管理功能
对应用的管理根据应用的部署位置区分为容器应用和主机应用两种。本平台支持对各类应用的如下管理功能。
访问方式
容器应用访问方式
应用管理为容器应用提供了服务、应用域名、应用访问路径和网络策略四种对外提供服务的方式。
服务
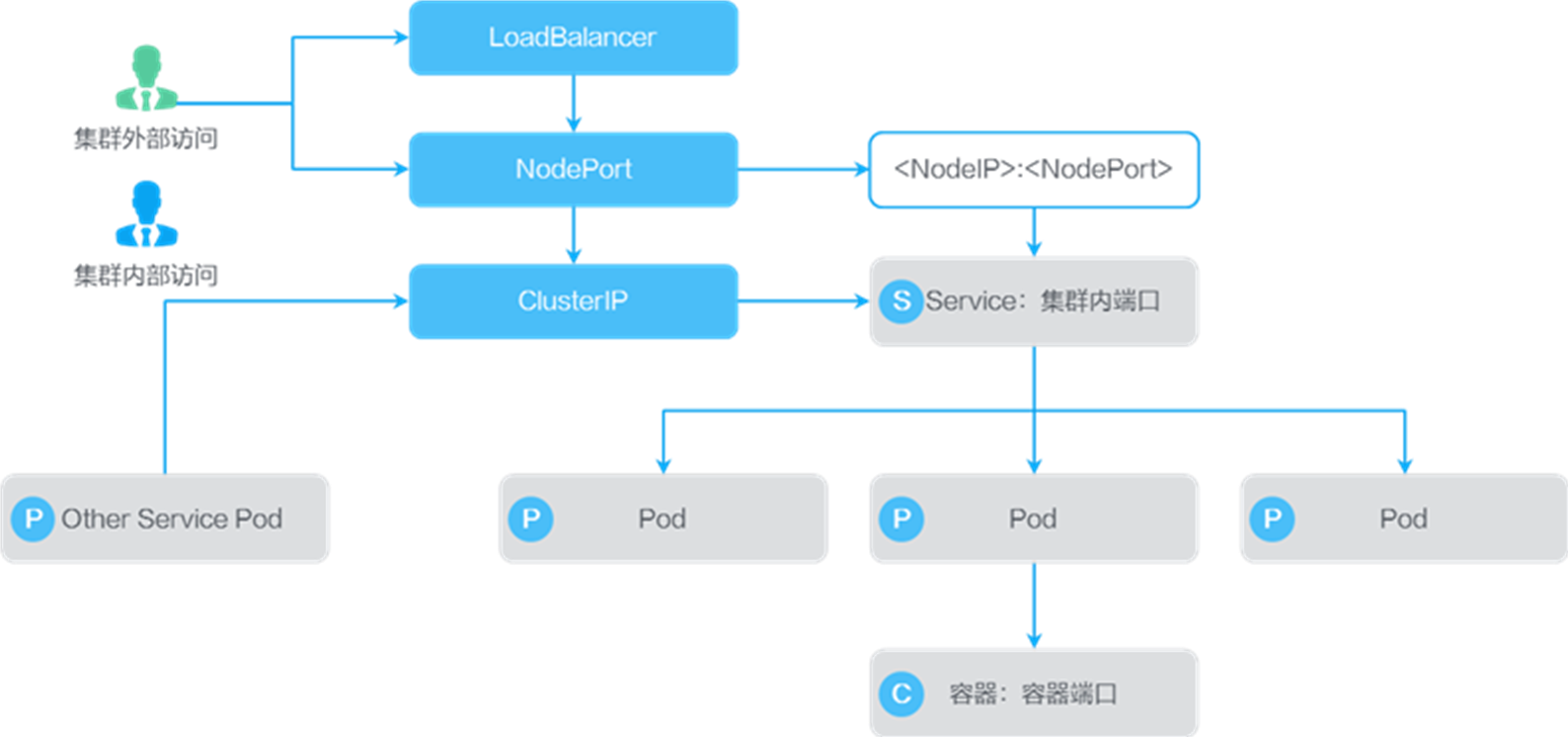
“服务”(即Service)是Kubernetes中应用提供服务的入口,是一个应用访问另一个应用的方式。Service代表一组Pod,由于Pod IP是随机的,且可能会因重启改变,因此不应该直接访问Pod IP。而集群IP是Service在集群中的具体实现,该IP地址一经创建便不会改变。Kubernetes负责建立和维护Service与Pod的映射关系,因此用户只需要访问Service的IP,无论后端Pod如何变化,对用户都不会有任何影响。Service提供了两种访问容器服务的方式:
集群外访问,通过一个对外端口暴露服务,集群外可以通过集群的VIP或者任意节点IP加端口访问此应用的所有实例:
负载均衡(LoadBalancer):将各节点IP和端口注册到负载均衡中,请求访问时,通过负载均衡选择合适的节点,然后通过Service端口和容器端口访问对应容器。
节点访问:请求通过节点IP、节点端口、Service端口和容器端口访问对应容器。
集群内访问(ClusterIP):通过集群IP、Service端口和容器端口访问对应容器。只能在集群内部使用该访问方式(域名)访问。设置上,协议根据实际情况选择TCP还是UDP,容器端口为应用程序本身所监听的端口,集群内部端口可以随意填写为了减少出错一般建议跟容器端口一致。集群外部端口需要根据集群限制和环境网络限制填写。
相对于之前通过IP或者微服务网关去访问一个应用的多个实例,容器平台可以通过一个四层负载均衡代理(负载算法根据版本的不同使用轮询或随机)来访问一个应用的多个实例。
为了发挥平台的容错和负载均衡能力,对于之前通过IP访问的应用,相互调用通过创建访问方式访问,对于使用注册中心的应用(如spring boot),应用实例应该将内部访问方式作为自己的地址进行注册。
外部访问方式会在集群的所有节点开启同一个端口,这会导致端口占用,访问时存在单节点问题或者VIP节点压力问题,因此一般不建议这样。对于需要外部暴露的服务建议使用ingress(路由)访问。
图-1 Service架构图
应用域名
“应用域名”(即Ingress)可以允许Kubernetes中一个应用通过域名访问另一个应用,相当于一种“路由规则”,即通过域名将访问流量路由到对应容器。使用应用域名作为访问方式,需首先在DNS上配置域名与容器所在集群VIP的对应关系。
应用访问路径
可通过配置“IP(域名):端口号/path”的方式配置访问应用的路径,通过该路径访问应用。
网络策略
网络策略为应用提供了基于策略的网络控制,以白名单的方式支持指定远端访问本端容器端口,用于隔离应用并减少攻击面。使用网络策略作为访问方式的集群需要安装网络插件如Calico、Romana、Weave Net和trireme,系统默认已安装了Weave Net插件。
主机应用访问方式
为主机应用提供了应用域名、应用访问路径两种对外提供服务的方式。
应用域名访问
通过域名将访问流量路由到对应主机。使用应用域名作为访问方式,需首先在DNS上配置域名与主机的对应关系。配置应用域名访问,还可以采用两种负载均衡的方式,来实现访问的可靠性。
多实例的负载均衡:支持轮转调度、最小连接和三列求余的三种方式的负载均衡。
IaaS负载均衡:需配合IaaS负载均衡服务使用,将访问流量根据转发策略分发到后端多台云主机上。
应用访问路径
可通过配置“IP(域名):端口号/path”的方式配置访问应用的路径,通过该路径访问应用。
弹性伸缩
对Pod实例的个数进行调整。根据用户的业务需求,通过设置伸缩来自动增加/缩减业务资源。这样灵活扩展或者收缩资源,提高资源利用效率,帮助企业降低运营成本。
容器应用:支持自动伸缩、手动伸缩、定时伸缩、周期伸缩四种方式。
自动伸缩:通过对CPU/内存使用率或HTTP请求速率、最小/最大实例数等阈值的配置,使系统根据监控情况自动调整服务中Pod实例的个数,保证系统业务平稳健康的运行。
手动伸缩:用户可根据需求手动设置Pod实例的个数,系统会将实例数量调整至设置预期。
定时伸缩:系统将在到达设置的触发时间时自动将实例数量调整至设置的预期值。
周期伸缩:在所选择的日期范围内,每天到达触发时间时自动将实例数量调整至设置的预期值。
主机应用:支持自动伸缩、手动伸缩两种方式。
自动伸缩:通过对检查周期、CPU/内存使用率、TCP连接数、最大后端服务数等阈值的配置,使系统根据监控情况自动调整服务中应用实例的个数,保证系统业务平稳健康的运行。
手动伸缩:通过修改云主机实例个数进行扩缩容。
应用路由
当前系统支持针对每个应用的域名创建功能,实现通过域名访问应用。同时,还可以创建全局通用的应用路由,方便用户通过一个规则一次性访问多个应用。
应用升级
应用升级包括替换升级、滚动升级和灰度升级三种策略。
|
|

替换升级:旧版本直接全部被新版本替换。优点是不占用更多的资源,缺点是一旦新版本出现问题,由于没有旧版本承担业务,会导致业务的中断。
滚动升级:默认的升级策略,通过新的服务实例逐个更新来实现零停机的部署升级,即先升级并启动一台新版本,再停止其老版本,使得在整个滚动过程期间,保证始终有可用的副本在运行,从而平滑地发布新版本。优点是节约资源,不需要同时运行两倍的实例个数,缺点是回滚过程困难。
灰度升级:在进行灰度升级时,不停止老版本,同时会部署一套新版本,用户可自定义配置新旧版本间的流量权重,新旧版本按照流量权重承担流量,同时对外提供服务。待新版验证完毕即可完成升级或取消升级,可以保证整体系统的稳定和平滑过渡。优点是无需停机,风险较小,回滚简单,缺点是同时运行新旧两套版本,需要两倍的资源。
应用回滚
升级后的应用会保留所有历史版本,您可以选择某个历史版本将应用回退到历史状态。
应用报表
本系统提供应用报表,您可以浏览、查询和导出应用数据。
健康检查
健康检查通过指定方式定期判断应用状态,在应用异常无法恢复时重启实例,配合平台的4层负载均衡(访问方式)在实例无法响应请求时将实例从负载均衡池中删除。健康检查能够及时解决或隔离异常实例,解决因个别实例异常导致请求异常的问题,因此强烈建议应用配置健康检查。
健康检查方式有三种,command,httpGet和tcpSocket。无论使用哪种方式,必须从业务的角度确认这个探测命令(接口)确实能够真实反映应用状态。否则很难通过此检查获得预期效果。
使用httpGet探测方式,必须要有一个接口能够反映当前应用的真实状态。spring boot应用的health接口(/actuator/health)能够检查业务用到的中间件数据库、磁盘等方方面面的状况, 因此对于spring boot应用若无其它业务需求可以直接使用此接口。这种接口探测到的问题(如数据库连接失败)无法自行恢复,但是重启应用有可能解决此问题。因此这种类型的接口适合作为存活性探测接口。
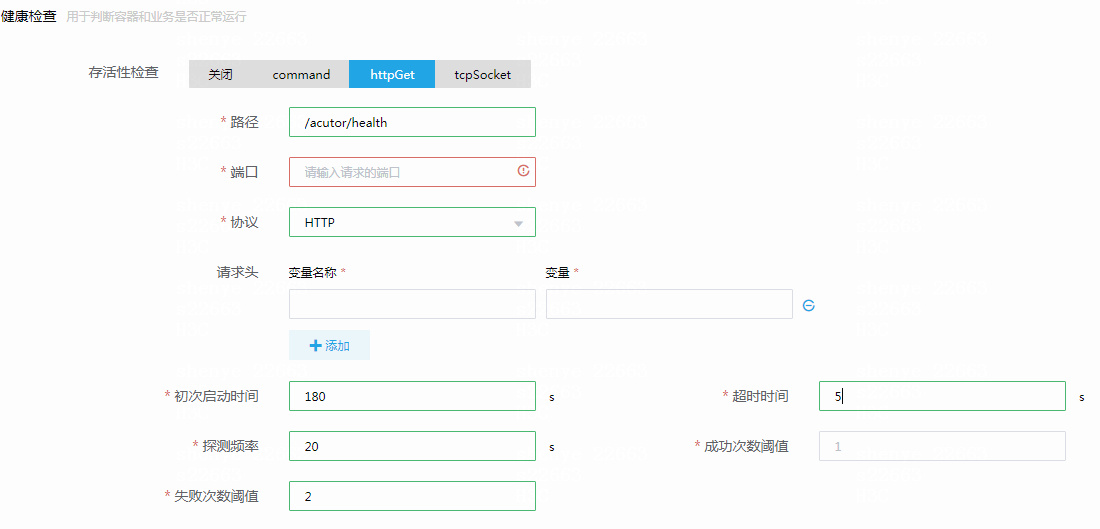
配置如上图所示,检查的初次启动时间必须要大于服务实际启动时间(初始启动时间+探测频率×失败阈值 > 服务实际启动的时间),否则会造成服务无法启动。建议配置较大的探测频率值,一般建议20s左右或者更大。失败阈值一般建议3次左右,超时时间需要根据接口实际响应时间来确定,不小于接口平均响应时间,否则会因为超时导致服务重启。
使用command方式检查服务的可用性,假定一个服务只有文件读写容易出问题,其它部分基本不会出现问题,则可以通过一个定期创建文件的操作来检查服务是否可用。
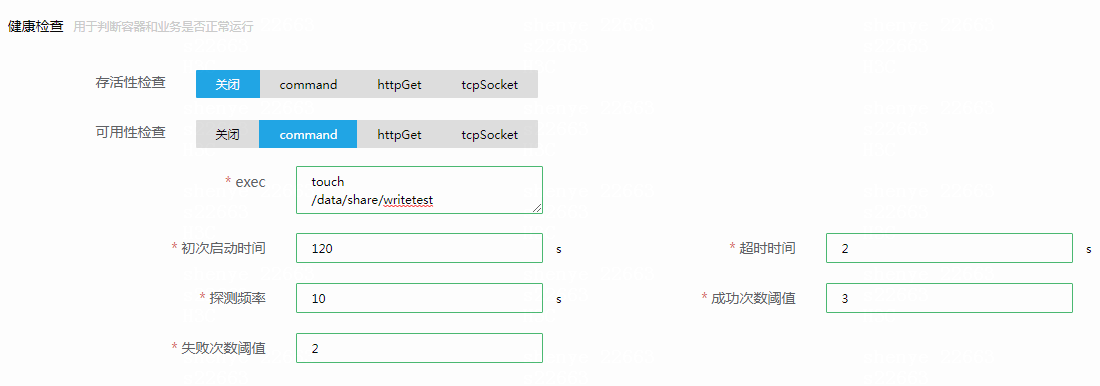
如上图所示,其中探测频率建议10s,这样如果发生异常会在检测到异常后的20s(频率×失败阈值)从负载池摘除该服务。初次启动时间应该参考业务启动时间,一般为业务完成启动的时间。超时时间不超过1s,执行命令的时间一般较短因此不需要过长的超时时间。
总之,httpGet是比较常见的健康检查方式,对于一个业务来说一般很难通过command或者socket连接就能判断应用是否正常。通常一个服务往往会使用多个模块,而出问题时往往是部分模块,这不会导致进程退出,因此通过socket或者command难以探测服务真实情况。对于可用性检查的接口一般可以反映当前实例是否可以正常响应请求,存储性检查接口一般可以探测到各个部分是否正常。
应用诊断
应用诊断能够在业务出现异常时定位异常点或耗时点,有助于业务问题的排查。