数据搜索常见问题
1. 系统运维/巡检显示snake服务的内存使用率较高,超过90%
snake服务的JVM占用内存最大值是1.5GB,而系统为snake服务所属docker(容器)默认分配的内存是2GB,二者比较接近,这会导致巡检结果显示进程使用率偏高,详见运维常见问题中的“服务内存或CPU使用率高”问题。
2. 当在一个组织/工作空间下,数据源配置多个开启了Kerberos认证的Elasticsearch数据源,且指向的物理集群是不同的ES集群,不同ES集群用的Kerberos认证是不同的认证中心(如果适配DataEngine集群,一般情况不同的集群使用的Kerberos是独立的),建ES表会提示“无法连接ES集群”
该问题的提示信息如下图所示。
图-1 错误信息

针对该问题说明如下:
不同的Kerberos认证提供的认证文件krb5.conf内容是不同的,可以对比两个文件直观查看。
当前本系统不支持在同一个组织内适配两个不同Kerberos认证的ES集群。
如果ES集群没有开启Kerberos认证,可以在任何一个组织空间下进行关联使用。
如果是适配DataEngine集群,且开启了Kerberos认证,可以通过新建其他组织,进行大数据集群关联关联配置。
如果是其他的ES集群,且开启了Kerberos认证,则只能和非Kerberos认证的空间配合使用。
3. 对于Hive数据源中ORCFILE存储方式的Hive表修改字段类型后使用SparkSQL引擎查询数据失败
问题说明:
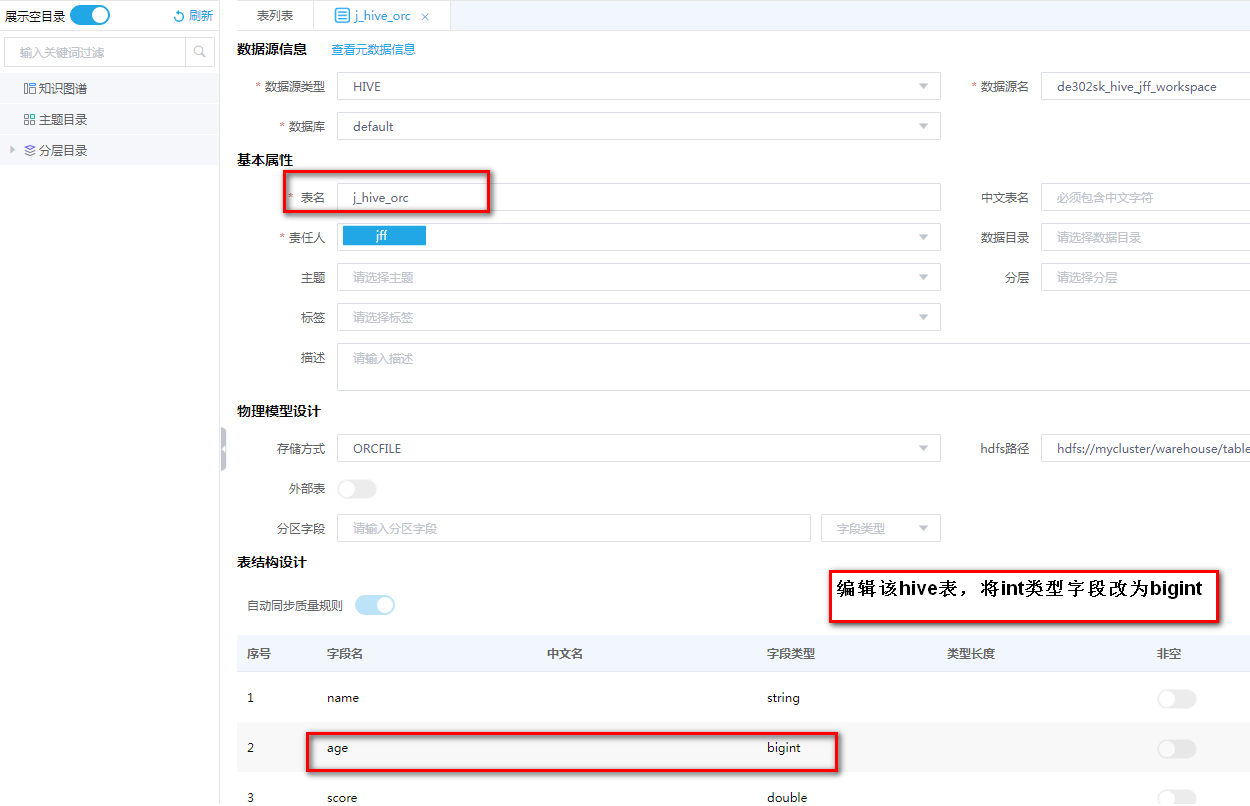
在Hive数据源中ORCFILE存储方式的数据表中,修改字段类型,将int类型改为bigint类型。
图-2 修改字段类型
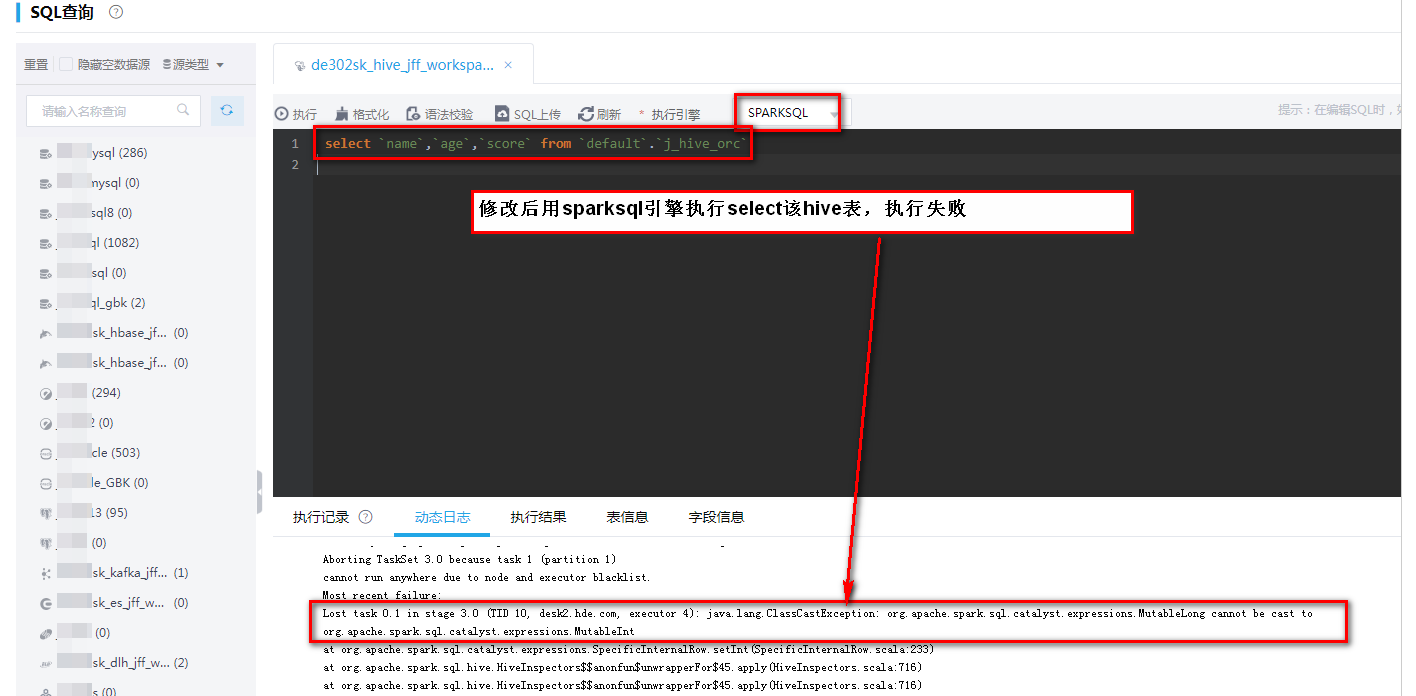
然后在[数据搜索/SQL查询]中,使用SparkSQL引擎查询时,会出现如下图所示报错。
图-3 查询报错
解决方法
使用SparkSQL引擎对修改过的ORCFILE存储方式的Hive表进行查询时,在查询语句前加上如下配置语句:
set spark.sql.hive.convertMetastoreOrc=false;
例如,查询语句为select 'name', 'age', 'score' from 'default'.'j_hive_orc',则输入的语句为:
set spark.sql.hive.convertMetastoreOrc=false;
select 'name', 'age', 'score' from 'default'.'j_hive_orc'
4. Elasticsearch集群中,临时测试数据或脏数据的清理方法(用户直接通过Elasticsearch集群或其它应用程序创建的Elasticsearch数据表不属于本系统管理范围)
如需删除这些脏数据,可通过Elasticsearch命令手动删除,参考步骤如下:
登录至Elasticsearch集群任一节点后台。
确认Elasticsearch集群是否开启Kerberos认证。
未开启,请执行3。
已开启,请执行4。
执行如下命令,删除模板:
curl -XDELETE "http://IP:port/_template/模板名称"
其中,IP为Elasticsearch集群节点的IP;port为Elasticsearch服务的端口号,通常为9200;模板名称为索引使用的模板,通常格式为:数据源名.表名_template。
执行如下命令,删除索引:
curl -XDELETE "http://IP:port/索引名称"
其中,索引名称为集群监控中,对应的索引名称。
切换至有权限的Kerberos用户,然后执行相应的删除模板或删除索引命令,命令执行完成,操作结束。
执行如下命令,切换Kerberos用户:
kinit -kt /etc/security/keytabs/example.keytab username
其中,example.keytab为该Kerberos用户的认证文件,username为该Kerberos用户的用户名。
执行如下命令,删除模板:
curl --negotiate -u : -XDELETE "http://IP:port/_template/模板名称"
其中,IP为Elasticsearch集群节点的IP;port为Elasticsearch服务的端口号,通常为9200;模板名称为索引使用的模板,通常格式为:数据源名.表名_template。
执行如下命令,删除索引:
curl --negotiate -u : -XDELETE "http://IP:port/索引名称"
其中,索引名称为集群监控中,对应的索引名称。
5. 使用ES搜索功能查询数据失败,报错java.io.IOException: entity content is too long [292564109] for the configured buffer limit [104857600]
问题说明
当数据所在表中存在超大字段(一般为单个字段长度超过500KB,即超过50万个字符)时,如果对这些超大字段进行批量查询,会由于Elasticsearch通过HTTP传输数据存在最大传输量不能超过100MB的限制,而出现报错,如下图所示。
图-4 查询报错

解决方法
查询数据时出现该报错后,请将返回字段中的超大字段剔除,然后重新进行查询。
对于涉及超大文件的查询,建议查询流程为:先进行模糊查询,命中片段信息,然后转换为单条查询。