackhole entry, 24
MAC address table multiport unicast entry, 24
address
MAC address learning disable, 25
MAC address table address synchronization, 26
MAC Information queue length, 31
advertising
LAN switching LLDP+DCBX TLV advertisement, 155
LLDP advertisable TLV, 149
aggregating
link. See Ethernet link aggregation
aging
MAC address table timer, 26
STP max age timer, 85
algorithm
STP calculation, 70
alternate port (MST), 77
APP parameter (LLDP), 156
assigning
port to isolation group (multiple), 65
port-based VLAN access port, 118
port-based VLAN access port (in interface view), 119
port-based VLAN access port (in VLAN view), 119
port-based VLAN hybrid port, 120
port-based VLAN trunk port, 119
attribute
Ethernet link aggregation attribute configuration, 35
auto
Ethernet interface autonegotiation mode, 3
interface auto power-down (Ethernet), 9
loop detection port status auto recovery, 107
AutoMDIX mode (Ethernet interface), 13
B
backup port (MST), 77
bandwidth
Ethernet link aggregate interface (expected bandwidth), 46
LAN switching LLDP ETS parameters, 158
basic management LLDPDU TLV types, 142
Ethernet link aggregation group BFD, 47
bidirectional
forwarding detection. Use BFD
blackhole entry
MAC address table, 21, 24
block action (loop detection), 107
boundary port (MST), 77
BPDU
MST region max hops, 84
STP BPDU forwarding, 73
STP BPDU guard, 98
STP hello time, 85
STP max age timer, 85
STP TC-BPDU guard, 100
STP TC-BPDU transmission restriction, 100
transmission rate configuration, 87
bridge
LLDP agent customer bridge, 140
LLDP agent nearest bridge, 140
LLDP agent non-TPMR bridge, 140
MST common root bridge, 77, 77
MST regional root, 77
MSTP root bridge configuration, 83
MSTP secondary root bridge configuration, 83
RSTP root bridge configuration, 83
RSTP secondary root bridge configuration, 83
STP designated bridge, 69
STP loop guard, 99
STP root bridge, 69
STP root bridge configuration, 83
STP root guard, 98
STP secondary root bridge configuration, 83
bulk
interface configuration, 19
interface configuration display, 20
C
cable
interface cable connection (Layer 2 Ethernet), 14
calculating
MSTI calculation, 79
MSTP CIST calculation, 79
STP algorithm, 70
STP port path cost calculation standard, 88
STP timeout factor, 86
CDP
LLDP CDP compatibility, 153
checking
STP mCheck, 93
STP mCheck (global), 93
STP mCheck (interface view), 93
STP No Agreement Check, 96, 97
choosing
Ethernet link aggregation reference port, 36, 38
Cisco
LLDP CDP compatibility, 153
CIST
calculation, 79
network device connection, 77
STP max age timer, 85
common root bridge, 77
configuring
Ethernet aggregate interface, 44
Ethernet interface, 1
Ethernet interface basic settings, 3
Ethernet interface common settings, 1
Ethernet interface generic flow control, 6
Ethernet interface jumbo frame support, 5
Ethernet interface link mode, 4
Ethernet interface PFC, 7
Ethernet interface physical state change suppression, 5
Ethernet link aggregation, 34, 40, 54
Ethernet link aggregation edge aggregate interface, 47
Ethernet link aggregation group, 41
Ethernet link aggregation group (dynamic), 43
Ethernet link aggregation group (static), 42
Ethernet link aggregation group BFD, 47
Ethernet link aggregation group load sharing mode, 49
Ethernet link aggregation load sharing, 49
interface (inloopback), 17
interface (loopback), 16
interface (null), 16
LAN switching LLDP 802.1p-to-local priority mapping, 158
LAN switching LLDP APP parameter, 156
LAN switching LLDP DCBX, 154, 166
LAN switching LLDP ETS parameter, 158
LAN switching LLDP group-based WRR queuing, 159
LAN switching LLDP PFC parameter, 159
Layer 2 Ethernet interface, 10
Layer 2 Ethernet interface storm control, 10
Layer 2 Ethernet interface storm suppression, 10
Layer 2 Ethernet link aggregation (dynamic), 55
Layer 2 Ethernet link aggregation (static), 54
Layer 2 Ethernet link aggregation group (dynamic), 43
Layer 2 Ethernet link aggregation group (static), 42
Layer 2 Ethernet link aggregation load sharing, 57
Layer 3 Ethernet interface, 14
Layer 3 Ethernet link aggregation (dynamic), 61
Layer 3 Ethernet link aggregation (static), 60
Layer 3 Ethernet link aggregation edge aggregate interface, 62
Layer 3 Ethernet link aggregation group (dynamic), 44
Layer 3 Ethernet link aggregation group (static), 42
Layer 3 Ethernet subinterface, 14
Layer 3 Ethernet subinterface basic settings, 4
LLDP, 140, 146
LLDP advertisable TLVs, 149
LLDP basics, 146, 161
LLDP bridge mode, 147
LLDP CDP compatibility, 153
LLDP DCBX version, 155
LLDP management address, 151
LLDP management address encoding format, 151
LLDP trapping, 160
LLDP-MED trapping, 160
loop detection, 106, 108, 110
MAC address table, 21, 22, 29
MAC address table dynamic aging timer, 26
MAC address table entry, 22
MAC change notification interval, 31
MAC Information, 30, 31
MAC Information mode, 30
MAC Information queue length, 31
management Ethernet interface, 1
MST region, 82
MST region max hops, 84
MSTP, 68, 79, 102
MSTP device priority, 84
MSTP root bridge, 83
MSTP root bridge device, 84
MSTP secondary root bridge, 83
MSTP secondary root bridge device, 84
port isolation, 65
port isolation (on LAN), 66
RSTP, 68, 79, 102
RSTP device priority, 84
RSTP root bridge, 83
RSTP root bridge device, 84
RSTP secondary root bridge, 83
RSTP secondary root bridge device, 84
STP, 68, 79, 102
STP BPDU transmission rate, 87
STP device priority, 84
STP Digest Snooping, 94, 95
STP edge port, 87
STP No Agreement Check, 96, 97
STP port link type, 91
STP port mode, 92
STP port path cost, 88, 90
STP port priority, 90
STP port role restriction, 99
STP protection features, 98
STP root bridge, 83
STP root bridge device, 84
STP secondary root bridge, 83
STP secondary root bridge device, 84
STP switched network diameter, 85
STP TC-BPDU transmission restriction, 100
STP timeout factor, 86
STP timer, 85
VLAN (port-based), 117, 121
VLAN basic settings, 114
VLAN interface basic settings, 115
VLAN mapping, 124, 129, 134
VLAN mapping (0\2), 131
VLAN mapping (1\1), 130, 134
VLAN mapping (1\2), 130, 136
VLAN mapping (2\2), 132, 136
VLAN mapping (2\3), 133
connecting
interface cable connection (Layer 2 Ethernet), 14
Converged Enhanced Ethernet. Use CEE
cost
STP path cost, 69
STP port path cost calculation standard, 88
STP port path cost configuration, 88, 90
CST
MST region connection, 76
customer
LLDP customer bridge mode, 147
CVLAN
VLAN mapping configuration, 124, 129, 134
VLAN mapping implementation, 126
D
Data Center
Bridging Exchange Protocol. Use DCBX
Ethernet. Use DCE
configuration, 154, 166
LAN switching LLDP APP parameter configuration, 156
LAN switching LLDP ETS parameter configuration, 158
LAN switching LLDP PFC parameter configuration, 159
LAN switching LLDP+DCBX TLV advertisement, 155
LLDP DCBX version configuration, 155
DCBX version (LLDP), 155
default
Ethernet link aggregate interface default settings, 49
designated
MST port, 77
STP bridge, 69
STP port, 69
detecting
Ethernet link aggregation group BFD, 47
device
Ethernet interface configuration, 1
LAN switching LLDP DCBX configuration, 154, 166, 166
LLDP basic configuration, 146, 161
LLDP CDP compatibility, 153
LLDP configuration, 140, 146
LLDP parameters, 151
loop protection actions, 107
MSTP implementation, 79
MSTP priority, 84
MSTP root bridge configuration, 84
MSTP secondary root bridge configuration, 84
RSTP priority, 84
RSTP root bridge configuration, 84
RSTP secondary root bridge configuration, 84
STP BPDU guard, 98
STP Digest Snooping, 94, 95
STP loop guard, 99
STP No Agreement Check, 96, 97
STP port role restriction, 99
STP priority, 84
STP protection features, 98
STP root bridge configuration, 84
STP root guard, 98
STP secondary root bridge configuration, 84
STP TC-BPDU guard, 100
STP TC-BPDU transmission restriction, 100
Digest Snooping (STP), 94, 95
directing
Ethernet link aggregation traffic redirection, 51
disabling
MAC address learning, 25
discarding
MST discarding port state, 78
displaying
bulk interface configuration, 20
Ethernet interface, 14
Ethernet link aggregation, 53
interface, 17
LLDP, 161
loop detection, 110
MAC address table, 28
MSTP, 101
port isolation, 65
RSTP, 101
STP, 101
VLAN, 121
VLAN mapping, 134
dot1d-1998 (STP port path cost calculation), 88
dot1s (STP port mode), 92
dot1t (STP port path cost calculation), 88
dynamic
Ethernet link aggregation dynamic mode, 37
Ethernet link aggregation edge aggregate interface, 40
Ethernet link aggregation group, 43
Ethernet link aggregation mode, 35
Layer 2 Ethernet link aggregation, 55
Layer 2 Ethernet link aggregation group (dynamic), 43
Layer 3 Ethernet link aggregation, 61
Layer 3 Ethernet link aggregation edge aggregate interface, 62
Layer 3 Ethernet link aggregation group (dynamic), 44
link aggregation process, 38
MAC address table dynamic aging timer, 26
MAC address table entry, 21
E
edge port
MST, 77
STP, 87
EEE energy saving, 9
enabling
Ethernet link aggregation traffic redirection, 51
interface auto power-down (Ethernet), 9
interface EEE energy saving, 9
interface energy-saving features (Ethernet), 9
LAN switching LLDP+DCBX TLV advertisement, 155
LLDP, 146
LLDP polling, 148
loop detection (global), 108
loop detection (port-specific), 108
MAC address learning at ingress, 28
MAC address synchronization, 26
MAC Information, 30
STP BPDU guard, 98
STP feature, 93
STP loop guard, 99
STP port state transition information output, 92
STP root guard, 98
STP TC-BPDU guard, 100
encapsulating
LLDP frame encapsulated in Ethernet II, 141
LLDP frame encapsulated in SNAP format, 141
LLDP frame encapsulation format, 152
VLAN frame encapsulation, 113
Energy Efficient Ethernet. See EEE
energy-saving features, 9
Ethernet
interface. See Ethernet interface
LAN switching LLDP APP parameters, 156
LAN switching LLDP DCBX configuration, 154, 166
LAN switching LLDP ETS parameters, 158
LAN switching LLDP group-based WRR queuing, 159
LAN switching LLDP PFC parameters, 159
LAN switching LLDP+DCBX TLV advertisement, 155
link aggregation. See Ethernet link aggregation
LLDP DCBX version, 155
LLDP frame encapsulated in Ethernet II, 141
LLDP trapping, 160
LLDP-MED trapping, 160
loop detection configuration, 106, 110
MAC address table configuration, 21, 22, 29
MAC Information configuration, 30, 31
port isolation configuration, 65
port isolation configuration (on LAN), 66
port-based VLAN access port assignment, 118
port-based VLAN access port assignment (in interface view), 119
port-based VLAN access port assignment (in VLAN view), 119
port-based VLAN hybrid port assignment, 120
port-based VLAN trunk port assignment, 119
reserving VLAN interface resource, 116
reserving VLAN interface resource (global type), 116
reserving VLAN interface resource (local type), 116
VLAN basic configuration, 114
VLAN configuration, 113
VLAN frame encapsulation, 113
VLAN interface basic configuration, 115
VLAN port-based configuration, 117, 121
auto power-down enable, 9
basic settings configuration, 3
common settings configuration, 1
configuration, 1
configuring management Ethernet interface, 1
displaying, 14
EEE energy saving enable, 9
energy-saving features, 9
generic flow control, 6
jumbo frame support configuration, 5
link mode, 4
maintaining, 14
naming convention, 1
PFC configuration, 7
physical state change suppression, 5
splitting and combining, 2
aggregate group min/max number Selected ports, 46
aggregate interface, 34
aggregate interface (description), 44
aggregate interface configuration, 44
aggregate interface default settings, 49
aggregate interface shutdown, 48
aggregation group, 34
basic concepts, 34
capability, 52
configuration, 34, 40, 54
configuration types, 35
displaying, 53
dynamic mode, 37
dynamic process, 38
edge aggregate interface, 40, 47
group configuration, 41
group configuration (dynamic), 43
group configuration (static), 42
group load sharing mode, 49
interface configuration (expected bandwidth), 46
LACP, 37
Layer 2 aggregate interface (ignored VLAN), 45, 45
Layer 2 aggregation (dynamic), 55
Layer 2 aggregation (static), 54
Layer 2 aggregation load sharing, 57
Layer 2 group (dynamic), 43
Layer 2 group (static), 42
Layer 3 aggregate interface configuration (MTU), 45
Layer 3 aggregate subinterface configuration (MTU), 45
Layer 3 aggregation (dynamic), 61
Layer 3 aggregation (static), 60
Layer 3 edge aggregate interface, 62
Layer 3 group (dynamic), 44
Layer 3 group (static), 42
load sharing configuration, 49
load sharing mode, 40
local-first load sharing, 50
maintaining, 53
member port, 34
member port state, 34, 36, 39
modes, 35
operational key, 35
reference port, 38
reference port choice, 36
static mode, 36
traffic redirection, 51
traffic redirection restrictions, 52
Ethernet link aggregation group
BFD configuration, 47
ETS parameter (LLDP), 158
F
FCoE
LAN switching LLDP APP parameters, 156
LAN switching LLDP DCBX configuration, 166
LLDP DCBX version, 155
flow control
Ethernet interface generic flow control, 6
Ethernet interface PFC, 7
forcing
interface fiber port (Layer 2 Ethernet), 12
format
LLDP frame encapsulated in Ethernet II, 141
LLDP frame encapsulated in SNAP format, 141
LLDP frame encapsulation format, 152
LLDP management address encoding format, 151
forwarding
MST forwarding port state, 78
STP BPDU forwarding, 73
STP forward delay timer, 74, 85
frame
Ethernet interface jumbo frame support, 5
loop detection (Ethernet frame header), 106
loop detection (inner frame header), 106
loop detection interval, 107
MAC address learning, 21
MAC address table blackhole entry, 24
MAC address table configuration, 21, 22, 29
MAC address table entry configuration, 22
MAC address table multiport unicast entry, 24
MAC Information configuration, 30, 31
port-based VLAN frame handling, 118
VLAN frame encapsulation, 113
full-duplex mode (Ethernet interface), 3
G
generic flow control (Ethernet interface), 6
group
Ethernet link aggregate group min/max number Selected ports, 46
Ethernet link aggregation capability, 52
Ethernet link aggregation group, 34
Ethernet link aggregation group (dynamic), 43
Ethernet link aggregation group (static), 42
Ethernet link aggregation group configuration, 41
Ethernet link aggregation LACP, 37
Ethernet link aggregation load sharing, 49
Ethernet link aggregation load sharing mode, 40, 49
Ethernet link aggregation member port state, 34
Layer 2 Ethernet link aggregation group (dynamic), 43
Layer 2 Ethernet link aggregation group (static), 42
Layer 3 Ethernet link aggregation group (dynamic), 44
Layer 3 Ethernet link aggregation group (static), 42
H
half-duplex mode (Ethernet interface), 3
hello
STP timer, 74, 85
hybrid port
port-based VLAN assignment, 120
I
ignored VLAN
Layer 2 aggregate interface, 45
implementing
0\2 VLAN mapping, 128
1\1 VLAN mapping, 126, 127
1\2 VLAN mapping, 126, 127
2\2 VLAN mapping, 126, 128
2\3 VLAN mapping, 129
MSTP device implementation, 79
ingress
MAC address learning at ingress, 28
inloopback interface
configuration, 17
display, 17
maintain, 17
interface
bulk configuration, 19
configuration (inloopback), 16, 17
configuration (loopback), 16, 16
configuration (null), 16, 16
Ethernet aggregate interface, 44
Ethernet aggregate interface (description), 44
Ethernet link aggregate interface default settings, 49
Ethernet link aggregate interface shutdown, 48
Ethernet link aggregation edge aggregate interface, 40, 47
Layer 2 Ethernet aggregate interface (ignored VLAN), 45
Layer 3 aggregate interface configuration (MTU), 45
Layer 3 aggregate subinterface configuration (MTU), 45
interval
loop detection, 107, 109
MAC Information change send interval, 31
isolating
ports. See port isolation
IST
MST region, 77
J
jumbo frame support (Ethernet interface), 5
K
key
Ethernet link aggregation operational key, 35
L
LACP
Ethernet link aggregation, 37
LAN
port isolation configuration, 66
reserving VLAN interface resource, 116
reserving VLAN interface resource (global type), 116
reserving VLAN interface resource (local type), 116
VLAN basic configuration, 114
VLAN configuration, 113
VLAN interface basic configuration, 115
VLAN port-based configuration, 117, 121
LAN switching
Ethernet link aggregation basic concepts, 34
Ethernet link aggregation configuration, 54
Ethernet link aggregation dynamic mode, 37
Ethernet link aggregation LACP, 37
Ethernet link aggregation load sharing, 49
Ethernet link aggregation load sharing mode, 40
Ethernet link aggregation static mode, 36
Ethernet link aggregation traffic redirection, 51
Ethernet link aggregation traffic redirection restrictions, 52
LLDP DCBX configuration, 166
Layer 2
Ethernet link aggregation (dynamic), 55
Ethernet link aggregation (static), 54
Ethernet link aggregation configuration, 54
Ethernet link aggregation group (dynamic), 43
Ethernet link aggregation group (static), 42
Ethernet link aggregation group load sharing mode, 49
Ethernet link aggregation load sharing, 49, 57
Ethernet link aggregation load sharing mode, 40
Ethernet link aggregation local-first load sharing, 50
LAN switching LLDP group-based WRR queuing, 159
LAN switching LLDP+DCBX TLV advertisement, 155
LLDP basic configuration, 161
LLDP trapping, 160
LLDP-MED trapping, 160
loop detection configuration, 106, 108, 110
port isolation configuration, 65
port isolation configuration (on LAN), 66
port-based VLAN access port assignment, 118
port-based VLAN access port assignment (in interface view), 119
port-based VLAN access port assignment (in VLAN view), 119
port-based VLAN hybrid port assignment, 120
port-based VLAN trunk port assignment, 119
reserving VLAN interface resource, 116
reserving VLAN interface resource (global type), 116
reserving VLAN interface resource (local type), 116
VLAN basic configuration, 114
VLAN configuration, 113
VLAN interface basic configuration, 115
VLAN port-based configuration, 117, 121
Layer 2 Ethernet interface
cable connection, 14
configuration, 1, 10
fiber port, 12
MDIX mode, 13
storm control configuration, 10
storm suppression configuration, 10
Layer 2 LAN switching
Ethernet aggregate interface, 44
Ethernet aggregate interface (description), 44
Ethernet link aggregate group min/max number Selected ports, 46
Ethernet link aggregate interface (expected bandwidth), 46
Ethernet link aggregate interface default settings, 49
Ethernet link aggregate interface shutdown, 48
Ethernet link aggregation configuration, 34, 40
Ethernet link aggregation edge aggregate interface, 40, 47
Ethernet link aggregation group, 41
Ethernet link aggregation group (dynamic), 43
Ethernet link aggregation group (static), 42
VLAN mapping configuration, 124, 129, 134
VLAN mapping configuration (0\2), 131
VLAN mapping configuration (1\1), 130, 134
VLAN mapping configuration (1\2), 130, 136
VLAN mapping configuration (2\2), 132, 136
VLAN mapping configuration (2\3), 133
Layer 3
aggregate interface configuration (MTU), 45
aggregate subinterface configuration (MTU), 45
Ethernet aggregate interface, 44
Ethernet aggregate interface (description), 44
Ethernet link aggregate group min/max number Selected ports, 46
Ethernet link aggregate interface (expected bandwidth), 46
Ethernet link aggregate interface default settings, 49
Ethernet link aggregate interface shutdown, 48
Ethernet link aggregation (dynamic), 61
Ethernet link aggregation (static), 60
Ethernet link aggregation configuration, 34, 40
Ethernet link aggregation edge aggregate interface, 40, 47, 62
Ethernet link aggregation group, 41
Ethernet link aggregation group (dynamic), 43, 44
Ethernet link aggregation group (static), 42, 42
Ethernet link aggregation traffic redirection, 51
LLDP basic configuration, 161
LLDP trapping, 160
LLDP-MED trapping, 160
port-based VLAN access port assignment, 118
port-based VLAN access port assignment (in interface view), 119
port-based VLAN access port assignment (in VLAN view), 119
port-based VLAN hybrid port assignment, 120
port-based VLAN trunk port assignment, 119
reserving VLAN interface resource, 116
reserving VLAN interface resource (global type), 116
reserving VLAN interface resource (local type), 116
VLAN interface basic configuration, 115
VLAN port-based configuration, 117, 121
Layer 3 Ethernet interface
configuration, 1, 14
MTU setting, 14
Layer 3 Ethernet subinterface
basic settings configuration, 4
configuration, 14
MTU setting, 14
learning
loop detection no-learning action, 107
MAC address, 21
MAC address learning disable, 25
MST learning port state, 78
legacy
STP port mode, 92
STP port path cost calculation, 88
link
aggregation. See Ethernet link aggregation
Ethernet interface link mode, 4
Ethernet link aggregation group BFD, 47
link layer discovery protocol. See LLDP
MSTP configuration, 68, 79, 102
RSTP configuration, 68, 79, 102
STP configuration, 68, 79, 102
STP hello time, 85
STP port link type configuration, 91
802.1p-to-local priority mapping, 158
advertisable TLV configuration, 149
agent, 140
APP parameter configuration, 156
basic concepts, 140
basic configuration, 146, 161
bridge mode configuration, 147
CDP compatibility configuration, 153
configuration, 140, 146
DCBX configuration, 154, 166
DCBX version configuration, 155
displaying, 161
enable, 146
ETS parameter configuration, 158
group-based WRR queuing, 159
how it works, 145
LAN switching LLDP+DCBX TLV advertisement, 155
LLDP frame encapsulation format, 152
LLDP frame format, 141
LLDP frame management address TLV, 145
LLDP frame reception, 146
LLDP frame transmission, 145
LLDPDU TLV types, 142
LLDPDU TLVs, 142
LLDP-MED trapping configuration, 160
management address configuration, 151
management address encoding format, 151
operating mode (disable), 145, 147
operating mode (Rx), 145, 147
operating mode (Tx), 145, 147
operating mode (TxRx), 145, 147
operating mode set, 147
parameter set, 151
PFC parameter configuration, 159
polling enable, 148
protocols and standards, 146
re-initialization delay, 148
trapping configuration, 160
LLDP frame
encapsulated in Ethernet II format, 141
encapsulated in SNAP format, 141
encapsulation format, 152
LLDP basic configuration, 146, 161
LLDP configuration, 140, 146
LLDP parameters, 151
management address configuration, 151
management address encoding format, 151
management address TLV, 145
receiving, 146
transmitting, 145
LLDPDU
TLV basic management types, 142
TLV LLDP-MED types, 142
TLV organization-specific types, 142
load sharing
Ethernet link aggregation configuration, 49
Ethernet link aggregation group load sharing, 40
Ethernet link aggregation group mode, 49
Ethernet link aggregation local-first load sharing, 50
Ethernet link aggregation packet type-based load sharing, 40
Ethernet link aggregation per-flow load sharing, 40
Ethernet link aggregation per-packet load sharing, 40
Layer 2 Ethernet link aggregation configuration, 57
local
Ethernet link aggregation local-first load sharing, 50
logging
loop detection configuration, 106, 108, 110
loop
MSTP configuration, 68, 79, 102
RSTP configuration, 68, 79, 102
STP configuration, 68, 79, 102
STP loop guard, 99
loop detection
configuration, 106, 108, 110
displaying, 110
enable (global), 108
enable (port-specific), 108
interval, 107
interval setting, 109
mechanism, 106
port status auto recovery, 107
protection action setting (global), 109
protection action setting (Layer 2 aggregate interface), 109
protection action setting (Layer 2 Ethernet interface), 109
protection actions, 107
loopback interface
configuration, 16
display, 17
maintain, 17
M
MAC address
VLAN frame encapsulation, 113
MAC address learning
MAC address learning at ingress, 28
MAC address table
address learning, 21
address synchronization, 26
blackhole entry, 24
configuration, 21, 22, 29
displaying, 28
dynamic aging timer, 26
entry configuration, 22
entry creation, 21
entry types, 21
MAC address learning at ingress, 28
MAC address learning disable, 25
manual entries, 21
multiport unicast entry, 24
MAC Information
change notification interval, 31
configuration, 30, 31
enable, 30
mode configuration, 30
queue length configuration, 31
MAC relay (LLDP agent), 140
maintaining
Ethernet interface, 14
Ethernet link aggregation, 53
interface, 17
MSTP, 101
RSTP, 101
STP, 101
VLAN, 121
management address
LLDP encoding format, 151
management Ethernet interface
configuration, 1
mapping
1\2 VLAN mapping, 125
2\2 VLAN mapping, 125
MSTP VLAN-to-instance mapping table, 76
master port (MST), 77
max age timer (STP), 74
mCheck (STP), 93, 93, 93
MDI mode (Ethernet interface), 13
MDIX mode (Ethernet interface), 13
MED (LLDP-MED trapping), 160
MIB
LLDP basic configuration, 146, 161
LLDP configuration, 140, 146
mode
Ethernet interface autonegotiation, 3
Ethernet interface full-duplex, 3
Ethernet interface half-duplex, 3
Ethernet interface link mode, 4
Ethernet link aggregation dynamic, 35
Ethernet link aggregation dynamic mode, 37
Ethernet link aggregation load sharing mode, 40
Ethernet link aggregation static, 35
Ethernet link aggregation static mode, 36
interface Auto MDIX (Layer 2 Ethernet), 13
interface MDI (Layer 2 Ethernet), 13
interface MDIX (Layer 2 Ethernet), 13
LLDP customer bridge mode, 147
LLDP disable, 145, 147
LLDP Rx, 145, 147
LLDP service bridge mode, 147
LLDP Tx, 145, 147
LLDP TxRx, 145, 147
MAC Information syslog, 30
MAC Information trap, 30
modifying
MAC address table blackhole entry, 24
MAC address table multiport unicast entry, 24
MQC 802.1p-to-local priority mapping, 158
MST
CIST, 77
common root bridge, 77
CST, 76
IST, 77
MSTI, 76
port roles, 77
port states, 78
region, 76
region configuration, 82
region max hops, 84
regional root, 77
MSTI
calculation, 79
MST instance, 76
basic concepts, 75
CIST calculation, 79
configuration, 68, 79, 81, 102
device implementation, 79
device priority configuration, 84
displaying, 101
features, 75
how it works, 78
maintaining, 101
mode set, 82
MSTI calculation, 79
No Agreement Check, 96, 97
protocols and standards, 79
relationship to RSTP and STP, 74
root bridge configuration, 83
root bridge device configuration, 84
secondary root bridge configuration, 83
secondary root bridge device configuration, 84
STP basic concepts, 69
STP max age timer, 85
STP port mode configuration, 92
VLAN-to-instance mapping table, 76
MTU
Layer 3 Ethernet aggregate interface, 45
Layer 3 Ethernet aggregate subinterface, 45
multiport unicast entry (MAC address table), 21, 24
N
network
Ethernet interface basic settings configuration, 3
Ethernet interface common settings configuration, 1
Ethernet interface generic flow control, 6
Ethernet interface jumbo frame support configuration, 5
Ethernet interface link mode, 4
Ethernet interface PFC, 7
Ethernet interface physical state change suppression, 5
Ethernet interface splitting and combining, 2
Ethernet link aggregation configuration types, 35
Ethernet link aggregation dynamic mode, 37
Ethernet link aggregation edge aggregate interface, 40
Ethernet link aggregation LACP, 37
Ethernet link aggregation member port state, 36, 39
Ethernet link aggregation modes, 35
Ethernet link aggregation operational key, 35
Ethernet link aggregation reference port, 38
Ethernet link aggregation reference port choice, 36
Ethernet link aggregation static mode, 36
interface auto power-down (Ethernet), 9
interface cable connection (Layer 2 Ethernet), 14
interface configuration (inloopback), 17
interface configuration (loopback), 16
interface configuration (null), 16
interface EEE energy saving, 9
interface energy-saving features (Ethernet), 9
interface fiber port (Layer 2 Ethernet), 12
interface MDIX mode (Layer 2 Ethernet), 13
Layer 2 Ethernet interface configuration, 10
Layer 2 Ethernet interface storm control configuration, 10
Layer 2 Ethernet interface storm suppression configuration, 10
Layer 3 Ethernet interface configuration, 14
Layer 3 Ethernet interface MTU setting, 14
Layer 3 Ethernet subinterface basic settings configuration, 4
Layer 3 Ethernet subinterface configuration, 14
Layer 3 Ethernet subinterface MTU setting, 14
loop detection enable, 108
loop detection interval, 107, 109
loop detection protection action setting, 108
loop protection actions, 107
MAC address table address synchronization, 26
MAC address table blackhole entry, 24
MAC address table dynamic aging timer, 26
MAC address table entry configuration, 22
MAC address table entry types, 21
MAC address table multiport unicast entry, 24
MST region configuration, 82
MSTP mode set, 82
port-based VLAN access port assignment, 118
port-based VLAN access port assignment (in interface view), 119
port-based VLAN access port assignment (in VLAN view), 119
port-based VLAN hybrid port assignment, 120
port-based VLAN trunk port assignment, 119
reserving VLAN interface resource, 116
reserving VLAN interface resource (global type), 116
reserving VLAN interface resource (local type), 116
RSTP mode set, 82
RSTP network convergence, 74
STP algorithm calculation, 70
STP BPDU guard, 98
STP BPDU transmission rate, 87
STP designated bridge, 69
STP designated port, 69
STP Digest Snooping, 94, 95
STP edge port, 87
STP loop guard, 99
STP mode set, 82
STP No Agreement Check, 96, 97
STP path cost, 69
STP port link type, 91
STP port mode, 92
STP port path cost, 88, 90
STP port priority, 90
STP port role restriction, 99
STP port state transition, 92
STP protection features, 98
STP root bridge, 69
STP root guard, 98
STP root port, 69
STP switched network diameter, 85
STP TC-BPDU guard, 100
STP TC-BPDU transmission restriction, 100
VLAN interface basic configuration, 115
VLAN mapping 0\2 implementation, 128
VLAN mapping 1\1 implementation, 127
VLAN mapping 1\2 implementation, 127
VLAN mapping 2\2 implementation, 128
VLAN mapping 2\3 implementation, 129
VLAN mapping configuration (0\2), 131
VLAN mapping configuration (1\1), 130
VLAN mapping configuration (1\2), 130
VLAN mapping configuration (2\2), 132
VLAN mapping configuration (2\3), 133
VLAN port-based configuration, 117, 121
network management
Ethernet interface configuration, 1
Ethernet link aggregation configuration, 34, 40, 54
interface bulk configuration, 19
interface configuration (inloopback), 16
interface configuration (loopback), 16
interface configuration (null), 16
LAN switching LLDP DCBX configuration, 154, 166
Layer 2 Ethernet link aggregation (dynamic), 55
Layer 2 Ethernet link aggregation (static), 54
Layer 2 Ethernet link aggregation load sharing, 57
Layer 3 Ethernet link aggregation (dynamic), 61
Layer 3 Ethernet link aggregation (static), 60
Layer 3 Ethernet link aggregation edge aggregate interface, 62
LLDP basic concepts, 140
LLDP basic configuration, 146, 161
LLDP configuration, 140, 146
loop detection, 106
loop detection configuration, 108, 110
MAC address table configuration, 21, 22, 29
MAC Information configuration, 30, 31
MSTP configuration, 68, 79, 102
port isolation configuration, 65
port isolation configuration (on LAN), 66
RSTP configuration, 68, 79, 102
STP configuration, 68, 79, 102
VLAN basic configuration, 114
VLAN configuration, 113
VLAN mapping configuration, 124, 129, 134
VLAN mapping configuration (1\1), 134
VLAN mapping configuration (1\2), 136
VLAN mapping configuration (2\2), 136
No Agreement Check (STP), 96, 97
no-learning action (loop detection), 107
null interface
configuration, 16, 16
display, 17
maintain, 17
O
operational key (Ethernet link aggregation), 35
organization-specific LLDPDU TLV types, 142
outputting
STP port state transition information, 92
P
packet
Ethernet link aggregation group BFD, 47
Ethernet link aggregation packet type-based load sharing, 40
LAN switching LLDP DCBX configuration, 166
LAN switching LLDP PFC parameters, 159
LLDP CDP compatibility, 153
STP BPDU protocol packets, 68
STP port mode configuration, 92
STP TCN BPDU protocol packets, 68
VLAN mapping configuration, 124, 129, 134
VLAN mapping configuration (0\2), 131
VLAN mapping configuration (1\1), 130, 134
VLAN mapping configuration (1\2), 130, 136
VLAN mapping configuration (2\2), 132, 136
VLAN mapping configuration (2\3), 133
parameter
LAN switching LLDP APP configuration, 156
LAN switching LLDP ETS configuration, 158
LAN switching LLDP PFC configuration, 159
LLDP DCBX configuration, 155
STP timeout factor, 86
per-flow load sharing, 40
performing
STP mCheck, 93
STP mCheck globally, 93
STP mCheck in interface view, 93
per-packet load sharing, 40
PFC (Ethernet interface), 7
PFC priority (LLDP), 159
physical
Ethernet interface physical state change suppression, 5
polling
LLDP enable, 148
port
Ethernet aggregate interface, 44
Ethernet aggregate interface (description), 44
Ethernet link aggregate group min/max number Selected ports, 46
Ethernet link aggregate interface (expected bandwidth), 46
Ethernet link aggregate interface default settings, 49
Ethernet link aggregate interface shutdown, 48
Ethernet link aggregation capability, 52
Ethernet link aggregation configuration, 34, 40, 54
Ethernet link aggregation configuration types, 35
Ethernet link aggregation dynamic mode, 37
Ethernet link aggregation edge aggregate interface, 40, 47
Ethernet link aggregation group (dynamic), 43
Ethernet link aggregation group (static), 42
Ethernet link aggregation group configuration, 41
Ethernet link aggregation LACP, 37
Ethernet link aggregation load sharing, 49
Ethernet link aggregation load sharing mode, 40
Ethernet link aggregation local-first load sharing, 50
Ethernet link aggregation member port, 34
Ethernet link aggregation member port state, 34, 36, 39
Ethernet link aggregation modes, 35
Ethernet link aggregation operational key, 35
Ethernet link aggregation reference port, 38
Ethernet link aggregation reference port choice, 36
Ethernet link aggregation static mode, 36
Ethernet link aggregation traffic redirection, 51
group assignment (port isolation), 65
interface fiber port (Layer 2 Ethernet), 12
isolation. See port isolation
Layer 2 aggregate interface (ignored VLAN), 45
Layer 2 Ethernet link aggregation (dynamic), 55
Layer 2 Ethernet link aggregation (static), 54
Layer 2 Ethernet link aggregation group (dynamic), 43
Layer 2 Ethernet link aggregation group (static), 42
Layer 2 Ethernet link aggregation load sharing, 57
Layer 3 aggregate interface configuration (MTU), 45
Layer 3 aggregate subinterface configuration (MTU), 45
Layer 3 Ethernet link aggregation (dynamic), 61
Layer 3 Ethernet link aggregation (static), 60
Layer 3 Ethernet link aggregation edge aggregate interface, 62
Layer 3 Ethernet link aggregation group (dynamic), 44
Layer 3 Ethernet link aggregation group (static), 42
LLDP basic configuration, 146, 161
LLDP configuration, 140, 146
LLDP disable operating mode, 145, 147
LLDP enable, 146
LLDP frame encapsulation format, 152
LLDP frame reception, 146
LLDP frame transmission, 145
LLDP operating mode, 147
LLDP polling, 148
LLDP re-initialization delay, 148
LLDP Rx operating mode, 145, 147
LLDP Tx operating mode, 145, 147
LLDP TxRx operating mode, 145, 147
loop detection configuration, 106, 108, 110
loop detection interval, 107, 109
loop detection protection action setting, 108
loop detection protection actions, 107
loop detection status auto recovery, 107
MAC address learning, 21
MAC address table blackhole entry, 24
MAC address table configuration, 21, 22, 29
MAC address table entry configuration, 22
MAC address table multiport unicast entry, 24
MAC Information configuration, 30, 31
MST port roles, 77
MST port states, 78
RSTP network convergence, 74
STP BPDU guard, 98
STP BPDU transmission rate, 87
STP designated port, 69
STP edge port configuration, 87
STP forward delay timer, 85
STP loop guard, 99
STP mCheck, 93
STP mCheck (global), 93
STP mCheck (interface view), 93
STP path cost calculation standard, 88
STP path cost configuration, 88, 90
STP port link type configuration, 91
STP port mode configuration, 92
STP port priority configuration, 90
STP port role restriction, 99
STP port state transition output, 92
STP root guard, 98
STP root port, 69
STP TC-BPDU guard, 100
STP TC-BPDU transmission restriction, 100
VLAN port link type, 117
configuration, 65
configuration (on LAN), 66
displaying, 65
port assignment to group (multiple), 65
port-based VLAN
access port assignment, 118
access port assignment (in interface view), 119
access port assignment (in VLAN view), 119
configuration, 117, 121
hybrid port assignment, 120
port frame handling, 118
port link type, 117
PVID, 118
trunk port assignment, 119
power
interface auto power-down (Ethernet), 9
interface EEE energy saving, 9
interface energy-saving features (Ethernet), 9
priority
802.1p-to-local priority mapping, 158
Ethernet link aggregation LACP, 37
LAN switching LLDP PFC 802.1p priority, 159
MSTP device priority, 84
RSTP device priority, 84
STP device priority, 84
STP port priority configuration, 90
priority-based flow control. Use PFC
procedure
adding MAC address table blackhole entry, 24
adding MAC address table multiport unicast entry, 24
assigning port to isolation group (multiple), 65
assigning port-based VLAN access port, 118
assigning port-based VLAN access port (in interface view), 119
assigning port-based VLAN access port (in VLAN view), 119
assigning port-based VLAN hybrid port, 120
assigning port-based VLAN trunk port, 119
bulk configuring interfaces, 19
combining 10-GE breakout interfaces into 40-GE interface, 2
configuring Ethernet aggregate interface, 44
configuring Ethernet interface basic settings, 3
configuring Ethernet interface common settings, 1
configuring Ethernet interface generic flow control, 6
configuring Ethernet interface jumbo frame support, 5
configuring Ethernet interface link mode, 4
configuring Ethernet interface PFC, 7
configuring Ethernet interface physical state change suppression, 5
configuring Ethernet link aggregation, 40, 54
configuring Ethernet link aggregation capability, 52
configuring Ethernet link aggregation edge aggregate interface, 47
configuring Ethernet link aggregation group, 41
configuring Ethernet link aggregation group (dynamic), 43
configuring Ethernet link aggregation group (static), 42
configuring Ethernet link aggregation group BFD, 47
configuring Ethernet link aggregation group load sharing mode, 49
configuring Ethernet link aggregation load sharing, 49
configuring interface (inloopback), 17
configuring interface (loopback), 16
configuring interface (null), 16
configuring interface auto power-down (Ethernet), 9
configuring interface EEE energy saving, 9
configuring interface energy-saving features (Ethernet), 9
configuring LAN switching LLDP 802.1p-to-local priority mapping, 158
configuring LAN switching LLDP APP parameters, 156
configuring LAN switching LLDP DCBX, 154, 166
configuring LAN switching LLDP ETS parameters, 158
configuring LAN switching LLDP group-based WRR queuing, 159
configuring LAN switching LLDP PFC parameters, 159
configuring Layer 2 Ethernet interface, 10
configuring Layer 2 Ethernet interface storm control, 10
configuring Layer 2 Ethernet interface storm suppression, 10
configuring Layer 2 Ethernet link aggregation (dynamic), 55
configuring Layer 2 Ethernet link aggregation (static), 54
configuring Layer 2 Ethernet link aggregation group (dynamic), 43
configuring Layer 2 Ethernet link aggregation group (static), 42
configuring Layer 2 Ethernet link aggregation load sharing, 57
configuring Layer 3 Ethernet interface, 14
configuring Layer 3 Ethernet link aggregation (dynamic), 61
configuring Layer 3 Ethernet link aggregation (static), 60
configuring Layer 3 Ethernet link aggregation edge aggregate interface, 62
configuring Layer 3 Ethernet link aggregation group (dynamic), 44
configuring Layer 3 Ethernet link aggregation group (static), 42
configuring Layer 3 Ethernet subinterface, 14
configuring Layer 3 Ethernet subinterface basic settings, 4
configuring LLDP, 146
configuring LLDP advertisable TLVs, 149
configuring LLDP basics, 146, 161
configuring LLDP bridge mode, 147
configuring LLDP CDP compatibility, 153
configuring LLDP DCBX version, 155
configuring LLDP management address, 151
configuring LLDP management address encoding format, 151
configuring LLDP trapping, 160
configuring LLDP-MED trapping, 160
configuring loop detection, 108, 110
configuring MAC address table, 29
configuring MAC address table dynamic aging timer, 26
configuring MAC address table entry, 22
configuring MAC change notification interval, 31
configuring MAC Information, 31
configuring MAC Information mode, 30
configuring MAC Information queue length, 31
configuring management Ethernet interface, 1
configuring MST region, 82
configuring MST region max hops, 84
configuring MSTP, 79, 81, 102
configuring MSTP device priority, 84
configuring MSTP root bridge, 83
configuring MSTP root bridge device, 84
configuring MSTP secondary root bridge, 83
configuring MSTP secondary root bridge device, 84
configuring port isolation (on LAN), 66
configuring RSTP, 79, 80, 102
configuring RSTP device priority, 84
configuring RSTP root bridge, 83
configuring RSTP root bridge device, 84
configuring RSTP secondary root bridge, 83
configuring RSTP secondary root bridge device, 84
configuring STP, 79, 80, 102
configuring STP BPDU transmission rate, 87
configuring STP device priority, 84
configuring STP Digest Snooping, 94, 95
configuring STP edge port, 87
configuring STP No Agreement Check, 96, 97
configuring STP port link type, 91
configuring STP port mode for MSTP packets, 92
configuring STP port path cost, 88, 90
configuring STP port priority, 90
configuring STP port role restriction, 99
configuring STP protection features, 98
configuring STP root bridge, 83
configuring STP root bridge device, 84
configuring STP secondary root bridge, 83
configuring STP secondary root bridge device, 84
configuring STP switched network diameter, 85
configuring STP TC-BPDU transmission restriction, 100
configuring STP timeout factor, 86
configuring STP timer, 85
configuring VLAN (port-based), 117, 121
configuring VLAN basic settings, 114
configuring VLAN interface basic settings, 115
configuring VLAN mapping, 129, 134
configuring VLAN mapping (0\2), 131
configuring VLAN mapping (1\1), 130, 134
configuring VLAN mapping (1\2), 130, 136
configuring VLAN mapping (2\2), 132, 136
configuring VLAN mapping (2\3), 133
disabling global MAC address learning, 25
disabling MAC address learning, 25
disabling MAC address learning on interface, 25
displaying bulk interface configuration, 20
displaying Ethernet interface, 14
displaying Ethernet link aggregation, 53
displaying interface, 17
displaying LLDP, 161
displaying loop detection, 110
displaying MAC address table, 28
displaying MSTP, 101
displaying port isolation, 65
displaying RSTP, 101
displaying STP, 101
displaying VLAN, 121
displaying VLAN mapping, 134
enabling Ethernet link aggregation local-first load sharing, 50
enabling Ethernet link aggregation traffic redirection, 51
enabling LAN switching LLDP+DCBX TLV advertisement, 155
enabling LLDP, 146
enabling LLDP polling, 148
enabling loop detection (global), 108
enabling loop detection (port-specific), 108
enabling MAC address learning at ingress, 28
enabling MAC address synchronization globally, 26
enabling MAC Information, 30
enabling STP BPDU guard, 98
enabling STP feature, 93
enabling STP loop guard, 99
enabling STP port state transition information output, 92
enabling STP root guard, 98
enabling STP TC-BPDU guard, 100
forcing interface fiber port (Layer 2 Ethernet), 12
maintaining Ethernet interface, 14
maintaining Ethernet link aggregation, 53
maintaining interface, 17
maintaining MSTP, 101
maintaining RSTP, 101
maintaining STP, 101
maintaining VLAN, 121
modifying MAC address table blackhole entry, 24
modifying MAC address table multiport unicast entry, 24
performing STP mCheck, 93
performing STP mCheck globally, 93
performing STP mCheck in interface view, 93
reserving VLAN interface resource, 116
reserving VLAN interface resource (global type), 116
reserving VLAN interface resource (local type), 116
restoring Ethernet link aggregate interface default settings, 49
setting Ethernet aggregate interface (description), 44
setting Ethernet link aggregate group min/max number Selected ports, 46
setting Ethernet link aggregate interface (expected bandwidth), 46
setting Ethernet link aggregation load sharing mode (global), 50
setting Ethernet link aggregation load sharing mode (group-specific), 50
setting interface MDIX mode (Layer 2 Ethernet), 13
setting Layer 3 aggregate interface (MTU), 45
setting Layer 3 aggregate subinterface (MTU), 45
setting Layer 3 Ethernet interface MTU, 14
setting Layer 3 Ethernet subinterface MTU, 14
setting LLDP frame encapsulation format, 152
setting LLDP operating mode, 147
setting LLDP parameters, 151
setting LLDP re-initialization delay, 148
setting loop detection interval, 109
setting loop detection protection action (global), 109
setting loop detection protection action (Layer 2 aggregate interface), 109
setting loop detection protection action (Layer 2 Ethernet interface), 109
setting MSTP mode, 82
setting RSTP mode, 82
setting STP mode, 82
shutting down Ethernet link aggregate interface, 48
specifying Layer 2 aggregate interface (ignored VLAN), 45
specifying STP port path cost calculation standard, 88
splitting 40-GE interface into 10-GE breakout interfaces, 2
splitting and combining Ethernet interface, 2
testing interface cable connection (Layer 2 Ethernet), 14
protecting
loop detection protection action setting, 108
STP protection features, 98
protocols and standards
Ethernet link aggregation protocol configuration, 35
LLDP, 146
MSTP, 79
STP protocol packets, 68
VLAN, 114
PVID (port-based VLAN), 118
Q
QinQ
loop detection configuration, 106, 108, 110
QoS
LAN switching LLDP 802.1p-to-local priority mapping, 158
LAN switching LLDP APP parameters, 156
LAN switching LLDP ETS parameters, 158
LAN switching LLDP group-based WRR queuing, 159
LAN switching LLDP PFC parameters, 159
LLDP DCBX version, 155
queuing
MAC Information queue length, 31
R
rate
STP BPDU transmission rate, 87
receiving
LLDP frames, 146
recovering
loop detection port status auto recovery, 107
redirecting
Ethernet link aggregation traffic redirection, 51
reference port (Ethernet link aggregation), 36, 38
region
MST, 76
MST region configuration, 82
MST region max hops, 84
MST regional root, 77
re-initialization delay (LLDP), 148
reserving
VLAN interface resource, 116
VLAN interface resource (global type), 116
VLAN interface resource (local type), 116
restoring
Ethernet link aggregate interface default settings, 49
restrictions
Ethernet link aggregation traffic redirection, 52
STP Digest Snooping configuration, 94
STP edge port configuration, 87
STP port link type configuration, 91
STP port role restriction, 99
STP TC-BPDU transmission restriction, 100
STP timer configuration, 86
root
MST common root bridge, 77
MST regional root, 77
MST root port role, 77
MSTP root bridge configuration, 83
MSTP secondary root bridge configuration, 83
RSTP root bridge configuration, 83
RSTP secondary root bridge configuration, 83
STP algorithm calculation, 70
STP root bridge, 69
STP root bridge configuration, 83
STP root guard, 98
STP root port, 69
STP secondary root bridge configuration, 83
configuration, 68, 79, 80, 102
device priority configuration, 84
displaying, 101
maintaining, 101
mode set, 82
network convergence, 74
No Agreement Check, 96, 97
root bridge configuration, 83
root bridge device configuration, 84
secondary root bridge configuration, 83
secondary root bridge device configuration, 84
STP basic concepts, 69
S
selecting
Ethernet link aggregation Selected ports, 46
Ethernet link aggregation selected state, 34
Ethernet link aggregation unselected state, 34
service
LLDP service bridge mode, 147
setting
Ethernet aggregate interface (description), 44
Ethernet link aggregate group min/max number Selected ports, 46
Ethernet link aggregate interface (expected bandwidth), 46
Ethernet link aggregation load sharing mode (global), 50
Ethernet link aggregation load sharing mode (group-specific), 50
Ethernet link aggregation member port state, 36, 39
interface MDIX mode (Layer 2 Ethernet), 13
Layer 3 aggregate interface (MTU), 45
Layer 3 aggregate subinterface (MTU), 45
Layer 3 Ethernet interface MTU, 14
Layer 3 Ethernet subinterface MTU, 14
LLDP frame encapsulation format, 152
LLDP operating mode, 147
LLDP parameters, 151
LLDP re-initialization delay, 148
loop detection interval, 109
loop detection protection action (global), 109
loop detection protection action (Layer 2 aggregate interface), 109
loop detection protection action (Layer 2 Ethernet interface), 109
MSTP mode, 82
RSTP mode, 82
STP mode, 82
shutting down
Ethernet link aggregate interface, 48
loop detection shutdown action, 107
SNAP
LLDP frame encapsulated in SNAP format, 141
LLDP frame encapsulation format, 152
SNMP
MAC Information configuration, 30, 31
snooping
STP Digest Snooping, 94, 95
spanning tree. Use STP, RSTP, MSTP
specifying
Layer 2 aggregate interface (ignored VLAN), 45
STP port path cost calculation standard, 88
state
Ethernet interface state change suppression, 5
Ethernet link aggregation member port state, 34, 36, 39
static
Ethernet link aggregation group, 42
Ethernet link aggregation mode, 35
Ethernet link aggregation static mode, 36
Layer 2 Ethernet link aggregation, 54
Layer 2 Ethernet link aggregation group, 42
Layer 3 Ethernet link aggregation, 60
Layer 3 Ethernet link aggregation group, 42
MAC address table entry, 21
storm
Layer 2 Ethernet interface storm control, 10
Layer 2 Ethernet interface storm suppression, 10
algorithm calculation, 70
basic concepts, 69
BPDU forwarding, 73
BPDU guard enable, 98
BPDU transmission rate configuration, 87
CIST, 77
configuration, 68, 79, 80, 102
CST, 76
designated bridge, 69
designated port, 69
device priority configuration, 84
Digest Snooping, 94, 95
Digest Snooping configuration restrictions, 94
displaying, 101
edge port configuration, 87
edge port configuration restrictions, 87
feature enable, 93
IST, 77
loop detection, 68
loop guard enable, 99
maintaining, 101
mCheck, 93
mCheck (global), 93
mCheck (interface view), 93
mode set, 82
MST common root bridge, 77
MST port roles, 77
MST port states, 78
MST region, 76
MST region configuration, 82
MST regional root, 77
MSTI, 76
MSTI calculation, 79
MSTP, 74, See also MSTP
MSTP CIST calculation, 79
MSTP device implementation, 79
No Agreement Check, 96, 97
path cost, 69
port link type configuration, 91
port link type configuration restrictions, 91
port mode configuration, 92
port path cost calculation standard, 88
port path cost configuration, 88, 90
port priority configuration, 90
port role restriction, 99
port state transition output, 92
protection features, 98
protocol packets, 68
root bridge, 69
root bridge configuration, 83
root bridge device configuration, 84
root guard enable, 98
root port, 69
RSTP, 74, See also RSTP
secondary root bridge configuration, 83
secondary root bridge device configuration, 84
switched network diameter, 85
TC-BPDU guard, 100
TC-BPDU transmission restriction, 100
timeout factor configuration, 86
timer configuration, 85
timer configuration restrictions, 86
timers, 74
VLAN-to-instance mapping table, 76
suppressing
Ethernet interface physical state change suppression, 5
Layer 2 Ethernet interface storm control configuration, 10
Layer 2 Ethernet interface storm suppression configuration, 10
SVLAN
VLAN mapping configuration, 124, 129, 134
VLAN mapping implementation, 126
switching
Ethernet interface configuration, 1
interface configuration (inloopback), 16, 17
interface configuration (loopback), 16, 16
interface configuration (null), 16, 16
MAC address table configuration, 21, 22, 29
port isolation configuration, 65
port isolation configuration (on LAN), 66
port-based VLAN access port assignment, 118
port-based VLAN access port assignment (in interface view), 119
port-based VLAN access port assignment (in VLAN view), 119
port-based VLAN hybrid port assignment, 120
port-based VLAN trunk port assignment, 119
reserving VLAN interface resource, 116
reserving VLAN interface resource (global type), 116
reserving VLAN interface resource (local type), 116
VLAN basic configuration, 114
VLAN configuration, 113
VLAN interface basic configuration, 115
VLAN port-based configuration, 117, 121
synchronizing
MAC addresses, 26
system
interface bulk configuration, 19
T
table
LAN switching LLDP priority mapping table, 158
MAC address, 21, 22, 29
MSTP VLAN-to-instance mapping table, 76
tag
VLAN mapping configuration, 124, 129, 134
VLAN mapping configuration (0\2), 131
VLAN mapping configuration (1\1), 130, 134
VLAN mapping configuration (1\2), 130, 136
VLAN mapping configuration (2\2), 132, 136
VLAN mapping configuration (2\3), 133
TC-BPDU
STP TC-BPDU guard, 100
STP TC-BPDU transmission restriction, 100
testing
interface cable connection (Layer 2 Ethernet), 14
time
Ethernet link aggregation LACP timeout interval, 37
timeout
STP timeout factor, 86
timer
LLDP re-initialization delay, 148
MAC address table dynamic aging timer, 26
STP forward delay, 74, 85
STP hello, 74, 85
STP max age, 74, 85
TLV
LAN switching LLDP+DCBX TLV advertisement, 155
LLDP advertisable TLV configuration, 149
LLDP frame management address TLV, 145
LLDP management address configuration, 151
LLDP management address encoding format, 151
LLDP parameters, 151
LLDPDU basic management types, 142
LLDPDU LLDP-MED types, 142
LLDPDU organization-specific types, 142
topology
STP TCN BPDU protocol packets, 68
traffic
Ethernet link aggregation traffic redirection, 51
transmitting
LLDP frames, 145
STP TC-BPDU transmission restriction, 100
trapping
LLDP configuration, 160
LLDP-MED configuration, 160
MAC Information configuration, 30, 31
MAC Information mode configuration, 30
trunk port
port-based VLAN assignment, 119
U
unicast
MAC address table configuration, 21, 22, 29
MAC address table multiport unicast entry, 21
V
Virtual Local Area Network. Use VLAN
basic configuration, 114
configuration, 113
configuring, 113
displaying, 121
frame encapsulation, 113
hybrid port assignment, 120
interface basic configuration, 115
Layer 2 Ethernet aggregate interface (ignored VLAN), 45
LLDP CDP compatibility, 153
loop detection configuration, 106, 108, 110
maintaining, 121
mapping. See VLAN mapping
MSTP VLAN-to-instance mapping table, 76
port isolation configuration, 65
port link type, 117
port-based configuration, 117, 121
port-based VLAN access port assignment, 118
port-based VLAN access port assignment (in interface view), 119
port-based VLAN access port assignment (in VLAN view), 119
port-based VLAN frame handling, 118
port-based VLAN trunk port assignment, 119
protocols and standards, 114
PVID, 118
reserving interface resource, 116
reserving interface resource (global type), 116
reserving interface resource (local type), 116
0\2 application scenario, 126
0\2 configuration, 131
0\2 implementation, 128
1\1 application scenario, 124
1\1 configuration, 130, 134
1\1 implementation, 126, 127
1\2 application scenario, 125
1\2 configuration, 130, 136
1\2 implementation, 126, 127
2\2 application scenario, 125
2\2 configuration, 132, 136
2\2 implementation, 126, 128
2\3 application scenario, 126
2\3 configuration, 133
2\3 implementation, 129
configuration, 124, 129, 134
displaying, 134
voice traffic
LLDP CDP compatibility, 153
W
WRR queuing
LAN switching LLDP group-based WRR queuing, 159