fashion-mnist使用说明
|
|
· 通过fashion-mnist使用说明,演示一套完整的建模流程:演示用户如何使用开发环境,如何使用jupyterlab进行线上的开发建模,以及如何将模型保存到模型库,进行推理服务部署。 · 本章节使用的开发环境功能、TensorBoard功能,以及模型仓库的部分功能、推理服务的部分功能,只有普通用户才可使用。因此操作时,需要切换至普通用户进行操作。 |
开发环境是人工智能平台的核心业务功能之一,它为用户提供了一个线上的jupyber编程环境,方便用户在没有本地计算资源的情况下,直接创建线上的开发实例,进行AI建模、编码,以及基础的运行测试工作。人工智能平台的集群环境是采用Kubernetes+Docker的技术架构,理所当然,开发环境的本质也就是一个容器环境,平台可以根据用户所需要的计算资源、运行环境来创建容器实例。本部分包括fashion-mnist建模示例和快速创建两部分。
人工智能平台的集群环境是采用Kubernetes+Docker的技术架构,理所当然,开发环境的本质也就是一个容器环境,平台可以根据用户所需要的计算资源、运行环境来创建容器实例。
fashion-mnist建模示例
下面就开始第一个示例的完整实操演示。
创建开发环境
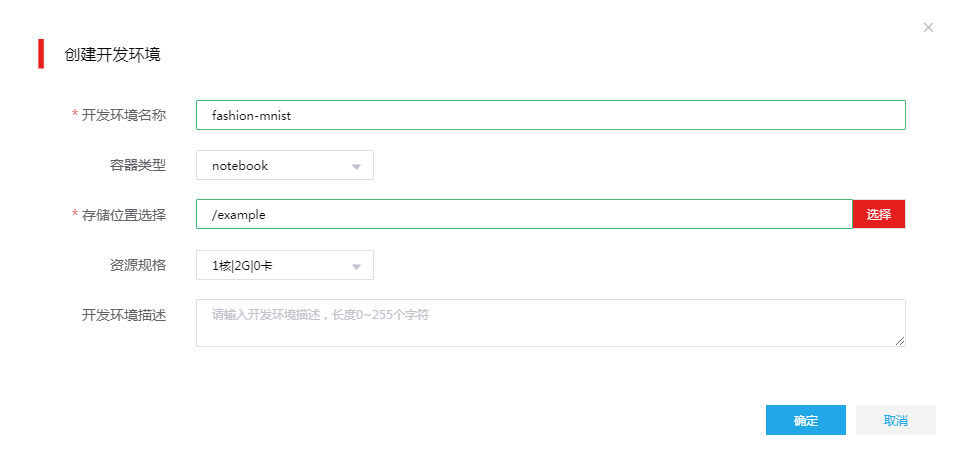
在[人工智能平台/建模服务/开发环境]页面,单击<创建>按钮,在弹出的窗口中,填写本示例所需要的计算资源,以及运行时镜像环境等信息,如图-1所示。
图-1 开发环境
参数说明如下:
开发环境名称:指当前创建的容器实例名称,按要求输入有意义的名称即可。
容器类型:这一步非常重要,因为平台会根据用户所选择来创建容器实例。本例选择notebook容器类型。
notebook:平台内置的容器类型,只有它可以用来创建jupyter容器实例,所以用户只能选择该notebook容器类型,才能进行jupyter的使用。系统会根据用户填写的资源规格中的GPU卡信息,自动创建CPU或者GPU的开发环境。如果GPU卡为0,则创建CPU的开发环境;如果GPU卡不为0,则创建GPU的开发环境。我们当前是一个简单的示例,不需要用到GPU,因此资源规格中选择0卡即可。
自定义:如果用户需要使用其它的AI计算框架或者其它开发环境,需要选择自定义容器类型。容器类型选择“自定义”后,进入镜像选择页面。在此页面三个页签中,“我的镜像”是用户自己制作上传的镜像,若要做开发环境用,镜像需要满足平台的《开发环境镜像制作规范》的要求;“AIOS HUB”即平台内置镜像,只有hpai-tf下的镜像支持开发环境;“共享镜像”,为其他用户共享的镜像。其中,“AIOS HUB”下的hpai-tf有4个镜像标签,分别是:
1.14:这是tensorflow1.14的cpu版本,其中python版本为2.7。
1.14-py3:这是tensorflow1.14的cpu版本,其中python版本为3.6。
1.14-gpu:这是tensorflow1.14的gpu版本,其中python版本为2.7。
1.14-gpu-py3:这是tensorflow1.14的gpu版本,其中python版本为3.6。
存储位置选择:人工智能平台中,不是简单的集成了jupyter,而是集成了体验效果更好的jupyterlab,它将用户的存储空间与jupyter有机的结合在一起,更加方便用户使用,所以我们在创建开发环境时,需要用户选择自己在jupyter中希望看到的根目录是什么。在我们的示例中所有的程序及数据集都在前面上传的“example”目录中,所以这里我们就选择该目录。
资源规格:创建一个容器实例,会占用集群环境中的资源,所以需要用户告诉平台,该实例需要多少计算资源。该项下拉框中,会展示一个默认的配置资源和一个自定义设置资源的选项,我们在这里选择自定义输入计算资源。在下拉框选择“自定义”,在弹出开发环境规格定义窗口中,输入CPU、内存、GPU等信息。本例输入的是1核|2G|0卡。
开发环境描述:输入开发环境描述,方便快速了解开发环境。
|
|
人工智能平台中,无论是开发环境,还是后续的训练环境、推理服务、可视化环境等,因为它们都需要动态的创建运行实例,需要占用平台中的计算资源,所以平台不能让单个用户毫无限制的随意使用。管理员会针对集群的资源总量,以及当前平台的用户数量做出判断,从而全局配置每个人所能使用的基础资源,以及可创建的实例数量,以达到公平的资源竞争。 |
单击创建开发环境页面中的<确定>按钮,即可创建容器实例。已创建的开发环境如图-2所示。

部分参数说明如下:
状态:因为kubernetes在创建一个容器实例时需要时间,所以用户需要等当前实例处于“运行中”时才可以使用。
访问方式:在内置的notebook中提供了SSH、远程桌面以及VNC。用户如果希望直接进入容器的命令行界面,则可以使用SSH中提供的连接信息;用户如果希望进入容器的桌面环境,则可以使用远程桌面或者VNC中提供的远程连接信息。具体操作就是将鼠标移到对应按钮上。
|
|
只有使用默认的notebook容器类型,<打开>按钮才为可操作状态。 |
运行jupyter示例脚本
单击已经创建好的开发环境对应的<打开>按钮,进入jupyterlab环境,如图-3所示。
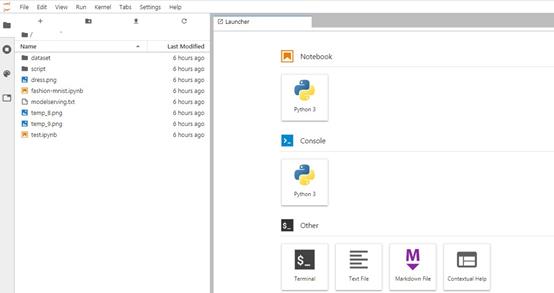
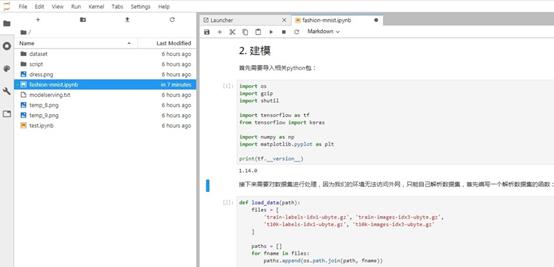
在左侧的目录结构,是我们用户空间的“example”目录,直接双击“fashion-mnist.ipynb”,打开完整的开发案例。
图-4 jupyterlab开发案例
|
|
· 若用户完全按照上面的操作说明顺序进行,打开的编程脚本不需要做任何改动即可运行;否则,用户需要仔细检查自己的目录结构与当前脚本中的相关路径地址是否一致。 · 这里我们不对jupyter的使用进行详细说明,若有疑问,可以直接百度或者google。 |
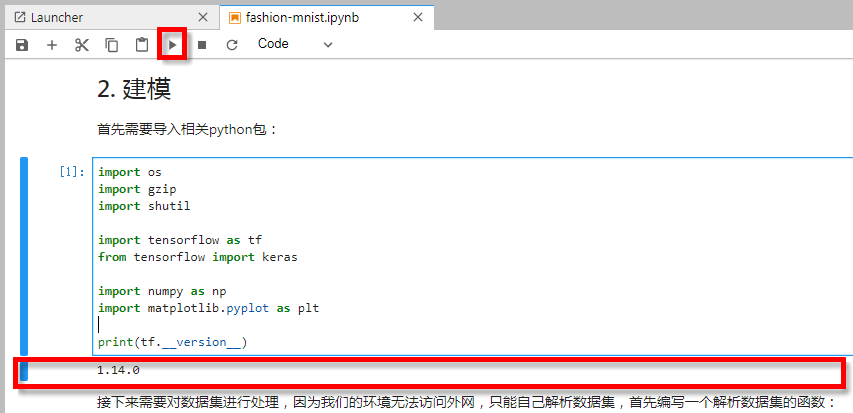
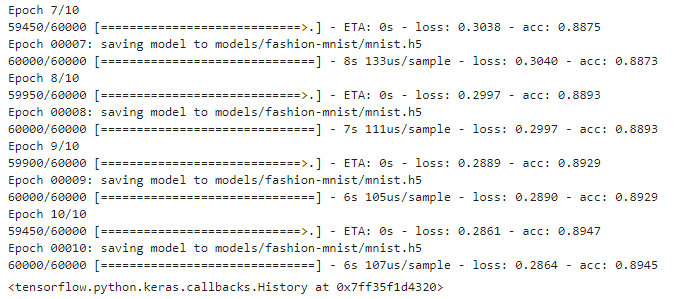
单击运行按钮之后,当前单元格的下方,就会展示出单元格脚本的输出结果。如图-5所示,可以看到我们输出了tensorflow的版本号信息,是1.14.0。具体的运行过程不再描述,只要按顺序依次执行即可。
这里对该图中示例的代码做一个简单的讲解,说明如下:
该示例是一个简单的图片分类问题,是0~9的10个分类,其中图片是28*28的灰度图片,与mnist数据集本质是一模一样的。
由于该数据集是事先别人制作好的,我们需要按照格式进行解压,解析出其中的训练数据集和测试数据集。load_data函数就是将我们数据集进行解析。
核心内容为建模,使用的是一个简单的DNN网络模型,并将模型保存成h5格式。(h5格式是keras的默认模型格式)
训练过程中,可对模型进行简单的评估和预测。
最后,若觉得模型不错,准确率达到要求,可以用来发布部署,需要将该模型转换成推理模型,即saved_model格式。这一步同样是需要代码进行转换的。
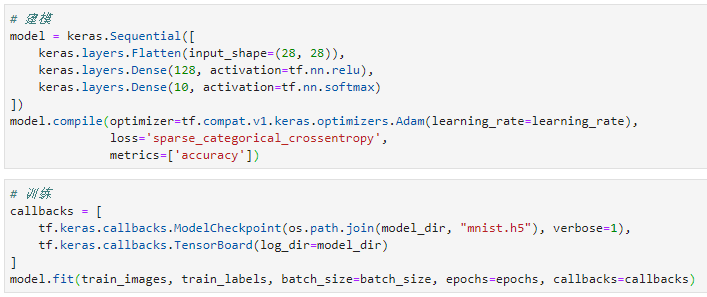
下面展示几段核心代码:
图-6 建模以及训练的代码
|
|
将mnist.h5模型转换为saved_model格式的代码。 |
图-7 训练过程中的日志
|
|
展示一个预测的日志(使用matplotlib组件进行的特殊处理,使预测结果更直观)。 |
图-8 预测的日志

|
|
· 其中训练过程,用户是可以反复的改动相关参数,进行反复训练的,直到用户觉得训练出满意的模型,训练以及推理所产生的文件,可以直接在左侧目录结构中看到图-9中的内容。 · 模型文件目录里面包含了训练过程中所产生的训练模型mnist.h5以及训练过程中的事件日志(该日志可以使用tensorboard进行可视化展示),另外还有推理脚本所产生的推理模型文件saved_model。 |
TensorBoard可视化
对于Tensorflow建模训练,会产生训练日志,我们可以使用平台提供的TensorBoard特性,来创建一个可视化实例,查看当前训练的效果。
在[人工智能平台/建模服务/Tensorboard]页面,单击<创建>按钮,并填入相关信息。如图-10所示。
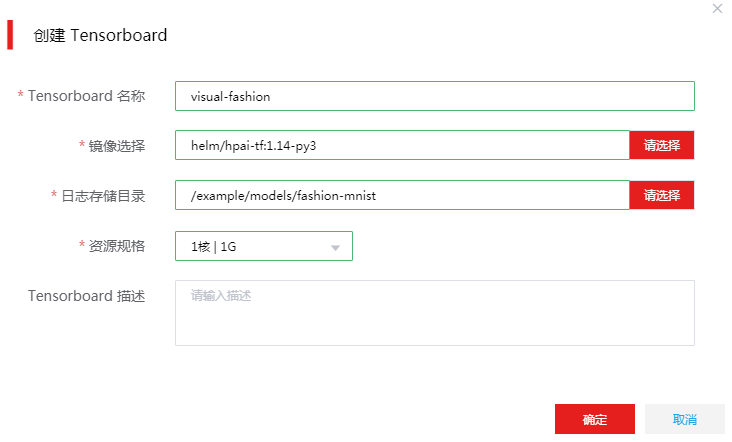
部分参数说明如下:
镜像选择:只有内置镜像集成了TensorBoard,所以需要选择hpai-tf这个镜像。
日志存储目录:TensorBoard启动时,一定需要一个日志目录,并且该目录下面存放的就是我们上面训练时产生的事件日志文件:/example/models/fashion-mnist。
单击<确定>按钮,平台会动态创建一个可视化实例。如图-11所示。

待实例状态为“运行中”时,单击<打开>连接,即可以看到上面训练的可视化信息。如图-12所示。
图-12 TensorBoard环境界面

保存模型仓库
开发和训练是平台最最核心的功能特性,而模型库以及模型部署可以算是整个AI建模的最后一程,因为模型已经产生,剩下的只需要将其部署起来,供外部使用即可。模型部署之前,首先需要将模型保存到模型库中。
在[人工智能平台/建模服务/模型仓库]页面,单击页面中的<新增模型>按钮,在弹出窗口中,输入模型名称和描述,单击<确定>按钮,完成新增模型。
图-13 新增模型
单击上一步新建的模型后的<详情>按钮,进入模型详情页面。可以看到模型的基本信息和版本信息。一个模型可以有多个版本。
图-14 模型详情
单击页面中的<导入>按钮,在弹出界面中填入相关表单信息。
图-15 导入模型
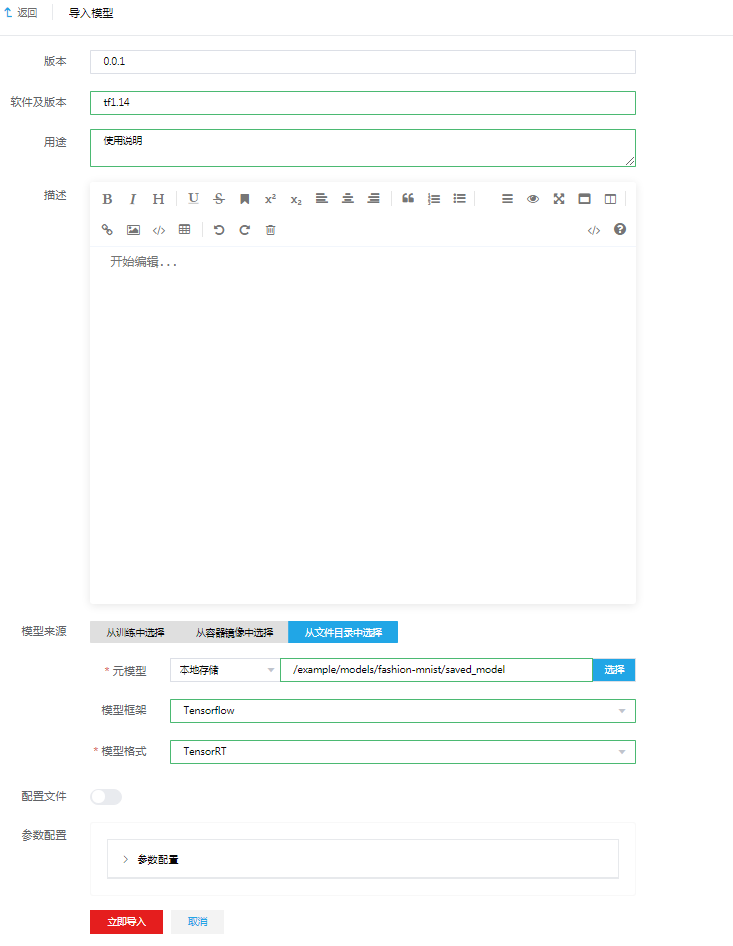
关键字段的说明如下:
模型名称:即模型名称。
版本:即当前模型名称下的版本,一个模型名称,可以对应多个版本的模型。
软件及版本:模型内使用的软件及相关版本。
用途:模型的用途。
描述:在界面上是一个md的在线编辑器,因为一个模型如果要发布部署,别人并不会知道这个模型怎么使用,需要哪些参数,这些都需要模型的开发者进行详细说明。
模型来源:模型的来源,可选择从训练中选择、从容器镜像中选择和从文件目录中选择:
从训练中选择:从训练任务中选择模型导入,训练任务,必填,选择模型导入的训练任务;模型框架,模型使用的框架;模型格式,必填,模型保存的格式。
从容器镜像中选择:选择要导入模型的镜像。
从文件目录中选择:从文件目录中导入模型。元模型:必填,选择模型保存的目录;模型框架,模型使用的框架;模型格式,必填,模型保存的格式。本例我们从文件目录中选择模型文件导入。
配置文件:配置文件开关。
参数配置:配置文件展示。
|
|
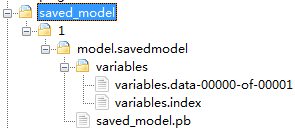
这里重点解释一下Tensorflow的推理模型文件格式,Tensorflow的默认推理模型为pb文件。人工智能平台中目前是使用nvidia官方的TensorRT通用推理镜像进行部署的,它对Tensorflow模型文件以及目录的要求如图-16所示,即模型根目录下是一个表示版本的数字(默认是1),该数字目录下是一个名为model.savedmodel的文件夹,该文件夹下才是Tensorflow默认的pb模型相关文件。 |
图-16 tensorflow模型文件以及目录
表单填写完毕之后,单击<立即导入>按钮,即可将模型导入到平台的模型库中。因为模型文件有时会比较大,所以导入需要一点时间。模型导入之后,可以在列表界面看到我们刚刚导入的fashion-mnist模型。
图-17 模型版本列表
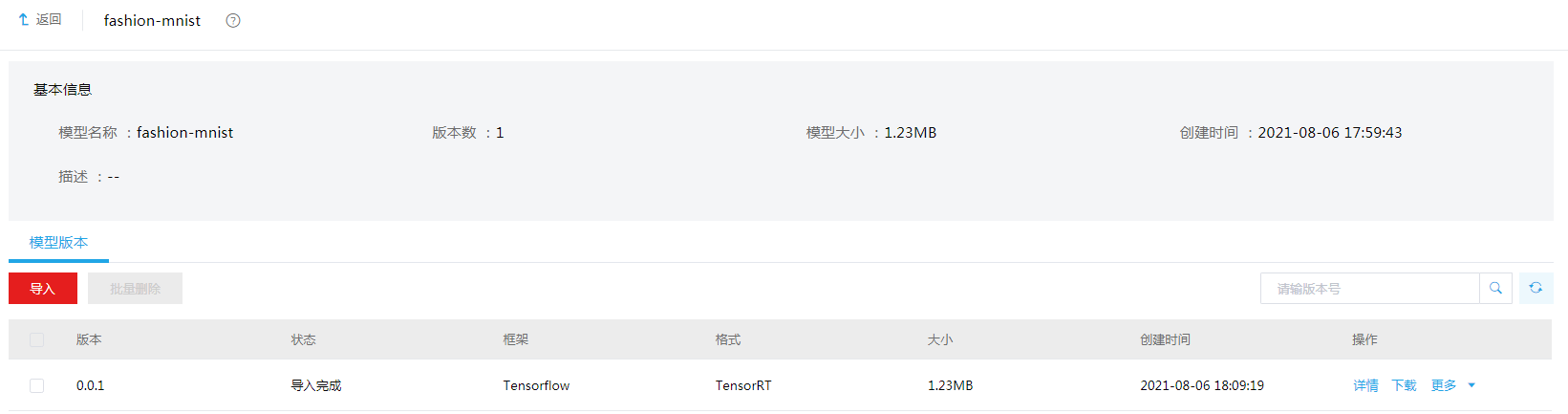
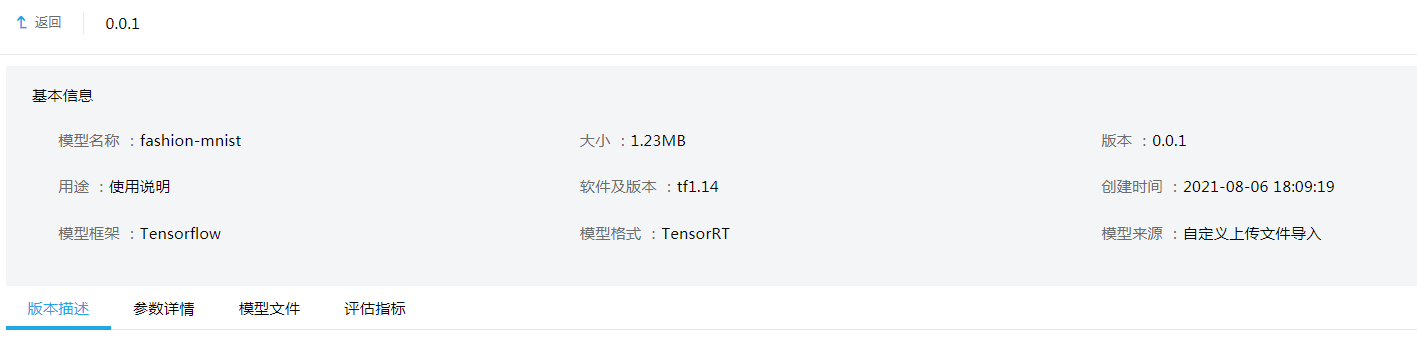
单击<详情>按钮可以看到对应模型版本的详细信息,因为是快速上手示例,我们并没有对模型参数做配置。
图-18 模型版本详情
创建推理服务
如果说开发训练是AI算法工程师的日常工作,那么模型部署推理才是真正让模型具有商业价值的一步,模型只有变成真正的服务,供外部调用,模型才具有实际价值。
人工智能平台作为一个AI计算平台,为用户提供AI建模全生命周期管理,推理服务就是该生命周期中的最后一个环节。下面我们演示如何将刚才保存的模型部署成在线服务,供外部调用。
在[人工智能平台/建模服务/推理服务]页面,单击<创建服务>按钮,输入服务名称和描述,单击<确定>按钮,创建服务。
图-19 创建服务

图-20 服务列表创建成功

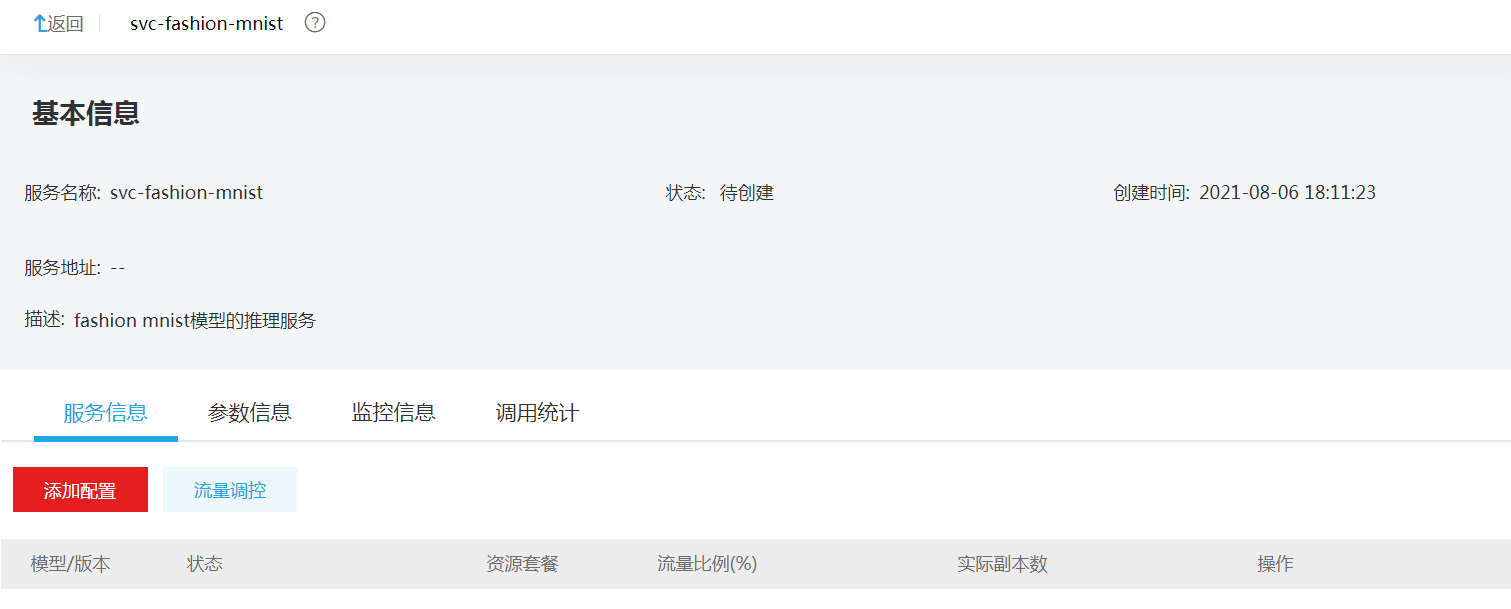
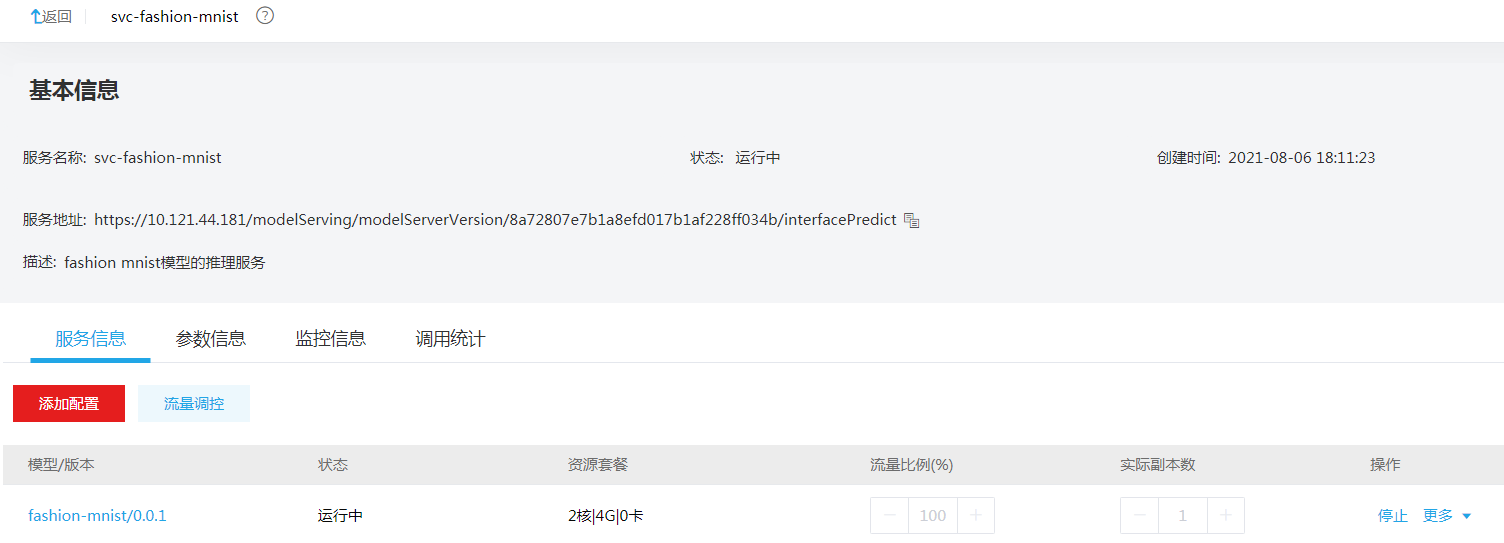
单击<详情>按钮,进入推理服务详情页面,推理服务详情页面包含基本信息,服务信息、参数信息、监控信息、调用统计四个切换页。其中:
基本信息:展示了服务名称、状态、创建时间、服务地址、描述等信息。
服务信息:包含服务版本列表,在线服务版本列表展示如下信息:
服务名称:推理服务名称。
状态:推理服务的状态。
服务地址:推理服务的调用URL。
创建时间: 创建推理服务的时间。
操作:启动、停止、更多(详情、修改、删除)。
参数信息:推理服务的原生参数以及配置的deploy.json的参数配置(如果没有配置deploy.json,参数配置默认为空)。
监控信息:服务启动实例的资源(CPU、GPU、内存)可视化展示。
调用统计:推理服务测试的统计可视化展示,右侧可进行该服务下所有版本实例资源信息的切换,默认展示全部资源信息整合展示。
图-21 推理服务详情
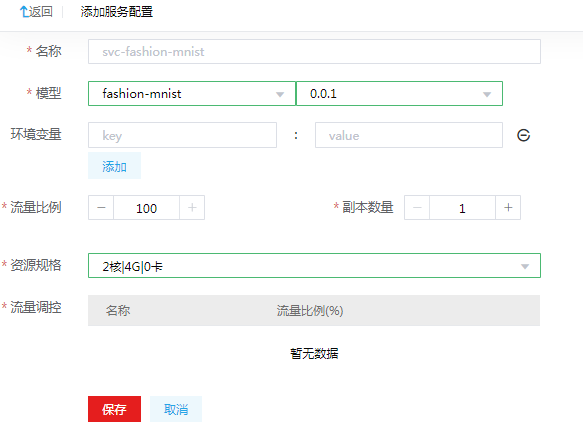
单击<添加配置>按钮,弹出添加服务配置页面,填写模型名称和版本。流量比例等参数,单击<保存>按钮即可完成服务的添加。添加服务版本表单页面参数说明:
服务名称:推理服务的名称,系统化自动带入。
模型:选择导入的模型及版本。
环境变量:设置环境变量值。
流量比例:设置服务的流量比例,多版本需要保证流量比例为100%。
资源规格:启动服务版本所需的资源信息。
流量调控:多版本配置流量比例为100%。
再次进入AI推理列表页面,会发现该推理服务正在启动中,需要耐心等待一段时间,等“状态”变成“运行中”,表示该推理服务部署成功。
图-23 服务运行中
运行成功后,可以单击<返回>按钮,回到推理服务列表,单击对应服务后面的<测试>按钮,进行推理服务的测试页面。输入请求报文,单击<测试>按钮,即可对该服务进行在线测试。
图-24 推理服务在线测试
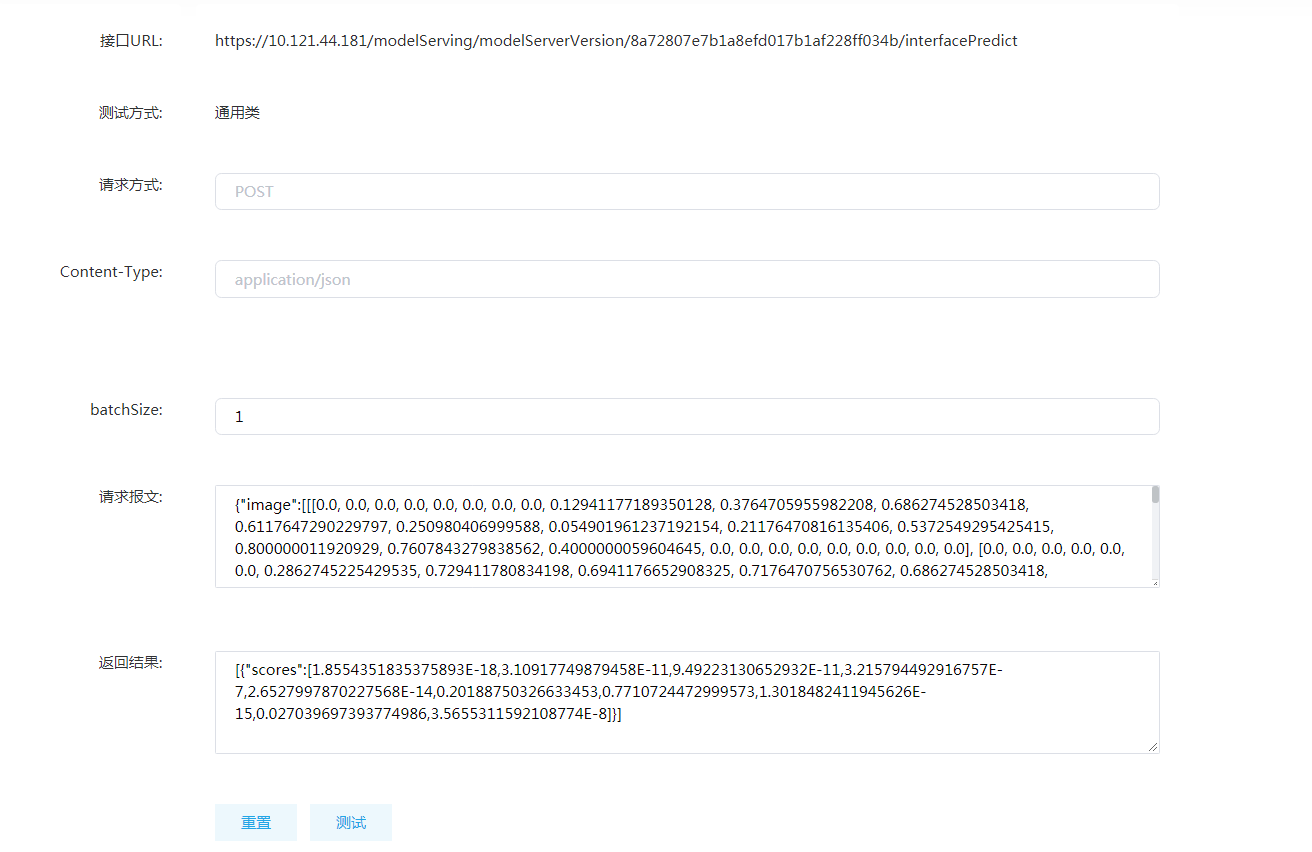
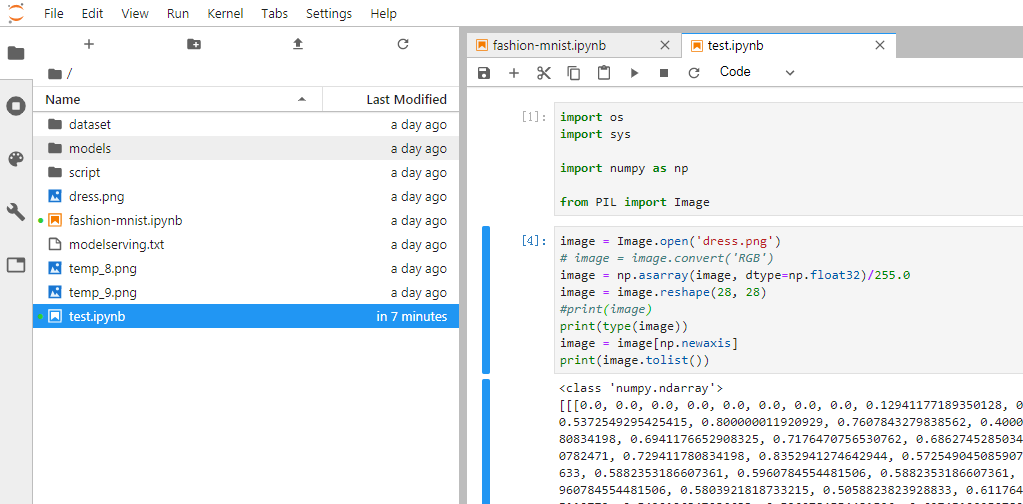
测试中的请求报文,就是该模型需要的输入参数,它是一个(28,28,1)的向量。该参数可以从示例文件中的“modelserving.txt”中拿到。用户也可以自己生成这个参数,具体可以在jupyterlab中运行test.ipynb文件,该文件中有一个简单的示例,可以将图片转换成推理服务所需要的向量数据,具体使用需要用户有一定的AI以及python编程基础。该脚本就是读取一张28*28的灰度图片,将其转换成一个28*28的数组。再拼装成推理服务需要的请求报文即可。
图-25 获取请求报文
快速创建
用户可以通过“立即创建”的功能,来快速创建fashion-mnist的示例。需要注意的是,通过“立即创建”得到的是一个AI建模的工作流,而非开发环境。
选择[人工智能平台],进入人工智能平台页面。
在[人工智能平台]左侧导航栏中选择[样例库管理/样例库]菜单项,进入样例库页面。
单击fashion-mnist样例右侧的<立即创建>按钮,选择任务流所在工程,输入任务流名称,单击<确定>按钮,保存任务流。页面会自动跳转到该工程的页面。
单击上一步创建的任务流,进入任务流页面。各个组件已经创建,且参数已经配置。用户也可以根据自己的需要,调整参数。