数据集成常见问题解答
本章节提供用户常见问题及解答,以帮助用户更好的使用和管理DI系统。
新增carte子服务器
Kettle安装包中均自带对应版本的carte服务。carte服务可以远程执行传来的Kettle任务,并将执行结果返回。
安装carte服务的步骤如下:
将Kettle安装包拷贝至目标服务器节点。
修改carte的配置文件data-integration/pwd/carte-config-master-8080.xml后保存。根据Kettle carte子服务器的用户名/密码设置不同,分为以下两种情况:
将Kettle carte子服务器的用户名/密码设置为缺省用户名/密码时,如图-1所示。其中:hostname为程序所在节点的IP;port为端口地址(自定义);username和password为Kettle carte子服务器的缺省用户名/密码(缺省为cluster/cluster)。
图-1 修改carte-config-master-8080.xml(一)

对Kettle carte子服务器的用户名/密码进行自定义设置时(示例用户名为user,密码为passwd),如图-2所示。其中:hostname为程序所在节点的IP;port为端口地址(自定义);username为Kettle carte子服务器的用户名user,password为Kettle carte子服务器的密码passwd。
图-2 修改carte-config-master-8080.xml(二)

【注意】:对于自定义的Kettle carte子服务器的用户名(示例user),其密码(示例passwd)必须经过生成等相关配置后才可生效,配置过程如下:
修改配置文件data-integration/encr.sh(encr.sh需要具有可执行权限),对自定义用户的密码进行生成,命令为:./encr.sh –carte passwd,如图-3所示。

修改配置文件kettle.pwd,将缺省用户的密码信息“cluster: OBF:1v8w1uh21z7k1ym71z7i1ugo1v9q”注释掉,然后写入上一步骤中新生成的自定义用户的密码相关信息,如图-4所示。

在data-integration目录下启动carte服务。
命令为./carte.sh pwd/carte-config-master-8080.xml,如图-5所示。

carte服务启动成功性验证。
方法:通过URL地址:http://<启动carte服务的节点IP>:<port>/kettle/status/,若能正常登录,说明服务启动成功,此时即可在carte上执行kettle任务。
获取.kjb文件用于新增Kettle Job任务
在Kettle里获取的.kjb文件可直接用于在DI中新增Kettle Job类型的任务,获取.kjb文件的步骤如下:
在Kettle里转换作业生成.kjb文件,转换时需要配置转换文件名,然后保存后即可得到.kjb文件。此时需要注意:
转换文件名可填写绝对路径,也可使用变量(${Internal.Job.Filename.Directory}/${Internal.Transformation.Filename.Directory}/${Internal.Entry.Current.Directory})进行替换。
转换文件名使用变量替换的路径时,要求用户输入的路径与Kettle carte服务器上KettleJob的路径一致。
SSL证书导入
将SSL证书导入服务器的的步骤如下:
转换证书格式(非必须操作,保证证书可成功导入到库文件即可)。
示例:转换.pem格式的证书,命令如下:
将CA证书ca.pem转换为cer文件:
openssl x509 -CAform pem -in /opt/ssl/ca.pem -out /opt/ssl/ca.cer
将用户证书client.pem转为PKCS12类型文件:
openssl pkcs12 -export -out /opt/ssl/client.pkcs12 -in /opt/ssl/client.pem -password pass:123456
分别将ca.cer和client.pkcs12认证文件导入到JKS文件中,命令如下:
将ca.cer导入到JKS文件:
keytool -import -v -alias ca -trustcacerts -keystore /opt/ssl/cakeystore -file /opt/ssl/ca.cer
将client.pkcs12导入到JKS文件:
keytool -importkeystore -srckeystore /opt/ssl/client.pkcs12 -srcstoretype PKCS12 -destkeystore /opt/ssl/clientkeystore -deststoretype JKS -deststorepass 123456 -srcstorepass 123456
|
|
· 上述示例中的文件路径:/opt/ssl/cakeystore和/opt/ssl/clientkeystore,可以自由选择任何路径和文件名,只要保证在设计器中页面填写的“信任证书文件”和“用户证书文件”与其保持一致即可。 · 任务保存后,如果需要更换库文件的名字和密码,则新的名字和密码需要在对应的页面文本框中进行修改并保存即可,无需重新启动DigWeb和DigExecutor应用。 · 证书文件可以在非DigWeb节点所在的服务器生成,可以在其它服务器生成后拷贝到DigWeb服务器上即可。 · 执行器无需任何手动配置证书的操作。 |
数据源连接错误信息乱码
在DI的任务画布中使用数据源进行数据库相关操作时,若数据源配置错误导致了数据源连接失败,数据库服务端会返回相应的错误信息,如果数据库的locale相关参数设置错误,可能会导致DI给出的提示信息乱码。
使用PostgreSQL类数据源时,若出现提示信息乱码现象,请检查相应postgresql数据库的启动参数配置文件 postgresql.conf,将其中的 lc_messages参数的值修改为 en_US.UTF-8,然后重启数据库服务即可恢复正常。
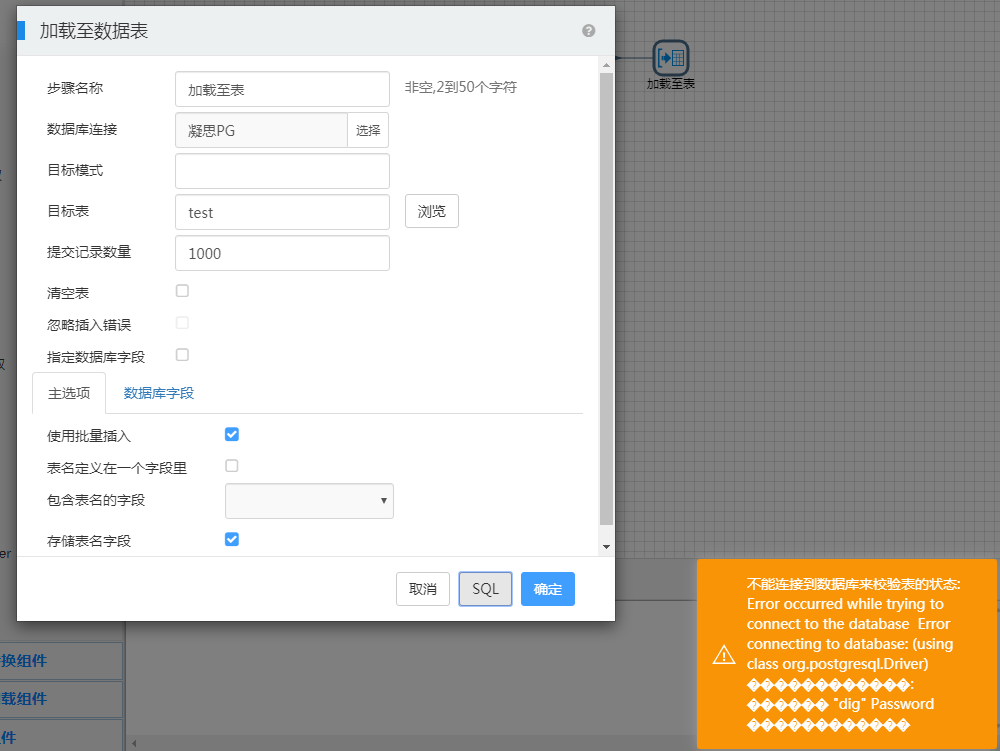
使用加载至表组件的SQL功能,连接postgresql数据库获取建表语句,配置postgresql数据源时输入错误的用户名或密码,发现给出的数据源连接失败的错误信息中出现乱码:
图-6 加载至表组件中SQL功能报错信息乱码
linux系统中,PostgreSQL数据库的配置文件路径可使用如下命令查找: find / -name "postgresql.conf"
图-7 查找postgresql.conf文件

lc_messages 参数被默认设置为 zh_CN.UTF-8,需要修改为 en_US.UTF-8 或 C.UTF-8 ,然后重启数据库服务
图-8 修改lc_messages参数

其他类型数据源,若出现类似的提示信息乱码现象,请检查相应数据库中有关于语言环境的设置是否正确。
下发Shell任务时,因为服务器Open SSH版本较高,导致Shell任务连接不上
1. 问题原因:
高版本Open SSH出于安全考虑去掉了很多它认为不安全的认证方式,而我们使用的ganymed-ssh2的方式连接支持的几种认证方式被Open SSH剔除,造成连接不上的问题。
2. 解决方案:
修改sshd_config文件,将认证方式重新加入任务执行主机的配置文件中。
登录需要下发任务的执行主机,执行vi /etc/ssh/sshd_config命令,在配置文件末尾增加如下两个配置:
KexAlgorithms diffie-hellman-group1-sha1,diffie-hellman-group14-sha1,diffie-hellman-group-exchange-sha1,diffie-hellman-group-exchange-sha256,ecdh-sha2-nistp256,ecdh-sha2-nistp384,ecdh-sha2-nistp521,diffie-hellman-group1-sha1,[email protected]
HostKeyAlgorithms [email protected],[email protected],[email protected],[email protected],[email protected],[email protected],[email protected],[email protected],ssh-ed25519,ecdsa-sha2-nistp256,ecdsa-sha2-nistp384,ecdsa-sha2-nistp521,[email protected],[email protected],rsa-sha2-512,rsa-sha2-256,ssh-rsa,ssh-dss
然后执行service sshd restart命令重启sshd服务。
此时再执行任务下发,任务即可下发成功。
如何将用户提供的数据库驱动导入数据源
|
|
重启“数据集成执行器”会导致正在运行的定时调度任务停止运行,为了避免影响业务,请在没有任务运行时,重启执行器;或者重启执行器后,手动运行重启前没有运行完成的定时调度任务。 |
当用户创建数据源时如果需要使用用户提供的数据源驱动,此时需要将用户的驱动包导入到数据源服务中。操作步骤如下:
登录融合集成平台后台任意节点,并将用户驱动包上传到此节点如下目录中:
/data/software/base/glusterfs/oasis-data-pvc/oip/oip-platform-data-pvc/plugins/dig-connector-<datasourceType>-<版本号>/
其中<datasourceType>为数据源类型,<版本号>为软件版本号,路径下存在多种数据源类型的目录,用户可根据实际需要,选择对应的目录进行上传。
比如要替换generic Jdbc通用数据源驱动插件时可放在/data/software/base/glusterfs/oasis-data-pvc/oip/oip-platform-data-pvc/plugins/dig-connector-generic-E5202-V500R001B02D010-SNAPSHOT目录下。
然后登录融合集成平台系统,在[运维/服务管理]页面重启数据集成下的“数据源”“数据集成执行器”、“数据集成web”服务。
图-9 重启对应服务
数据集成服务端本地文件上传及下载
1. 上传
如果需要将文件上传至数据集成容器的共享存储中,按照如下步骤操作:
登录融合集成平台任意节点,并将文件上传到此节点,可通过FTP方式上传。
查找数据集成容器。命令如下:
docker ps | grep di-web
图-10 查找数据集成容器

将文件拷贝到数据集成容器共享存储中。数据集成容器可能有多个,上传到任意一个即可,命令如下:
docker cp [用户文件] [数据集成任意容器]:/usr/local/dig/data
2. 下载
如果需要将数据集成容器中文件下载至服务器,按照如下步骤操作:
登录融合集成平台任意节点。
查找数据集成容器。命令如下:
docker ps | grep di-web
图-11 查找数据集成容器

docker cp [数据集成任意容器]:/usr/local/dig/data/[用户文件] [服务器本地目录]
PostgreSQL数据库开启WAL日志归档
PostgreSQL数据库开启WAL日志归档,开启方式如下:
登录PostgreSQL服务器,编辑postgresql.conf文件,配置归档需要开启如下参数:
wal_level =logical
archive_mode =on
编辑完成后需重启PostgreSQL数据库。因为wal_level和archive_mode参数修改都需要重新启动数据库才可以生效。
CDC作业使用PostgreSQL数据源的用户如果为普通用户,则需为该用户授予replication权限。使用超级管理员执行如下命令为用户授权:
alter user <username> replication;
如果上面命令完成后,仍然无法进行数据抽取,请继续执行下列命令:
grant create on database < database name> to <username>;
alter table < table name > owner to <username>;
MySQL、MySQL8或DRDS数据库开启Binlog
MySQL、MySQL8或DRDS数据库开启Binlog,开启方式如下:
登录MySQL服务器,编辑my.cnf文件,添加如下配置:
log-bin=<binlog存储路径及文件名,例:/mysql/logs/mysql-bin.log>
expire-logs-days=<日志过期时间,单位为天,例:10>
max-binlog-size=<单个binlog文件大小,例:500M>
server-id=<服务器ID,保证唯一,不可重复,例:1>
如下配置可选:
gtid-mode=<是否开启GTID复制功能,根据需要开启,例:ON>
enforce-gtid-consistency=<启动强制GTID的一致性,如果开启GTID功能此项必须开启,例:ON>
binlog_format=<binlog日志格式,当前只支持ROW格式。默认为ROW>
编辑完成后重启MySQL。
启动完成后查看binlog相关配置状态。连接MySQL,执行命令:
show variables like 'log_bin';查看binlog开启状态
show variables like 'binlog_format';查看binlog格式是否为ROW。如果不为ROW,需参照步骤1中可选配置进行修改。
show variables like '%ssl%';查看ssl是否开启
show master status;查看GTID是否开启
CDC作业使用MySQL数据源的用户如果为普通用户,则需使用超级管理员执行如下命令为用户授权:
grant select on <数据库名> to <用户名>;
update mysql.user set Super_priv = 'Y' where `User`='<用户名>';
grant replication slave on *.* to <用户名>;
grant replication client on *.* to <用户名>;
flush privileges;
Oracle数据库启用CDC
|
|
每个Oracle数据库支持配置的CDC作业数量与Oracle数据库的CPU核数有关。建议作业数量不超过CPU核数,包含有Lob字段的作业数量建议不超过CPU核数的一半。配置作业过多,可能严重影响数据库性能。 |
LogMiner是Oracle数据库自带的服务组件,可以解析数据库的redo和undo操作数据,对回溯数据库操作以及恢复数据发挥巨大作用。
Oracle版本为10g、11g
当Oracle版本为10g、11g时,启用CDC时步骤如下:
1. 开启数据库LogMiner组件
@$ORACLE_HOME/rdbms/admin/dbmslm.sql
@$ORACLE_HOME/rdbms/admin/dbmslmd.sql
2. 开启数据库归档日志模式
以DBA身份登录数据库。
执行以下SQL,检查数据库日志模式。
Select log_mode from v$database;
如果查询log_mode为ARCHIVELOG,则跳过步骤3(开启数据库归档日志模式);如果是NOARCHIVELOG,则执行步骤3。
开启数据库归档日志模式。
关闭数据库:shutdown immediate;
启动数据库mount:startup mount;
开启数据库归档日志并开启数据库:
Alter database archivelog;
Alter database open;
3. 开启附加日志
开启整库附加日志命令:
Alter database add supplemental log data (primary key) columns;
Alter database add supplemental log data (all) columns;
开启指定表的附加日志命令:
Alter database add supplemental log data;
Alter table <schema>.<table> add supplemental log data (primary key) columns;
Alter table <schema>.<table> add supplemental log data (all) columns;
4. 创建Logminer抽取用户
如果用户为普通权限用户,请参考步骤5普通用户授权,如果需要重新创建用户,请执行以下操作:
create user <username> identified by <password>;
grant connect to <username>;
grant select any transaction to <username>;
grant select_catalog_role to <username>;
grant select any table to <username>;
grant select any dictionary to <username>;
grant flashback any table to <username>;
grant execute_catalog_role to <username>;
grant ANALYZE ANY to <username>;
5. 普通用户授权
CDC作业使用Oracle数据源的用户如果为普通用户,则需超级管理员执行如下命令为用户授权:
grant connect to <用户名>;
grant select on sys.dba_objects to <用户名>;
grant select on sys.dba_extents to <用户名>;
GRANT SELECT ON V_$DATABASE to <用户名>;
GRANT SELECT ON V_$LOG TO <用户名>;
GRANT SELECT ON V_$LOGFILE TO <用户名>;
GRANT SELECT ON V_$ARCHIVED_LOG TO <用户名>;
GRANT SELECT ON V_$ARCHIVE_DEST_STATUS TO <用户名>;
GRANT EXECUTE ON DBMS_LOGMNR to <用户名>;
grant select on v_$logmnr_contents to <用户名>;
grant select any transaction to <用户名>;
grant select any table to <用户名>;
Oracle版本为12c
当Oracle版本为12c时,启用CDC时步骤如下:
1. 开启数据库LogMiner组件
12c版本之后数据库默认开启LogMiner,无需手动开启。
2. 开启数据库归档日志模式
以DBA身份登录数据库。
执行以下SQL,检查数据库日志模式。
Select log_mode from v$database;
如果查询log_mode为ARCHIVELOG,则跳过步骤3(开启数据库归档日志模式);如果是NOARCHIVELOG,则执行步骤3。
开启数据库归档日志模式。
关闭数据库:shutdown immediate;
启动数据库mount:startup mount;
开启数据库归档日志并开启数据库:
Alter database archivelog;
Alter database open;
3. 开启附加日志
执行以下命令检查数据库是否开启附加日志。
Select supplemental_log_data_min, supplemental_log_data_pk, supplemental_log_data_all from v$database;
如果查询结果返回NO,则需要执行下一步;如果是YES,则无需任何操作。
12c版本开启附加日志分为两种,一种是整库的附加日志,一种是指定表的附加日志。
如果为12c版本的容器数据库,需要先切换会话到要开启附加日志的PDB中,以名称为“test”的PDB为例:Alter session set container=test;
开启整库附加日志命令:
Alter database add supplemental log data (primary key) columns;
Alter database add supplemental log data (all) columns;
开启指定表的附加日志命令:
Alter database add supplemental log data;
Alter table <schema>.<table> add supplemental log data (primary key) columns;
Alter table <schema>.<table> add supplemental log data (all) columns;
4. 创建Logminer抽取用户
如果用户是被指定的普通权限用户,请参考步骤5普通用户授权,如果需要重新创建用户,请执行以下操作:
创建Logminer抽取用户,对于12c 标准版和12c CDB版操作不同,具体操作如下:
对于12c 标准版,操作如下:
Create user <username> identified by <password>;
grant connect to <username>;
grant create session, alter session, execute_catalog_role, select any dictionary, logmining to <username>;
grant select on <schema>.<table> to <username>;
对于12c CDB版,操作如下:
Alter session set container=CDB$ROOT;
Create user <username> identified by <password> container=all;
grant connect to <username>;
grant create session, alter session, execute_catalog_role, select any dictionary, set container, logmining to <username> container=all;
创建完用户后,该用户对所有PDB生效(包括权限)。
查看具体有哪些PDB可再切换到CDB后执行如下语句:show pdbs。
切换到要抽取的PDB数据库,并授权对应的表select权限给<username>。
Alter session set container=<pdb>;
grant select on <schema>.<table> to <username>;
5. 普通用户授权
CDC作业使用Oracle数据源的用户如果为普通用户,则需超级管理员执行如下命令为用户授权:
grant connect to <用户名>;
grant select on sys.dba_objects to <用户名>;
grant select on sys.dba_extents to <用户名>;
GRANT SELECT ON V_$DATABASE to <用户名>;
GRANT SELECT ON V_$LOG TO <用户名>;
GRANT SELECT ON V_$LOGFILE TO <用户名>;
GRANT SELECT ON V_$ARCHIVED_LOG TO <用户名>;
GRANT SELECT ON V_$ARCHIVE_DEST_STATUS TO <用户名>;
GRANT EXECUTE ON DBMS_LOGMNR to <用户名>;
grant select on v_$logmnr_contents to <用户名>;
grant select any transaction to <用户名>;
grant select any table to <用户名>;
Oracle版本为21c
当Oracle版本为21c时,启用CDC时步骤如下:
1. 开启数据库LogMiner组件
21c版本之后数据库默认开启LogMiner,无需手动开启。
2. 开启数据库归档日志模式
以DBA身份登录数据库。
执行以下SQL,检查数据库日志模式。
Select log_mode from v$database;
如果查询log_mode为ARCHIVELOG,则跳过步骤3(开启数据库归档日志模式);如果是NOARCHIVELOG,则执行步骤3。
开启数据库归档日志模式。
关闭数据库:shutdown immediate;
启动数据库mount:startup mount;
开启数据库归档日志并开启数据库:
Alter database archivelog;
Alter database open;
3. 开启附加日志
执行以下命令检查数据库是否开启附加日志。
Select supplemental_log_data_min, supplemental_log_data_pk, supplemental_log_data_all from v$database;
如果是YES,无需任何操作;如果查询结果返回NO,则需要执行以下命令。
开启整库附加日志命令:
Alter database add supplemental log data (primary key) columns;
Alter database add supplemental log data (all) columns;
开启指定表的附加日志命令:
Alter database add supplemental log data;
Alter table <schema>.<table> add supplemental log data (primary key) columns;
Alter table <schema>.<table> add supplemental log data (all) columns;
如果为21c版本的容器数据库,需要先切换会话到CDB中,然后执行开启整库附加日志命令,整体操作如下:
Alter session set container=CDB$ROOT;
Alter database add supplemental log data (primary key) columns;
Alter database add supplemental log data (all) columns;
提交上一步中的所有修改。
Alter system switch logfile;
4. 创建Logminer抽取用户
如果用户是被指定的普通权限用户,请参考步骤5 普通用户授权,如果需要重新创建用户,请执行以下操作:
Alter session set container=CDB$ROOT;
Create user <username> identified by <password> container=all;
grant connect to <username>;
grant create session, alter session, execute_catalog_role, select any dictionary, set container, logmining to <username> container=all;
创建完用户后,该用户对所有PDB生效(包括权限)。
查看具体有哪些PDB可再切换到CDB后执行如下语句:show pdbs。
切换到要抽取的PDB数据库,并授权对应的表select权限给<username>。
Alter session set container=<pdb>;
grant select on <schema>.<table> to <username>;
5. 普通用户授权
CDC作业使用Oracle数据源的用户如果为普通用户,则需超级管理员执行如下命令为用户授权:
grant connect to <用户名>;
grant select on sys.dba_objects to <用户名>;
grant select on sys.dba_extents to <用户名>;
GRANT SELECT ON V_$DATABASE to <用户名>;
GRANT SELECT ON V_$LOG TO <用户名>;
GRANT SELECT ON V_$LOGFILE TO <用户名>;
GRANT SELECT ON V_$ARCHIVED_LOG TO <用户名>;
GRANT SELECT ON V_$ARCHIVE_DEST_STATUS TO <用户名>;
GRANT EXECUTE ON DBMS_LOGMNR to <用户名>;
grant select on v_$logmnr_contents to <用户名>;
grant select any transaction to <用户名>;
grant select any table to <用户名>;
SQL SERVER数据库开启CDC
SQL Server开启CDC的命令如下,用户需登录SQL Server控制台进行操作。
use <database>; ##选择数据库
exec sys.sp_cdc_enable_db; ##该库启用CDC
Exec sys.sp_cdc_enable_table @source_schema=<schema>,@source_name=<table>,@role_name=null; ##对指定表启动CDC
EXEC sys.sp_cdc_start_job; ##开启日志记录任务,若执行该命令后,提示任务已开启,忽略即可
当表结构发生变更时,需要关闭表CDC并重新开启,否则变更的字段数据无法捕获,关闭表CDC命令如下:
|
EXEC sys.sp_cdc_disable_table @source_schema = N'dbo', @source_name = N'newtable', @capture_instance = N'dbo_newtable' GO |
批量开启表CDC命令如下,执行该命令后,会将该模式下所有的表都开启CDC。如下命令中模式以dbo为例,如果是其它模式把dbo改为其它模式即可。
|
BEGIN DECLARE @temp varchar(100) DECLARE @tb_schema varchar(100) set @tb_schema='dbo' DECLARE tb_cursor CURSOR for (SELECT a.name from sys.tables a LEFT JOIN sys.schemas b on a.schema_id=b.schema_id where a.is_tracked_by_cdc=0 and b.name=@tb_schema and a.name !='systranschemas') open tb_cursor FETCH NEXT from tb_cursor into @temp WHILE @@fetch_status=0 BEGIN exec sys.sp_cdc_enable_table @source_schema=@tb_schema,@source_name=@temp,@role_name=null FETCH NEXT from tb_cursor into @temp END CLOSE tb_cursor DEALLOCATE tb_cursor END ; |
MySQL CDC组件出现Slave has more GTIDs than the master has,using the master'sSERVER_UUID错误
1. 问题原因:
当MySQL数据库重置GTID或异常断电导致GTID丢失,引起MySQL CDC组件出现Slave has more GTIDs than the master has,using the master'sSERVER_UUID错误。出现此情况是因为MySQL CDC组件同步的MySQL Master中GTID小于MySQL CDC中记录的GTID。
2. 解决办法:
如果是用户手动重置GTID引起的,首先保证之前MySQL CDC抽取的数据正常落库,然后单击MySQL CDC配置中“清除断点”,重新启动即可。
当由于异常情况出现GTID丢失时,首先查看MySQL CDC对应Topic中数据GTID断点位置,与MySQL Master位置进行比较,将二者相差数据手动同步。同步完成后,保证之前MySQL CDC抽取的数据正常落库后,然后单击MySQL CDC配置中“清除断点”,并设置“初始化偏移量”为MySQL Master最新位置,然后重新启动运行即可。
如何扩容CDC运行资源
当CDC作业运行提示Flink集群资源不足时,需要用户在后台手动对集群的taskmanager进行扩容。扩容步骤如下:
登录Flink集群任一节点后端。
执行如下脚本进行扩容:
/data/software/dataintegration/flink/flink-1.13.6/bin/taskmanager.sh start
用户通过实时作业从SQL SERVER抽取数据时,出现长时间未捕获到数据
1. 可能问题原因1:
原因描述:可能是因为源端数据库所在服务器节点磁盘空间不足,导致源端停止捕获。
解决办法:清理源端数据库磁盘空间后,在源端数据库执行EXEC sys.sp_cdc_start_job命令,源端即可恢复数据捕获。
2. 可能问题原因2:
原因描述:SQL Server服务端的SQLServerAgent未运行,导致源端停止捕获。
解决办法:需要到数据库后端节点启动SQLServerAgent服务,方可恢复。
批量在Hive数据源中执行SQL组件时出现异常
1. 问题现象
批量在Hive数据源中执行SQL组件时出现异常,提示java.lang.RuntimeException: java.util.concurrent.RejectedExecutionException:Task java.util.concurrent.FutureTask@4be797a1 rejected from java.util.concurrent.ThreadPoolExecutor@a568b69[Running, pool size = 100, active threads = 100, queued tasks = 100, completed tasks =****]
2. 解决方法
建议增加Hive组件自定义配置项中hive.server2.async.exec.threads的值(默认值为200,可根据实际情况进行增加)。
从Hive数据源抽取数据加载至MySQL时出现异常
1. 问题现象
从Hive数据源抽取数据加载至MySQL时出现异常,提示Can not read response from server .Expected to read 4 bytes,read 0 bytes before connection was unexpectedly lost。
2. 解决方法
调整MySQL服务端配置文件/etc/my.cnf中参数net_read_timeout=300,net_write_timeout=600。
如何修改组件资源最大收藏个数
登录绿洲平台安装部署节点(所有部署节点都涉及修改)。
在/data/software/dataintegration/oip-di-web/scripts/restart_di_web.sh文件中,找到变量“ETL_NUM_UPPERBOUND”,修改其对应的值(默认为100,用户可根据实际需要进行配置),配置完成后保存该文件。
执行该脚本(请注意依次执行各节点该脚本,同时执行可能会引起web页面功能异常)。
同步数据时,时间类型数据的值在同步到数据库后发生了改变
比如原来时间类型数据为“2021-12-25 11:00:00”,同步到数据库后,时间类型数据变为“2021-12-24 21:00:00”,同步数据时,时间类型数据的值和插入数据库后的值不匹配。
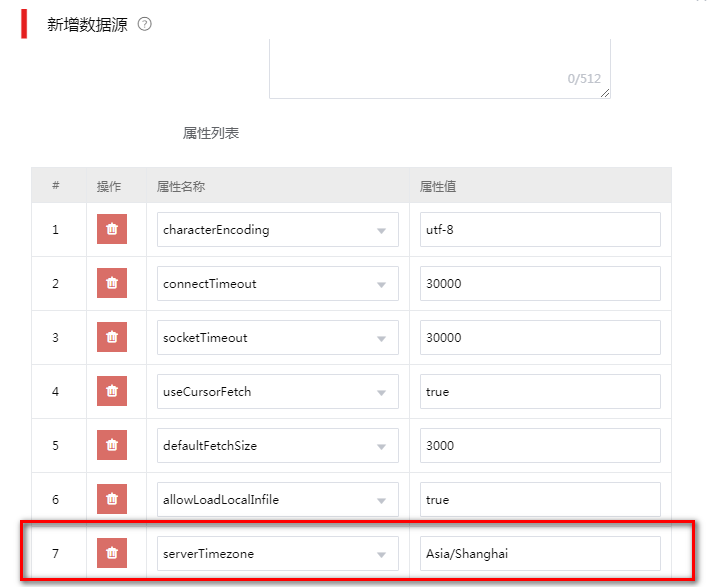
问题常见于MySQL数据库,主要是数据库服务端使用了CST时区。CST时区在操作系统中指的是China Standard Time UTC+8中国标准时,但这种简写形式的时区表示在jdbc驱动中会有歧义,被解读为Central Standard Time UTC-6美国中部标准时间。
此时需要修改插入数据的数据源属性,在数据源的属性列表中,添加属性:serverTimezone,值设置为:Asia/Shanghai。
图-12 配置数据源属性值
当DataEngine集群中禁用了root用户导致任务超时无法进行日志采集时,如何修改数据集成相关服务配置
分别进入数据集成各服务的启动脚本目录,修改启动脚本。
数据集成-执行器
cd /data/software/dataintegration/oip-di-executor_20300/scripts
vi restart_di_executor.sh
数据集成-web
cd /data/software/dataintegration/oip-di-web/scripts
vi restart_di_web.sh
数据集成-调度器
cd /data/software/dataintegration/ oip-di-schedule /scripts
vi restart_di_schedule.sh
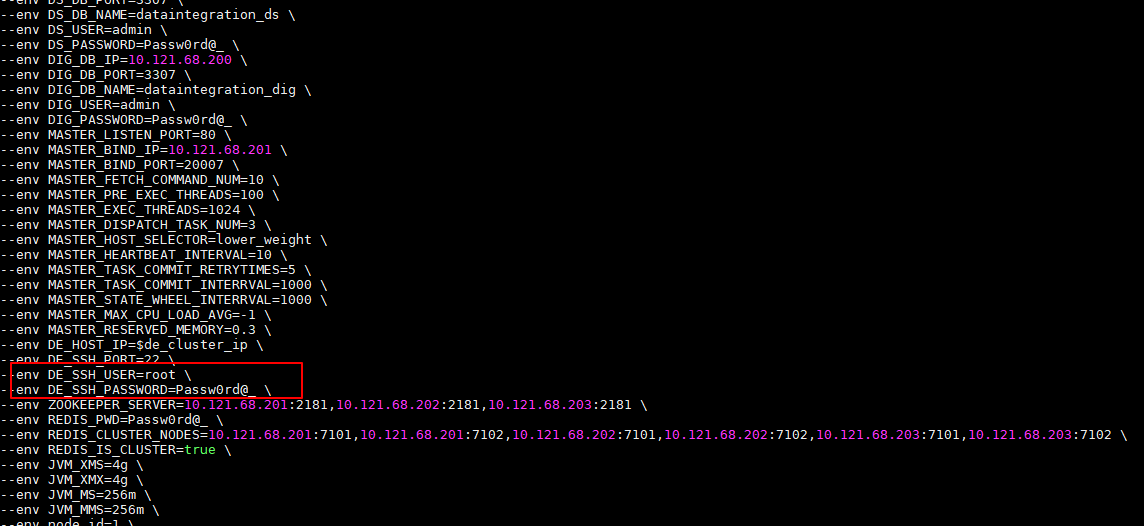
分别修改各个启动脚本中配置的DE服务器用户名密码。
DE_SSH_USER 配置DE服务器用户名
DE_SSH_PASSWORD 配置DE服务器密码
图-13 修改服务器用户名密码
参数修改完成后分别执行启动脚本。
重启执行器:sh restart_di_executor.sh
重启web:sh restart_di_web.sh
重启调度器:sh restart_di_schedule.sh
融合集成平台各个节点均需执行上述操作。
加载至表数据库选择Vertica时,提示“Locking failure:Timed out I locking Table”错误
由于Vertica使用表级锁,插入数据时如果有其他进程在操作同一张表,如Delete、Update、Insert等操作,可能会导致插入数据等待锁超时。出现该问题时,需等待其他进程执行完成,然后再重新运行数据集成作业。
CDC任务提交yarn时手动在DE集群中同步绿洲平台IP和域名的映射关系
CDC任务提交yarn时需用户手动在DE大数据平台的所有Flink节点上同步配置绿洲平台的hosts配置信息。具体操作:登录绿洲平台任一节点,打开/etc/hosts文件,将绿洲平台的IP和域名的映射关系(如下图所示)复制后追加到DE大数据平台Flink节点上的/etc/hosts文件最下方。
图-14 IP和域名的映射关系

注意:如果绿洲平台、DE大数据平台部署节点的IP地址发生变化,用户需在DE大数据平台的所有Flink节点上重新修改绿洲平台的hosts配置信息。
加载至表数据库选择Oracle时,提示“ORA-01461: can bind a LONG value only for insert into a LONG column”
当目标数据库为Oracle时,同时向多个varchar2(4000)字段加载数据可能会产生报错,是因为在使用UTF-8或其他能存储中文的字符集时,Oracle存储一个字符可能需要2个或3个字节的存储空间。虽然表字段被定义为varchar2(4000) 类型,但是该字段的data_length为4000的2或3倍长,这种情况下Oracle会把data_length长度超过4000的字节当做LONG型处理,当表中有两个这样的字段,插入数据时相当于同时操作2个LONG字段,所以会产生报错,建议减小字段长度定义来避免此问题。
抽取SQLServer中double类型数据并加载至MySQL,Navicat中查看两边数据不一致
Navicat对于SQLServer、MySQL等不同数据库的部分数据类型值的呈现方式有所不同,因为此工具对应不同数据库的适配方式不同。比如:Navicat中显示MySQL“3.3999999521443642e38”与SQLServer“3.4E38”实际值是一样的,都是“339999995214436420000000000000000000000”。
从SQLServer抽取数据并加载至MySQL,bit类型被映射为MySQL的tinyint(1)类型
从SQLServer抽取数据并加载至MySQL,bit类型会被映射为MySQL的tinyint(1)类型。
SQLServer数据库中的bit即位数据类型,取值0或1,经常用于逻辑值判断true(1)或false(0),输入非0值时系统将其替换为1。
MySQL中功能上最接近SQLServer中bit类型的是tinyint(1),且MySQL驱动中预留了一个名为tinyInt1isBit的属性,缺省值为true,表示数据库中出现的长度为1的tinyint类型当做bit用。所以,MySQL本身没有bit类型,且官方提供的JDBC驱动中默认会把tinyint(1)当做bit用。
CDC作业配置MySQL数据源时出现The server time zone value为乱码的错误提示
问题产生条件:MySQL数据库时区配置不正确,使用show variables like '%time_zone%'命令查看显示time_zone的值为SYSTEM,但system_time_zone的值为空。
解决方案:如下两个方案任选其一即可。
方法一:修改数据库配置。
在数据库my.cnf配置文件中增加一行default-time-zone='+8:00'
然后在SQL命令行中执行命令set global time_zone = '+8:00'
方法二、在MySQL数据源中增加以下两个配置。
serverTimezone=Asia/Shanghai
connectionTimeZone=Asia/Shanghai