共享自行车案例
数据运营平台是通过数据技术,对海量数据进行采集、清洗、加工,成为标准化、统一化的数据存储,形成大数据资产,进而为客户提供高效的、创新的服务。其中又以数据开发模块最为核心,将实际业务需求抽象为一个个实体,提供基于任务类型的代码组织方式。
本章旨在以业务流程中的“SparkSQL”节点为核心创建离线任务,展示开发及运维等过程的完整使用步骤。
案例说明
自行车共享系统是一种租赁自行车的方法,注册会员、租车、还车都将通过城市中的站点网络自动完成。通过该系统,人们可以根据需要从一个地方租赁一辆自行车然后骑到自己的目的地归还。
但在共享单车的运维过程中,不时出现一些共享单车长时间未有运行轨迹上报或无法准确监控到位置的情况。这就导致,在APP中可以看到很多可用单车,但走到对应位置时,才发现该位置没有单车或无法使用。这些单车中,有些单车不知道被藏到了哪里;有些车或许是在高楼的后面,因GPS的误差而找不到;有些车被放到了小区内,一墙之隔使骑车人无法取到单车,甚至使单车直接从GPS定位中消失等等。
为了获得这些单车的数据,确认这些车是否已经变成了“僵尸车”,本案例将通过业务流程中的SparkSQL节点将单车基本数据信息与实时更新的数据信息进行关联分析,筛出“僵尸车”。
环境与数据准备
配置运行环境
本例使用根组织下的默认工作空间defaultWorkspace,在进行数据处理的配置前,需要给该工作空间配置集群资源。
本例中,以业务数据在大数据集群的Hive数据库中为例,配置的集群需为Hive数据源所在的集群。
|
|
本例中前提为业务数据已存入对应工作空间所配置集群的Hive数据库中。 实际操作中,需注意避免对业务数据库执行操作,建议将业务数据抽取至专用的Hive数据库中,以免影响原始的业务数据。数据抽取可以通过[融合集成/数据集成]中创建作业来完成。 |
在顶部导航栏中选择[系统],进入系统模块。
在左侧导航树中,选择[大数据环境管理/大数据集群管理]菜单项,进入大数据集群管理页面。
在页面中,确认是否已存在集群。如已存在,请直接执行下一步骤。如不存在,请增加集群,步骤如下:
单击列表上方的<配置>按钮,弹出新增集群窗口。
图-1 新增集群
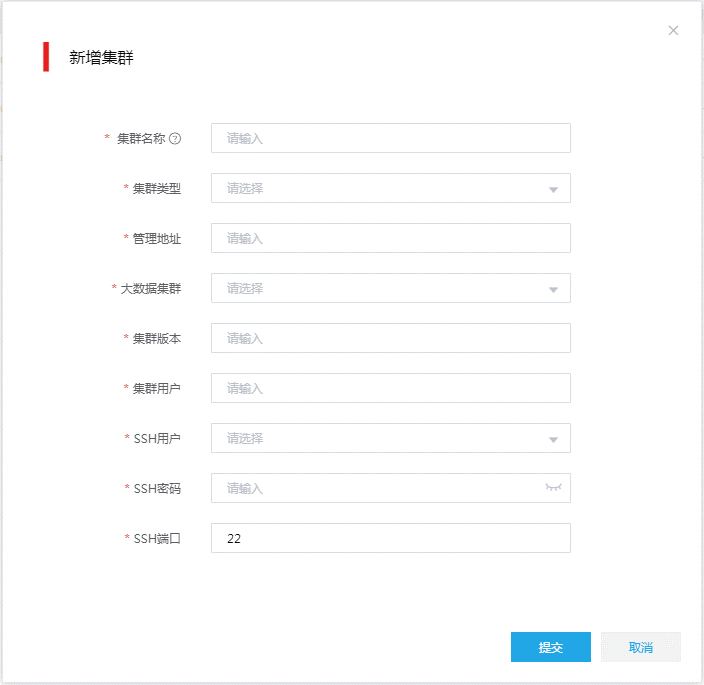
配置集群的参数信息。
集群名称:配置大数据集群在本系统中的名称,不可使用default关键字作为集群名称。
集群类型:选择集群的类型,即对接的大数据集群类型,通常为dataengine。
管理地址:输入大数据集群所在大数据平台的管理地址。输入完成后,系统会自动获取该地址对应大数据平台中的信息。
大数据集群:从下拉列表中选取需要的大数据集群。列表中的集群均为系统从大数据平台中自动获取,如无可选值,说明大数据平台中为创建符合要求的集群,或本系统与大数据平台连接故障。
集群版本:系统会自动获取版本号,对于DataEngine类型集群,支持E5202、E5203、E5205、E5301、E5302、E5303。
集群用户:系统自动根据所选的大数据集群填充。
SSH用户:配置连接大数据平台所需使用的SSH用户名。
SSH密码:配置SSH用户的登录密码。
SSH端口:指定SSH连接使用的端口,默认为22。
单击<提交>按钮,集群配置完成。
在左侧导航树中,选择[大数据环境管理/运行环境管理]菜单项,进入运行环境页面。
在“组织”页签中,确认是否已为根组织配置了集群资源。如已配置,请直接执行下一步骤。如未配置,请为根组织配置集群资源:
单击列表上方的<配置>按钮,弹出分配运行环境窗口。
图-2 配置组织运行环境
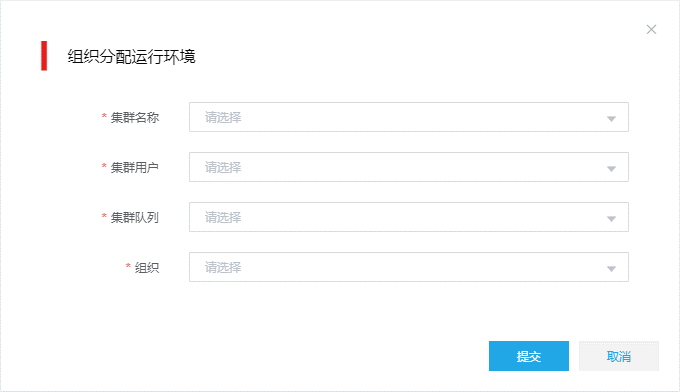
配置组织的运行环境参数。
集群名称:从下拉列表中选择大数据集群。列表中的集群即之前配置的大数据集群。
集群用户:从下拉列表中选择大数据集群的用户。
集群度列:从下拉列表中选择使用的队列,本例中选择root.default。
组织:选择集群资源分配给的目标组织。本例中选择根组织。
单击<提交>按钮,配置完成。
切换至“工作空间”页签,确认是否已为根组织的默认工作空间defaultWorkspace配置了集群资源。如已配置,请直接执行下一步骤。如未配置,请为工作空间配置资源:
单击列表上方的<配置>按钮,弹出分配运行环境窗口。
图-3 配置工作空间运行环境
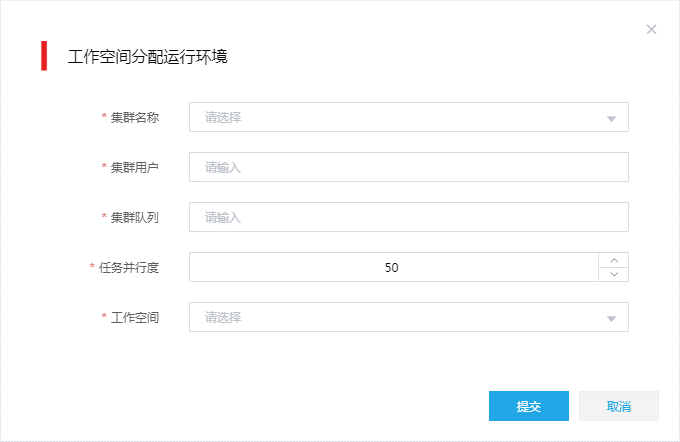
配置工作空间的运行环境参数。
集群名称:从下拉列表中选择大数据集群,可选择的集群为之前分配给工作空间所属组织的集群。
集群用户:选择集群后会自动填充。
集群度列:选择集群后会自动填充。
任务并行度:配置工作空间中,任务执行的并行度,本例中使用默认值。
工作空间:选择集群资源分配给的目标工作空间。本例中选择根组织下的默认工作空间defaultWorkspace。
单击<提交>按钮,配置完成。配置完成后,对应该工作空间,在大数据集群中建立默认的Hive等类型数据源连接。
至此,运行环境配置完成。
采集元数据
在通过业务流程对需要分析的数据源进行操作之前,需要先从Hive数据源的指定模式(业务数据所在的模式)中采集元数据,以便使用并管理其中的表。
成功新增数据源之后,进入[数据运营/数据资产]模块,按照图-4中所示的1、2、3步骤,进入元数据采集的任务创建页面,并创建元数据采集任务。
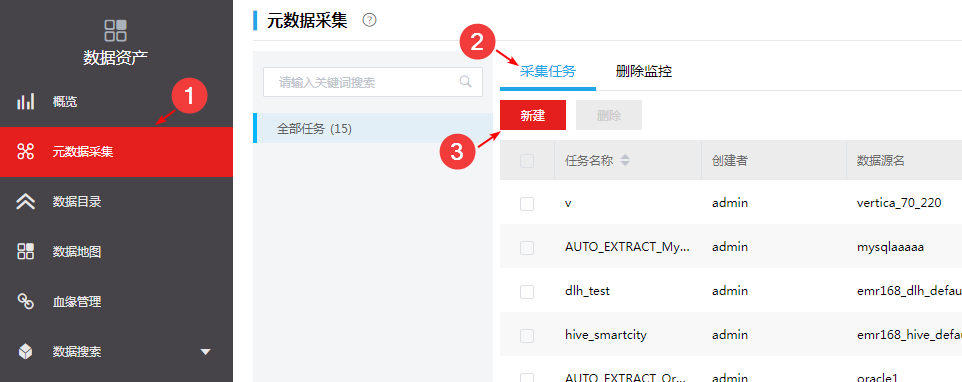
图-5 新增采集任务
创建完成后,在列表中单击对应操作列中的<运行>按钮,启动采集任务,如图-6所示,将Hive数据源share_bikes中的表采集到数据运营平台中。
采集任务启动之后,单击<更多>按钮,并选择[运行监控]菜单项,转入选择“运行监控”页签,进入该采集任务的监控页面,如图-7所示。
采集任务可以设置调度周期,从而定期或周期性对某个数据源执行采集操作,更新已采集的数据表信息。
注册离线表
Hive数据源的表在采集到的元数据后,会被自动注册为离线表,其他类型数据源(MySQL/Oracle/PostgreSQL等)中的数据表需要在[数据开发/表管理]中执行“离线表注册”操作后才可在业务流程的SparkSQL节点中使用。
构建业务流程
业务流程是按照业务的种类将相关的不同类型的节点任务组织在一起所构成的有向无环图。本章中以SparkSQL节点为例介绍离线分析任务在业务流程中的使用步骤。
创建业务流程
进入[数据运营/数据开发]模块。
在调度中心页面中,单击<新建>按钮,弹出新建业务流程窗口,如图-8所示。
填写业务流程及名称,单击<确定>按钮,新建业务流程。
进入业务流程画布编辑页面,拖拽一个SparkSQL节点到画布中,双击弹出右侧边栏,如下图-9所示。
图-9 查看SparkSQL节点信息
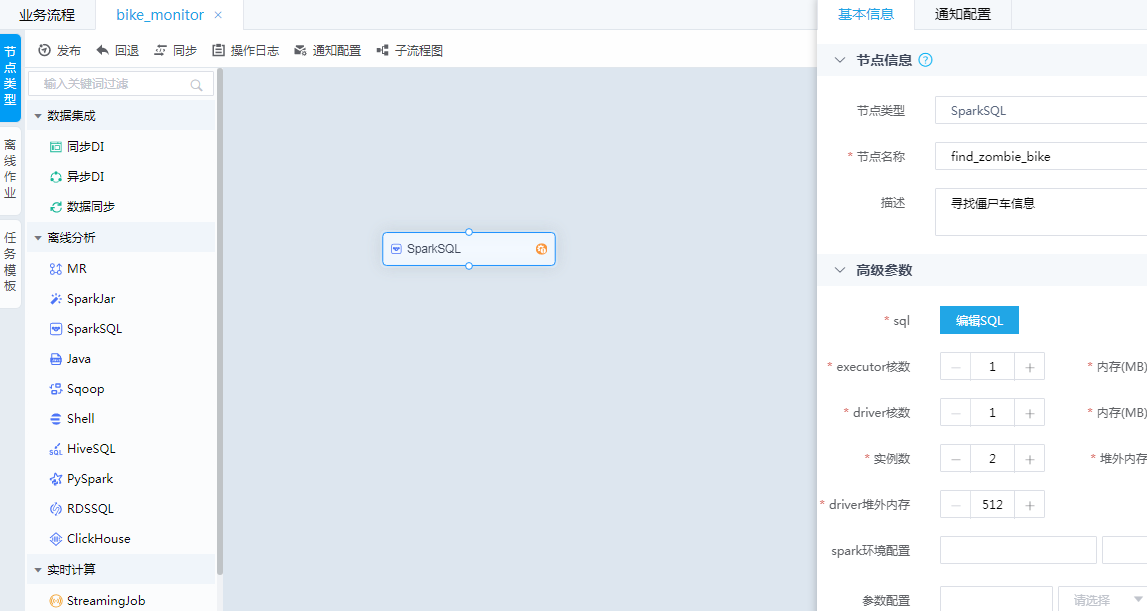
编辑SparkSQL节点
编辑SparkSQL节点信息,根据提示填写必要的节点名称等信息。
单击<编辑SQL>按钮,弹出SQL智能编辑器窗口,如图-10所示。
图-10 SQL智能编辑器开发SQL

在此窗口中编写符合SparkSQL/HiveSQL语法规范的SQL语句,所使用的分析表即为通过元数据采集操作注册进来的Hive数据表。
本例所述的识别“僵尸车”信息的分析SQL语句,其执行的操作是对单车基本数据信息表share_bikes.bikes_record和实时更新的数据信息表share_bikes.bikes_history做left join操作,获取近30天内未有实时数据的车辆即推测为“僵尸车”。
一般而言,对于需要通过SparkSQL节点任务执行的离线分析操作,建议将分析结果保存至数据表中。将分析结果保存至结果表可以便于后续查看分析结果或作为其他操作的数据源使用。本例中,在保存执行识别僵尸车的分析SQL语句之前,对其添加结果表share_bikes.zombie_bike_info。
将SQL语句改写为“create... select...”方式,如图-11所示。
图-11 通过SQL创建结果表

编辑完成SQL语句后,可以通过单击<语法校验>按钮,校验SQL语法是否正确规范。在不追加结果表保存的情况下,也可以单击<执行>按钮或<选中执行>按钮,直观地查看结果。
SQL智能编辑器窗口的各参数填写完毕后,单击<确定>按钮,退出编辑SQL窗口,返回业务流程画布编辑页面。
在页面右侧边栏中配置其他几项可选填的参数,具体说明请参阅0。
SparkSQL节点选填信息说明汇总
|
参数名 |
参数说明 |
示例值 |
|
配置参数 |
配置执行节点的基本配置参数 |
|
|
参数配置 |
如在SparkSQL中需要写入动态参数,如EL表达式等,该参数配置用于传递实际的参数名和参数值 |
如果SparkSQL代码为“select * from default.table where start_date='$biztime' and end_date='$cyctime'”,其参数配置值为$biztime= 2022-12-28 $cyctime=2022-12-29 |
提交执行
保存SparkSQL节点之后,单击业务流程画布左上方的<
 发布>按钮,发布业务流程。
发布>按钮,发布业务流程。
图-12 发布业务流程

单击<确定>按钮,业务流程发布完成。
在左侧导航树中选择[运维管理/调度运维]菜单项,进入调度运维页面。
在业务流程列表中,单击业务流程对应操作列的<提交>按钮,如图-13所示。

任务监控
提交业务流程之后,可在调度运维页面业务流程列表中,单击业务流程对应操作列的<监控>按钮,如图-14所示。

单击<监控>按钮,进入该业务流程的监控画布页面,提交的SparkSQL节点上显示监控属性的实时变化。在画布中右键单击该节点,弹出菜单中会显示该节点相关的“运行详情”、“查看日志”等监控属性,可查看该节点的具体监控信息,如图-15所示。等待业务流程运行完成,如图-16示。


调度配置(可选)
发布后的业务流程实例,支持配置调度策略。
为业务流程实例配置调度策略的步骤如下:
在[运维管理/调度运维]页面中,单击业务流程实例操作列<更多>按钮,并在下拉菜单中选择[调度管理]菜单项,如图-17所示。

在弹出的调度策略配置窗口中,配置调度参数,如图-18所示。

根据提示信息填写调度策略参数。
调度策略配置完成后,单击<确定>按钮,调度配置完成。
单击窗口中的<上线>按钮,调度配置上线生效。
单击业务流程实例操作列<监控>按钮,进入业务流程实例的监控界面。


结果查看
对于未设置“结果导出”操作但带有结果表的SparkSQL节点(即SQL语句以“create...”或“insert...”等开头)执行成功之后,可以通过[数据运营/数据资产]模块中的[数据搜索/SQL查询]页面直接查询,如图-21所示。
由于本例所使用的案例的结果表存于数据源share_bikes中,所以可以再执行一次先前创建的元数据采集任务,将该表采集到元数据信息中,从而可以在[数据搜索]中引用到该表名,再对其执行如下命令同样可以查询结果。
select * from "share_bikes"."zombie_bike_info"
