Management functions
Applications are classified into container applications and host applications, depending on the deployment location of applications.
Access mode
Access mode for container applications
Service
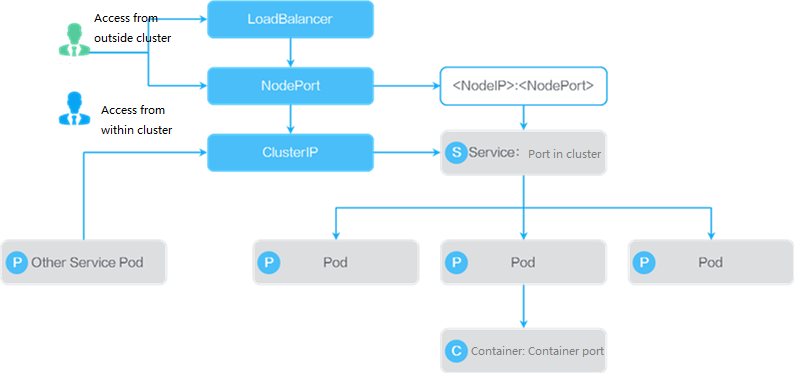
A Service is an entry for providing services in Kubernetes and allows an application to access another application. A Service represents a group of pods. The pod IP address is random and might change upon a restart. A cluster IP address for the Service remains unchanged after assignment. Kubernetes is responsible for establishing and maintaining service-to-pod mappings. You can access the IP address of the Service, and users are not affected no matter how backend pods change. A Service provides the following methods of accessing containers:
Access from outside the cluster: The Service exposes an external port for all instances of an application to be accessed at the cluster's virtual IP address or a node IP address and the external port number from outside the cluster. Configure the external port number according to cluster port planning and the network environment.
Load balancer: The IP address and port number of each node are registered with a load balancer. When receiving a request, the load balancer selects a node for the request. Then, the request reaches the container through the Service port and container port.
Node access: The request reaches the container through the node IP address, node port number, Service port, and container port.
Access from within the cluster: The request reaches the container through the cluster IP address, Service port, and container port.
This domain name-based access method is available only within the cluster. You can use either TCP or UDP for container access. The container port is the port listened to by the application. The cluster internal port can be any available port. As a best practice, use the same port as the cluster internal port and container port.
Instead of using access based on IP addresses or microservice gateways, containerization enables access to multiple instances of an application by using a Layer 4 LB proxy that distributes requests by using a round robin or randomized algorithm.
To employ the fault tolerance and LB capabilities of the system, configure access modes for IP address-based applications to access one other, and configure instances of applications that use a registration center, such as spring boot, to use their internal access addresses for registration.
Access from outside the cluster requires the same port to be open on all nodes in the cluster, which might result in node access issues or heady access load for the virtual IP address. As a best practice, configure ingresses to provide access to the services exposed to the external environment.
Table-1 Service architecture
Ingress (application domain name)
An Ingress allows an application to access another application through a domain name. Similar to a routing rule, an Ingress routes traffic to the container through a domain name. To use this access mode, you must configure a mapping between the domain name and the virtual IP address of the cluster where the container resides.
App access path
This access method allows you to access an application through IP (domain name):port number/path.
Network policy
A network policy implements policy-based network control and allows you to specify remote ends that can access local container ports through an allowlist. This access mode helps isolate applications and reduce attack risks. To use this access mode, you must install the Calico, Romana, Weave Net, and trireme plug-ins. The system has been installed the Weave Net plug-in by default. Container applications deployed on the MCP cluster do not support network policies.
Access mode for host applications
Host applications can provide services by using two methods: application domain name and app access path.
Application domain name
Traffic is routed to the corresponding hosts through the domain name. To use this access method, you must configure the mappings between domain names and hosts on the DNS server. You can also use the following load balancing methods for access reliability.
Load balancing across multiple instances
The following load balancing methods are supported: round robin, least connections, and IP hash.
IaaS load balancing
Uses IaaS load balancing to direct traffic to multiple backend cloud hosts according to the forwarding policy.
App access path
This access method allows you to access an application through IP (domain name):port number/path.
Elastic scaling
Elastic scaling allows you to adjust the number of pod or application instances based on business needs to improve resource usage and reduce operational expenses of enterprises.
Container applications support the following scaling methods:
Automatic scaling—Enable the system to automatically adjust the number of pod instances in accordance with changes of criteria such as the CPU or memory usage, HTTP request rate, minimum or maximum number of pod instances.
Manual scaling—Manually set the number of pod instances. For an MCP cluster, you can increase or decrease the number of pod instances on different member clusters.
One-off scaling—Enable the system to set the number of pod instances to a preset value at a specific point in time.
Scheduled scaling—Enable the system to set the number of pod instances to a preset value at a fixed point in time each day in a time range.
Host applications support the following scaling methods:
Automatic scaling—Enable the system to automatically adjust the number of application instances in accordance with changes of criteria such as the check period, CPU or memory usage, TCP connection count, maximum number of backend services.
Manual scaling—Manually set the number of cloud host instances.
Application routes
Application routes allow you to access multiple applications through one rule.
Application upgrade
|
|
· Applications deployed to a single cloud host instance support only replacement upgrade and grayscale upgrade. Applications deployed to multiple cloud host instances support only rolling upgrade, grayscale upgrade, and replacement upgrade. · Applications deployed to a container cluster or a member cluster managed by an MCP cluster support only rolling upgrade and grayscale upgrade. · To perform a grayscale upgrade, you must configure Ingress as the access mode. |
The system offers the following application upgrade methods:
Replacement upgrade—Uses a new version to replace the old version. Compared with other upgrade methods, replacement upgrade requires the least resources, but it does not guarantee service availability as no old version is available to back up the new version.
Rolling upgrade—Upgrades one service instance at a time to prevent the upgrade from interrupting service. For each service instance, the system creates and starts a new version before it stops the old version. During rolling upgrade, an application always has running replicas, which allows for application upgrade with zero downtime. Rolling upgrade saves resources, but it is complex to roll back an application upgraded through rolling upgrade.
Grayscale upgrade—Deploys a new version to load share traffic based on a traffic assignment ratio with the old version and then switches all traffic to the new version if the new version can run correctly. Grayscale upgrade features stable and smooth upgrade with zero downtime, low risks, and simple rollback. However, it requires twice resources than those used in the other methods because the system needs to run the old and new versions simultaneously.
Application rollback
An application stores all history versions after an upgrade. You can select a history version to roll back to.
Application report
You can view, filter, and export application data.
Health check
Health check periodically checks the availability of applications to recover or isolate abnormal application instances and reduce request errors. It restarts unrecoverable abnormal application instances and cooperates with the Layer 4 LB function to remove instances unable to respond to requests from the LB pool. As a best practice to ensure application availability, enable health check for applications.
Health check can be performed by sending an HTTP request, sending an HTTP request, or opening a TCP socket, and all of these methods require reliable application state data to be provided to detect application availability.
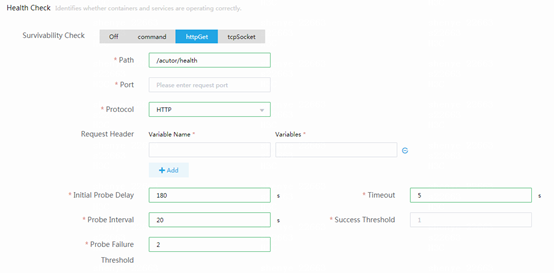
For example, you can use the /actuator/health interface of the spring boot application to obtain the application state if you use the HTTP request method for health check. This interface can check the state of the middleware, database, and disks used by services for issues such as database connection failure. Those issues cannot recover automatically, but they can be resolved by restarting the application.
As shown in the following figure, set the initial startup delay to be longer than the time used to start up the service when you configure the survivability check. This restriction ensures that the service can start up successfully. Make sure the following requirement is met: Initial startup delay + probe interval × failure threshold > service startup time. As a best practice, set the probe interval to 20 seconds or longer, and set the failure threshold to 3. To avoid frequent service restarts, make sure the timeout time is not shorter than the average response time of the /actuator/health interface.
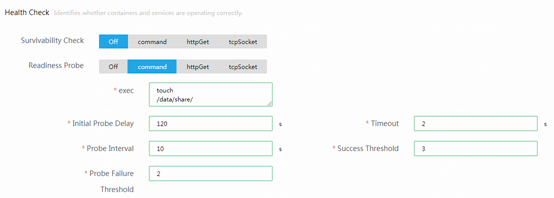
You can use the command method for the readiness probe. For example, you can periodically create a key file to verify readiness of a service.
As shown in the following figure, if you set the probe frequency to 10 seconds and failure threshold to 2, the service will be removed from the LB pool 20 seconds after the service becomes unavailable. Set the initial startup delay to be longer than the time used to start up the service, and set the timeout time to 1 second or shorter.
For the survivability check, the HTTP request method is used more frequently than the command and TCP socket method, because the HTTP request method can call an interface to detect the overall status of a service that uses multiple modules. For the readiness probe, you can use an interface that tests whether an instance can respond to requests correctly.
Application analyzer
Application analyzer helps locate faults and time-consuming phases for an abnormal service.