- Released At: 13-06-2025
- Page Views:
- Downloads:
- Table of Contents
- Related Documents
-
|
|
|
H3C G6 Servers Intel Platform RAS |
|
Technology White Paper |
|
|
|
|
Copyright © 2024-2025 New H3C Technologies Co., Ltd. All rights reserved.
No part of this manual may be reproduced or transmitted in any form or by any means without prior written consent of New H3C Technologies Co., Ltd.
Except for the trademarks of New H3C Technologies Co., Ltd., any trademarks that may be mentioned in this document are the property of their respective owners.
The information in this document is subject to change without notice.
Overview
The server is one of the key components of any modern data center infrastructure. It includes various components such as processors, storage devices, PCIe devices, power supplies, and fans. To ensure service stability, correct server operation based on data integrity are critical to a modern data center. In other words, we must avoid data corruption, regardless of whether data is stored on any server component (memory, cache, or processor registers) or transmitted through any platform links (Intel®UPI, PCIe, or DMI).
When a server component fails, the set of reliability, availability and serviceability (RAS) features can meet the above requirements by maximizing service availability and maintaining data integrity.
Table 1 RAS definition based on H3C G6 servers
|
Item |
Definition |
|
Reliability |
Probability that the system produces the correct output within a given time T, as measured by the mean time between failures (MTBF) metric. It can be enhanced by avoiding, detecting, and repairing hardware failures. A reliable system does not provide incorrect data and calculation results, but can detect and correct data corruption. |
|
Availability |
Probability of correct system running at a given time, and the percentage of the actual running time of the server to the actual running time. |
|
Serviceability |
How easy and fast the system can be repaired or maintained. If the time for the system to repair errors increases, the serviceability decreases. Serviceability can be improved by simplifying system issue diagnosis and providing clear and intelligent advance warnings of failures to avoid system failures. |
Figure 1 Error categories

Benefits
RAS can provide the following benefits:
· Increased system uptime—Increases system reliability for the system to stay longer, as measured by the Mean Time To Fail (MTTF), Annual Crash Rate (ACR), or Annual Service Rate (ASR) metric. A reliable system will have a longer stable running time, making it more available. H3C G6 servers, designed with high reliability in both hardware and software, can provide enterprises with longer server stability and create more value for the enterprises.
· Reduced the duration of unexpected downtime—Adopts Intel 4th generation Xeon Scalable processors (codenamed Sapphire Rapids) and is designed to support log recording through hardware and firmware synergy. This helps identifying and isolating faults, enabling users to take preventive or proactive maintenance measures. In the event of a shutdown, the system can quickly come online, reducing maintenance costs and mitigating the impact of downtime on enterprises.
Outages are inevitable even with the best plans and processes. When an unplanned outage happens, a maintainable system can come back online quickly, as measured by the Mean Repair Time (MTTR) matric.
· Enhanced data integrity—RAS provides several mechanisms to prevent data corruption or correct corrupted data, which ensures data corruption can get contained once detected.
Applicable products
This document is applicable to the following H3C UniServer servers:
· H3C UniServer R4300 G6
· H3C UniServer R4700 G6
· H3C UniServer R4900 G6
· H3C UniServer R4900 G6 Ultra
· H3C UniServer R4900LE G6 Ultra
· H3C UniServer R4700LE G6
· H3C UniServer R5300 G6
· H3C UniServer R5500 G6
· H3C UniServer R6700 G6
· H3C UniServer R6900 G6
Using this document
The information in this document is subject to change over time.
The information in this document might differ from your product if it contains custom configuration options or features.
RAS system architecture
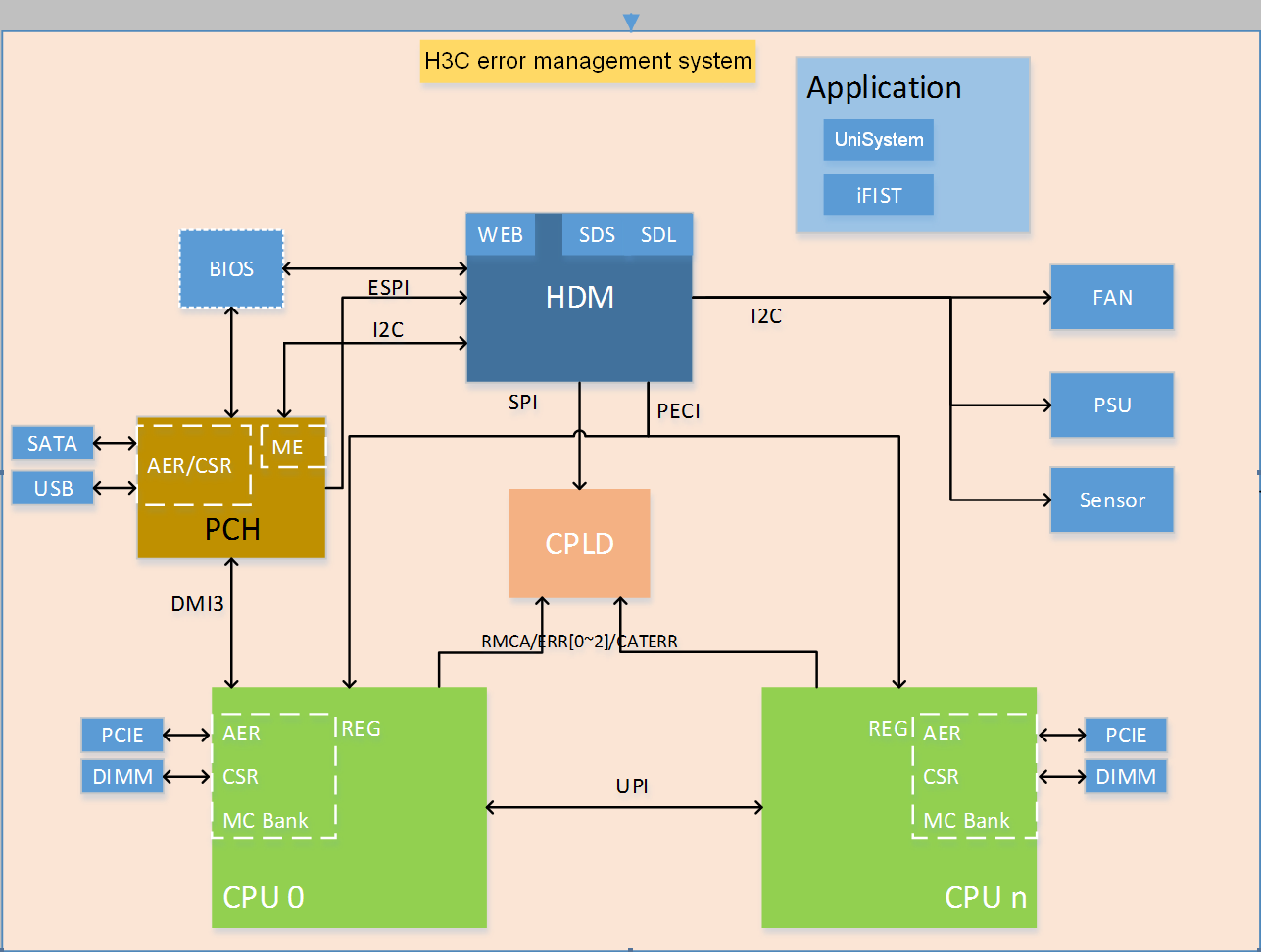
Based on MCA supported by Intel Xeon scalable processors, H3C provides a complete error management system together with hardware, the BIOS, HDM, and OS error processing mechanisms. The system can provide functions such as error diagnosis, error location, error correction, information collection, and error reporting. Since the core of the system is provided by the BIOS and HDM, it does not rely on the OS and can perform all-time detection of the system and take corresponding measures once an error occurs.
As shown in Figure 2, the error management system contains the hardware layer, CPLD, processor platform, HDM (out-of-band management), the BIOS, and OS.
· HDM—Core of the error location system. It is responsible for error information collection and analysis and can display error information as event logs or alarms from the Web interface.
· Processor platform—Supported by Intel Xeon scalable processors of the fourth generation, which compared with the previous generation provides enhanced RAS capabilities and more powerful management of errors occurred on processors, memory modules, and PCIe devices.
· CPLD—Connects downlink hardware modules, including power supplies, fans, and other underlying hardware (except processors, memory modules, drives, and standard PCIe modules), captures hardware exceptions, connects to HDM at the uplink, and transmits error information.
· BIOS—Collects and locates errors occurred on processors, memory modules, PCIe devices, and storage devices, provides error location results to HDM, and provides OS-level error management interfaces, such as APEI, to the OS.
· UniSystem—Server management software developed by H3C. It can decode SDS log messages to record hardware and software events occurred during each service cycle, including main processor, BIOS, OS, and HDM events. This helps maintenance engineers to fast locate server issues that affect server health and improve serviceability. This component is optional.
· iFIST—Single-server management tool embedded in each server. You can use iFIST to configure RAID settings, install the OS, install drivers, and diagnose server health conditions.
· Web interface—Web interface provided by management tools, such as HDM, for users to maintain the server locally or remotely. Users can use the Web interface together with LEDs of specific server components to manage the server.
· Involved protocols—Protocols used by the error management system includes ESPI, PECI, PCIe, UART, I2C, SMBUS, and LocalBus.
Figure 2 H3C error management system architecture
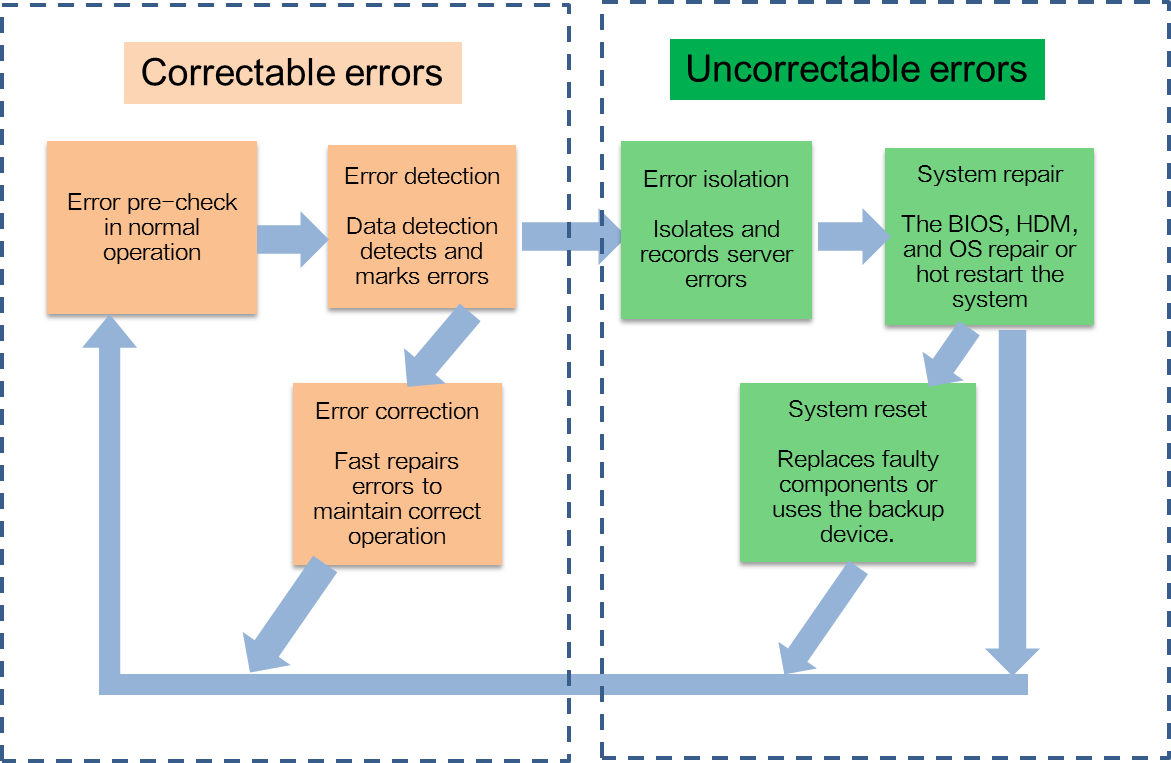
RAS operating mechanism
H3C RAS technology is realized through the processes of error detection, reporting, and processing.
The basic error processing schemes of RAS are as follows:
· For correctable errors, RAS marks the error location and fast repair the corresponding module. Users will not aware the occurrence of such errors.
· For uncorrectable errors, RAS isolates the errors by isolating bad memory blocks or degrading the bus to maintain system operation. If severe errors occur and result in system outage, you must use HDM to restore or restart the system.
· For permanent hardware failures, you must replace the faulty component or use the backup device. You can replace hot swappable components without powering off the server.
RAS technology is realized based on the following mechanisms:
· Machine Check Architecture (MCA)
MCA reports and fixes system bus, ECC, parity, cache, and TLB errors, identifies the source of failures, and records the failure information in MC Bank. Through the MCA mechanism, both correctable and uncorrectable errors of the CPU can be reported and logged and correctable errors of hardware can be corrected. For uncorrectable errors, a hot restart is usually performed. MCA can take effect on all processors modules such as Core, Uncore, and IIO (via IOMCA) modules.
· Integrated Error Handler (IEH)
IEH is a unified and clear-leveled error processing and reporting mechanism, including south satellite IEH, north satellite IEH, and global IEH. South satellite IEH is located in PCH, which collects and summarizes the fault information in PCH and reports the information to global IEH. North satellite IEH is located in each stack of CPU IIO, which collects and summarizes the fault information reported by all internal devices and downstream PCIe devices in the stack and reports the information to global IEH. Global IEH is located in Ubox, which summarizes the fault information reported by the downstream IEH and triggers the related interruption signal SMI/NMI or outputs ERRPIN in the range of 0 to 2.
· IIO Advanced Error Reporting (AER)
AER detects, logs and sends signals for errors of various IIO sub-modules. AER can take effect on all IIO sub-modules such as PCIe interface, DMI, IIO core logic, and Intel VT-d modules.
Figure 3 RAS schemes
Error detection
As shown in Table 2, H3C G6 servers use different error detection methods for different modules to maintain high processor availability. Both error detection and correction events will be reported.
For more information about error detection methods, see "Error detection and correction (including the socket level)."
Table 2 Error detection methods for different modules
|
Module |
Definition/Submodule |
Detection method |
|
EE |
Execution engine |
Residue check |
|
IFU |
Instruction fetch unit (L1 I-Cache) |
Parity |
|
DCU |
Data cache unit (L1 D-cache) |
Parity |
|
I/DTLB |
Instruction/Data translation look aside buffer |
Parity |
|
MLC |
Mid-level cache |
ECC |
|
CHA |
L3 cache: Data, tag, MESIF state |
ECC |
|
M2M |
Mesh To Memory (M2M) |
Parity |
|
Punit |
Power controller unit |
Parity, stack overflow, time schemes |
|
IVR |
Integrated voltage regulators |
Overvoltage and overcurrent |
|
UPI |
Ultra path interconnect |
CRC |
|
Rx and Tx queues |
Parity |
|
|
IMC |
Read data buffer |
Parity |
|
Memory read write data byte enable |
ECC |
|
|
IIO/PCIe |
Integrated I/O: Phy and link layer |
CRC & ECC |
|
Rx/Tx queues |
Parity |
|
|
IIO, IRP, Inter VT-d, MISC, DMA errors |
||
|
Internal ring |
Internal ring - data and command (DPPP, APPP) |
Parity |
Error reporting
Error reporting notifies potential faults of various types. Processor error reporting is triggered only when an error is detected. The system reports detected errors and generates error log messages.
The error reporting feature includes the following modules:
· Machine Check Architecture (MCA)
MCA can capture and record the first error for uncorrectable errors, while for correctable errors, it records the last error. MCA can take effect on all processors modules such as Core, Uncore, and IIO (via IOMCA) modules.
· Integrated Error Handler (IEH)
IEH provides unified error reporting. It can aggregate error information from all internal and external devices under PCH and IIO. The error information is transmitted via an internal dedicated message bus, and the global IEH device ultimately generates relevant interrupts or external signals to notify the BIOS or HDM for error handling.
· Integrated I/O Advanced Error Reporting (IIO AER)
IIO AER is an optional extension feature of PCI Express. It provides a more powerful error reporting mechanism than the standard PCI Express error reporting mechanism, including PCI Express AER, traffic switch, IRP, IIO core, Intel VT-D, and other specific extension devices by Intel.
· Memory correctable error reporting
This feature records the number of memory correctable errors and sends signals for memory correctable errors.
· UPI correctable error reporting
This feature records UPI error records and send signals for UPI errors.
· IVR error reporting
This feature provides error reporting for the voltage regulator integrated within CPUs.
Error reporting modes
The following error reporting modes are available:
· Legacy IA-32 MCA mode—Supported by several generations of Intel processors and most operating systems.
· Corrupt Data Containment (CDC) mode—An enhancement to the MCA mechanism. When the CDC mode detects an uncorrectable error, the detection agent forwards the error data with the poison flag set to the request agent.
· Enhanced MCA Gen2 (EMCA Gen2) mode—Second-generation enhancement to the Legacy IA-32 MCA mode. It was developed to create a mode that can be enabled in the OS and further expanded the error reporting coverage of FFM.
· IOMCA mode—Allows IIO correctable and uncorrectable fatal errors to be signaled through MCE.
· Viral mode—Adopts hardware measures to improve error tolerance. The CDC mode can tolerate data errors, but the viral mode can tolerate address, control, and other fatal errors. This prevents errors from being submitted to drives or networks.
Some of the above modes are complementary to each other and can be enabled at the same time. Table 3 describes mode compatibility.
Table 3 Error reporting mode compatibility
|
Mode |
Legacy IA-32 MCA mode |
CDC mode |
EMCA Gen2 mode |
IO MCA mode |
Viral mode |
|
Legacy IA-32 MCA mode |
Yes |
N/A |
N/A |
N/A |
N/A |
|
CDC mode |
No |
Yes |
N/A |
N/A |
N/A |
|
EMCA Gen2 mode |
No |
Yes |
Yes |
N/A |
N/A |
|
IO MCA mode |
Yes |
Yes |
Yes |
N/A |
N/A |
|
Viral mode |
Yes |
Yes |
Yes |
Yes |
N/A |
As shown in Table 4, the interrupt type used for error reporting depends on the error type.
Table 4 Error reporting interrupt
|
Error type |
Interrupt type |
Range |
Remarks |
|
|
Correctable errors |
Corrected Machine Check Interrupt (CMCI) |
Core/uncore |
Available only in Legacy IA-32 MCA mode |
|
|
Corrected SMI (CSMI) |
Core/uncore |
Available only in eMCA2 mode |
||
|
System Management Interrupt (SMI) |
Memory errors |
In-band communication between all sockets through UPI bus |
||
|
Message Signaled Interrupt (MSI) |
PCIe errors |
N/A |
||
|
ERROR_N[0] pin |
IIO AER and memory errors |
Can be used for HDM-based RAS |
||
|
Uncorrectable errors |
UCNA |
CMCI |
Core/uncore errors at the source |
Available only in Legacy IA-32 MCA mode |
|
MSMI |
Core/uncore errors at the source |
Available only in eMCA2 mode |
||
|
MSI and ERROR_N[1] pin |
Severity 1 IIO AER nonfatal errors |
N/A |
||
|
SRAO and SRAR |
MCERR |
Core/uncore errors |
Available only in Legacy IA-32 MCA mode |
|
|
MSMI |
Core/uncore errors at the source |
Available only in eMCA2 mode |
||
|
Catastrophic errors |
IERR |
Core/uncore errors |
Available only in Legacy IA-32 MCA mode |
|
|
MSMI |
Core/uncore errors at the source |
Available only in eMCA2 mode |
||
As shown in Figure 4, the system processes errors as follows:
· For correctable errors, when frequently occurred correctable errors reach the threshold based on the leaky bucket algorithm, the system triggers an SMI to notify the BIOS to process the errors. Upon receiving the interrupt request, the BIOS performs the following tasks while ensuring the normal operation of the system:
¡ Take the corresponding measures based on the interrupt type.
¡ Locate and isolate the failed component.
¡ Collect information about the register failure.
¡ Report error events and register information to HDM.
· For uncorrectable errors that can be recovered, the system labels error data and triggers an SMI. Upon receiving the interrupt request, the BIOS collects information about the failed register, locates the failed component, and reports error events and register information to HDM. Such errors will not affect the operation of the system.
· For uncorrectable errors that cannot be recovered, such errors can pull the CATERR_N pin low and causes system outage, which then will triggers HDM to collect information about the failed register in the x86 system. This ensures that users can obtain error information even if the system gets stuck.
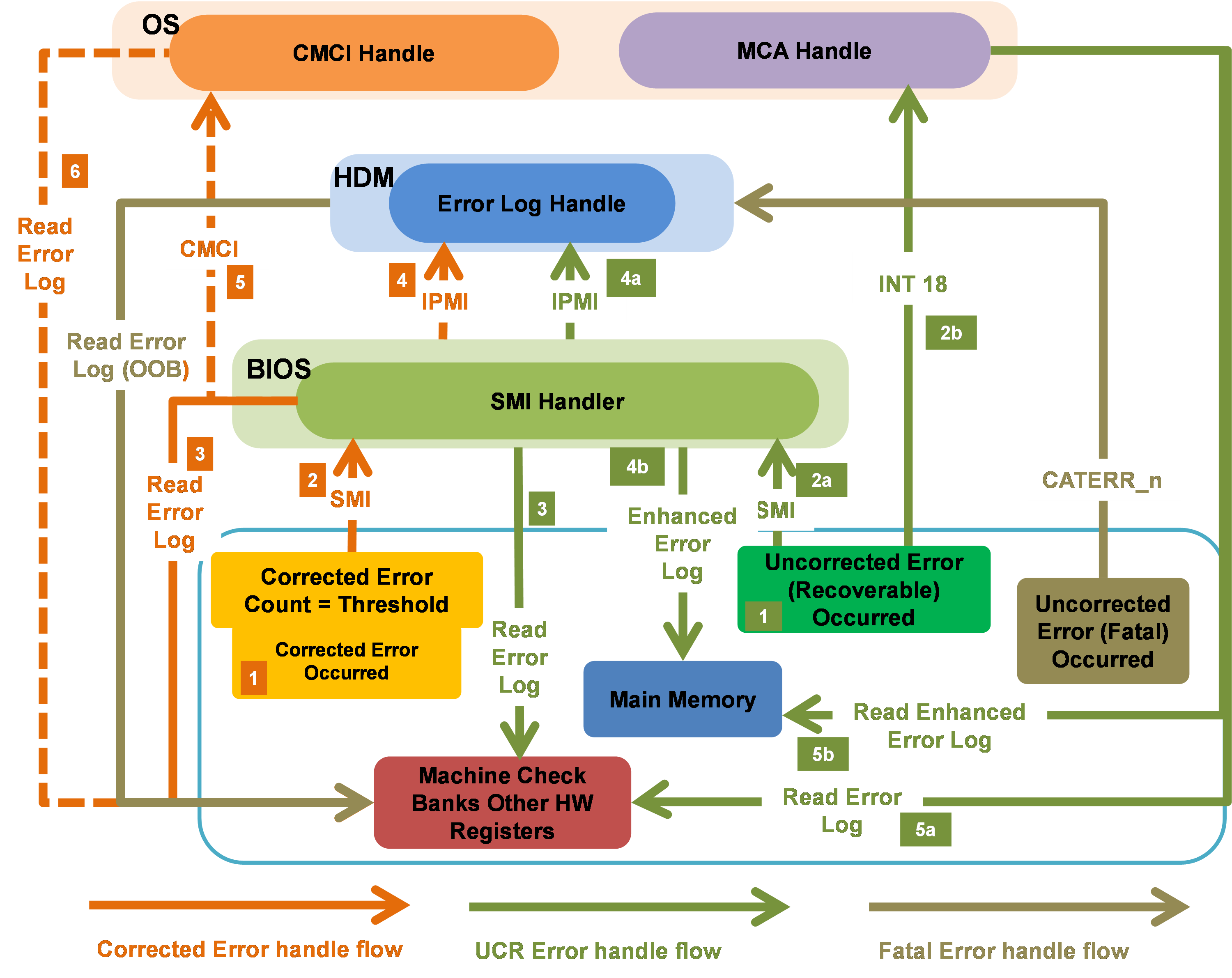
Error logging
The system uses MCA Bank status registers, AER status registers, memory correctable error status registers, and Intel UPI error status registers to log and record log messages for the Core, Uncore, and IIO modules.
To prevent new error logs from overwriting existing log messages, enable the FCERR mode. For more information, see "First corrected error mode."
To set the PCIe correctable error reporting thresholds, see "PCIe correctable error reporting." If the number of correctable errors reaches the threshold for both the IIO submodule and all other Uncore modules in processors, an error reporting signal is triggered. For more information, see "Threshold for correctable errors."
Table 5 Error severity and reporting methods
|
Error type |
Range |
Error logging |
|
Corrected or advisory non-fatal |
MCA |
MCA Bank registers |
|
AER (severity 0) |
PCIe error registers |
|
|
IMC |
CORRERRSTATUS (per rank) |
|
|
Uncorrected recoverable or non-fatal |
MCA |
MCA Bank registers |
|
AER (severity 1) |
PCIe error registers |
|
|
Uncorrected fatal |
MCA |
MCA Bank registers |
|
AER (Severity 2) |
PCIe error registers |
|
|
Catastrophic |
MCA |
MCA Bank registers |
Error processing
Memory error processing
As shown in Table 6, the memory error processing method varies by memory error type.
Table 6 Memory error processing
|
Error type |
Possible causes |
Processing method |
|
Bit (Cell) error |
High energy particle strike-soft error (SE), or transient error |
SDDC, patrol scrub, and demand scrub |
|
Persistent fault |
PCLS (HBM Only) |
|
|
Row error |
Persistent fault |
SDDC and PPR |
|
Bank error |
Persistent fault |
ADDDC(SR) and ADDDC(MR) |
|
Rank/Device error |
Persistent fault |
ADDDC(MR), SDDC |
|
Addr/Cmd error |
Transient/Persistent fault |
DDR CMD/ADDR parity error check and retry |
|
Multi-device error(UCE) |
Persistent fault + SE |
MCA-recovery and address range mirroring |
|
Connector error |
Electrical noise or transient error |
Transaction retry |
|
Wear-out or manufacturing defect or persistent fault |
Memory disable/mapout for FRB |
|
|
Channel failure |
Board defect |
For information about SDDC, see "DRAM single device data correction (SDDC)." SDDC corrects errors on individual DRAM devices based on error codes and requires virtual lockstep support. SDDC provides error check and correction to correct single-bit (hard errors) and multi-bit errors on individual DRAM chips on DIMMs.
For information about PCLS, see "Partial cache line sparing (PCLS, HBM only)." PCLS can correct single-bit errors. When a permanent single-bit error occurs on the cache line, a backup bit can be used to replace the error bit, which makes PCLS performance better than ADDDC(MR) and ADC(SR). A single memory channel can support a maximum of 16 sets of PCLS. PCLS is supported only on HBM.
Another key technology for memory error handling is ADDDC (MR), which also requires virtual lockstep support and supports only correctable errors. ADDDC supports only x4 DIMMs, and it can correct hard failures on up to two DIMM regions (different banks or ranks) per memory channel.
Virtual lockstep is a data error correction algorithm implemented in hardware and firmware. This algorithm enables the duplication and swapping of codewords (32 bytes, half of a cache line) between related memory regions. Based on this algorithm, it allows for the replacement of faulty memory regions (bank or rank) to complete error repair.
CPU error processing
CPU core errors are mainly processed by using the Core Disable For FRB (Fault Resilient Boot), Core DCU Scrubbing, and Corrupt Data Containment functions.
· Core Disable For FRB—As the number of CPU cores in a server increases, a single failure point shifts from the entire processor to smaller components within processors, such as individual cores or part of the LLC. Therefore, when a CPU fails, it becomes necessary to disable a specific core or a subset of cores except for disabling the entire CPU.
· Core DCU Scrubbing—Allows the system to write the DCU data in M state to MLC and leave a data copy in E state in DCU when soft error occurs to DCU data. This write back algorithm has the minimal impact on performance and the fatal MCERR error can be transformed to a correctable error because MLC is protected by the ECC mechanism.
· Corrupt Data Containment (CDC)
CDC is also known as data poisoning. It synchronizes uncorrectable data error messages to transactions to improve error containment and system reliability. H3C G6 servers with Intel Xeon scalable processors of the fourth generation implement CDC functionality in Core, Uncore, and IIO subsystems.
¡ CDC in the Core subsystem
When uncorrectable data errors are detected in memory, MLC, or LLC, and CDC is enabled, data is marked as poisoned and received by the Core. Then, the Core can directly drop data and triggers fatal or correctable MCERRs. If a correctable MCERR is triggered, the SW/OS/VMM layer can attempt error clearance to enhance system reliability.
¡ CDC in the Uncore subsystem
When data marked as poisoned is received by an Uncore component (such as IMC, M2M, UPI, and CHA), the Uncore does not consume the data and discards it directly. In addition, a correctable MCERR event occurs. The SW/OS/VMM layer can then attempt error clearance to enhance system reliability.
¡ CDC in the IIO subsystem
CDC is also supported by the submodules in the IIO subsystem, such as IRP, CXL, and PCIe, enhancing system reliability.
PCIe error processing
PCIe errors are mainly processed by using the PCIe Link Retraining and Recovery and PCI Express Corrup Data Containment functions.
· PCIe Link Retraining and Recovery—Allows link rebuilding in case of link degrading on PCI Express interfaces without affecting hung processes. If link degrading occurs on a specific lane, the recovery mechanism reduces the link width (for example, from x16 to x8) based on the link degrading rules defined by Platform Design Guide (PDG). If link degrading occurs on multiple lanes, the recovery mechanism attempts to rebuild links at the next available speed.
· PCI Express Corrup Data Containment—Also known as Data Poisoning. This feature allows the system to mark received uncorrectable data errors as bad data and then send the data to the destination. The destination ignores the data or saves the data with the poison bit set. The poison flag can be set by both the transmitter and receiver.
UPI error processing
UPI errors are mainly processed by using the Intel UPI Corrupt Data Containment and Intel UPI Dynamic Link Width Reduction functions.
· Intel UPI Corrupt Data Containment—Adds a global POISON_ENABLE bit to each UPI link. The BIOS can set the enabling status of data poison by specifying a global bit through writing. With Intel UPI Date Poison enabled, UPI forwards received poison data to the destination without triggering error signal reporting or logging. It is determined by data consumers how to process uncorrectable data errors.
With UPI Data Poison disabled, UPI cannot identify poison data, and all units operate in Legacy MCA mode. Once poison data is received, Intel UPI will send an error signal and log the error.
· Intel UPI Dynamic Link Width Reduction—Dynamically adjusts lane width to recover from hard failures occurred on one or multiple data lanes of an Intel UPI link. If possible, the link will keep operating over the narrow width. In case of a physical lane failure, width reduction from full-width to x8 is supported. Half-width support is only available for a minimal set of a x8 bits to allow for the failure of any single data lane. The supported dynamic link width reduction modes are lanes [7:0] or [23:15], which means that a multi lane failure will recover as long as not all failures are on [7:0] and [23:15].
RAS features
Hardware compatibility with RAS features
|
|
IMPORTANT: · Each G6 server model supports multiple processor models. For more information about compatible processors, see the appendix of the user guide for the server. RAS features marked with No for some processors in Table 7 are not available for 4XXX or 3XXX processors. · Only HBM processors support RAS features marked with HBM Only in Table 7. · R4900 in Table 7 include R4900 G6 and R4900 G6 Ultra. |
Table 7 RAS feature and server compatibility
|
Type |
Feature name |
R4700 |
R4900 |
R5300 |
R5500 |
R6700 |
R6900 |
|
CPU |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
CPU |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
CPU |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
CPU |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
CPU |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
CPU |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
CPU |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
CPU |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
CPU |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
CPU |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
||
|
CPU |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
CPU |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
CPU |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
CPU |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
CPU |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
Memory |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
Memory |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
Memory |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
Memory |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
Memory |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
Memory |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
||
|
Memory |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
Memory |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
Memory |
HBM only |
HBM only |
HBM only |
HBM only |
HBM only |
HBM only |
|
|
Memory |
HBM only |
HBM only |
HBM only |
HBM only |
HBM only |
HBM only |
|
|
Memory |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
Memory |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
Memory |
No for some processors |
No for some processors |
No for some processors |
No for some processors |
Yes |
Yes |
|
|
Memory |
No for some processors |
No for some processors |
No for some processors |
No for some processors |
Yes |
Yes |
|
|
UPI |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
UPI |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
UPI |
No for some processors |
No for some processors |
No for some processors |
No for some processors |
Yes |
Yes |
|
|
PCH |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
IIO |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
IIO |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
||
|
IIO |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
IIO |
Yes |
Yes |
Yes |
Yes |
Yes |
||
|
IIO |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
IIO |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
IIO |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
IIO |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
||
|
System |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
System |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
System |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
System |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
System |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
System |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
System |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
System |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
System |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
System |
No for some processors |
No for some processors |
No for some processors |
No for some processors |
Yes |
Yes |
|
|
System |
Asynchronous MCA error injection (aka MCA bank spoofing error injection) |
No for some processors |
No for some processors |
No for some processors |
No for some processors |
Yes |
Yes |
|
Power supply |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
Fan module |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
Network adapter |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
Drive |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
Drive |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
Storage controller |
Yes (with supercapacitor installed) |
Yes (with supercapacitor installed) |
Yes (with supercapacitor installed) |
Yes (with supercapacitor installed) |
Yes (with supercapacitor installed) |
Yes (with supercapacitor installed) |
|
|
Storage controller |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
Storage controller |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
HDM |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
HDM |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
HDM |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
HDM |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
HDM |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
HDM |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
HDM |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
HDM |
System board monitoring and environment information from HDM |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
HDM |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
HDM |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
HDM |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
|
HDM |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
RAS feature overview
Error detection and correction (including the socket level)
|
Feature name |
Error detection and correction (including the socket level) |
|
Description |
This feature covers the error detection and correction capability at the entire processor level. It provides data protection and data integrity through enhanced cache error reporting, data path parity protection (DPPP) and address path parity protection (APPP). |
|
Purpose |
Ensure the reliability at the component level. |
|
Configuration |
Enabled by default and cannot be disabled. |
|
Remarks |
N/A |
Corrupt data containment mode – poison mode
|
Feature name |
Corrupt data containment mode – Poison mode |
|
Description |
The processor supports Legacy IA-32 MCA mode and MCA corrupt data containment mode In Legacy IA-32 MCA mode, if the system detects an uncorrectable error on a module (including error-generating modules and data-transmitting modules), an MCE is directly triggered to reset the system. In corrupt data containment mode, if the system detects an uncorrectable error on a module (including error-generating modules and data-transmitting modules), an MCE will not be triggered. On the detection of an uncorrected error, the detector sets a poison bit, and the system continues data transmission with the poison bit and triggers CMCI interrupt. The receiver can perform various processing operations as needed, including ignoring errors (for example, an error of a certain pixel on the screen), discarding data, initiating retransmission, and triggering MCE. |
|
Purpose |
Improve the fault tolerance of the entire system. |
|
Configuration |
Enabled by default and can be disabled from the BIOS. |
|
Remarks |
N/A |
Advanced error detection and correction (AEDC)
|
Feature name |
Advanced error detection and correction (AEDC) |
|
Description |
AEDC enables fault detection by using residue checking and parity protection techniques. Fault correction is completed by instruction retry. Correctable error events are logged in IFU MCA bank. If the retry did not correct a fault, a MCERR signal is triggered. |
|
Purpose |
Improve the error coverage in the core execution engine. |
|
Configuration |
CPU built-in feature, not configurable. |
|
Remarks |
N/A |
Time-out timer schemes
|
Feature name |
Time-out timer schemes |
|
Description |
This feature allows timeout timers within various sub-modules to report the faults as close as possible to the fault source. The following timeout features are implemented: · Core 3-strike. · CHA TOR timeout · Intel UPI link level retry timeout. · Mesh-to-Memory (M2Mem) timeout (formerly referred to as CHA BT timeout). · IRP Config retry time-out. · PCIe Port Completion Timeout (CTO). |
|
Purpose |
Improve the server availability and serviceability. |
|
Configuration |
Enabled by default, and partially configurable. |
|
Remarks |
N/A |
Error reporting (MCA, AER) – Core, Uncore, and IIO
|
Feature name |
Error reporting (MCA, AER) – Core, Uncore, and IIO |
|
Description |
Error reporting includes logging and error signaling. Error reporting through Machine Check Architecture (MCA) and Advanced Error Reporting (AER) is mainly supported. Platform-specific memory and UPI error reporting mechanisms are also available. |
|
Purpose |
· Report various types of errors occurring in a chassis. · Improve mean time to repair (MTTR). · Accelerate error debugging, especially in the field. |
|
Configuration |
Enabled by default and partly configurable. |
|
Remarks |
N/A |
Error reporting through MCA 2.0 (EMCA Gen2)
|
Feature name |
Error reporting through MCA 2.0 (EMCA Gen2) |
|
Description |
Prior to EMCA Gen2, Legacy IA-32 MCA directly reports error signals to OS/VMM, which does not utilize the UEFI firmware capability on fault diagnosis. EMCA Gen2 allows the firmware to strengthen the error logging capability of MCA. When this feature is enabled, UEFI-FW SMI handler can read MCA bank registers and other error logging registers before the OS machine check handler reads and clears the MCA banks. |
|
Purpose |
Provide UEFI FW recovery mechanism. |
|
Configuration |
Enabled by default and configurable from the BIOS. |
|
Remarks |
N/A |
Processor BIST
|
Feature name |
Processor BIST |
|
Description |
BIST a self-check module inside the processor. It performs self-check on each core of the processor during the BIOS startup process and records the self-check result. |
|
Purpose |
Detect errors in the processor. |
|
Configuration |
Enabled by default and not configurable. |
|
Remarks |
N/A |
MCA bank error control
|
Feature name |
MCA bank error control |
|
Description |
This feature allows hiding correctable errors and UCNA errors from the operating system because these errors are already corrected by the hardware. Thus, a certain number of correctable errors can be regarded as normal actions. When this feature is enabled, only SMM and PECI can access this type of error logs. By default, correctable errors are hided and UCNA errors can be accessed by the OS. |
|
Purpose |
Enhance server control over errors. |
|
Configuration |
Enabled by default and partly configurable. |
|
Remarks |
N/A |
First corrected error mode
|
Feature name |
First corrected error (FCERR) mode of error reporting |
|
Description |
This feature avoids correctable error overwriting when multiple correctable errors are reported. In a situation where multiple correctable errors occur rapidly, hardware will not overwrite the current correctable error log until the error handling program in the firmware/software has finished processing the current error. This ensures that the error handling program in the firmware/software can reliably handle errors. |
|
Purpose |
Enhance the ability to identify faulty components that require replacement on site, improving server availability. |
|
Configuration |
Enabled by default and cannot be disabled. |
|
Remarks |
N/A |
PCIe correctable error reporting
|
Feature name |
PCIe correctable error reporting |
|
Description |
You set PCIe correctable error thresholds on the root port basis and implement a better correctable error reporting system through SMI. |
|
Purpose |
Implement a better correctable error reporting architecture. |
|
Configuration |
Disabled by default and configurable. |
|
Remarks |
N/A |
Threshold for correctable errors
|
Feature name |
Threshold for corrected errors |
|
Description |
The processor supports error threshold functionality for all uncore MCA banks, allowing for error correction. When the threshold is reached, the corresponding MCA bank triggers a CSMI interrupt, and the FW/SW error handling program executes error processing and reporting. |
|
Purpose |
Capture threshold-based error logs for FRU isolation, PFA, and debugging when FFM is enabled. |
|
Configuration |
Enabled by default and configurable. |
|
Remarks |
N/A |
CSR error log cloaking
|
Feature name |
CSR error log cloaking |
|
Description |
The operating system generally does not obtain error logs from control and status registers (CSR), but some drivers might be able to access the error logs. Because these errors are already corrected by the hardware, we allow certain levels of errors to be considered normal system behavior. This feature hides part of the CSR error log registers and prevents the operating system from processing these registers until the BIOS is ready to expose these errors. |
|
Purpose |
With BIOS-based error handling code, system developers can manage system error log capturing and reporting in absence of any interference from the error handling code in the operating system. This enhances the serviceability of the server. |
|
Configuration |
Enabled by default and configurable from the BIOS. |
|
Remarks |
N/A |
DCU/IFU poison enhancements
|
Feature name |
DCU/IFU poison enhancements |
|
Description |
This feature improves DCU/IFU error logging by expanding the poison storm use case of the extended DCU/IFU, reducing the probability of multiple poison errors occurring due to proximity. |
|
Purpose |
Improve the system availability. |
|
Configuration |
Enabled by default and not configurable. |
|
Remarks |
N/A |
Core DCU scrubbing
|
Feature name |
Core DCU scrubbing |
|
Description |
This feature enables the system to write the DCU data in M state to MLC and leave a data copy in E state in DCU when soft error occurs to DCU data. This write back algorithm has the minimal impact on performance and the fatal MCERR error can be transformed to a correctable error because MLC is protected by the ECC mechanism. |
|
Purpose |
Improve the system availability. |
|
Configuration |
Enabled by default and cannot be disabled. |
|
Remarks |
N/A |
Core disable for FRB
|
Feature name |
Core disable for FRB |
|
Description |
With each generation, as the number of processor cores increases, a single point of failure shifts from the entire processor to smaller entities inside the processor, such as a single core or a portion of LLC. When a failure occurs, you can disable specific cores except for disabling the entire processor. |
|
Purpose |
Improve the system reliability. |
|
Configuration |
Enabled by default and cannot be disabled. |
|
Remarks |
Make sure at least one active core is retained to complete the system boot process. |
Enhanced SMM (ESMM)
|
Feature name |
Enhanced SMM (ESMM) |
|
Description |
Multiple RAS features report faults through eMCA gen2, and SMM is part of eMCA gen2. This feature facilitates the SMM mode by improving the following attributes: · Threads in long flow/blocked indicators. · Target SMI. · SMM dump state storage into internal MSRs. |
|
Purpose |
Improve the existing SMM mode and promote the use of eMCA gen2 for error reporting. |
|
Configuration |
Enabled by default and cannot be disabled. |
|
Remarks |
This feature is available only in eMCA mode. |
Memory corrected error reporting
|
Feature name |
Memory corrected error reporting |
|
Description |
This feature provides correctable error counters based on leaky bucket algorithm per rank. According to the number of correctable error records in each rank, various RAS features can be activated when the correctable error threshold is reached, such as ADDDC(MR/SR), PLCS, and PPR. |
|
Purpose |
Provide correctable error counters per rank. |
|
Configuration |
Enabled by default. You can set the thresholds from the BIOS. |
|
Remarks |
N/A |
DRAM single device data correction (SDDC)
|
Feature name |
DRAM single device data correction (SDDC) |
|
Description |
This feature can correct multiple bit errors on 10x4 DRAM devices. SDDC error correction uses a read retry method, where each bit is individually set to the opposite value, and then the CRC calculation is performed to check for a successful match. |
|
Purpose |
Effectively handle hard failures on DRAM devices, improving the availability of the memory. |
|
Configuration |
Enabled by default and cannot be disabled. |
|
Remarks |
· 5x8 SDDC is available only when the operating mode of the memory is set to lockstep from the BIOS. · Though a hard failure on a DRAM device can be corrected by SDDC, the performance of the memory will degrade sharply. |
DDR command/address parity check and retry
|
Feature name |
DDR command/address parity check and retry |
|
Description |
The DDR5 command/address parity check and retry feature include logging of the address after command/address parity check errors and retrying the command/address. Command/address parity check errors are reported via Alert PIN and can be resolved. Although one alert signal is shared by ranks/DIMMs in one channel, which causes the IMC to fail to determine which rank/DIMM or which command triggers the alert signal, the system still locates the source of the error and attempts to restore during the error processing phase. This feature equals to memory address parity protection. |
|
Purpose |
Detect and handle errors during read, write, or various other protocol-related transmissions on the memory command/address bus to improve reliability. |
|
Configuration |
Enabled by default. You can set the thresholds from the BIOS. |
|
Remarks |
N/A |
Command and address-based memory data irregular encoding
|
Feature name |
Command and address-based memory data irregular encoding |
|
Description |
The memory data stream is pseudo-randomly coded through the linear shift register to balance the 0/1 distribution and reduce the probability of soft errors. In addition, the memory address double-bit error detection is realized. |
|
Purpose |
Prevent a large number of high and low voltages, reducing electrical shock and increasing reliability. |
|
Configuration |
Enabled by default and cannot be disabled. |
|
Remarks |
N/A |
Memory demand and patrol scrubbing
|
Feature name |
Memory demand and patrol scrubbing |
|
Description |
Demand scrubbing is the ability to write the corrected data back to the memory if a correctable error is detected on a read transaction. If an uncorrectable error is detected in the data, another read operation will be tried. Patrol scrubbing is the ability to proactively searching system memory and attempting to correct any errors. The scrubbing and sparing (SSR) engine in the CHA reads the contents of the memory when it memory is idle according to the set frequency and step size. If a correctable error is detected in the read data, patrol scrubbing will write the corrected data back to the memory. This feature reduces the occurrence of uncorrectable errors by read retry and correcting single-bit errors. |
|
Purpose |
Reduce the possibility of memory error occurrence. |
|
Configuration |
Disabled by default and configurable from the BIOS. |
|
Remarks |
This feature might increases power consumption. |
Memory thermal throttling (memory temperature adjustment)
|
Feature name |
Memory thermal throttling (memory temperature regulation) |
|
Description |
This feature adjusts memory temperature. When the temperature of the memory module reaches a threshold, the system automatically triggers performance adjustments. The memory reduces its throughput rate and increases the refresh rate to lower the temperature and maintain memory stability. |
|
Purpose |
Prevent system issues caused by overheating, enhancing system stability and reliability. |
|
Configuration |
Enabled by default. |
|
Remarks |
Memory overheating might degrade the memory performance. |
Memory mirroring
|
Feature name |
Memory mirroring |
|
Description |
The feature saves two copies of memory data in the primary memory and mirroring memory respectively. This can ensure that when a DIMM chip fails, the memory protection technology can use the backup mirroring memory to retrieve data automatically. Since cross mirroring between channels is used, each channel has a complete set of memory data copy, which ensures a smooth server operation. |
|
Purpose |
Avoid data loss and device shutdown caused by memory failures and improve the availability of the memory through redundancy. |
|
Configuration |
Disabled by default and can be enabled from the BIOS. |
|
Remarks |
· Make sure the installation of DIMMs meets the requirements of memory mirroring. · Only 50% of the memory capacity is exposed to the operating system. · Memory mirroring is mutually exclusive with ADDDC. |
Adaptive DDDC - single region (ADDDC - SR)
|
Feature name |
|
|
Description |
In virtual lockstep mode, ADDDC(SR) can repair hard failures in individual DRAM devices. When a hard failure occurs on the bank area, it is mapped out through adaptive virtual lockstep. This is also referred to as ADC(SR). |
|
Purpose |
Repair hard failures on DRAM devices to improve the processing efficiency and reliability of hardware-level failures, enhancing system stability. |
|
Configuration |
Enabled by default and configurable from the BIOS. |
|
Remarks |
x4 DRAM memory. The failures are correctable. |
Post package repair (PPR)
|
Feature name |
Post package repair (PPR) |
|
Description |
DRAM devices employ row redundancy circuits to address single-row faults. A faulty row can be remapped to built-in redundant rows. Repairs are categorized as hard repair (hPPR) and soft repair (sPPR). Hard repair is a permanent fix, while soft repair is temporary and undone after a DRAM reset. During hPPR, each bank must have at least one repairable row, with the maximum number of repairable rows determined by the provider. |
|
Purpose |
DRAM units are increasingly susceptible to electrical, thermal, and mechanical stresses. PPR provides a memory repair solution to enhance the system reliability. |
|
Configuration |
Disabled by default. |
|
Remarks |
The DRAM must be larger than 4 GB. |
Partial cache line sparing (PCLS, HBM only)
|
Feature name |
Partial Cache Line Sparing (PCLS, HBM only) |
|
Description |
PCLS can correct single-bit errors. When a permanent single-bit error occurs on the cache line, a backup bit can be used to replace the error bit, which makes PCLS performance better than ADDDC(MR) and ADC(SR). A single memory channel can support a maximum of 16 sets of PCLS. |
|
Purpose |
Improve the system reliability. |
|
Configuration |
Enabled by default and configurable from the BIOS. |
|
Remarks |
Only available for HBM memory. |
HBM- bank sparing
|
Feature name |
HBM- bank sparing |
|
Description |
In the system, one bank is reserved as a spare on each HBM2e pseudo-channel. Once a fault is detected during system operation, the BIOS initiates bank sparing on the affected channel and replaces the faulty bank. This operation sets aside 1/16 of the HBM2e memory as spare memory. |
|
Purpose |
Improve the system reliability. |
|
Configuration |
Disabled by default and configurable from the BIOS. |
|
Remarks |
Only available for HBM memory. |
Memory disable/map-out for FRB
|
Feature name |
Memory disable/map-out for FRB |
|
Description |
During server startup, memory discovery, training, and testing are performed. If a memory is detected during this startup process, the server will disable the faulty memory (per rank, DIMM, or channel). This ensures that the server can continue with the booting process. |
|
Purpose |
Improve the system reliability. |
|
Configuration |
Enabled by default and not configurable. |
|
Remarks |
N/A |
Memory SMBus hang recovery
|
Feature name |
Memory SMBus hang recovery |
|
Description |
This feature enables the BIOS to perform SMBus error recovery by using SMI in runtime. You can configure the memory controller of the server to generate an SMI on SMBus error occurrence. If the SMI occurs, the BIOS SMI handler perform the following operations: 1. Save the TSOD address issued last time. 2. Save the current settings of TSOD polling and error recovery. 3. Disable both TSOD polling and error recovery. 4. Program safe temperature. 5. Save the current settings of closed loop thermal throttling (CLTT) and disable CLTT. 6. Trigger the hardware timer, activate the soft reset for the SMBus, and start the periodic SMI of N ms. The value N depends on the platform. 7. When the periodic SMI expires, identify whether the recovery is completed and disable the periodic timer. If the recovery is not completed, the periodic SMI handler will be executed again. 8. After the SMBus recovery is completed, disable soft reset, and restore the system state saved in steps 1 to 5 above. |
|
Purpose |
Perform SMBus error recovery in runtime, improving the system availability. |
|
Configuration |
Enabled by default and cannot be disabled. |
|
Remarks |
N/A |
DDR address range/partial memory mirroring
|
Feature name |
Address range/partial memory mirroring |
|
Description |
In partial mirror mode, you can set the size of mirrored memory from the BIOS. Other memory still operates in non-mirroring mode. All error detection, signaling, and correction operations in the full mirror mode can be applied to the partial mirror mode in the mirroring region. |
|
Purpose |
Save critical codes or data by using the partial mirror mode, improving memory reliability. |
|
Configuration |
Disabled by default and configurable from the BIOS. |
|
Remarks |
Memory rank sparing is mutually exclusive with memory mirroring. |
Adaptive DDDC - multi-region(ADDDC - MR)
|
Feature name |
|
|
Description |
In virtual lockstep mode, the ADDDC (MR) feature can repair a maximum of two hard failures on DRAM devices for different ranks and banks. If a hard failure on a DRAM device occurs at bank/rank region granularity, it is mapped out through the adaptive virtual lockstep mode. The ADDDC(MR) feature allows a maximum of two such hard failures and is able to correct a single-bit error subsequently. ADDDC(MR) is also referred to as ADDDC(MR)+1. |
|
Purpose |
Handle hard failures on DRAM devices to improve the processing efficiency and reliability of hardware-level failures, enhancing system stability. |
|
Configuration |
Disabled by default and configurable from the BIOS. |
|
Remarks |
This feature cannot be used together with mirror mode, and supports only x4 DRAM DIMMs. This feature can be enabled on each memory channel. The failures are correctable. |
UPI link level retry
|
Feature name |
UPI link level retry |
|
Description |
This feature allows a link to continue the normal operation when the receiver detects a CRC error. On the detection of a CRC error, the receiver sends a retry request to the transmitter. If the CRC error occurs due to a transient event, the retry operation is expected not to experience an error. This feature allows a maximum of two retry attempts. If the error continues after two retry attempts, the physical layer will be initialized. If the error still exits after the initialization, an uncorrectable error is triggered. |
|
Purpose |
Avoid transmission errors caused by transient data errors, improving the transmission reliability of UPI links, improving system stability. |
|
Configuration |
Enabled by default and cannot be disabled. |
|
Remarks |
N/A |
UPI protocol protection via CRC (16 bit)
|
Feature name |
UPI protocol protection via CRC (16 bit) |
|
Description |
This feature achieves more reliable inter-processor link communication through 16-bit CRC and improves data integrity through error detection. You can configure notifications for the system to detect CRC errors and identify potential link degradation issues that could lead to future link failures through the logs. |
|
Purpose |
Improve the system reliability. |
|
Configuration |
Enabled by default and cannot be disabled. |
|
Remarks |
N/A |
UPI dynamic link width reduction
|
Feature name |
UPI dynamic link width reduction |
|
Description |
Dynamic link width reduction clears hard failure for one or multiple data channels on a physical UPI link through dynamically adjusting the link width. If the system detects persistent errors on the link, the UPI link width can be halved and the performance can also be reduced. |
|
Purpose |
Improve the uptime and reliability of the system by enabling the system to continue running even when hard failure is detected in some channels. |
|
Configuration |
Enabled by default and cannot be disabled. |
|
Remarks |
· If the clock link fails, the UPI link width narrows by 50%. · After the link width is reduced, fault tolerance is not available for new failures. · As a best practice, arrange the maintenance when the issue is present. |
PCH PCIe Advanced Error Reporting (AER)
|
Feature name |
PCH PCIe Advanced Error Reporting (AER) |
|
Description |
PCIe devices integrated inside Intel chips can report faults to the CPU. The PCIe devices within Intel chips comply with the PCIe specifications. |
|
Purpose |
Report PCIe device errors within chips, improving system stability and reliability. |
|
Configuration |
The decision to report is determined by setting the corresponding mask bit. |
|
Remarks |
N/A |
PCIe link retraining and recovery
|
Feature name |
PCI Express link retraining and recovery |
|
Description |
This feature allows the processor to start a PCIe link retraining based on error conditions defined by PCIe specifications. Retraining the link includes resetting the link training and status state machine (LTSSM) to the recovery state and continuing the operation. LTSSM in the recovery state can start a speed or width degradation if errors are further detected during the retraining sequence. |
|
Purpose |
Ensure the reliability at the component level. |
|
Configuration |
Enabled by default and cannot be disabled. |
|
Remarks |
N/A |
PCIe link CRC error check and retry
|
Feature name |
PCIe link CRC error check and retry |
|
Description |
This feature provides the ability of CRC error detection and transaction retry on error occurrence. The point is to protect the link from signal integrity issues caused by EMI, marginal links, poor connectors, long trace lengths, and so on. This feature provides a mechanism to detect and correct errors that can be corrected most of the time through retry. |
|
Purpose |
Improve the PCIe link reliability in case of low signal integrity. |
|
Configuration |
Enabled by default and cannot be disabled. |
|
Remarks |
N/A |
PCIe corrupt data containment (data poisoning)
|
Feature name |
PCIe corrupt data containment (data poisoning) |
|
Description |
This feature attached an EP bit to the header any time the system detects an uncorrectable error before forwarding the packet to the next agent. This is used to achieve data integrity in both directions at the transaction level. The receiver detects the poison TLP and redirects the error event as a non-fatal warning (correctable error event) instead of sending it as an uncorrectable error signal, to avoid system reset. |
|
Purpose |
Improve the uptime and reliability of the system by allowing the system to continue operation when a poison mark is present on faulty data. |
|
Configuration |
Enabled by default and cannot be disabled. |
|
Remarks |
N/A |
PCIe ECRC
|
Feature name |
PCIe ECRC |
|
Description |
When an uncorrected error is detected before a group is forwarded to the next proxy, the EP bit is appended to the header to maintain bidirectional data integrity at the transaction layer. The receiver detects TLPs with poison tags and redirects the error event as a non-fatal error (correctable error event) instead of sending it as an unrecoverable error signal, thus avoiding a system reset. |
|
Purpose |
Mark data as poison when a fault occurs, allowing the system to continue running, increasing normal operation time and reliability. |
|
Configuration |
Disabled by default and can be enabled from the BIOS. |
|
Remarks |
N/A |
PCIe enhanced downstream port containment (eDPC)
|
Feature name |
PCIe enhanced downstream port containment (eDPC) |
|
Description |
Downstream Port Containment (DPC) allows data transmission to be stopped when an uncorrectable error is detected on the downstream port or on a device connected to the downstream port. This can avoid the propagation of potentially corrupted data and allow software to restore the data. eDPC is an enhancement to the DPC function, which adds support for the Root Port Programmable IO (RPPIO) error. |
|
Purpose |
Improve the system reliability. |
|
Configuration |
Disabled by default and can be enabled from the BIOS. |
|
Remarks |
Make sure the OS has the DPC processing capability for link recovery. |
PCIe card surprise hot plug
|
Feature name |
PCIe card surprise hot plug |
|
Description |
This feature complies with the PCI Express protocol and does not require the OOB SMBus mechanism for hot removal and insertion. |
|
Purpose |
Remove or install a PCIe module during the system operation. |
|
Configuration |
Disabled by default and can be enabled from the BIOS. |
|
Remarks |
· Proper software operations are required for the unexpected removal. · For information about support for PCIe slots, see the product manual. |
PCIe card hot-plug (add/remove/swap)
|
Feature name |
PCIe card hot-plug (add/remove/swap) |
|
Description |
This feature complies with the PCI Express protocol and requires the OOB SMBus mechanism for hot removal and insertion. |
|
Purpose |
Remove or install a PCIe module during the system operation. |
|
Configuration |
Disabled by default and can be enabled from the BIOS. |
|
Remarks |
· Proper software operations are required for the unexpected removal. · For information about support for PCIe slots, see the product manual. |
Error reporting via IOMCA
|
Feature name |
Error reporting via IOMCA |
|
Description |
This feature allows IIO uncorrectable fatal and non-fatal errors to send error signals through MCE to improve the platform's diagnostic capabilities. If this feature is not available, all the IIO uncorrectable errors are reported through NMI or platform-specific error handlers that use SMI or ERROR_N[2:1] pins. |
|
Purpose |
Provide a uniform error reporting mechanism aligned with MCA for uncorrectable error signaling without relying on NMI. |
|
Configuration |
Disabled by default and configurable from the BIOS. |
|
Remarks |
N/A |
Integrated error handler
|
Feature name |
Integrated error handler |
|
Description |
This feature provides unified error reporting, which can collect error information from all internal and external PCIe devices under PCH and IIO. The error information is transmitted to the global IEH device through an internal message bus, and eventually generates related interrupts or external signals to notify BIOS or HDM for error processing. |
|
Purpose |
Provide the unified error reporting mechanism for PCIe devices. |
|
Configuration |
Disabled by default and not configurable. |
|
Remarks |
N/A |
Faulty DIMM isolation
|
Feature name |
Faulty DIMM isolation |
|
Description |
Faulty DIMM isolation is one of the fault management features of the servers using Intel Xeon processors. The platform can keep track of the number of correctable errors, carry out failure prediction analysis and scheduled services, and replace faulty components before the severity of the errors becomes uncorrectable. The platform system management will identify the root cause of the DIMM failure, map the faulty device, and schedule a repair. |
|
Purpose |
Improve the server availability and maintainability. |
|
Configuration |
Enabled by default. |
|
Remarks |
Out-of-band error log obtaining
|
Feature name |
Out-of-band error log obtaining |
|
Description |
This feature is an HDM-based RAS implementation. It uses a PECI interface to access MCA bank registers to obtain memory error logs, UPI error logs, and IIO AER logs. |
|
Purpose |
Improve the monitoring ability of HDM fault management system. |
|
Configuration |
Enabled by default and cannot be disabled. |
|
Remarks |
N/A |
Error injection
|
Feature name |
Error injection |
|
Description |
You can configure error ejection settings from the BIOS. After enabled, this feature tests the system performance by error injection. |
|
Purpose |
Improve the system reliability by providing the ability to verify RAS features. |
|
Configuration |
Disabled by default and can be enabled. |
|
Remarks |
N/A |
Predictive failure analysis
|
Feature name |
Predictive failure analysis |
|
Description |
This feature enables predictive analysis on various correctable error logs and trends to identify potential risks and suggest appropriate measures. It can be applied to different subsystems. |
|
Purpose |
Enhance system stability, and predict potential risks and take corresponding measures. |
|
Configuration |
Enabled by default and cannot be disabled. |
|
Remarks |
N/A |
Suppress inbound shutdown
|
Feature name |
Suppress inbound shutdown |
|
Description |
This feature allows HDM to control system reboot for error log collection, ensuring successful retrieval of error logs without any failures caused by in-band system restart. |
|
Purpose |
Improve the monitoring ability of HDM fault management system. |
|
Configuration |
Enabled by default and configurable from the BIOS. |
|
Remarks |
N/A |
Demoted warm reset
|
Feature name |
Demoted warm reset |
|
Description |
In some cases, global reset is downgraded to warm reset for the BIOS to collect error information after reboot. When the system encounters a catastrophic error and the error information cannot be collected through OOB, use this feature to collect some sticky registers after the system warm reset. These error messages can be used as an important reference for error location. |
|
Purpose |
Improve the system maintainability. |
|
Configuration |
Enabled by default and not configurable. |
|
Remarks |
N/A |
MCA 2.0 recovery
|
Feature name |
MCA 2.0 recovery (as per EMCA gen2 architecture) |
|
Description |
EMCA gen2 allows firmware to intercept errors (correctable and uncorrectable errors) triggered by MCA and enables FFM of error handling and possible recovery. |
|
Purpose |
Recover the system from uncorrectable errors defined by the EMCA Gen2 specification through the software layers. |
|
Configuration |
Disabled by default and configurable. |
|
Remarks |
N/A |
MCA recovery – execution path
|
Feature name |
MCA recovery – execution path |
|
Description |
This feature assists the server to recover from uncorrectable errors through the software layers. The software layers including OS, VMM, DBMS, and applications, can assist the system to recover from uncorrectable errors at the hardware level, and mark the errors as corrupt data through the processors. If a processor identifies an error that cannot be corrected by hardware, the processor marks the data as corrupt data and hands the error event firmware and/or the OS. If the firmware or operating system has a redundant copy of the data, the error might be corrected. If the error occurs in the application space, the operating system can use the SIGBUS event to signal the application and allow further recovery or termination of the application and keep the operating system running. If the error occurs in the kernel space, the operating system will trigger a kernel panic. |
|
Purpose |
Recover the system from uncorrectable errors through the software layers. |
|
Configuration |
Enabled by default and cannot be disabled. |
|
Remarks |
OSs recommended: WS 2008 or higher, REHL 6 or higher, and SUSE 11 or higher. |
MCA recovery – non-execution path
|
Feature name |
MCA recovery – non-execution path |
|
Description |
For some uncorrectable errors on non-execution paths, the OS can recover or isolate faulty data. The non-execution paths include patrol scrub events or LLC explicit write back transaction processing. If a processor identifies an error that cannot be corrected by hardware, the processor marks the data as corrupted data and hands the error to firmware and/or the OS. The OS isolates the affected page and prevents applications from using it. This allows the system to continue to operate correctly. If the error occurs in the kernel space, the OS might not be able to isolate the faulty page and can only log the error and continue normal operation. |
|
Purpose |
Improve the system availability through the software layers. |
|
Configuration |
Enabled by default and cannot be disabled. |
|
Remarks |
OSs recommended: WS 2008 or higher, REHL 6 or higher, and SUSE 11 or higher. |
Local machine check exceptions (LMCE) based recovery
|
Feature name |
Local machine check exceptions (LMCE) based recovery |
|
Description |
LMCE allows the system to deliver the SRAR-type UCR events to the affected logical processors receiving poison data. LMCE implements following functions: · Enumeration—Identifies the hardware that supports LMCE through software. · Control mechanism—UEFI has the ability to enable or disable LMCE. This requires the software to enter LMCE. · Identification of LMCE—The software can identify whether the delivered MCE is only for one logical processor on MCE delivery. |
|
Purpose |
Prevent software from broadcasting SRAR-type UCR errors to all threads. |
|
Configuration |
Disabled by default and configurable. |
|
Remarks |
Corrupt data containment – Uncore must be enabled. |
Viral mode
|
Feature name |
Viral mode |
|
Description |
The viral mode is an advanced fault-tolerant feature designed for fatal errors. It is used to prevent faults from spreading to non-volatile storage devices or network devices. Errors that can cause the processor to enter the viral mode are all uncorrectable errors. |
|
Purpose |
Control the spread of errors. |
|
Configuration |
Enabled by default and configurable from the BIOS. |
|
Remarks |
Enable the poison mode first. |
Asynchronous MCA error injection (aka MCA bank spoofing error injection)
|
Feature name |
Asynchronous MCA error injection (aka MCA bank spoofing error injection) |
|
Description |
This feature allows the OS or BIOS to simulate error occurrence by writing to the MCA Bank registers. |
|
Purpose |
Provide the capability to verify RAS features, ensuring system reliability. |
|
Configuration |
Disabled by default and configurable from the BIOS. |
|
Remarks |
N/A |
Hot swappable power supplies in N+N redundancy
|
Feature name |
Hot swappable power supplies in N+N redundancy |
|
Description |
The power supplies can be hot swapped at the server rear. |
|
Purpose |
Ensure the reliability of the power system. |
|
Configuration |
Enabled by default and cannot be disabled. |
|
Remarks |
N/A |
Hot swappable fan modules in N+1 redundancy
|
Feature name |
Hot swappable fan modules in N+1 redundancy |
|
Description |
The fan modules support N+1 redundancy. The server can operate correctly when a single fan fails. You can hot swap a fan module. |
|
Purpose |
Ensure the reliability of the server heat dissipation system. |
|
Configuration |
Enabled by default and cannot be disabled. |
|
Remarks |
N/A |
Hot swappable OCP network adapters
|
Feature name |
Hot swappable OCP network adapters |
|
Description |
This feature provides the support of an OCP slot. You can hot insert or remove an OCP network adapter directly from the device back panel. |
|
Purpose |
Ensure that the OCP network adapter can be hot swappable. |
|
Configuration |
Enabled by default and cannot be disabled. |
|
Remarks |
You must use OCP network adapters and operating systems specified in H3C compatibility matrixes.. |
Hot swappable drives and RAID controllers
|
Feature name |
Hot swappable drives and RAID controllers |
|
Description |
RAID levels 0, 1, 1 ADM, 10, 10 ADM, 1E, 5, 50, and 60 are supported. The drives are hot swappable. |
|
Purpose |
Ensure the availability of the storage system. |
|
Configuration |
RAID arrays require scheduled configuration |
|
Remarks |
Support for RAID levels varies by RAID controller configuration. |
Drive fault location
|
Feature name |
Drive fault location |
|
Description |
The server supports locating a single drive fault. |
|
Purpose |
Quickly locate drive faults. |
|
Configuration |
Enabled by default and cannot be disabled. |
|
Remarks |
N/A |
Power fail safeguard
|
Feature name |
Power fail safeguard |
|
Description |
When a system power failure occurs, the supercapacitor of a power fail safeguard module can provide power for a short period of time for data to be transferred from the DDR memory to the flash card. When the power recovers, the data can be transferred back to drives. |
|
Purpose |
Prevents data loss caused by unexpected power failure. |
|
Configuration |
Enabled by default and cannot be disabled. |
|
Remarks |
Because of RAM battery capacity limit, the data can be protected for hours or tens of hours. The actual time depends on the supercapacitor model. |
Drive fault monitoring and data recovery
|
Feature name |
Drive fault monitoring and recovery |
|
Description |
This feature enables the system to inform users of physical drive or logical drive faults through in-band or out-of-band (SEL log reporting) channels. In a scenario where RAID is configured on the server, the feature can use RAID array features to recover data in failed drives. |
|
Purpose |
Enables fast fault identification to prevent error expansion and helps data recovery through RAID. |
|
Configuration |
Enabled by default and cannot be disabled. |
|
Remarks |
N/A |
RAID controller fault location
|
Feature name |
RAID controller fault location |
|
Description |
RAID controller faults can be displayed in many ways. For example, overtemperature errors can be reported by sensors and RAID controller operation events can be logged as log messages. |
|
Purpose |
Simplifies monitoring of RAID controller status and identifies RAID controller faults to accelerate troubleshooting. |
|
Configuration |
Enabled by default and cannot be disabled. |
|
Remarks |
This feature is only supported by LSI RAID controllers except the LSI 9300, 9311, and 9400 RAID controllers. |
Dual out-of-band management software images
|
Feature name |
Dual out-of-band management software images |
|
Description |
If the one image fails, HDM can start up by using the other image. |
|
Purpose |
Ensure the availability of HDM. |
|
Configuration |
Enabled by default and cannot be disabled. |
|
Remarks |
N/A |
Centralized fault management system
|
Feature name |
Centralized fault management system |
|
Description |
The fault management system comprehensively monitors the server, provides a reliable fault detection and prediction mechanism, and offers multi-dimensional alerts for users through HDM. The following faults can be detected: · Processor hardware failure, including CAT errors, self-check failure, and configuration errors. · Overtemperature alarms, including alarms at air inlet and outlet, processors, memory, power supplies, and drives. · Voltage faults on the server boards. · Fan module faults. · Power source faults, including power supply input lost (AC/DC), overtemperature conditions, and power supply fan failure. · DDR3 and DDR4 DIMM faults, including correctable ECC errors exceeding threshold, overtemperature conditions, and configuration errors. · Storage system faults, including LSI storage controller errors, SAS/SATA drive faults, and logical drive exception. · System shutdown. · Hardware operation status (via system health LED). · Faulty components (via SEL log messages) · HDM and OS reboot errors (via SEL log messages). |
|
Purpose |
Provide a unified fault management. |
|
Configuration |
Enabled by default and cannot be disabled. |
|
Remarks |
N/A |
Location of faulty processors
|
Feature name |
Location of faulty processors |
|
Description |
Review the SEL log from HDM and report the location of a faulty processor. |
|
Purpose |
Quickly locate a faulty processor. |
|
Configuration |
Enabled by default and cannot be disabled. |
|
Remarks |
N/A |
Location of faulty DIMMs
|
Feature name |
Location of faulty processors |
|
Description |
Review the SEL log for the location of a faulty DIMM from HDM. |
|
Purpose |
Precisely locate a faulty DIMM. |
|
Configuration |
Enabled by default and cannot be disabled. |
|
Remarks |
N/A |
Location of faulty PCIe devices
|
Feature name |
Location of faulty PCIe devices |
|
Description |
Review the SEL log for the location of a faulty PCIe device from HDM. |
|
Purpose |
Precisely locate a faulty PCIe device. |
|
Configuration |
Enabled by default and cannot be disabled. |
|
Remarks |
N/A |
Location of faulty power supplies
|
Feature name |
Location of faulty power supplies |
|
Description |
Review the SEL log for the location of a faulty power supply from HDM or use power supply LEDs to identify the faulty power supply. |
|
Purpose |
Quickly locate a faulty power supply. |
|
Configuration |
Enabled by default and cannot be disabled. |
|
Remarks |
N/A |
Location of faulty fan modules
|
Feature name |
Location of faulty fan modules |
|
Description |
Review the SEL log for the location of a faulty fan module from HDM. |
|
Purpose |
Quickly locate a faulty fan module. |
|
Configuration |
Enabled by default and cannot be disabled. |
|
Remarks |
N/A |
System board monitoring and environment information from HDM
|
Feature name |
System board monitoring and environment information from HDM |
|
Description |
HDM monitors the voltage, current, temperature, and power of key components in real time and provides corresponding graphics. Data are recorded by period. |
|
Purpose |
HDM monitors the voltage, current, temperature, and power of key components in real time and provides corresponding graphics. |
|
Configuration |
Enabled by default and cannot be disabled. |
|
Remarks |
N/A |
Remote update of system software and firmware from HDM
|
Feature name |
Remote update of system software and firmware from HDM |
|
Description |
HDM supports remote maintenance and update of the system software and firmware |
|
Purpose |
Improve the maintainability. |
|
Configuration |
Enabled by default and cannot be disabled. You can update the software and firmware from HDM. |
|
Remarks |
N/A |
BSoD screenshots
|
Feature name |
BSoD screenshots |
|
Description |
This feature automatically takes a bluescreen of death (BSoD) screenshot upon a system crash of Windows for future troubleshooting. HDM can save a maximum of 10 BSoD screenshots, which are named with a sequence number and the screenshot time. When the maximum number of screenshots is reached, a new BSoD screenshot overwrites the oldest one. |
|
Purpose |
View snapshots upon shutdown to help locate faults when a system shutdown occurs. |
|
Configuration |
Enabled by default and can be disabled from HDM. |
|
Remarks |
· Make sure the KVM service has been enabled. · HDM can save a maximum of 10 BSoD screenshots |
Video replay
|
Feature name |
|
|
Description |
This feature records the server status upon occurrence of severe operating system events, including crash, restart, and shutdown. You can replay these videos to analyze or troubleshoot the recorded events. |
|
Purpose |
Help locate faults by viewing videos from HDM. |
|
Configuration |
Enabled by default and can be disabled from HDM. |
|
Remarks |
· Make sure the KVM service has been enabled. · If the remote console is open when an event triggers video recording, video recording will fail. · Crash event recording is available only for the Windows operating system. · If the operating system is in sleep state when an event occurs, the video replay displays no signal. |
Log download
|
Feature name |
Log download |
|
Description |
This feature enables users to download SDS logs during runtime, including operation logs, event logs, component logs, static logs, and HDM system logs. You can use UniSystem to parse event logs and storage logs to learn about the server operation status. You can download the log entries for a period or download the entire log to an .sds log file. SDS log messages record context for every error, provide simple recommended actions, and allow message obtaining through multiple in-band or out-of-band methods. Information is provided in plaintext and is easy to use. |
|
Purpose |
Improve the serviceability by providing fault location ability through faulty data collection, fault analysis, and fault diagnosis. |
|
Configuration |
Enabled by default and can be downloaded from HDM. |
|
Remarks |
You cannot view the logs from HDM. To view the log entries, download the log entries to an .sds log file and import the .sds log file to UniSystem. |
Appendix A Glossary
|
Word/Acronym |
Definition |
|
ADDDC |
Adaptive Double Device Data Correction |
|
AER |
Advanced Error Reporting |
|
BIOS |
Basic Input Output System |
|
BIST |
Built in Self-Test |
|
CDC |
Corrupt Data Containment, also known as Data Poisoning |
|
Core |
A portion of a processor containing the processing units such as Execution Engine (EE) and the dedicated caches |
|
CHA |
Cache and Home Agent |
|
CMCI |
Corrected Machine Check Interrupt |
|
CRC |
Cyclic Redundancy Check |
|
CXL |
Compute Express Link™, an open interconnect protocol between CPUs and the accelerator. |
|
DCU |
Data Cache Unit, a L1 cache |
|
DMI |
Direct Media Interface, proprietary data path between Intel CPU and PCH |
|
DIMM |
Dual-Inline-Memory-Module, a memory device on a socketable substrate |
|
ECC |
Error Checking and Correcting |
|
EDPC |
Enhanced Downstream Port Containment |
|
EMCA |
Enhanced Machine Check Architecture |
|
FFM |
Firmware First Model |
|
FW |
Firmware |
|
FRB |
Fault Resilient Boot |
|
HBM |
High Bandwidth Memory |
|
HDM |
H3C Device Management, IPMI-compliant module-level management controller developed by H3C |
|
HW |
Hardware |
|
ICU |
Instruction Cache Unit |
|
IEH |
Integrated Error Handler |
|
IFU |
Instruction Fetch Unit |
|
IIO |
Integrated I/O Module |
|
IMC |
Integrated Memory Controller |
|
LLC |
Last Level Cache (L3 cache) |
|
LPC |
Low Pin Count, used to connect to I/O devices |
|
MCA |
Machine Check Architecture |
|
MCC |
Medium Core Count |
|
MCE |
Machine-Check Exception |
|
MDF |
Modular Die Fabric |
|
MLC |
Mid Level Cache |
|
MRC |
Memory Reference Code |
|
OS |
Operating system |
|
PCH |
Platform Controller Hub |
|
PCIe |
Peripheral Component Interconnect Express |
|
PCLS |
Partial Cache Line Sparing |
|
PCU |
Power Control Unit |
|
POST |
Power On Self Test |
|
RAS |
Reliability, availability, serviceability |
|
Runtime |
OS runtime |
|
SDDC |
Single device data correction (DIMM CRC) |
|
SMI |
System Management Interrupt |
|
TLP |
PCI Express Transaction Layer Packet |
|
UEFI |
Unified Extensible Firmware Interface |
|
Uncore |
Functionality in processor socket other than processor cores. It encompasses CHA, M2M, Intel®UPI, IMC, IVR, PCU, and UBOX. Note that IIO module is considered as outside of the Uncore but it is still integrated in the same die. |
|
UPI |
Ultra Path Interconnect |
|
VT-d |
Intel Virtualization Technology For Directed I/O |
|
XCC |
Extreme Core Count |
